第八篇:词汇语义
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第八篇:词汇语义相关的知识,希望对你有一定的参考价值。
目录
情感分析
• 词袋,kNN 分类器。 训练数据:
‣ “This is a good movie.” → ☺ positive
‣ “This is a great movie.” → ☺ postive
‣ “This is a terrible film.” → ☹ negative
• “This is a wonderful film.” → ?
• 两个问题:
‣ 模型不知道“movie”和“film”是同义词。 由于“film”仅出现在负面示例中,因此模型了解到它是一个负面词。
‣ “wonderful”不在词汇表中(OOV – 词汇外)。
• 直接比较单词是行不通的。 如何确保我们比较词义?
• 解决方案:通过词法数据库显式添加此信息。
词语义
• 词法语义(本篇文章)
‣ 单词的含义如何相互关联。
‣ 人工构建资源:词法数据库。
• 分布式语义(下篇文章)
‣ 文字在文本中如何相互关联。
‣ 从语料库自动创建资源。
大纲
• 词法数据库
• 词相似度
• 词义消歧
词法数据库
什么是词义/意思(Meaning)?
• 他们的字典定义
‣ 但是字典定义必然是正式的/循环的也就是相关的
‣ 仅在含义已被理解时有用
• 他们与其他词的关系
‣ 也是循环的相关的,但更适合文本分析
定义
• 一个词义描述了该单词的词义的一个方面
• 如果一个词有多种含义,则它是多义词
字典中的意思
• 注释:字典给出的意义的文本定义
• 比如英语中Bank这个词:
‣ 接受存款并将资金用于借贷活动的金融机构
‣ 坡地(尤其是靠近水体的坡地)
关系中的意义
• 另一种定义含义的方法:通过查看它与其他词的关系
• Synonymy 同义词:几乎相同的含义
‣ vomit 与 throw up
‣ big 与 large
• Antonymy 反义词:相反的意思
‣ long 与 short
‣ big 与 little
• Hypernymy:is-a 关系
‣ 猫是一种动物
‣ 芒果是一种水果
• Meronymy:部分整体关系
‣ 腿是椅子的一部分
‣ 车轮是汽车的一部分
词网
• 词汇关系数据库
• 英语 WordNet 包括 ~120,000 个名词、~12,000 个动词、~21,000 个形容词、~4,000 个副词
• 平均:名词有 1.23 个意义; 动词 2.16
• 支持大多数主要语言的 WordNets (www.globalwordnet.org, https://babelnet.org/)
• 免费提供英文版(可通过 NLTK 访问)
同义词集
• WordNet 的节点不是单词或引理,而是意义
• 由同义词集或同义词集表示
词相似度
• 同义词:film vs. movie
• show vs. film? opera vs. film?
• 与同义词(二元关系)不同,单词相似度是一个频谱
• 我们可以使用词法数据库(例如 WordNet)或同义词库来估计单词相似度
通过路径去计算词相似度
• 给定 WordNet,根据路径长度查找相似性
• pathlen(c1,c2) = 1+ 边长 在词义 c1 和 c2 之间最短路径中
• 两种词义(同义词集)之间的相似性

• 两个词之间的相似性

• 问题:边的实际语义距离差异很大
‣ 在层次结构顶部附近有更大的跳跃
• 解决方案 1:包括深度信息(Wu & Palmer)
‣ 使用路径查找最低公共子消费者 (LCS)
‣ 使用深度进行比较

抽象节点
• 但节点深度仍然是较差的语义距离度量
‣ simwup(镍,钱)= 0.44
‣ simwup(镍,里氏比例)= 0.22
• 层次结构较高的节点非常抽象或笼统
• 如何更好地捕捉它们?
节点的概念概率
• 直觉:
一般/更泛化的节点→高概念概率(例如对象)
窄/更具体的节点 → 低概念概率(例如歌手)
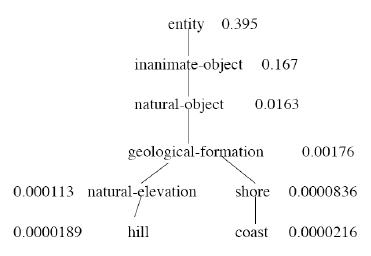
• 找到所有子节点,并总结它们的unigram 概率!

• child(c):c 的孩子的同义词集
• child(geological-formation) = {hill, ridge, grotto, coast, natural elevation, cave, shore}
• child(natural elevation) = {hill, ridge}

层次结构中较高的抽象节点具有较高的 P(c)
根据信息内容算相似性
信息内容: IC = − log P(c)
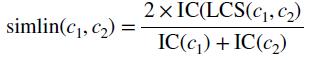
举例:将上面的概率带入即可
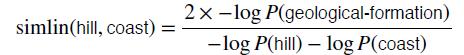
词义消歧Word Sense Disambiguation
• 任务:为句子中的单词选择正确的意义
• 基线:
‣ 假设最通俗的意义
• 良好的 词义消歧WSD 可能对许多任务有用
‣ 时下不太流行; 因为语义信息被上下文表征隐式地捕获了(在后面的文章会涉及)
有监督的WSD
• 应用标准机器分类器
• 特征向量通常是围绕目标的单词和语法
‣ 但是上下文也很模糊!
‣ 上下文窗口应该有多大? (实际上很小)
• 需要语义标记语料库
‣ 例如 SENSEVAL、SEMCOR(在 NLTK 中可用)
‣ 创建非常耗时!
无监督
lesk
• Lesk:选择 WordNet 词汇与上下文重叠最多的词义
Clustering
• 收集这个词的用法
• 对上下文词进行聚类以学习不同的意义
‣ 基本原理:同义的上下文词应该相似
• 缺点:
‣ 词义的集群不太好解释
‣ 需要符合字典的意思
总结
• 词汇数据库的创建涉及专家管理(语言学家)
• 现代方法试图直接从语料库中获取语义信息,无需人工干预
• 分布式语义(下一篇)
以上是关于第八篇:词汇语义的主要内容,如果未能解决你的问题,请参考以下文章