Tensorflow2 图像分类-Flowers数据及分类代码详解
Posted 空中旋转篮球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow2 图像分类-Flowers数据及分类代码详解相关的知识,希望对你有一定的参考价值。
目录
1、基本步骤
(1) 检查和熟悉数据
(2) 构建输入管道
(3) 构建模型
(4) 训练模型
(5) 测试模型
(6) 改进模型并重复此过程
2.数据下载
2.1 环境
需要使用到的库如下:
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential2.2 数据说明
下载flowers样本数据,该样本数据包含以下类别数据:
flower_photo/
daisy/菊花/
dandelion/蒲公英/
roses/玫瑰/
sunflowers/向日葵/
tulips/郁金香/
数据下载源代码如下:
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)以上这段代码中函数的完整参数如下:
参考原文:https://blog.csdn.net/qq_39507748/article/details/104997553
tf.keras.utils.get_file(
fname, origin, untar=False, md5_hash=None,
file_hash=None,cache_subdir='datasets',
hash_algorithm='auto', extract=False,
archive_format='auto', cache_dir=None
)
参数说明--
fname:文件名,如果指定了绝对路径"/path/to/file.txt",则文件将会保存到该位置
origin:文件的URL
untar:boolean,文件是否需要解压缩
md5_hash:MD5哈希值,用于数据校验,支持sha256和md5哈希
cache_subdir:用于缓存数据的文件夹,若指定绝对路径"/path/to/folder"则将存放在该路径下
hash_algorithm:选择文件校验的哈希算法,可选项有'md5', 'sha256', 和'auto'.
默认'auto'自动检测使用的哈希算法
extract:若为True则试图提取文件,例如tar或zip
archive_format:试图提取的文件格式,可选为'auto', 'tar', 'zip',
和None. 'tar' 包括tar, tar.gz, tar.bz文件. 默认'auto'是['tar', 'zip']. None或空列表将返回没有匹配
cache_dir:文件缓存后的地址,若为None,则默认存放在根目录的.keras文件夹中
运行结果如下:

pathlib.Path(data_dir)函数路径转换说明:
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
print(data_dir)
print(type(data_dir))
data_dir = pathlib.Path(data_dir)
print(data_dir)
print(type(data_dir))C:\\Users\\Administrator\\.keras\\datasets\\flower_photos
<class 'str'>
C:\\Users\\Administrator\\.keras\\datasets\\flower_photos
<class 'pathlib.WindowsPath'>我们在路径下查看该数据:数据已经被解压出来。

daisy/菊花/ 数量:633
dandelion/蒲公英/ 数量:898
roses/玫瑰/ 数量:641
sunflowers/向日葵/ 数量:699
tulips/郁金香/ 数量:799
共计:3670
LICENSE.txt 中包含了图片作者和网址信息:

打开一些数据查看图片的大小,发现图片的像素大小,形状都不一样。部分图片如下:

2.3 数据查看代码
源代码:str类型的data_dir没有glob函数,因此上文中转化为“pathlib.WindowsPath”类型
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
roses = list(data_dir.glob('roses/*'))
img0=PIL.Image.open(str(roses[0]))
plt.imshow(img0)
plt.show()
3.创建数据集
从上文中我们知道,以上图片数据集的大小尺寸都不一样,因此,我们需要创建一组具有相同大小尺寸的数据集,即将以上所有图片转化为像素大小相同的图片数据集。
3.1 数据集创建函数
使用的函数:
tf.keras.preprocessing.image_dataset_from_directory()函数详解:完整参数
tf.keras.preprocessing.image_dataset_from_directory(
directory,
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=32,
image_size=(256, 256),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
)参数说明:
- directory: 数据所在目录。如果标签是“inferred”(默认),则它应该包含子目录,每个目录包含一个类的图像。否则,将忽略目录结构。
- labels: “inferred”(标签从目录结构生成),或者是整数标签的列表/元组,其大小与目录中找到的图像文件的数量相同。标签应根据图像文件路径的字母顺序排序(通过Python中的os.walk(directory)获得)。
- label_mode: 'int':表示标签被编码成整数(例如:
sparse_categorical_crossentropyloss)。‘categorical’指标签被编码为分类向量(例如:categorical_crossentropyloss)。‘binary’意味着标签(只能有2个)被编码为值为0或1的float32标量(例如:binary_crossentropy)。None(无标签)。 - class_names: 仅当“labels”为“inferred”时有效。这是类名称的明确列表(必须与子目录的名称匹配)。用于控制类的顺序(否则使用字母数字顺序)。
- color_mode: "grayscale"、"rgb"、"rgba"之一。默认值:"rgb"。图像将被转换为1、3或者4通道。
- batch_size: 数据批次的大小。默认值:32
- image_size: 从磁盘读取数据后将其重新调整大小。默认:(256,256)。由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供。
- shuffle: 是否打乱数据。默认值:True。如果设置为False,则按字母数字顺序对数据进行排序。
- seed: 用于shuffle和转换的可选随机种子。
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证。
- subset: "training"或"validation"之一。仅在设置validation_split时使用。
- interpolation: 字符串,当调整图像大小时使用的插值方法。默认为:
bilinear。支持bilinear,nearest,bicubic,area,lanczos3,lanczos5,gaussian,mitchellcubic.。 - follow_links: 是否访问符号链接指向的子目录。默认:False。
Returns
一个tf.data.Dataset对象。
- 如果label_mode为None,它将生成float32张量,其shape为(batch_size, image_size[0], image_size(1), num_channels),并对图像进行编码(有关num_channels的规则,参见下文)。
- 否则,将生成一个元组(images, labels),其中图像的shape为(batch_size, image_size[0], image_size(1), num_channels),并且labels遵循下面描述的格式。
关于labels格式规则:
- 如果label_mode 是 int, labels是形状为(batch_size, )的int32张量
- 如果label_mode 是 binary, labels是形状为(batch_size, 1)的1和0的float32张量。
- 如果label_mode 是 categorial, labels是形状为(batch_size, num_classes)的float32张量,表示类索引的one-hot编码。
有关生成图像中通道数量的规则:
如果color_mode 是 grayscale, 图像张量有1个通道。
如果color_mode 是 rgb, 图像张量有3个通道。
如果color_mode 是 rgba, 图像张量有4个通道。
参考:https://blog.csdn.net/qq_40108803/article/details/110408217
3.2 创建数据集
参数设置如下:
batch_size = 32
img_height = 180
img_width = 180在开发模型时使用验证分割是一个很好的实践。我们使用80%的图像进行训练,20%进行验证。
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 3670 files belonging to 5 classes.
Using 2936 files for training.
2021-07-01 22:37:26.205600: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Found 3670 files belonging to 5 classes.
Using 734 files for validation.
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']4.数据可视化
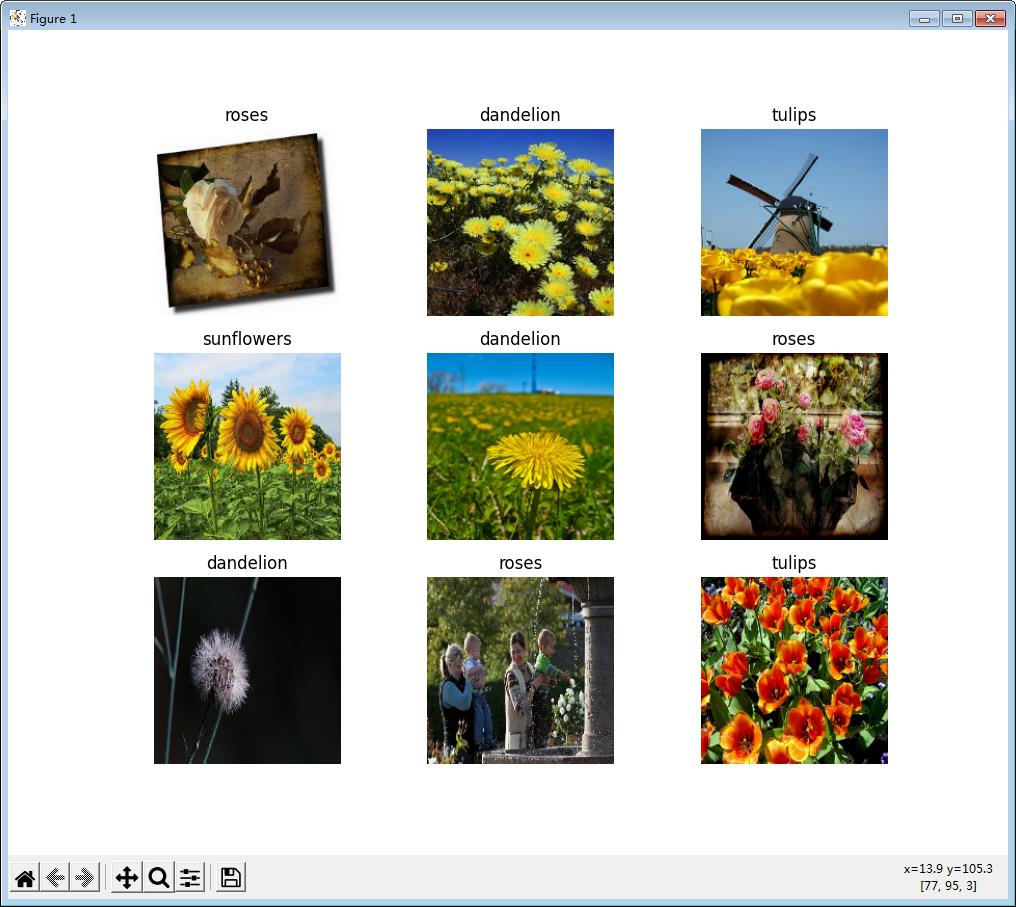
接下来我们对数据进行可视化:
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()显示结果如下:
plt.figure()
figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)
num:图像编号或名称,数字为编号 ,字符串为名称
figsize:指定figure的宽和高,单位为英寸;
dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80 1英寸等于2.5cm,A4纸是 21*30cm的纸张
facecolor:背景颜色
edgecolor:边框颜色
frameon:是否显示边框
原文链接:https://blog.csdn.net/m0_37362454/article/details/81511427
tranin_ds.take()
tranin_ds是一个dataset对象,即dataset.take()方法
dataset.take(1)取第一个元素构建dataset(是第一个元素,不是随机的一个)
每组中应该有30张图,最多可以显示30张图,可以设置为3行,10列都显示出来
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(30):
ax = plt.subplot(3, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
大于30就超限了。
plt.subplot()
plt.subplot(nrows, ncols, index, **kwargs)
第一个参数:*args (官网文档描述)
Either a 3-digit integer or three separate integers describing the position of the subplot. If the three integers are nrows, ncols, and index in order, the subplot will take the index position on a grid with nrows rows and ncols columns. index starts at 1 in the upper left corner and increases to the right.
可以使用三个整数,或者三个独立的整数来描述子图的位置信息。如果三个整数是行数、列数和索引值,子图将分布在行列的索引位置上。索引从1开始,从右上角增加到右下角。
pos is a three digit integer, where the first digit is the number of rows, the second the number of columns, and the third the index of the subplot. i.e. fig.add_subplot(235) is the same as fig.add_subplot(2, 3, 5). Note that all integers must be less than 10 for this form to work.
位置是由三个整型数值构成,第一个代表行数,第二个代表列数,第三个代表索引位置。举个列子:plt.subplot(2, 3, 5) 和 plt.subplot(235) 是一样一样的。需要注意的是所有的数字不能超过10。
第二个参数:projection : {None, ‘aitoff’, ‘hammer’, ‘lambert’, ‘mollweide’, ‘polar’, ‘rectilinear’, str}, optional
The projection type of the subplot (Axes). str is the name of a costum projection, see projections. The default None results in a ‘rectilinear’ projection.
可选参数:可以选择子图的类型,比如选择polar,就是一个极点图。默认是none就是一个线形图。
第三个参数:polar : boolean, optional
If True, equivalent to projection=‘polar’. 如果选择true,就是一个极点图,上一个参数也能实现该功能。
原文链接:https://blog.csdn.net/missyougoon/article/details/90543210
plt.axis()
-
plt.axis(‘square’)
作图为正方形,并且x,y轴范围相同,即y m a x − y m i n = x m a x − x m i n y_{max}-y_{min} = x_{max}-x_{min}y -
plt.axis(‘equal’) x,y轴刻度等长
-
plt.axis(‘off’) 关闭坐标轴
-
plt.axis([a, b, c, d])
设置x轴的范围为[a, b],y轴的范围为[c, d]
5.模型训练
5.1 配置数据集
我们通过将这些数据集传递给模型来训练模型,我们也可以手动遍历数据集和检索一批图像。
Dataset.cache()将图像在第一个epoch期间从磁盘上加载后保存在内存中。这将确保数据集在训练模型时不会成为瓶颈。如果数据集太大,无法装入内存,也可以使用此方法创建一个性能磁盘缓存。
dataset.prefetch() 在训练过程中重叠数据预处理和模型执行。这里自动翻译的。
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)待补充详细说明……
5.2 数据标准化
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))0.0 1.0将数据处理为[0,1]之间。
补充详细说明……
6.模型创建
6.1 创建模型
该模型由三个卷积块组成,每个卷积块中有一个最大池层。有一个完全连接的层,上面有128个单元,由一个relu激活功能激活。这个模型还没有进行高精度的调整,目标是展示一种标准的方法。
num_classes = 5
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])补充说明……
6.2 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])模型说明……
6.3 总结模型
model.summary()以上三小结输出结果:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 180, 180, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 90, 90, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 45, 45, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 22, 22, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 30976) 0
_________________________________________________________________
dense (Dense) (None, 128) 3965056
_________________________________________________________________
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________6.4 模型训练
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)函数说明……
6.5 训练结果可视化及分析
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()_________________________________________________________________
Epoch 1/10
92/92 [==============================] - 61s 656ms/step - loss: 1.3780 - accuracy: 0.4118 - val_loss: 1.0661 - val_accuracy: 0.5722
Epoch 2/10
92/92 [==============================] - 58s 633ms/step - loss: 1.0134 - accuracy: 0.5988 - val_loss: 1.0202 - val_accuracy: 0.5858
Epoch 3/10
92/92 [==============================] - 67s 731ms/step - loss: 0.8491 - accuracy: 0.6730 - val_loss: 1.0023 - val_accuracy: 0.6076
Epoch 4/10
92/92 [==============================] - 59s 641ms/step - loss: 0.6457 - accuracy: 0.7582 - val_loss: 0.9318 - val_accuracy: 0.6458
Epoch 5/10
92/92 [==============================] - 62s 676ms/step - loss: 0.4351 - accuracy: 0.8464 - val_loss: 1.0414 - val_accuracy: 0.6362
Epoch 6/10
92/92 [==============================] - 76s 832ms/step - loss: 0.2478 - accuracy: 0.9200 - val_loss: 1.3063 - val_accuracy: 0.6199
Epoch 7/10
92/92 [==============================] - 66s 716ms/step - loss: 0.1642 - accuracy: 0.9496 - val_loss: 1.5034 - val_accuracy: 0.6403
Epoch 8/10
92/92 [==============================] - 65s 707ms/step - loss: 0.0777 - accuracy: 0.9799 - val_loss: 1.6238 - val_accuracy: 0.6403
Epoch 9/10
92/92 [==============================] - 66s 714ms/step - loss: 0.0382 - accuracy: 0.9915 - val_loss: 1.7345 - val_accuracy: 0.6362
Epoch 10/10
92/92 [==============================] - 71s 771ms/step - loss: 0.0608 - accuracy: 0.9843 - val_loss: 1.8870 - val_accuracy: 0.6362
从图中可以看到,训练精度和验证精度相差很大,模型在验证集上仅实现了约60%的准确性。
让我们看看哪里出了问题,并尝试提高模型的整体性能。
在上面的图中,训练精度随时间线性增加,而验证精度在训练过程中停滞在60%左右。此外,训练和验证准确性之间的差异是明显的——这是过度拟合的迹象。
当训练样本数量很少时,模型有时会从训练样本的噪声或不需要的细节中学习,这在一定程度上会对模型在新样本上的性能产生负面影响。这种现象被称为过拟合。这意味着模型在新的数据集中泛化时会有困难。
在训练过程中有多种方法可以对抗过拟合。可以使用数据增强并将Dropout添加到我们的模型中。
6.6 数据增强
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.experimental.preprocessing.RandomRotation(0.1),
layers.experimental.preprocessing.RandomZoom(0.1),
]
)数据增强主要用来防止过拟合,用于dataset较小的时候。
之前对神经网络有过了解的人都知道,虽然一个两层网络在理论上可以拟合所有的分布,但是并不容易学习得到。因此在实际中,我们通常会增加神经网络的深度和广度,从而让神经网络的学习能力增强,便于拟合训练数据的分布情况。在卷积神经网络中,有人实验得到,深度比广度更重要。
然而随着神经网络的加深,需要学习的参数也会随之增加,这样就会更容易导致过拟合,当数据集较小的时候,过多的参数会拟合数据集的所有特点,而非数据之间的共性。那什么是过拟合呢,之前的博客有提到,指的就是神经网络可以高度拟合训练数据的分布情况,但是对于测试数据来说准确率很低,缺乏泛化能力。
因此在这种情况下,为了防止过拟合现象,数据增强应运而生。当然除了数据增强,还有正则项/dropout等方式可以防止过拟合。那接下来讨论下常见的数据增强方法。
1)随机旋转
随机旋转一般情况下是对输入图像随机旋转[0,360)
2)随机裁剪
随机裁剪是对输入图像随机切割掉一部分
3)色彩抖动
色彩抖动指的是在颜色空间如RGB中,每个通道随机抖动一定的程度。在实际的使用中,该方法不常用,在很多场景下反而会使实验结果变差
4)高斯噪声
是指在图像中随机加入少量的噪声。该方法对防止过拟合比较有效,这会让神经网络不能拟合输入图像的所有特征
5)水平翻转
6)竖直翻转
随机裁剪/随机旋转/水平反转/竖直反转都是为了增加图像的多样性。并且在某些算法中,如faster RCNN中,自带了图像的翻转。
原文链接:https://blog.csdn.net/lanmengyiyu/article/details/79658545
增强数据可视化:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off") 7.Dropout
7.Dropout
7.1 重建模型
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
原理参考:深度学习中Dropout原理解析
model = Sequential([
data_augmentation,
layers.experimental.preprocessing.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
epochs=15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)数据可视化:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
7.2 对新数据进行预测
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = keras.preprocessing.image.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)重新运行代码,疯狂计算中……

_________________________________________________________________
Epoch 1/15
92/92 [==============================] - 73s 791ms/step - loss: 1.3521 - accuracy: 0.4019 - val_loss: 1.0953 - val_accuracy: 0.5559
Epoch 2/15
92/92 [==============================] - 69s 748ms/step - loss: 1.0640 - accuracy: 0.5719 - val_loss: 0.9975 - val_accuracy: 0.6063
Epoch 3/15
92/92 [==============================] - 82s 896ms/step - loss: 1.0002 - accuracy: 0.6104 - val_loss: 0.9629 - val_accuracy: 0.6322
Epoch 4/15
92/92 [==============================] - 87s 945ms/step - loss: 0.9113 - accuracy: 0.6434 - val_loss: 0.9085 - val_accuracy: 0.6444
Epoch 5/15
92/92 [==============================] - 86s 929ms/step - loss: 0.8446 - accuracy: 0.6737 - val_loss: 0.9270 - val_accuracy: 0.6444
Epoch 6/15
92/92 [==============================] - 77s 833ms/step - loss: 0.8044 - accuracy: 0.6860 - val_loss: 0.8783 - val_accuracy: 0.6608
Epoch 7/15
92/92 [==============================] - 68s 738ms/step - loss: 0.7580 - accuracy: 0.7040 - val_loss: 0.7989 - val_accuracy: 0.6839
Epoch 8/15
92/92 [==============================] - 67s 734ms/step - loss: 0.7278 - accuracy: 0.7207 - val_loss: 0.8172 - val_accuracy: 0.6894
Epoch 9/15
92/92 [==============================] - 68s 743ms/step - loss: 0.7242 - accuracy: 0.7197 - val_loss: 0.7696 - val_accuracy: 0.6894
Epoch 10/15
92/92 [==============================] - 74s 808ms/step - loss: 0.6596 - accuracy: 0.7476 - val_loss: 0.8035 - val_accuracy: 0.6839
Epoch 11/15
92/92 [==============================] - 73s 799ms/step - loss: 0.6510 - accuracy: 0.7497 - val_loss: 0.7912 - val_accuracy: 0.7016
Epoch 12/15
92/92 [==============================] - 78s 852ms/step - loss: 0.6036 - accuracy: 0.7681 - val_loss: 0.7417 - val_accuracy: 0.7248
Epoch 13/15
92/92 [==============================] - 75s 818ms/step - loss: 0.5839 - accuracy: 0.7759 - val_loss: 0.6985 - val_accuracy: 0.7221
Epoch 14/15
92/92 [==============================] - 68s 736ms/step - loss: 0.5630 - accuracy: 0.7878 - val_loss: 0.8848 - val_accuracy: 0.6839
Epoch 15/15
92/92 [==============================] - 87s 950ms/step - loss: 0.5393 - accuracy: 0.7963 - val_loss: 0.7374 - val_accuracy: 0.7098Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg
122880/117948 [===============================] - 1s 7us/step
This image most likely belongs to sunflowers with a 97.72 percent confidence.8.最后 完整代码
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
"""flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/"""
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
print(data_dir)
print(type(data_dir))
data_dir = pathlib.Path(data_dir)
print(data_dir)
print(type(data_dir))
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
roses = list(data_dir.glob('roses/*'))
img0=PIL.Image.open(str(roses[0]))
plt.imshow(img0)
plt.show()
batch_size = 32
img_height = 180
img_width = 180
#It's good practice to use a validation split when developing your model.
# Let's use 80% of the images for training, and 20% for validation.
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
#图片可视化
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(30):
ax = plt.subplot(3, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
"""
num_classes = 5
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
"""
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.experimental.preprocessing.RandomRotation(0.1),
layers.experimental.preprocessing.RandomZoom(0.1),
]
)
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")
num_classes = 5
model = Sequential([
data_augmentation,
layers.experimental.preprocessing.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
epochs=15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
"""
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
"""
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = keras.preprocessing.image.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)以上是关于Tensorflow2 图像分类-Flowers数据及分类代码详解的主要内容,如果未能解决你的问题,请参考以下文章
Tensorflow2 图像分类-Flowers数据深度学习模型保存读取参数查看和图像预测
Tensorflow2 图像分类-Flowers数据及分类代码详解
ResNet实战:tensorflow2.X版本,ResNet50图像分类任务(大数据集)
MobileNet实战:tensorflow2.X版本,MobileNetV3图像分类任务(大数据集)