第一篇:开篇介绍篇
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一篇:开篇介绍篇相关的知识,希望对你有一定的参考价值。
目录
数据库系统的作用
- 安全可靠的数据存储
- 能够非常有效地检索和处理数据。
数据库系统的性能/表现
硬件
– 处理器的速度
– 处理器数量
– 磁盘驱动器数量和 I/O 带宽
– 主存储器(内存)的大小
– 通讯网络
– 架构类型
软件
– 用于给定应用程序的数据库技术类型。
数据库调优、崩溃恢复
– 索引
– 数据重复
– 共享数据等
硬件
基本硬件
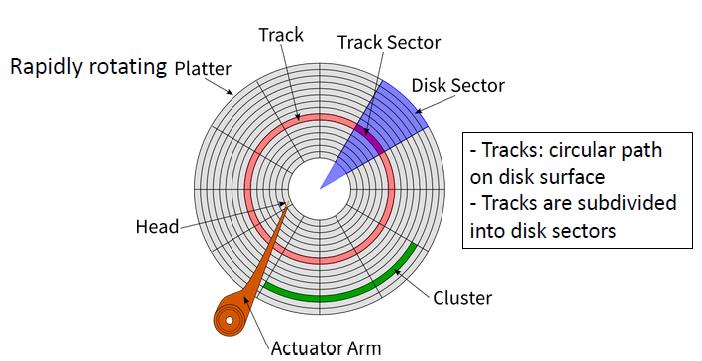
Tracks: 磁道; Actuator Arm:执行臂; platter:盘片; sector:扇区
磁盘访问
磁盘访问时间 = 寻址时间 + 旋转时间 + 传输长度/带宽
SSD(固态驱动器/固态磁盘)
• 没有移动部件,如硬盘驱动器 (HDD:也就是大家所说的机械硬盘)
• 硅而非磁性材料
• 无寻道/旋转延迟
• 没有像 HDD 那样的启动时间
• 静默运行
• 随机访问通常低于 100 微秒,而 HDD 为 2000 - 3000 微秒
• 相对非常昂贵。
磁盘访问时间 = 传输长度/带宽
存储架构
基本架构
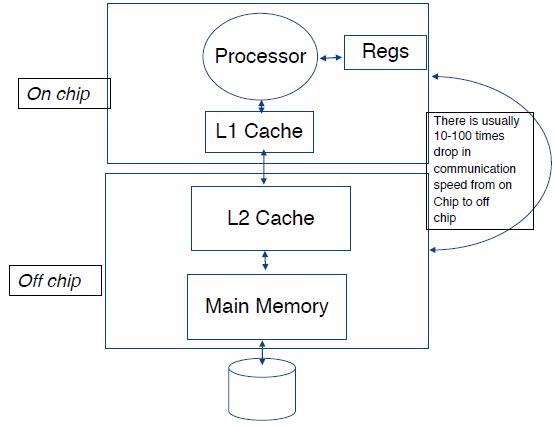
芯片上有处理器,寄存器和L1缓存, 芯片外有L2缓存和主存
多核架构
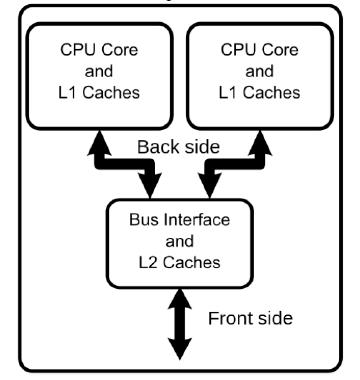
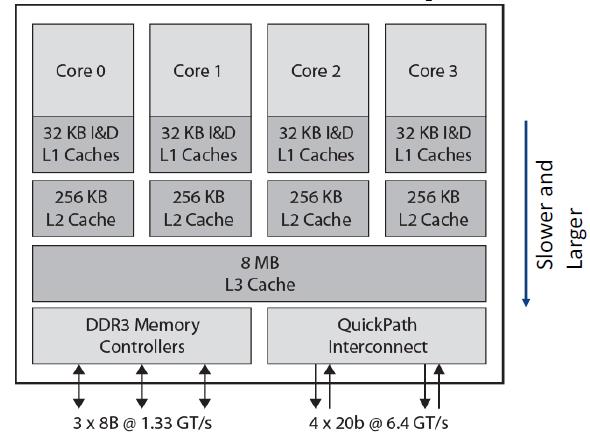
如上图,L1,2,3都在芯片上
缓存命中率= 查询在缓存中的次数/查询总次数
(内存)存储访问时间= H*C + (1-H)*M
H:缓存命中率
C:缓存访问时间
M:主存访问时间
同理,磁盘缓冲访问时间 = HB*BC+(1-HB)*D
HB:磁盘缓冲命中率
BC:磁盘缓冲访问时间
D:磁盘访问时间
数据库系统类型
| 简单文件 | 作为纯文本文件。 每行包含一条记录,字段由分隔符(例如,逗号或制表符)分隔 |
| 关系型数据库 | 作为由行和列组成的表(关系)的集合。 主键用于唯一标识每一行。 |
| 面向对象 | 直接以“对象”形式存储的数据(如 OOP) |
| No-SQL | 非关系 - 数据库建模而不是表格关系。 涵盖广泛的数据库类型。 |
接下来会挨个讨论:
简单文件
• 通常对于简单的应用程序非常快,但对于复杂的应用程序可能会很慢
• 可能不太可靠
• 应用依赖优化
• 很难维护(并发问题)
• 许多必需的特性(存在于关系数据库中)需要合并——不必要的代码开发和不可靠性的潜在增加
关系型数据库
• 非常可靠
• 独立于应用程序的优化
• 非常适合许多应用程序,由于大型主内存机器和 SSD,速度非常快。
• 一些 RDB 还支持面向对象模型,例如 Oracle、DB2 和 XML 数据+查询
• 对于一些简单的应用程序可能会很慢
面向对象数据库
• 直接存储为对象,而不是表
• 可能同时包含数据(属性)和方法——比如 OOP
• 在某些应用程序上可能会很慢
• 可靠的
• 有限的应用程序独立优化
• 非常适合需要复杂数据的应用
• 不幸的是,许多商业系统的起步并没有在RDB 技术的力量下存活下来,基本上从市场上消失了。
No-SQL
• 灵活/无固定模式(与 RDB 不同)
• 提供一种机制,用于存储和检索以表格关系以外的方式建模的数据
• 设计简单,应线性缩放
• NoSQL 有妥协的一致性并允许复制。
• 大多数 NoSQL 数据库提供“最终一致性”,这可能会导致从旧版本读取数据,这种问题称为过时读取
No-SQL数据库类型
| key value | Redis Server |
| Document-based | MongoDB,CouchDB |
| Column-based | HBase |
| Graph-based | Neo4j |
键值对数据库系统
将数据存储为键值对的集合,其中每个键都是唯一的.
为什么有用 - 许多应用程序不需要事务处理的表达功能——例如 Web 搜索、大数据分析可以使用 MapReduce 技术。
• 可以看作是一种 NoSQL 数据库
• 用于构建非常快速、高度并行的大数据处理 - MapReduce 和 Hadoop 就是示例
• 仅在键值对级别(行更新)进行原子更新。
数据库架构
| 中心化 | 数据存储在一个地点 |
| 分布式 | 数据存储在不同地点的服务器 |
| WWW | 存储在世界各地 |
| 网格 | 类似分布式,但每个节点管理自己的资源; 系统不作为一个整体。 |
| P2P | 像grid,但是节点可以随意加入和离开网络 |
| Cloud | 网格的泛化,但是资源是按需访问 |
中心化
• 数据集中在一处
• 系统管理简单
• 优化过程通常非常有效
• PC/集群计算/数据中心就是这方面的例子
分布式
• 数据分布在不同位置的多个节点上
• 节点通过网络连接
• 系统提供并发、恢复和事务处理
• 系统管理非常困难——通常只有一个资源管理器
• 崩溃恢复很复杂
• 通常存在数据复制——潜在的不一致
WWW万维网
• 数据存储在多个位置
• 多个数据所有者 - 不确定数据可用性或一致性
• 优化过程通常非常无效
• 不断发展的数据库技术——除了 XML/http 和一些访问数据的协议之外,没有制定任何标准
• 安全性可能是一个潜在问题
• 交易的概念更难执行
网格
• 非常类似于分布式数据库系统
• 数据和处理在可能在地理上分开的一组计算机系统之间共享。
• 通常为特定目的而设计——例如,科学应用
• 此类系统的管理由系统的每个所有者在本地完成
• 此类系统的可靠性和安全性没有得到很好的开发或研究。
• 网格系统模型与云计算模型相比或多或少已经过时
P2P
• 数据和处理在一组计算机系统之间共享,这些计算机系统可能像网格数据库系统一样在地理上分开
• 与网格数据库不同,计算机节点可以随意加入和离开网络 => 设计事务模型要困难得多
• 通常设计用于特定用途——例如 科学应用
• 此类系统的管理由数据所有者完成
Cloud computing
• 云计算为可通过 Internet 访问的数据和设备提供在线计算、存储和一系列新服务。
• 用户为服务付费,就像电话服务、电费等。
• 以最低的基础设施成本开发应用程序
以多种形式提供的云服务:
• Iaas – 基础设施即服务(提供虚拟机)
• Paas – 平台即服务(提供 Linux、Windows 等环境)
• Saas – 软件即服务(特定应用程序,如 RDB、邮件等)
关于数据库硬件部分的介绍就到这里了,辛苦大家观看,有问题欢迎随时评论交流。
以上是关于第一篇:开篇介绍篇的主要内容,如果未能解决你的问题,请参考以下文章