lDA主题模型最少需要多少数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lDA主题模型最少需要多少数据相关的知识,希望对你有一定的参考价值。
参考技术A 1. LDA主题数量,多少个才是最优的。2. 作出主题之后,主题-主题,主题与词语之间关联如何
机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)(代码
函数说明
1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题
参数说明:n_topics 表示分为多少个主题, max_iters表示最大的迭代次数, random_state 表示随机种子
2. LDA.components_ 打印输入特征的权重参数,
LDA主题模型:可以用于做分类,好比如果是两个主题的话,那就相当于是分成了两类,同时我们也可以找出根据主题词的权重值,来找出一些主题的关键词
使用sklearn导入库
from sklearn.decomposition import LatentDirichletAllocation, 使用方法还是fit_transform
LDA.components_ 打印出各个参数的权重值,这个权重值是根据数据特征的标签来进行排列的
代码:
第一步:Dataframe化数据
第二步:进行分词和停用词的去除,使用\' \'.join 为了词袋模型做准备
第三步:使用np.vectorizer对函数进行向量化处理,调用定义的函数进行分词和停用词的去除
第四步:使用Tf-idf 函数构建词袋模型
第五步:使用LatentDirichletAllocation构建LDA模型,并进行0,1标签的数字映射
第六步:使用LDA.components_打印输入特征标签的权重得分,去除得分小于0.6的得分,我们可以看出哪些词是主要的关键字
import pandas as pd import numpy as np import re import nltk #pip install nltk corpus = [\'The sky is blue and beautiful.\', \'Love this blue and beautiful sky!\', \'The quick brown fox jumps over the lazy dog.\', \'The brown fox is quick and the blue dog is lazy!\', \'The sky is very blue and the sky is very beautiful today\', \'The dog is lazy but the brown fox is quick!\' ] labels = [\'weather\', \'weather\', \'animals\', \'animals\', \'weather\', \'animals\'] # 第一步:构建DataFrame格式数据 corpus = np.array(corpus) corpus_df = pd.DataFrame({\'Document\': corpus, \'categoray\': labels}) # 第二步:构建函数进行分词和停用词的去除 # 载入英文的停用词表 stopwords = nltk.corpus.stopwords.words(\'english\') # 建立词分割模型 cut_model = nltk.WordPunctTokenizer() # 定义分词和停用词去除的函数 def Normalize_corpus(doc): # 去除字符串中结尾的标点符号 doc = re.sub(r\'[^a-zA-Z0-9\\s]\', \'\', string=doc) # 是字符串变小写格式 doc = doc.lower() # 去除字符串两边的空格 doc = doc.strip() # 进行分词操作 tokens = cut_model.tokenize(doc) # 使用停止用词表去除停用词 doc = [token for token in tokens if token not in stopwords] # 将去除停用词后的字符串使用\' \'连接,为了接下来的词袋模型做准备 doc = \' \'.join(doc) return doc # 第三步:向量化函数和调用函数 # 向量化函数,当输入一个列表时,列表里的数将被一个一个输入,最后返回也是一个个列表的输出 Normalize_corpus = np.vectorize(Normalize_corpus) # 调用函数进行分词和去除停用词 corpus_norm = Normalize_corpus(corpus) # 第四步:使用TfidVectorizer进行TF-idf词袋模型的构建 from sklearn.feature_extraction.text import TfidfVectorizer Tf = TfidfVectorizer(use_idf=True) Tf.fit(corpus_norm) vocs = Tf.get_feature_names() corpus_array = Tf.transform(corpus_norm).toarray() corpus_norm_df = pd.DataFrame(corpus_array, columns=vocs) print(corpus_norm_df.head()) # 第五步:构建LDA主题模型 from sklearn.decomposition import LatentDirichletAllocation LDA = LatentDirichletAllocation(n_topics=2, max_iter=100, random_state=42) LDA_corpus = np.array(LDA.fit_transform(corpus_array)) LDA_corpus_one = np.zeros([LDA_corpus.shape[0]]) LDA_corpus_one[LDA_corpus[:, 0] < LDA_corpus[:, 1]] = 1 corpus_norm_df[\'LDA_labels\'] = LDA_corpus_one print(corpus_norm_df.head())
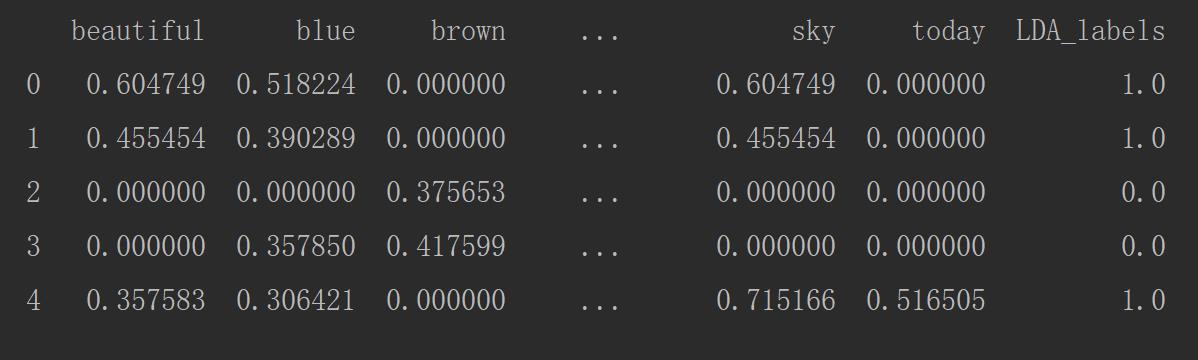
# 第六步:打印每个单词的主题的权重值 tt_matrix = LDA.components_ for tt_m in tt_matrix: tt_dict = [(name, tt) for name, tt in zip(vocs, tt_m)] tt_dict = sorted(tt_dict, key=lambda x: x[1], reverse=True) # 打印权重值大于0.6的主题词 tt_dict = [tt_threshold for tt_threshold in tt_dict if tt_threshold[1] > 0.6] print(tt_dict)
![]()
大于0.6权重得分的部分特征
以上是关于lDA主题模型最少需要多少数据的主要内容,如果未能解决你的问题,请参考以下文章
机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)(代码
在PYTHON中使用TMTOOLKIT进行主题模型LDA评估