滴滴开源监控夜莺的架构设计思考
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了滴滴开源监控夜莺的架构设计思考相关的知识,希望对你有一定的参考价值。
Nightingale是一套衍生自Open-Falcon的互联网监控解决方案,融入了滴滴的最佳实践,在性能、易用性、可用性方面都做了大幅改进,在滴滴抗住了7.7亿(包括物理机、虚机、容器、网络、业务模块的)监控指标。本文首先会介绍夜莺监控的总体架构,然后从研发人员的视角入手,总结好的软件和架构所具备的一些特征,最后讲解夜莺在设计和研发过程中关于这些思考的实践。
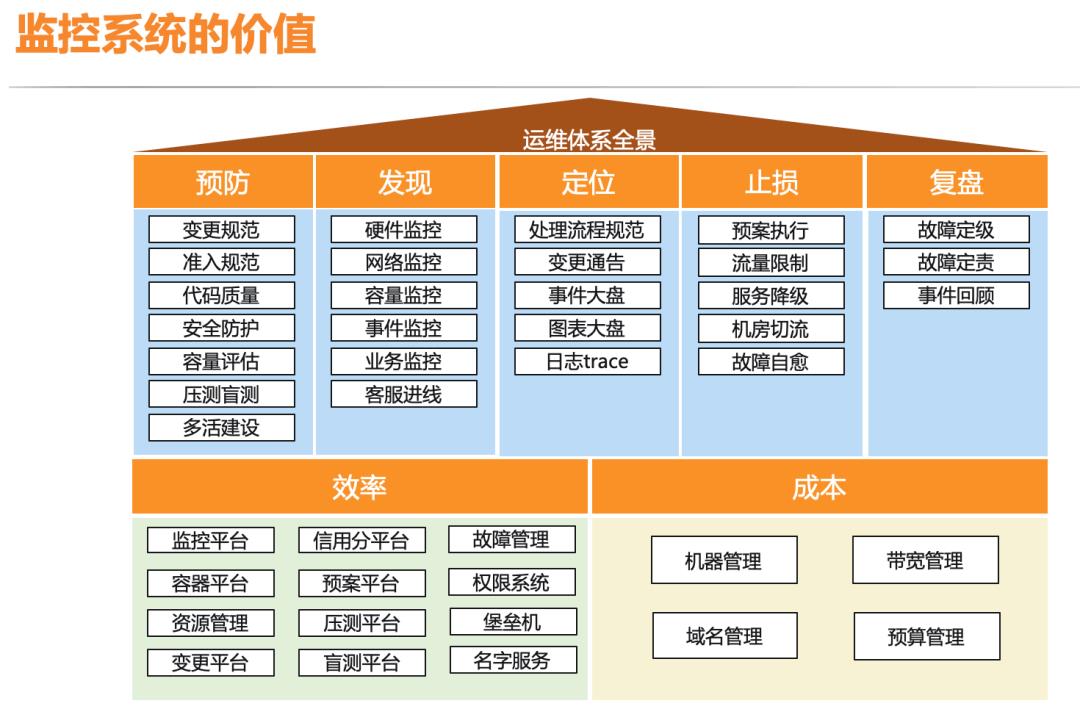
运维的主要工作主要由三个,稳定性、成本和效率,稳定性主要关注的是故障,从故障的整个生命周期,预防、发现、定位、止损、复盘,我们可以梳理出图中的手段。从上图可以看到预防阶段的容量评估、压测盲测,发现阶段的各种监控,定位阶段的事件大盘,图表大盘,日志trace,止损阶段的故障自愈,复盘阶段的事件回顾都和监控紧密相关,监控平台贯穿在整个运维体系各个阶段,可以说是运维体系中最核心的系统。
了解了监控系统的价值之后,下面对夜莺监控进行一下总体的介绍。
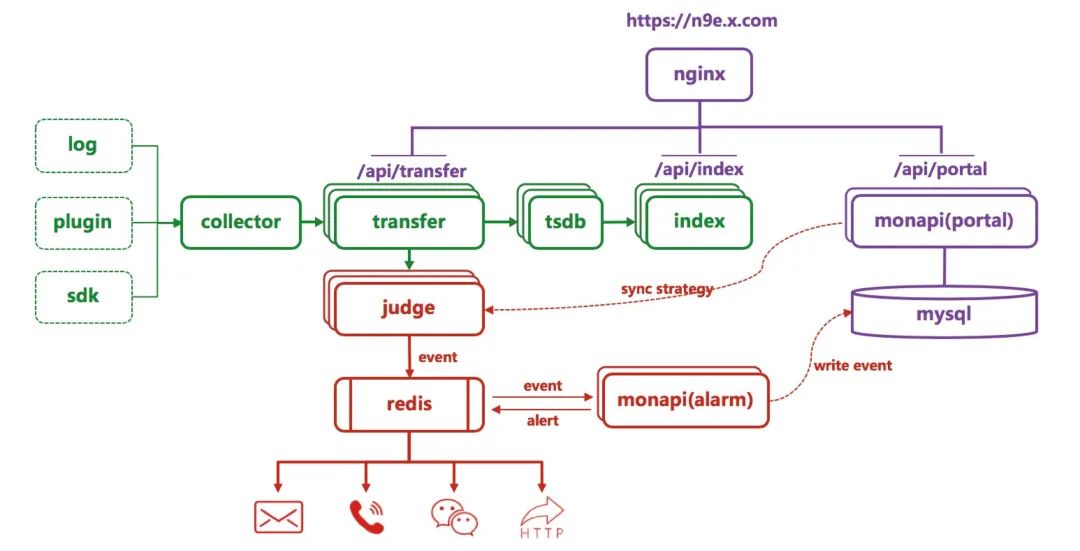
上面是夜莺监控的架构图,因为要应对海量的监控数据,所以图中的所有模块都支持横向水平扩展,绿色部分负责了采集、传输和存储功能,红色部分负责了告警功能,紫色部分负责和用户交互,用户可以通过监控数据上报API将数据上报给Collector或者Transfer,之后Transfer会将数据转发给TSDB,TSDB接收到数据之后会生成索引数据推给index,用户在看图的时候会先从index查询索引,然后再从TSDB查询监控指标。另一份会将配置了监控策略的监控数据发给Judge,Judge收到数据之后,会和内存中的告警策略做匹配,匹配成功之后,会进行告警判别,然后产生告警事件,将告警事件写的Redis中。

好的软件是容易维护的,容易维护主要体现在三个方面,容易部署、容易监控和容易扩容。
首先说一下,容易部署,如果做到以下两点,可以说算比较及格了。
其次是容易监控,系统的运行状态,健康状态,核心业务指标,做到可获取,可输出。可以通过接口的方式让外部去查询,也可以自动上报给监控平台,或者通过日志的方式输出到日志文件。做到假如系统出现问题,可以通过暴露的状态数据或者日志,快速定位系统的问题在哪里。
最后是容易扩容,服务尽量做到无状态,什么是无状态服务呢,只根据请求参数,返回对应的数据,服务本身不保存数据,不记录上下文。无状态服务的特点决定了它可以很方便的增加或者减少服务实例,容量不够了直接加机器,一定程度上也可以弥补程序性能不足的问题。
如果服务必须是有状态的,在扩容的时候就涉及到了数据迁移,因为每次数据迁移都会增加数据丢失的可能性,所以要尽量做到扩容的时候,数据少迁移。数据如何迁移是由数据的分片方式决定的。常见的数据分片方式有两种,一种是路由表,一种是hash算法。对于路由表分发的方式,将数据发到哪个实例都做好映射标记,旧实例容量满了之后,直接将新数据指向新实例,旧的数据不做迁移。这样方式适用于路由表规模比较小的情况,如果路由表里映射关系有达到了上亿规模,每次寻找匹配目标实例,就要消耗很多的时间。这个时候使用算法分发更加合适,通过hash算法,自动计算出流量分发到哪个实例,hash算法的选择也很重要,不同的算法在扩容的时候产生的数据迁移规模会有很大差别。
容易维护部分讲完之后,我们讲一下,如何提高软件的鲁棒性。
先看下鲁棒性定义:系统在异常和危险情况下的生存能力。要想提高软件的鲁棒性,在设计架构和研发的时候,可以多问问下面几个问题。
进程启动的时候,要对所处的环境进行检测,出现异常直接报错。比如如果自身的进程已经在跑了,是不是仍然启动新的进程。
有多年的开发和运维经验的同学,一定会遇到过各种基础软件出问题的情况,所以在开发软件的时候,我们不能假设依赖都是可靠的,不能信赖别人,尽量的减少对第三方的依赖,必须依赖,就依赖老牌的软件(这里提及一下林迪效应,存在越久的东西会存在更久,经过时间检验的系统要比新系统可靠性高很多)。
如果必须要依赖第三方系统,最好做到弱依赖,依赖的系统出问题我们要有重试策略,调用其他系统需要注意超时控制。考虑是否增加缓存,依赖的数据服务挂了,自身依然可以有损地运行,而不是直接不能正常工作了。
程序是否有recover panic的机制?自身的进程挂了,要有保姆程序负责拉起。如果是服务是无状态的,则至少同时跑两个实例,如果服务只能同时跑一个实例,可以搞个主备,定期探测对方心跳,对方挂掉自己直接成为master。
实现的接口尽量是幂等的,同样的请求调用一次和调用两次是相同的效果。进程退出尽量优雅,先关闭端口,把正常处理的任务完成之后,再退出。
下面讲一下,上面这些思考是如何在夜莺研发过程中的实践。
夜莺的所有组件都提供了一个health接口,通过访问health接口,可以清楚的知道服务是否存活。所有服务的核心业务数据(比如Transfer的接收点数,发送点数,Judge的运行任务数)都进行了统计并定时给自身监控,在监控系统中可以很直观的看到每个模块的内部数据,运行状态,调用第三方系统的出错次数,出现问题了可以很方便的进行定位。
作为数据入口的Transfer是无状态服务,可以很方便的进行水平扩展。judge和index模块会定时上报自己的心跳,增加实例后,和judge、index交互的模块可以立即感知,不需要再去修改它们的地址列表。tsdb模块做为存储服务,为了实现水平扩展能力,Transfer采用数据分片的方式将数据发给TSDB,因为监控数据体量非常大,指标量过亿,所以我们采用了算法分片的方式,使用一致性hash算法,将监控数据分发给tsdb存储,在扩容时可以保证数据迁移近可能的少。
夜莺的所有模块在启动之前都会检测是否已经有自身进程已经启动了,如果有自身进程已经启动,会提示进程已存在,并直接退出。
MySQL负责采集策略、告警策略和告警信息的存储,Monapi从MySQL拿到采集和告警策略之后,会对配置信息进行缓存,如果MySQL挂了,已配置的告警和采集仍然可以正常工作;Redis作为告警信息的传递通道,可以配置多个,push和pop端会对Redis挨个遍历,只要有一个Redis存活,服务就可以正常工作;Nginx作为自定义监控数据的上报入口,如果Nginx挂了,用户自定义的采集会受到影响,但基础指标的数据上报仍然可以正常工作。
夜莺对外提供的所有接口都加了panic recover机制,防止异常请求导致进程异常退出,所有进程默认都使用systemd进行托管,对进程意外panic的情况进行兜底处理。
夜莺的监控数据上报、配置相关的API均实现了幂等操作,重复提交相同的请求,对系统不会产生额外的影响,所有模块的http服务接收到退出请求后,会将正在处理的任务处理完成之后,再进行退出。
Q:Open-Falcon到Nightingale的改造过程中经历了哪些过程和阶段,踩过哪些坑,可否分享下?谢谢
A:这个话题有点大,展开可以说很多,就说一个吧,在告警方面的演进,滴滴在引进Falcon之初,将原来的judge处理数据的方式由push改为了pull,这样可以更好的支持与条件、NoData等告警,后面为了提高告警的时效性,我们又将pull模式改为了push模式,并且保留了与条件,同环比,NoData告警的能力,开源的夜莺就是演进到最后的状态。
A:我们把每个模块的功能都封装成了PKG,所以很容易进行二次开发,现在可以直接看代码。
A:可以参考这个:https://n9e.didiyun.com/docs/intro/#nightingale后续发展
A:夜莺的TSDB有数据归档的机制,默认会保存一年的数据,我们内部的核心数据会保存比较长的时间,持久化也是用的RRDtool。
A:Collector的日志采集是流式处理的,没有做限流,如果日志产生量太大,可以将想要监控统计的日志单独输出到一个文件中。
A:可以参考官方文档:https://n9e.didiyun.com/docs/install/product/
A:主要还是看系统的资源使用率,内存、CPU和磁盘这三个指标。
基于Kubernetes的DevOps实战培训将于2020年5月15日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片或者阅读原文链接查看详情。
以上是关于滴滴开源监控夜莺的架构设计思考的主要内容,如果未能解决你的问题,请参考以下文章
部署开源夜莺运维监控平台V3版本
滴滴夜莺nightingale v2版本磁盘读写监控bug修复方法
分布式系统监控平台-Overwatch架构设计(已开源)
Java生鲜电商平台--监控模块的设计与架构
实时海量日志分析系统的架构设计实现以及思考
实时海量日志分析系统的架构设计实现以及思考