深入解读 Flink SQL 1.13
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解读 Flink SQL 1.13相关的知识,希望对你有一定的参考价值。
简介: Apache Flink 社区 5 月 22 日北京站 Meetup 分享内容整理,深入解读 Flink SQL 1.13 中 5 个 FLIP 的实用更新和重要改进。
本文由社区志愿者陈政羽整理,Apache Flink 社区在 5 月份发布了 1.13 版本,带来了很多新的变化。文章整理自徐榜江(雪尽) 5 月 22 日在北京的 Flink Meetup 分享的《深入解读 Flink SQL 1.13》,内容包括:
- Flink SQL 1.13 概览
- 核心 feature 解读
- 重要改进解读
- Flink SQL 1.14 未来规划
- 总结
GitHub 地址
https://github.com/apache/flink
欢迎大家给 Flink 点赞送 star~
一、Flink SQL 1.13 概览

Flink 1.13 是一个社区大版本,解决的 issue 在 1000 个以上,通过上图我们可以看到,解决的问题大部分是关于 Table/SQL 模块,一共 400 多个 issue 占了总体的 37% 左右。这些 issue 主要围绕了 5 个 FLIP 展开,在本文中我们也会根据这 5 个方面进行介绍,它们分别是:
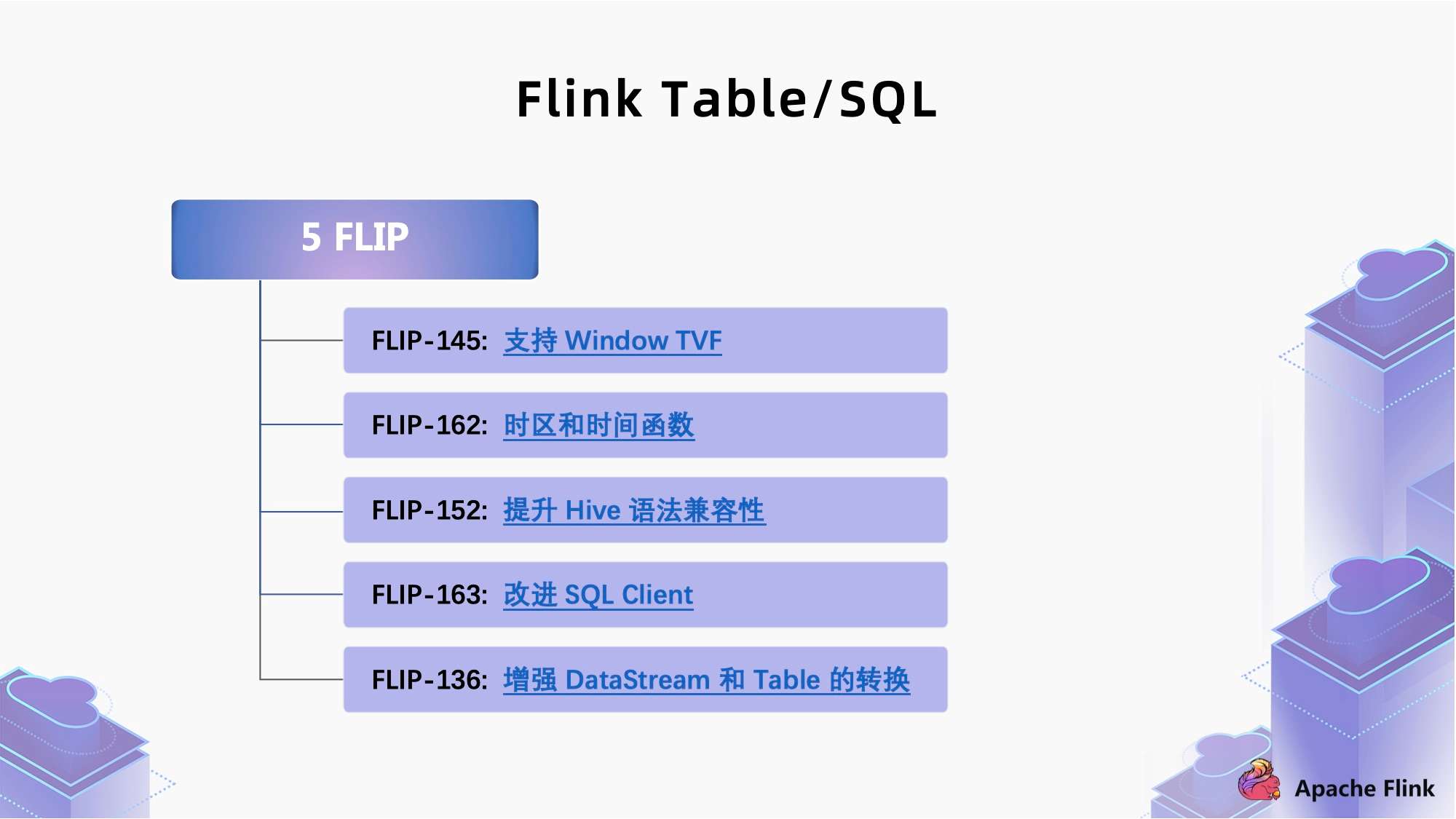
下面我们对这些 FLIP 进行详细解读。
二、 核心 feature 解读
1. FLIP-145:支持 Window TVF
社区的小伙伴应该了解,在腾讯、阿里巴巴、字节跳动等公司的内部分支已经开发了这个功能的基础版本。这次 Flink 社区也在 Flink 1.13 推出了 TVF 的相关支持和优化。下面将从 Window TVF 语法、近实时累计计算场景、 Window 性能优化、多维数据分析,来分析这个新功能。

1.1 Window TVF 语法
在 1.13 版本前,window 的实现是通过一个特殊的 SqlGroupedWindowFunction:
SELECT
TUMBLE_START(bidtime,INTERVAL '10' MINUTE),
TUMBLE_END(bidtime,INTERVAL '10' MINUTE),
TUMBLE_ROWTIME(bidtime,INTERVAL '10' MINUTE),
SUM(price)
FROM MyTable
GROUP BY TUMBLE(bidtime,INTERVAL '10' MINUTE)在 1.13 版本中,我们对它进行了 Table-Valued Function 的语法标准化:
SELECT WINDOW_start,WINDOW_end,WINDOW_time,SUM(price)
FROM Table(TUMBLE(Table myTable,DESCRIPTOR(biztime),INTERVAL '10' MINUTE))
GROUP BY WINDOW_start,WINDOW_end通过对比两种语法,我们可以发现:TVF 语法更加灵活,不需要必须跟在 GROUP BY 关键字后面,同时 Window TVF 基于关系代数,使得其更加标准。在只需要划分窗口场景时,可以只用 TVF,无需用 GROUP BY 做聚合,这使得 TVF 扩展性和表达能力更强,支持自定义 TVF(例如实现 TOP-N 的 TVF)。

上图中的示例就是利用 TVF 做的滚动窗口的划分,只需要把数据划分到窗口,无需聚合;如果后续需要聚合,再进行 GROP BY 即可。同时,对于熟悉批 SQL 的用户来说,这种操作是非常自然的,我们不再需要像 1.13 版本之前那样必须要用特殊的 SqlGroupedWindowFunction 将窗口划分和聚合绑定在一起。
目前 Window TVF 支持 tumble window,hop window,新增了 cumulate window;session window 预计在 1.14 版本也会支持。
1.2 Cumulate Window
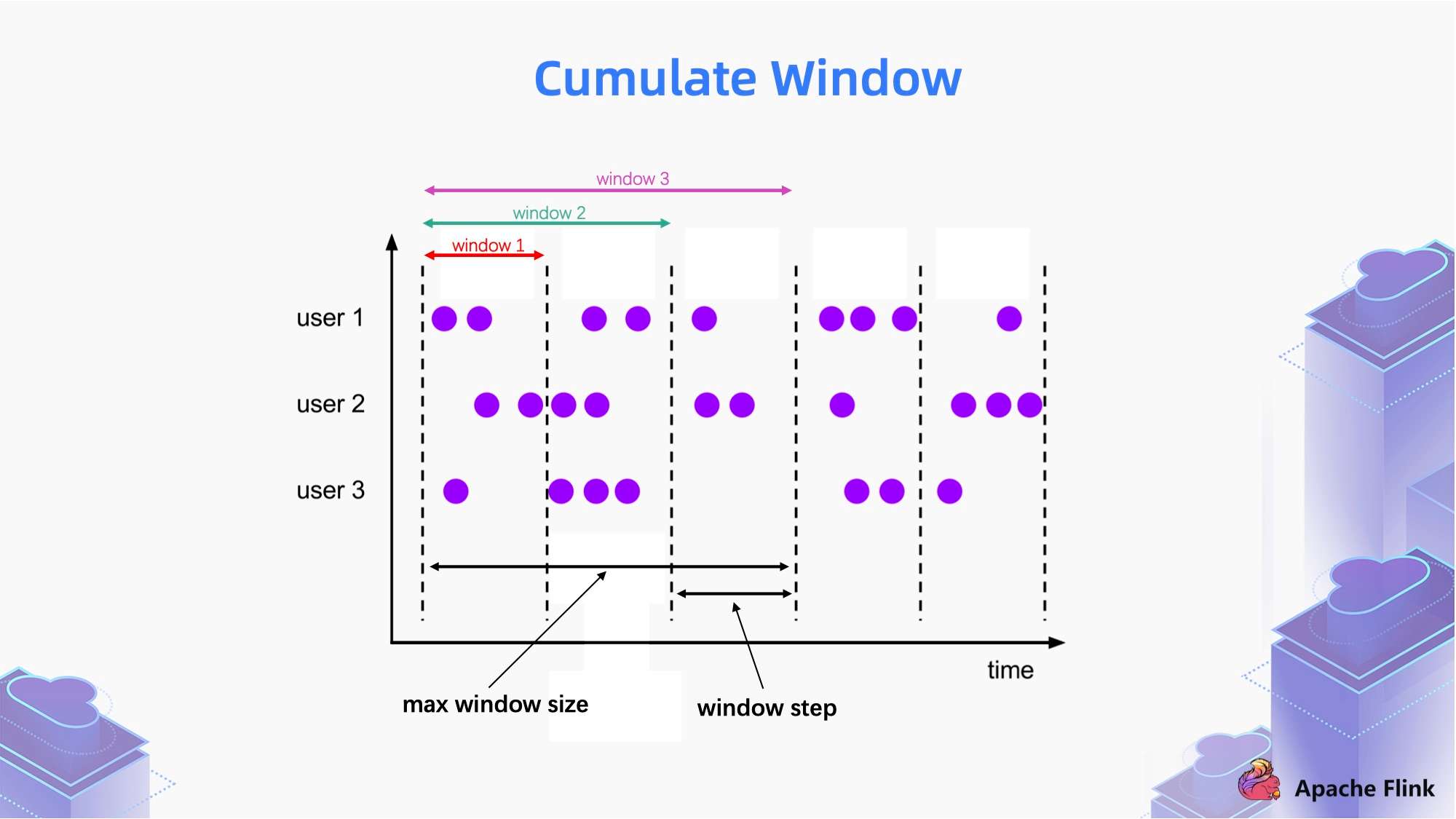
Cumulate window 就是累计窗口,简单来说,以上图里面时间轴上的一个区间为窗口步长。
- 第一个 window 统计的是一个区间的数据;
- 第二个 window 统计的是第一区间和第二个区间的数据;
- 第三个 window 统计的是第一区间,第二个区间和第三个区间的数据。
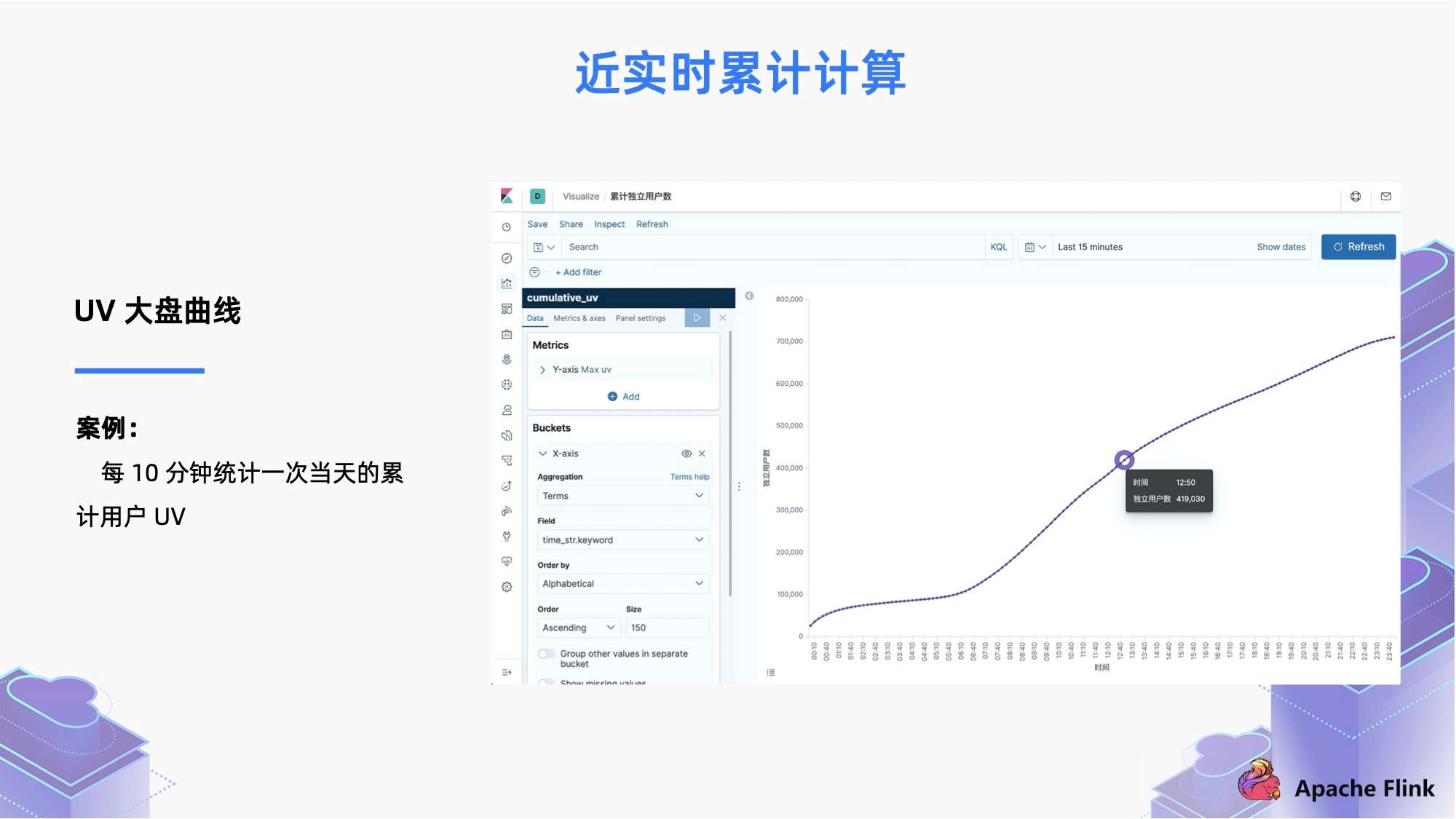
累积计算在业务场景中非常常见,如累积 UV 场景。在 UV 大盘曲线中:我们每隔 10 分钟统计一次当天累积用户 UV。

在 1.13 版本之前,当需要做这种计算时,我们一般的 SQL 写法如下:
INSERT INTO cumulative_UV
SELECT date_str,MAX(time_str),COUNT(DISTINCT user_id) as UV
FROM (
SELECT
DATE_FORMAT(ts,'yyyy-MM-dd') as date_str,
SUBSTR(DATE_FORMAT(ts,'HH:mm'),1,4) || '0' as time_str,
user_id
FROM user_behavior
)
GROUP BY date_str先将每条记录所属的时间窗口字段拼接好,然后再对所有记录按照拼接好的时间窗口字段,通过 GROUP BY 做聚合,从而达到近似累积计算的效果。
- 1.13 版本前的写法有很多缺点,首先这个聚合操作是每条记录都会计算一次。其次,在追逆数据的时候,消费堆积的数据时,UV 大盘的曲线就会跳变。
- 在 1.13 版本支持了 TVF 写法,基于 cumulate window,我们可以修改为下面的写法,将每条数据按照 Event Time 精确地分到每个 Window 里面, 每个窗口的计算通过 watermark 触发,即使在追数据场景中也不会跳变。
INSERT INTO cumulative_UV
SELECT WINDOW_end,COUNT(DISTINCT user_id) as UV
FROM Table(
CUMULATE(Table user_behavior,DESCRIPTOR(ts),INTERVAL '10' MINUTES,INTERVAL '1' DAY))
)
GROUP BY WINDOW_start,WINDOW_endUV 大盘曲线效果如下图所示:
1.3 Window 性能优化
Flink 1.13 社区开发者们对 Window TVF 进行了一系列的性能优化,包括:
- 内存优化:通过内存预分配,缓存 window 的数据,通过 window watermark 触发计算,通过申请一些内存 buffer 避免高频的访问 state;
- 切片优化:将 window 切片,尽可能复用已计算结果,如 hop window,cumulate window。计算过的分片数据无需再次计算,只需对切片的计算结果进行复用;
- 算子优化:window 算子支持 local-global 优化;同时支持 count(distinct) 自动解热点优化;
- 迟到数据:支持将迟到数据计算到后续分片,保证数据准确性。

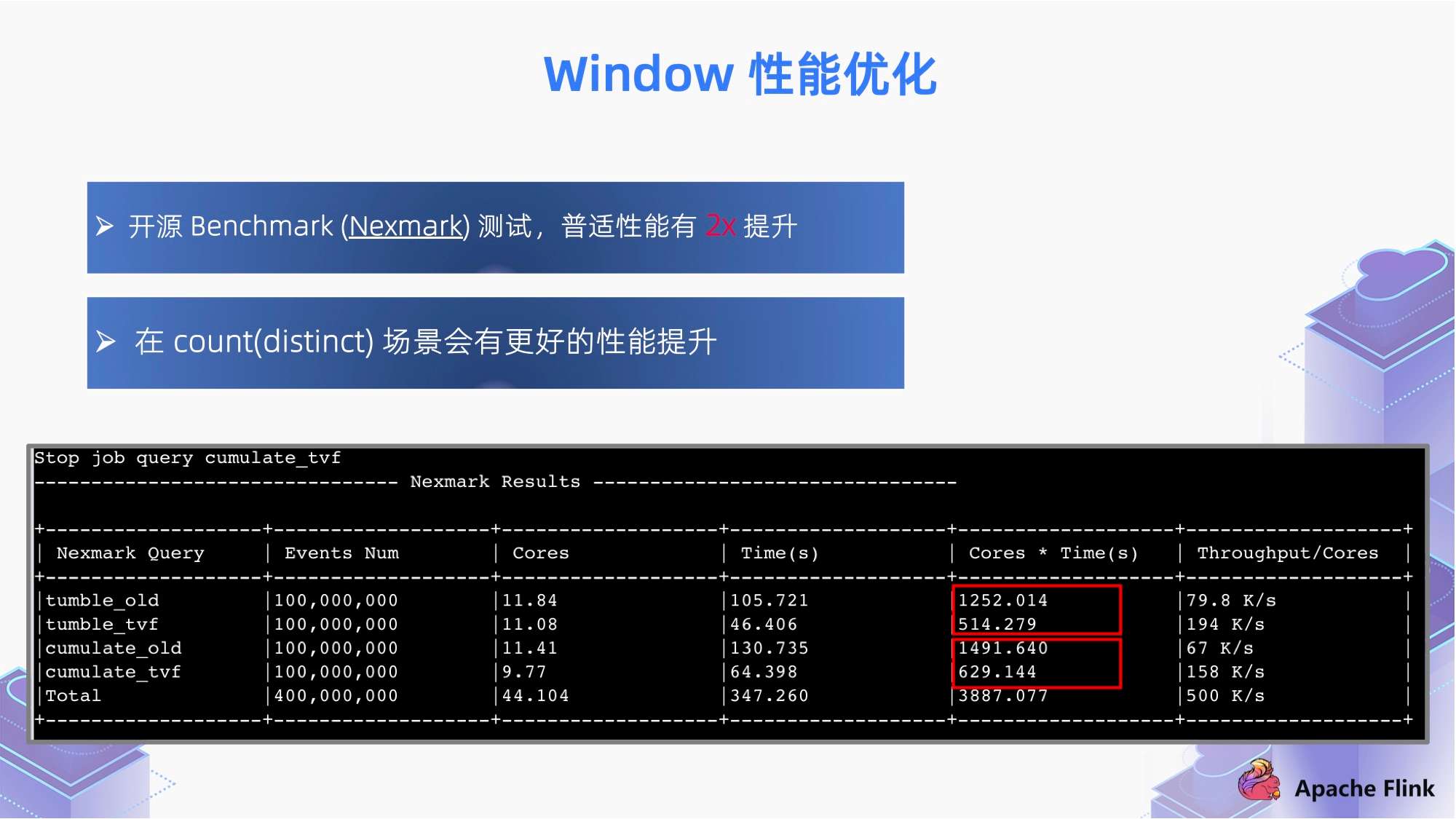
基于这些优化,我们通过开源 Benchmark (Nexmark) 进行性能测试。结果显示 window 的普适性能有 2x 提升,且在 count(distinct) 场景会有更好的性能提升。
1.4 多维数据分析
语法的标准化带来了更多的灵活性和扩展性,用户可以直接在 window 窗口函数上进行多维分析。如下图所示,可以直接进行 GROUPING SETS、ROLLUP、CUBE 的分析计算。如果是在 1.13 之前的版本,我们可能需要对这些分组进行单独的 SQL 聚合,再对聚合结果做 union 操作才能达到类似的效果。而现在,类似这种多维分析的场景,可以直接在 window TVF 上支持。

支持 Window Top-N
除了多维分析,Window TVF 也支持 Top-N 语法,使得在 Window 上取 Top-N 的写法更加简单。

2. FLIP-162:时区和时间函数
2.1 时区问题分析
大家在使用 Flink SQL 时反馈了很多时区相关的问题,造成时区问题的原因可以归纳为 3 个:
- PROCTIME() 函数应该考虑时区,但未考虑时区;
- CURRENT_TIMESTAMP/CURRENT_TIME/CURRENT_DATE/NOW() 函数未考虑时区;
- Flink 的时间属性,只支持定义在 TIMESTAMP 这种数据类型上面,这个类型是无时区的,TIMESTAMP 类型不考虑时区,但用户希望是本地时区的时间。

针对 TIMESTAMP 类型没有考虑时区的问题,我们提议通过TIMESTAMP_LTZ类型支持 (TIMESTAMP_LTZ 是 timestamp with local time zone 的缩写)。可以通过下面的表格来进行和 TIMESTAMP 的对比:

TIMESTAMP_LTZ 区别于之前我们使用的 TIMESTAMP,它表示绝对时间的含义。通过对比我们可以发现:
- 如果我们配置使用 TIMESTAMP,它可以是字符串类型的。用户不管是从英国还是中国时区来观察,这个值都是一样的;
- 但是对于 TIMSTAMP_TLZ 来说,它的来源就是一个 Long 值,表示从时间原点流逝过的时间。同一时刻,从时间原点流逝的时间在所有时区都是相同的,所以这个 Long 值是绝对时间的概念。当我们在不同的时区去观察这个值,我们会用本地的时区去解释成 “年-月-日-时-分-秒” 的可读格式,这就是 TIMSTAMP_TLZ 类型,TIMESTAMP_LTZ 类型也更加符合用户在不同时区下的使用习惯。
下面的例子展示了 TIMESTAMP 和 TIMESTAMP_LTZ 两个类型的区别。

2.2 时间函数纠正
订正 PROCTIME() 函数
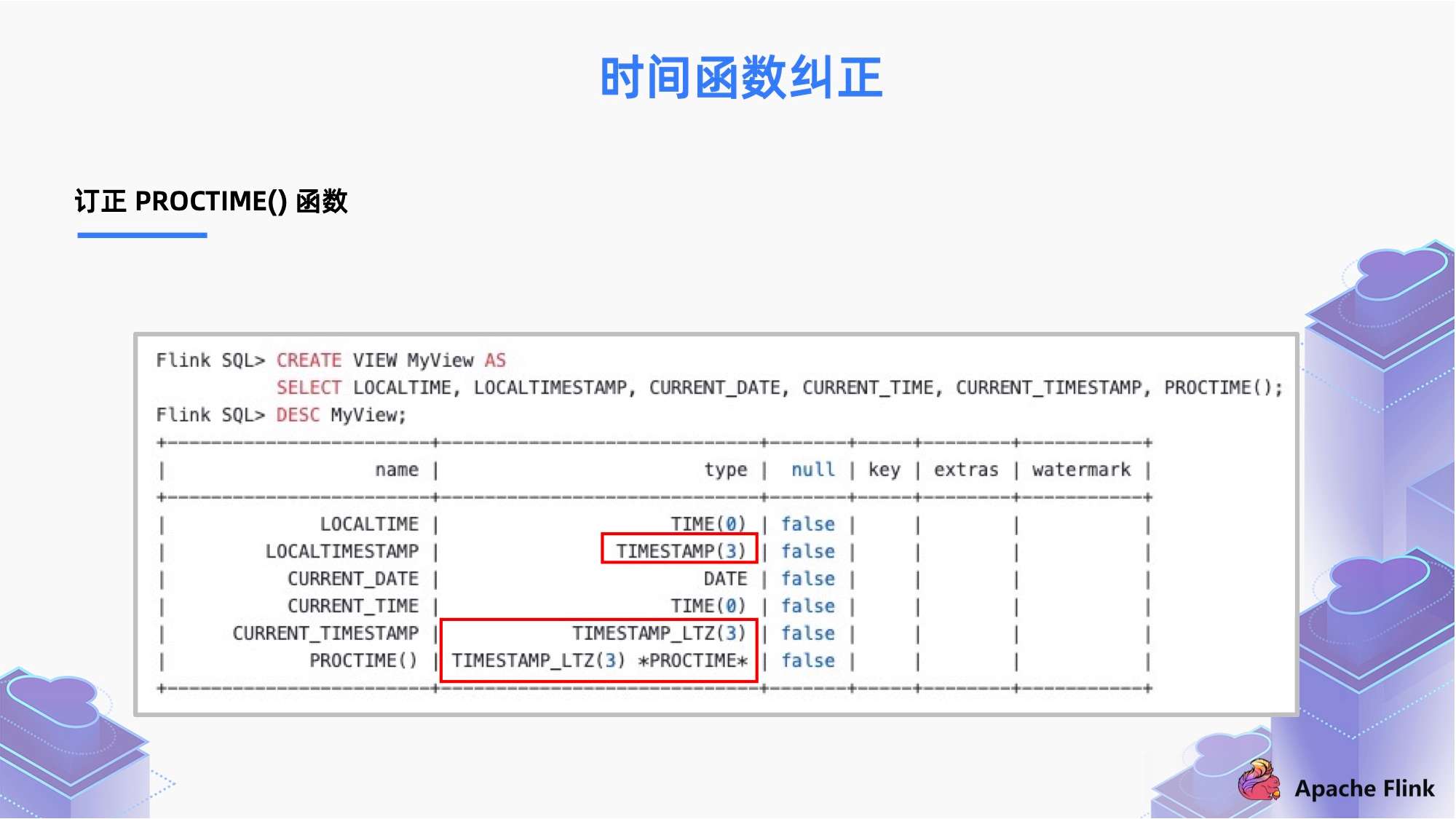
当我们有了 TIMESTAMP_LTZ 这个类型的时候,我们对 PROCTIME() 类型做了纠正:在 1.13 版本之前,它总是返回 UTC 的 TIMESTAMP;而现在,我们把返回类型变为了 TIMESTAMP_LTZ。PROCTIME 除了表示函数之外,也可以表示时间属性的标记。
订正 CURRENT_TIMESTAMP/CURRENT_TIME/CURRENT_DATE/NOW() 函数
这些函数在不同时区下出来的值是会发生变化的。例如在英国 UTC 时区时候是凌晨 2 点;但是如果你设置了时区是 UTC+8,时间就是在早上的 10 点。不同时区的实际时间会发生变化,效果如下图:

解决 processing time Window 时区问题
大家都知道 proctime 可以表示一个时间属性,对 proctime 的 window 操作:
- 在 1.13 版本之前,如果我们需要做按天的 window 操作,你需要手动解决时区问题,去做一些 8 小时的偏移然后再减回去;
- 在 FLIP-162 中我们解决了这个问题,现在用户使用的时候十分简单,只需要声明 proctime 属性,因为 PROCTIME() 函数的返回值是TIMESTAMP_LTZ,所以结果是会考虑本地的时区。下图的例子显示了在不同的时区下,proctime 属性的 window 的聚合是按照本地时区进行的。

订正 Streaming 和 Batch 模式下函数取值方式
时间函数其实在流和批上面的表现形式会有所区别,这次修正主要是让其更加符合用户实际的使用习惯。例如以下函数:
- 在流模式中是 per-record 计算,即每条数据都计算一次;
- 在 Batch 模式是 query-start 计算,即在作业开始前计算一次。例如我们常用的一些 Batch 计算引擎,如 Hive 也是在每一个批开始前计算一次。

2.3 时间类型使用
在 1.13 版本也支持了在 TIMESTAMP 列上定义 Event time,也就是说Event time 现在既支持定义在 TIMESTAMP 列上,也支持定义在 TIMESTAMP_ LTZ 列上。那么作为用户,具体什么场景用什么类型呢?
- 当作业的上游源数据包含了字符串的时间(如:2021-4-15 14:00:00)这样的场景,直接声明为 TIMESTAMP 然后把 Event time 定义在上面即可,窗口在计算的时候会基于时间字符串进行切分,最终会计算出符合你实际想要的预想结果;

- 当上游数据源的打点时间属于 long 值,表示的是一个绝对时间的含义。在 1.13 版本你可以把 Event time 定义在 TIMESTAMP_LTZ 上面。此时定义在 TIMESTAMP_LTZ 类型上的各种 WINDOW 聚合,都能够自动的解决 8 小时的时区偏移问题,无需按照之前的 SQL 写法额外做时区的修改和订正。

小提示:Flink SQL 中关于时间函数,时区支持的这些提升,是版本不兼容的。用户在进行版本更新的时候需要留意作业逻辑中是否包含此类函数,避免升级后业务受到影响。
2.4 夏令时支持

在 Flink 1.13 以前,对于国外夏令时时区的用户,做窗口相关的计算操作是十分困难的一件事,因为存在夏令时和冬令时切换的跳变。
Flink 1.13 通过支持在 TIMESTAMP_LTZ 列上定义时间属性,同时 Flink SQL 在 WINDOW 处理时巧妙地结合 TIMESTAMP 和 TIMESTAMP_LTZ 类型,优雅地支持了夏令时。这对国外夏令时时区用户,以及有海外业务场景的公司比较有用。
三、重要改进解读
1. FLIP-152:提升 Hive 语法兼容性
FLIP-152 主要是做了 Hive 语法的兼容性增强,支持了 Hive 的一些常用 DML 和 DQL 语法,包括:

通过 Hive dialect 支持 Hive 常用语法。Hive 有很多的内置函数,Hive dialect 需要配合 HiveCatalog 和 Hive Module 一起使用,Hive Module 提供了 Hive 所有内置函数,加载后可以直接访问。

与此同时,我们还可以通过 Hive dialect 创建/删除 Catalog 函数以及一些自定义的函数,这样使得 Flink SQL 与 Hive 的兼容性得到了极大的提升,让熟悉 Hive 的用户使用起来会更加方便。

2. FLIP-163:改进 SQL Client
在 1.13 版本之前,大家觉得 Flink SQL Client 就是周边的一个小工具。但是,FLIP-163 在 1.13 版本进行了重要改进:

- 通过 -i 的参数,提前把 DDL 一次性加载初始化,方便初始化表的多个 DDL 语句,不需要多次执行命令创建表,替代了之前用 yaml 文件方式创建表;
- 支持 -f 参数,其中 SQL 文件支持 DML(insert into)语句;
-
支持更多实用的配置:
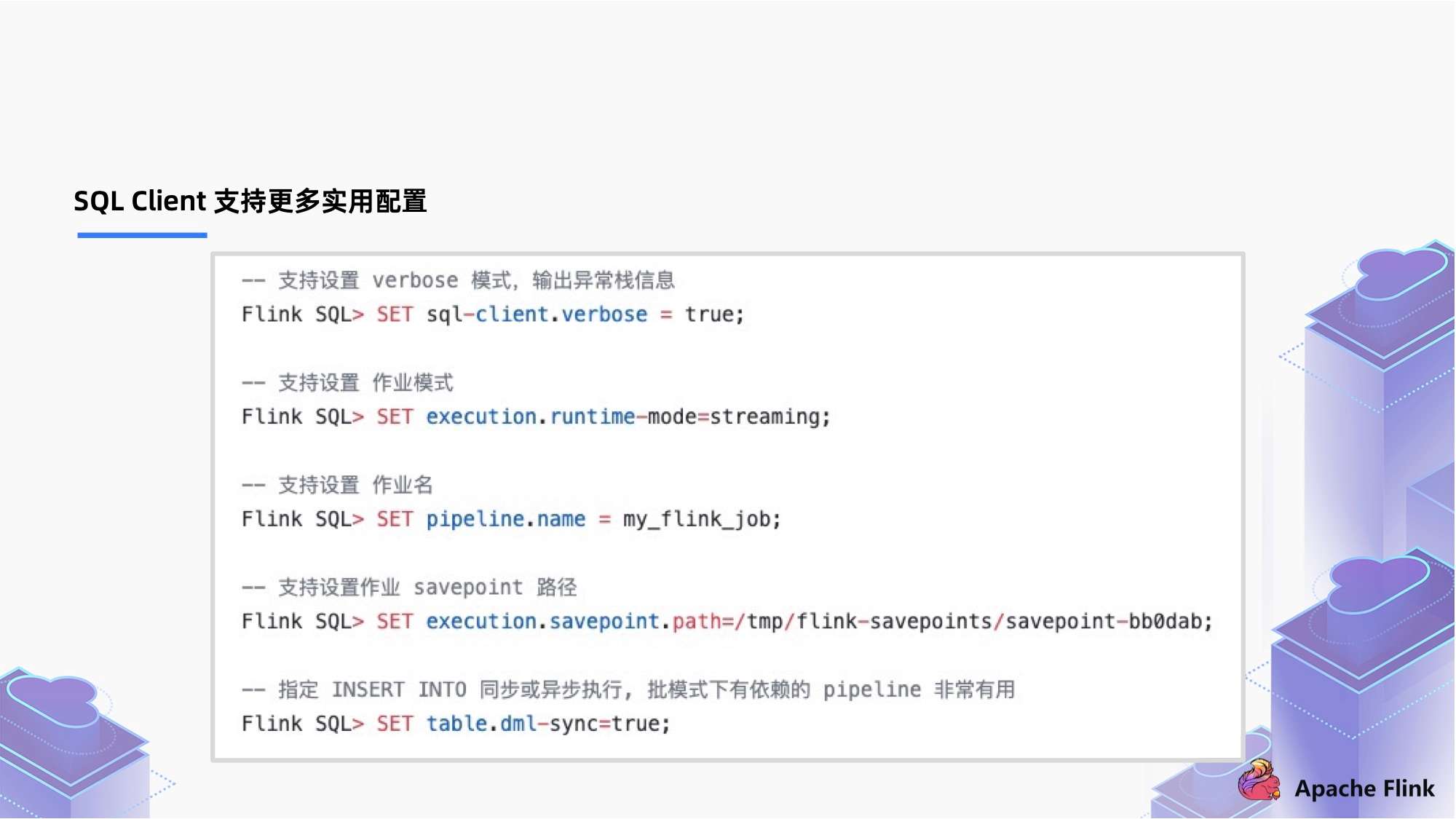
- 通过 SET SQL-client.verbose = true , 开启 verbose,通过开启 verbose 打印整个信息,相对以前只输出一句话更加容易追踪错误信息;
- 通过 SET execution.runtime-mode=streaming / batch 支持设置批/流作业模式;
- 通过 SET pipline.name=my_Flink_job 设置作业名称;
- 通过 SET execution.savepoint.path=/tmp/Flink-savepoints/savepoint-bb0dab 设置作业 savepoint 路径;
- 对于有依赖的多个作业,通过 SET Table.dml-sync=true 去选择是否异步执行,例如离线作业,作业 a 跑完才能跑作业 b ,通过设置为 true 实现执行有依赖关系的 pipeline 调度。
-
同时支持 STATEMENT SET语法:

有可能我们的一个查询不止写到一个 sink 里面,而是需要输出到多个 sink,比如一个 sink 写到 jdbc,一个 sink 写到 HBase。
- 在 1.13 版本之前需要启动 2 个 query 去完成这个作业;
- 在 1.13 版本,我们可以把这些放到一个 statement 里面,以一个作业的方式去执行,能够实现节点的复用,节约资源。
3. FLIP-136:增强 DataStream 和 Table 的转换
虽然 Flink SQL 大大降低了我们使用实时计算的一些使用门槛,但 Table/SQL 这种高级封装也屏蔽了一些底层实现,如 timer,state 等。不少高级用户希望能够直接操作 DataStream 获得更多的灵活性,这就需要在 Table 和 DataStream 之间进行转换。FLIP-136 增强了 Table 和 DataStream 间的转换,使得用户在两者之间的转换更加容易。
- 支持 DataStream 和 Table 转换时传递 EVENT TIME 和 WATERMARK;
Table Table = TableEnv.fromDataStream(
dataStream,
Schema.newBuilder()
.columnByMetadata("rowtime","TIMESTMP(3)")
.watermark("rowtime","SOURCE_WATERMARK()")
.build());
)- 支持 Changelog 数据流在 Table 和 DataStream 间相互转换。
//DATASTREAM 转 Table
StreamTableEnvironment.fromChangelogStream(DataStream<ROW>): Table
StreamTableEnvironment.fromChangelogStream(DataStream<ROW>,Schema): Table
//Table 转 DATASTREAM
StreamTableEnvironment.toChangelogStream(Table): DataStream<ROW>
StreamTableEnvironment.toChangelogStream(Table,Schema): DataStream<ROW> 四、Flink SQL 1.14 未来规划
1.14 版本主要有以下几点规划:
- 删除 Legacy Planner:从 Flink 1.9 开始,在阿里贡献了 Blink-Planner 之后,很多一些新的 Feature 已经基于此 Blink Planner 进行开发,以前旧的 Legacy Planner 会彻底删除;
- 完善 Window TVF:支持 session window,支持 window TVF 的 allow -lateness 等;
- 提升 Schema Handling:全链路的 Schema 处理能力以及关键校验的提升;
- 增强 Flink CDC 支持:增强对上游 CDC 系统的集成能力,Flink SQL 内更多的算子支持 CDC 数据流。
五、总结
本文详细解读了 Flink SQL 1.13 的核心功能和重要改进。
- 支持 Window TVF;
- 系统地解决时区和时间函数问题;
- 提升 Hive 和 Flink 的兼容性;
- 改进 SQL Client;
- 增强 DataStream 和 Table 的转换。
同时还分享了社区关于 Flink SQL 1.14 的未来规划,相信看完文章的同学可以对 Flink SQL 在这个版本中的变化有更多的了解,在实践过程中大家可以多多关注这些新的改动和变化,感受它们所带来的业务层面上的便捷。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于深入解读 Flink SQL 1.13的主要内容,如果未能解决你的问题,请参考以下文章
Apache Flink Meetup,1.13 新版本发布 x 互娱场景实践分享的开发者盛筵!
回顾 | Apache Flink 1.13 新版本 x 互娱实践分享 Meetup · 北京站精彩回顾 (附 PPT 下载)