滴滴在流量链路检测架构设计及实践
Posted Java指南者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了滴滴在流量链路检测架构设计及实践相关的知识,希望对你有一定的参考价值。
1.
背景
Omega是公司内部提供移动端用户行为采集、加工、存储、呈现和应用的全流程数据服务平台。整个平台以前端数据采集为源头,通过实时或者离线ETL加工出具有业务需求的指标结果,为滴滴的用户增长、产品优化、智能运营及科学决策等提供可靠的流量数据支持。目前支持了公司内外部近1500+应用,覆盖公司大部分业务线。
业务层面对埋点提出了全面、准确、及时的高要求,而这也是整个数据体系构建的基石。经过过往几年的持续打磨,我们沉淀了一套覆盖全链路的检测体系,能够有效的辅助链路同学看清数据现状,定位数据问题。下面我将与大家分享技术侧的架构设计。
2.
数据链路

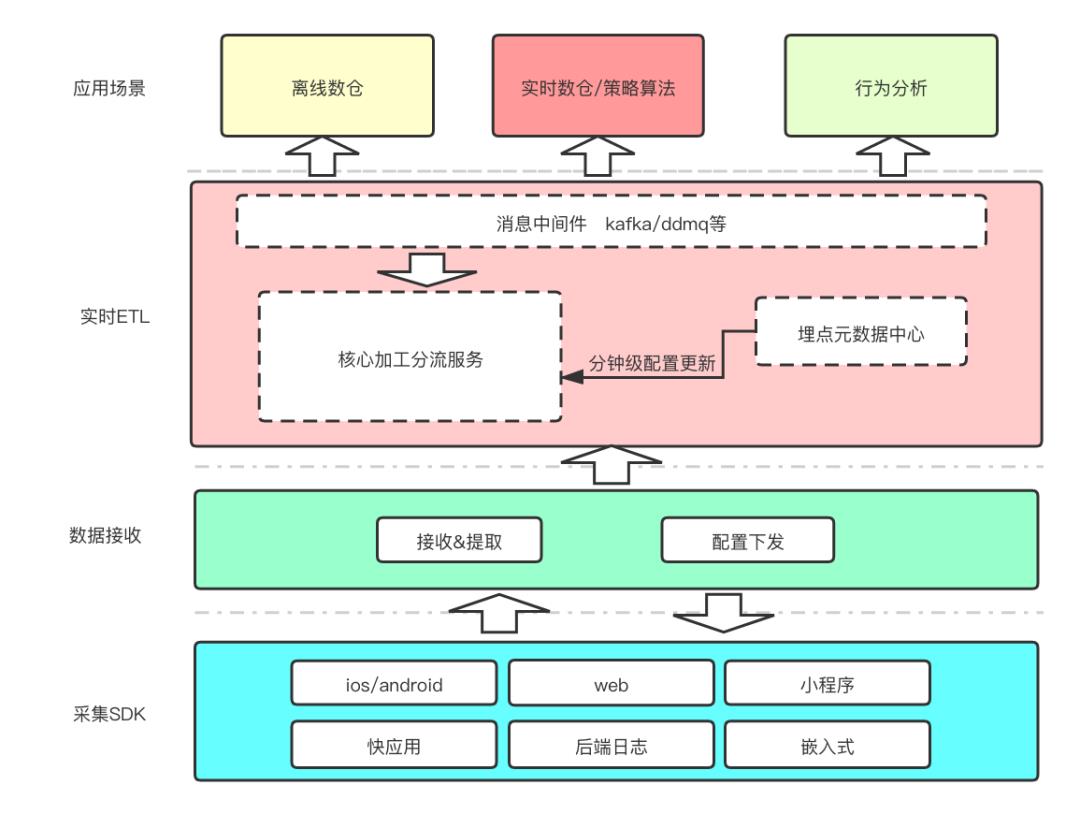
首先,先简单介绍一下整个数据链路的架构,一共包含如下六个核心模块。
采集SDK:用于收集、组装、发送埋点数据,通过相关缓存策略,降低丢包率、重复率。同时接收服务端策略下发,定向采集。
数据接收:用于接收来自端上的埋点数据及配置下发,高吞吐轻量级web服务。
实时ETL:下游实时、离线数据的同源出口,负责比较重的数据处理逻辑,如格式转换、地理信息填充、白名单过滤等。
离线数仓:kafka数据到hive的清洗过程,包含通用ODS及面向Session、设备等主题的数仓建设。
实时分流:面向实时数仓及算法策略场景的分流服务。
行为分析:kafka2olap子链路,服务上层行为分析能力,如埋点细分、漏斗、路径分析等分析产品。
1. 数据源种类多,需要多种采集SDK,且采集逻辑需要适配不同的生态。
2. 采集数据量大,强关联业务的使用场景,对数据的准确、及时性要求高。
3. 采集SDK宿主及各个采集组件在不断迭代,可能会出现问题。
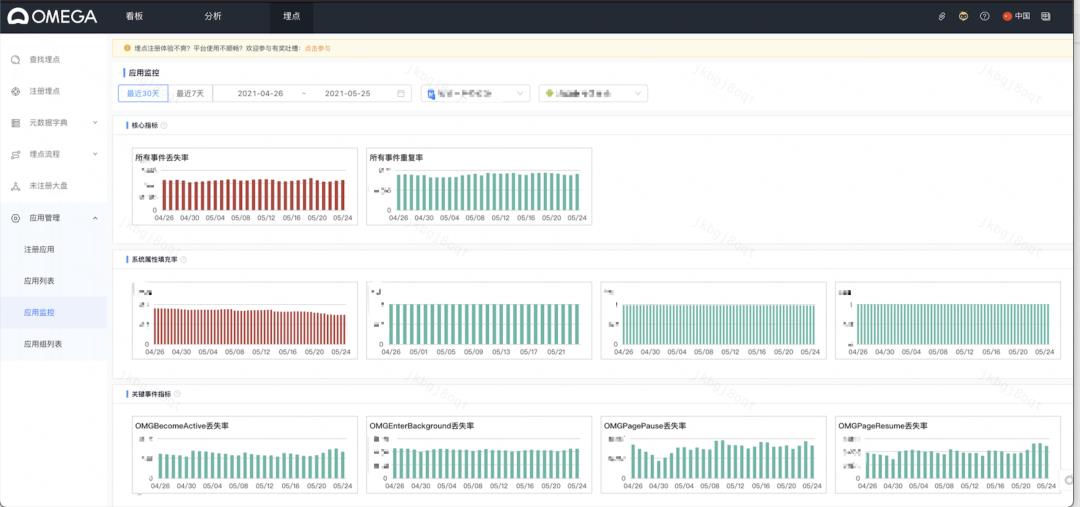
如何有效的评估并提供给下游一份可用的数据?这就是贯穿全流程的链路检测服务需要解决的问题,数据链路检测模块主要承担链路的接收率、重复率、丢包率的度量及预警等职责。
在采集精确度方面:
1)端上sdk层面,前端设备会以进程(android/ios,h5以页面)为基本单位,维护一个计数器,在app存活期间记录当前的埋点上报数据量,并且会记录后续的每次上报数据量。
2)通道数据加工层面,在端上实现类似trace系统的traceId,埋点每次上传会在端上生成唯一的请求Id,保证每次请求的唯一性,请求Id会在数据流动各个节点进行记录。在数据传输节点保证at last once语义的情况下,实现每一个埋点的唯一性校验。
3)在小时级粒度下,以服务器接收时间解决接入层请求日志和埋点日志切割的时间漂移问题。
在采集准确度方面:
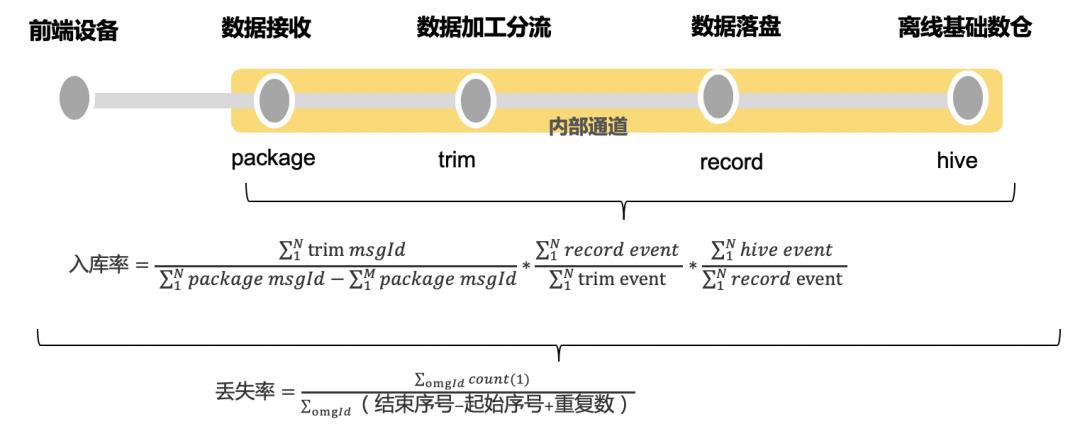
链路检测有两个核心指标:丢失率和入库率,分别用来度量端上sdk、内部通道的采集质量。
丢失率是逻辑上度量端上sdk采集质量,丢失率分子为实际在接入层收集到请求数,丢失率的分母是通过计数器实现预期的请求数,丢失率通过对埋点请求接收情况量化进而度量端上sdk的采集质量。
入库率是用来度量内部通道的采集质量,通过埋点数据流动过的4个节点的请求pv及埋点pv【一个请求包含多条埋点数据】比率实现,入库率通过对埋点请求pv及埋点pv实际流入到下游情况量化进而度量内部通道的采集情况。
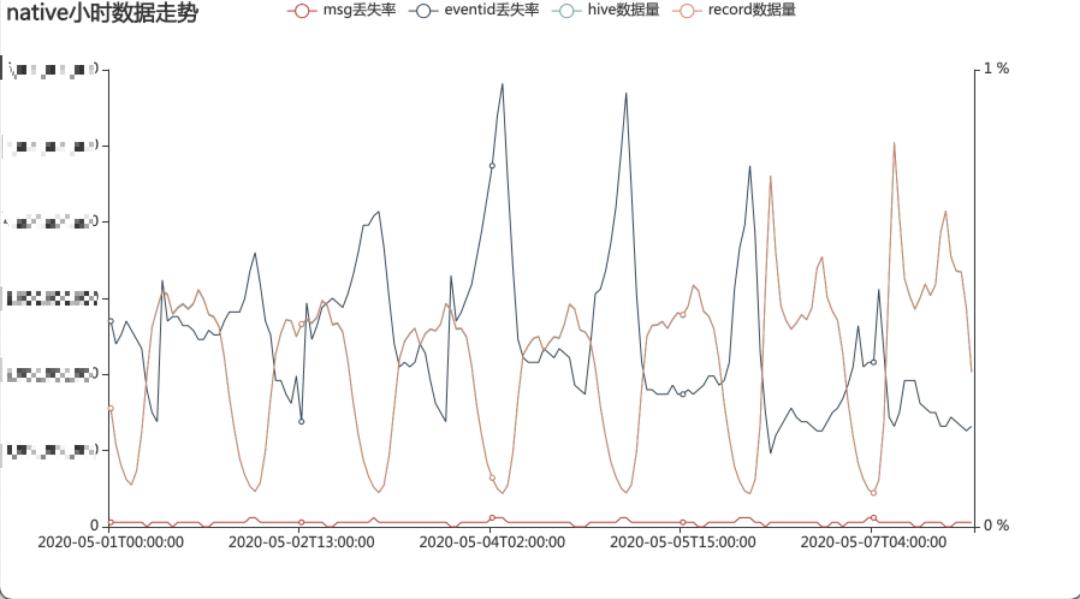
基于上面思考和设计,实现了小时级及天级的链路检测服务,具体如下:
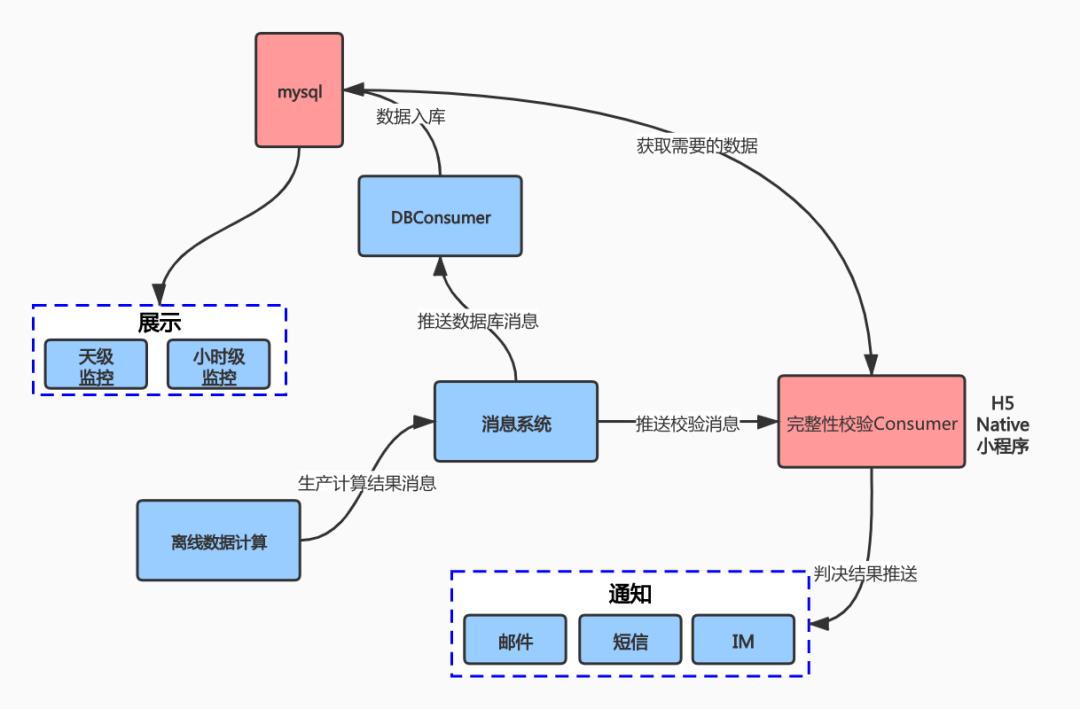
基于离线数据实现链路全局角度检测采集包、及包内部埋点的丢失,重复情况
 Omega采集链路起源滴滴对流量采集的诉求,并且跟随对流量数据使用
的
不断迭代升级,逐渐演进,和业务共同成长。
随着“0188战略落地”,业务增长方面持续发力,对实时数据诉求日渐增多,提升数据时效性和实时化服务也是Omega后续采集方案演进的重点,致力于进一步提升更好的数据埋点采集、实时服务、基础数仓等服务。
Omega采集链路起源滴滴对流量采集的诉求,并且跟随对流量数据使用
的
不断迭代升级,逐渐演进,和业务共同成长。
随着“0188战略落地”,业务增长方面持续发力,对实时数据诉求日渐增多,提升数据时效性和实时化服务也是Omega后续采集方案演进的重点,致力于进一步提升更好的数据埋点采集、实时服务、基础数仓等服务。
团队内推
▬
团队正在热招高级/资深数据研发工程师岗位。欢迎有兴趣的小伙伴加入,可以投递简历至diditech@didiglobal.com,请将邮件主题命名为 姓名-投递岗位-投递团队。

以上是关于滴滴在流量链路检测架构设计及实践的主要内容,如果未能解决你的问题,请参考以下文章