第十八篇:Question Answering问答系统
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十八篇:Question Answering问答系统相关的知识,希望对你有一定的参考价值。
目录
基于 IR 的 事实(Factoid) QA:TREC-QA
介绍
• 定义:问答(“QA”)是自动确定自然语言问题答案的任务
• 主要关注“事实”问题
事实问题
事实问题,有简短准确的答案。
非事实问题
一般的非事实问题需要更长的答案、批判性分析、总结、计算等。
为什么我们关注 NLP 中的事实问题?
• 他们更容易
• 他们有一个客观的答案
• 当前的 NLP 技术无法处理非事实的答案
• 对系统自动回答非事实问题的需求较少
2 种关键方法
• 基于信息检索的 QA
‣ 给定一个查询,搜索相关文档
‣ 在这些相关文档中查找答案
• 基于知识的QA
‣ 构建查询的语义表示
‣ 查询事实数据库以寻找答案
大纲
• IR-based QA
• Knowledge-based QA
• Hybrid QA
IR-based QA
基于 IR 的 事实(Factoid) QA:TREC-QA
1.使用问题去获得query,查询IR引擎
2. 查找文档,以及文档中的段落
3. 提取简答串
问题处理
• 找出有助于检索的问题的关键部分
‣ 丢弃非内容词/符号(wh-word、? 等)
‣ 制定为 tf-idf 查询,使用 unigrams 或 bigrams
‣ 识别实体并优先匹配
• 可以使用模板重新表述问题
‣ E.g. “Where is Federation Square located?”
‣ Query = “Federation Square located”
‣ Query = “Federation Square is located [in/at]”
• 预测预期答案类型(此处 = LOCATION)
答案类型
• 了解答案类型有助于:
‣ 找到包含答案的正确段落
‣ 查找答案字符串
• 分类处理
‣ 给定问题,预测答案类型
‣ 关键特征是问题的中心词
‣ 澳大利亚国徽上的动物是什么?
‣ 一般不难
检索
• 查找与查询匹配的前 n 个文档(标准 IR)
• 接下来查找这些文档中的段落(段落或句子)(也由 IR 驱动)
• 应包含:
‣ 问题关键字的许多实例
‣ 答案类型的几个命名实体
‣ 段落中这些术语的接近程度
‣ IR 引擎排名靠前
• 重新排列 IR 输出以找到最佳段落(例如,使用监督学习)
答案提取
• 找到问题的简明答案,作为文章的跨度
如何?
• 使用神经网络提取答案
• 又名阅读理解任务
• 但深度学习模型需要大量数据
• 我们是否有足够的数据来训练理解模型?
MCTest
• Crowdworkers 编写虚构的故事、问题和答案
• 500 个故事,2000 个问题
• 多项选择题
SQuAD
• 使用维基百科段落
• 第一组众包工作者提出问题(给定段落)
• 第二组众包工作者为答案贴上标签
• 15 万个问题(!)
• 第二个版本包含无法回答的问题
阅读理解
• 给定一个问题和上下文段落,预测答案跨度在段落中的开始和结束位置?
• 计算:
‣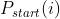 : 概率, 单词 i 是起始令牌
: 概率, 单词 i 是起始令牌
‣ 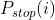 : 概率, 单词 i 是结束令牌
: 概率, 单词 i 是结束令牌
基于 LSTM 的模型
• 将问题标记提供给双向 LSTM
• 通过加权和聚合 LSTM 输出以产生 q ,即最终的问题嵌入
• 以类似的方式处理段落,使用另一个双向 LSTM
• 不仅仅是词嵌入作为输入
‣ 表示单词是否与疑问词匹配的特征
‣ POS 特征
‣ 加权问题嵌入:通过关注每个问题词产生
• {p1, . . . , pm} :来自双向 LSTM 的每个段落中单词的一个向量
• 计算每个单词的开始和结束概率:
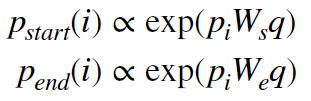
基于 BERT 的模型
• 微调 BERT 以预测答案跨度
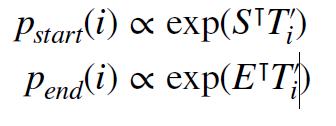
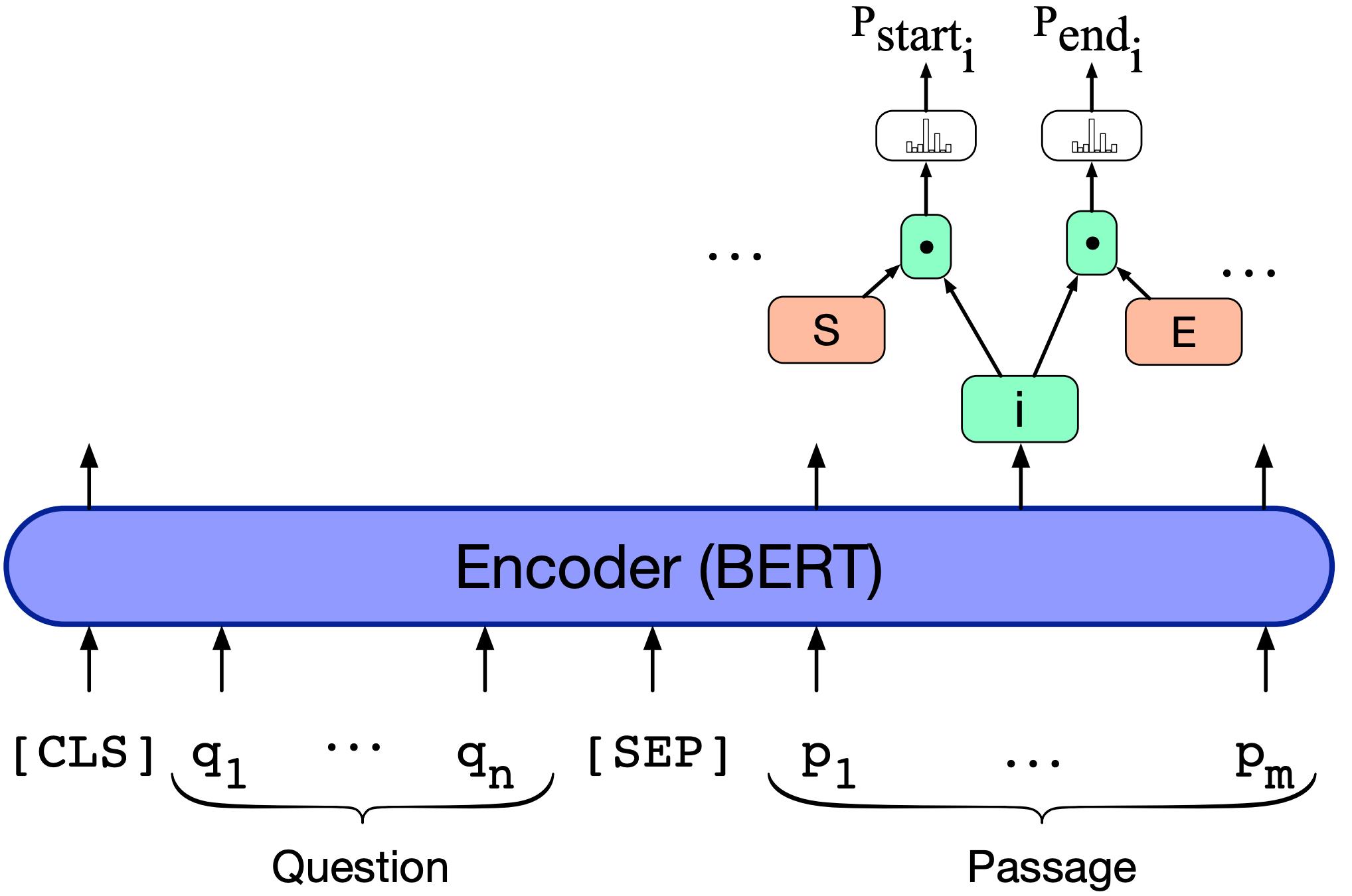
为什么 BERT 比 LSTM 效果更好?
• 它有更多的参数
• 它经过预先训练,因此在适应任务之前就已经“知道”语言
• 多头注意力是秘诀
• 自注意力架构允许在问题词和上下文段落之间进行细粒度分析
Knowledge-based QA
• 许多大型知识库
‣ Freebase、DBpedia、Yago 等
• 我们可以支持自然语言查询吗?
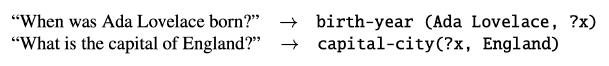
‣ 将“Ada Lovelace”与知识库中的正确实体链接以找到三元组(Ada Lovelace,出生年份,1815)
但是
• 将自然语言句子转换为三元组并非易事
![]()
• 实体链接也是一个重要组成部分
‣ 歧义:“洛夫莱斯是什么时候出生的?”
• 我们能否简化这两个步骤的过程?
语义解析
• 将问题转化为逻辑形式,直接查询知识库
‣ 谓词演算
‣ 编程查询(例如 SQL)
如何构建语义解析器?
• 文本到文本问题:
‣ 输入 = 自然语言句子
‣ 输出 = 逻辑形式的字符串
• 编码器-解码器模型(第 16 篇文章!)

Hybrid QA
• 为什么不同时使用基于文本和基于知识的资源进行 QA?
• IBM 的 Watson 赢得了游戏节目 Jeopardy! 使用各种资源来回答问题
Watson 核心理念
• 从基于文本和基于知识的来源生成大量候选答案
• 使用丰富多样的证据为他们评分
• 系统中的许多组件,大部分都经过单独培训
QA评估
• IR:返回匹配段落或答案字符串的系统的 MRR(平均倒数排名)
‣ 例如 系统为一个查询返回 4 个段落,第一个正确的段落是第 3 个段落
‣ MRR = ⅓
• MCTest:准确性
• SQuAD:字符串与黄金答案的精确匹配
最后
• 基于 IR 的 QA:搜索文本资源以回答问题
‣阅读理解:假设问题+段落
• 基于知识的 QA:搜索结构化资源以回答问题
• 热点领域:一直在创建许多新方法和评估数据集(叙事、QA、常识推理等)
OK,QA就倒这里了,辛苦观看,有问题随时评论哦!
以上是关于第十八篇:Question Answering问答系统的主要内容,如果未能解决你的问题,请参考以下文章