一图胜千言:大数据入门必备的15张数据流转图(建议收藏)
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一图胜千言:大数据入门必备的15张数据流转图(建议收藏)相关的知识,希望对你有一定的参考价值。
前言
大家好,我是ChinaManor,直译过来就是中国码农的意思,我希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
以下是我在学大数据时学大数据不得不背的15张数据流转图
首先必须给HDFS读写数据图排面,学习大数据开发第一座的大山!
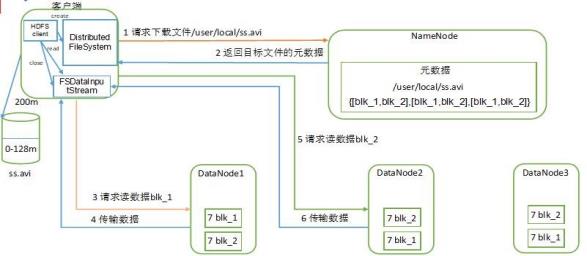
1.HDFS读写数据
HDFS读数据图:
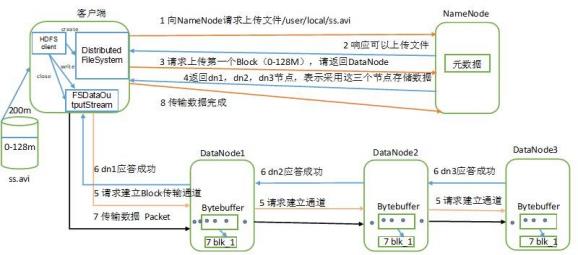
HDFS写数据图:
MR的洗牌机制也是绕不过去的
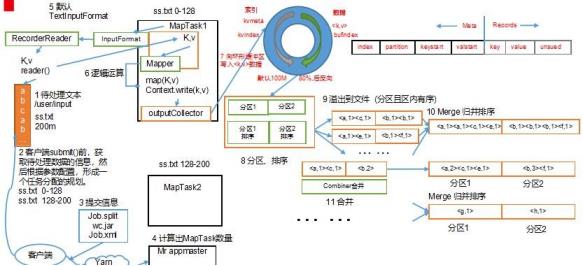
2.MapReduce 的 Shuffle 过程
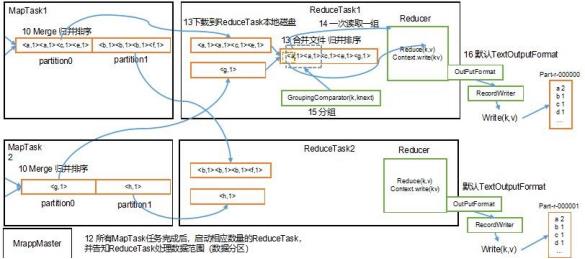
MapReduce 的详细工作流程:
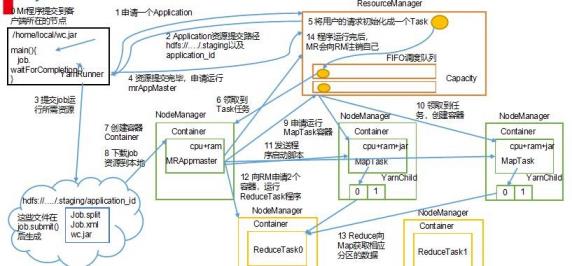
3.Yarn的Job提交流程
4.Yarn 的调度器分类
FIFO 调度器(先进先出调度器)
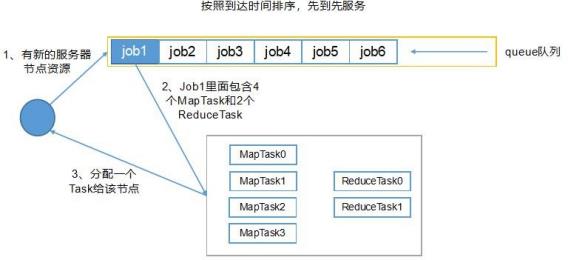
Capacity Scheduler(容量调度器)

Fair Sceduler(公平调度器)

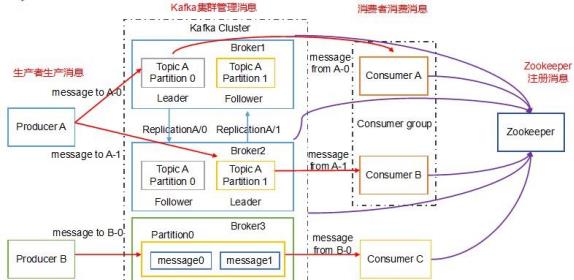
5.Kafka 架构图
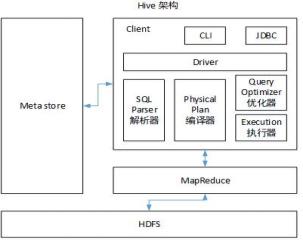
6.Hive架构图
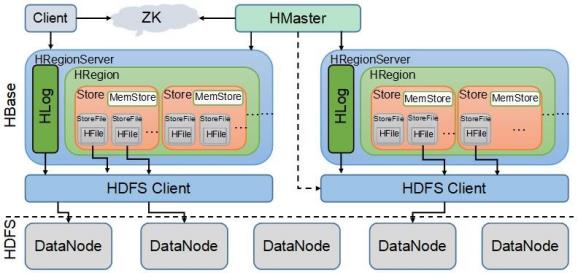
7.HBase存储结构图
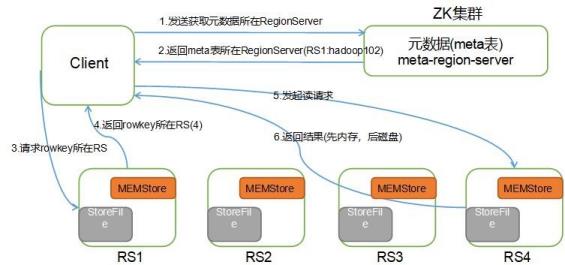
HBase读流程
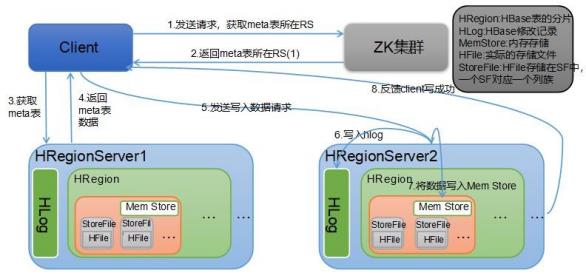
HBase读流程
Hadoop体系完了,下面是Spark和Flink体系
loading>>>>>>>>>>
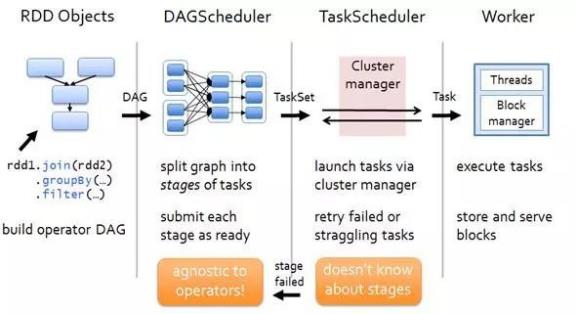
8.Spark 的架构与作业提交流程
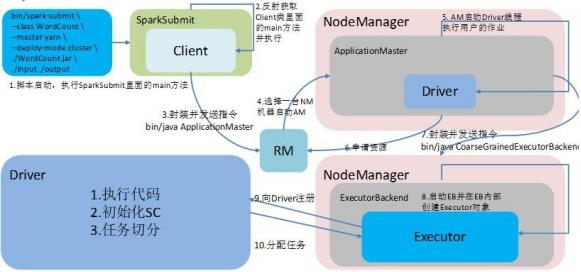
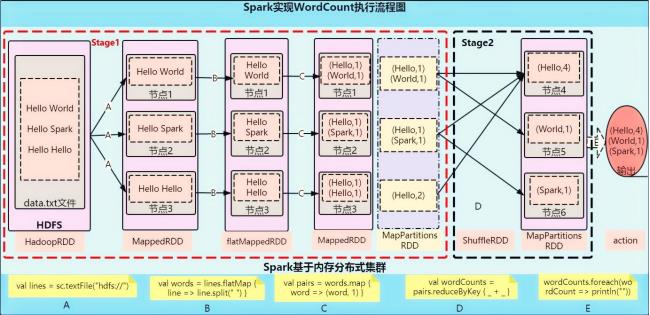
Spark实现WordCount执行流程图
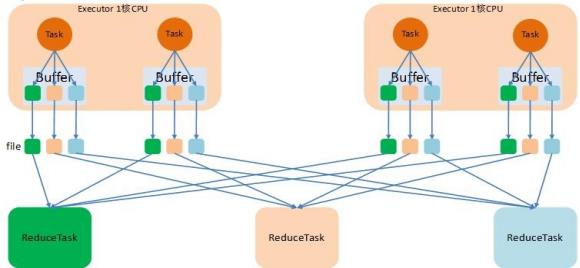
9.Spark 的 两 种 核 心 Shuffle ( HashShuffle 与SortShuffle)的工作流程
(1)未经优化的 HashShuffle
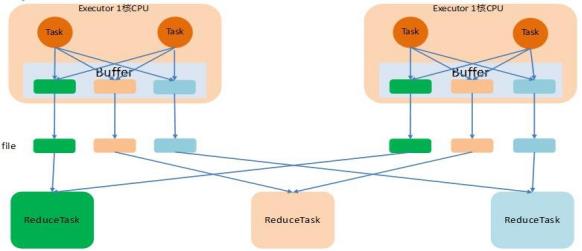
优化后的HashShuffle
(2)普通的 SortShuffle:
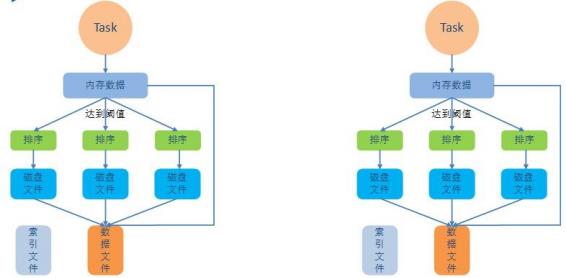
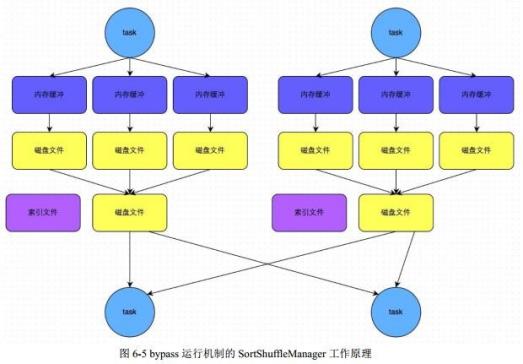
开启bypass机制后:
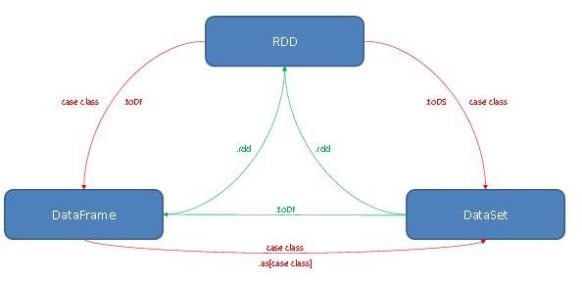
10.SparkSQL 中 RDD、DataFrame、DataSet 三者的区别与联系图解
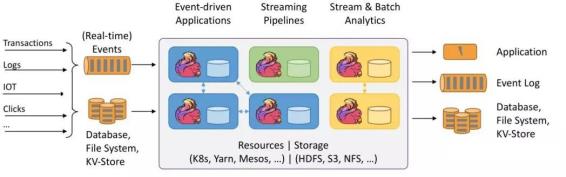
11.Flink架构模型图
12.Flink任务调度图
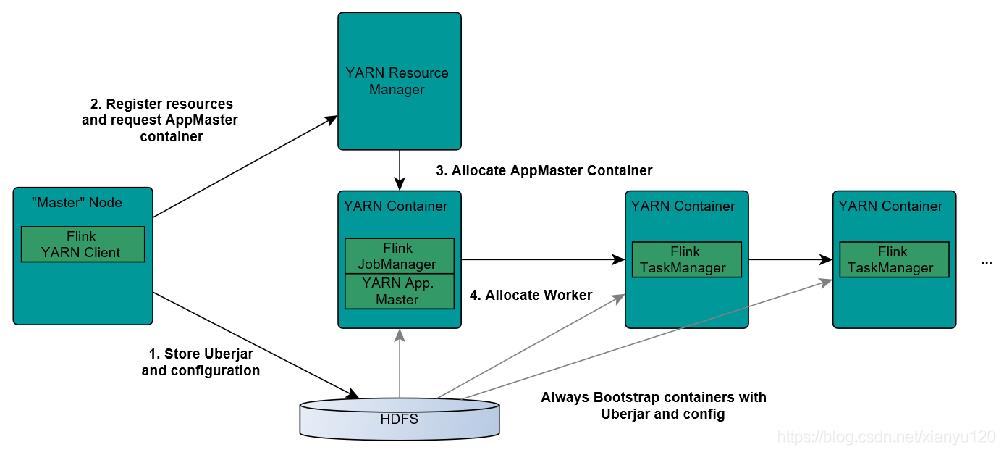
13.Flink On Yarn执行流程图
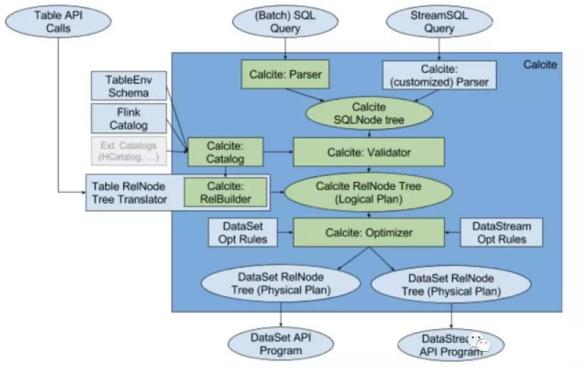
14.Flink 实现 SQL 解析图
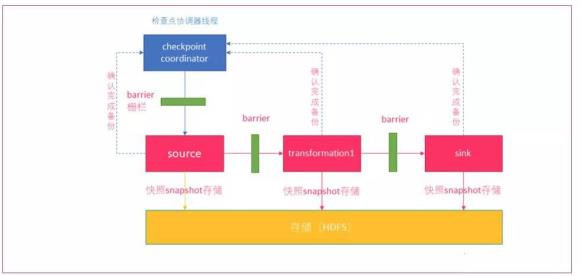
15.Flink 的容错机制
总结
以上便是本码农总结的15张大数据开发必背的数据流转图,有事没事拿出来看一看,潜移默化自然就记下来了~
喜欢的小伙伴欢迎一键三连!!!
我是manor,一枚相信技术改变世界的码农,我们下期再见~

以上是关于一图胜千言:大数据入门必备的15张数据流转图(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章