[翻译]Go与C#的比较,第二篇:垃圾回收
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[翻译]Go与C#的比较,第二篇:垃圾回收相关的知识,希望对你有一定的参考价值。
Go vs C#, part 2: Garbage Collection | by Alex Yakunin | ServiceTitan — Titan Tech | Medium
目录
译者注
什么是垃圾回收?
什么是GCBurn?
峰值分配吞吐量("速度测试")
GCBurn 测试
GC Burn测试结果
结论
.NET Core
Go
两者的相同点
免责声明和后记
译者注
本文90%通过机器翻译,另外10%译者按照自己的理解进行翻译,和原文相比有所删减,可能与原文并不是一一对应,但是意思基本一致。
这是Alex Yakunin大佬关于Go和C#比较的第二篇文章,本文发表于2018年9月,当时使用的.NET Core版本应该是2.1,Go版本应该是1.11版本。而现在.NET版本已经到6 Pre5,Go也到了1.16,经过这么多版本的迭代,Go和.NET的GC性能都有很大提高,所以数据仅供参考,当然也欢迎大家能在新的版本上跑一下最新的结果发一篇帖子出来。
译者水平有限,如果错漏欢迎批评指正
译者@Bing Translator、@InCerry,另外感谢@晓青、@贾佬、@晓晨、@黑洞、@maaserwen、@帅张、@3wlinecode、@huchenhao百忙之中抽出时间帮忙review和检查错误。
原文链接:https://medium.com/servicetitan-engineering/go-vs-c-part-2-garbage-collection-9384677f86f1

这一个系列中还有其他两篇文章:
第一篇:Goroutines vs Async-Await 【中文翻译版】
第三篇:Compiler, Runtime, Type System, Modules, and Everything Else. 【中文翻译版】
有趣的是,这篇文章的草稿是几个月前写的,而且比较短。它的主要内容是。"Go的GC显然比.NET的差,请看下面的帖子。1, 2, 3, 4(注意,其中有些是最近的),以了解详情"。
但是......我还是想让自己以某种方式测试这个问题,所以我请我的一个朋友 - Go专家帮我做这个基准测试。我们写了GCBurn,一个相对简单的垃圾收集和内存分配基准,目前支持Go和C#,尽管你可以自由地把它移植到任何其他有GC的语言上。
现在,让我们进入森林吧 ???? 【应该是俚语,来自电影https://en.wikipedia.org/wiki/Into_the_Woods_(film)】
什么是垃圾回收?
这个帖子相当长,所以如果你知道GC是什么,请跳过这一部分。
垃圾回收(GC,Garbage Collector)是运行时的一部分,负责回收 "死 "对象使用的内存,下面是它的工作原理:
"活着的 "对象是堆中的任何对象,它要么现在被使用(它的一个指针被存储在CPU的一个寄存器中),要么将来可能被使用(可能有一个程序最终获得了这样一个对象的指针)。如果你把堆看成是一个对象相互引用的图,很容易注意到,如果某个对象O是活的,那么它直接引用的每个对象(O1, O2, ... O_m)也是活的:有一个指向O的指针,你可以通过一条CPU指令获得指向O1, O2, ... O_m的指针。对于O1, O2, ...O_m所引用的对象也可以这样说--这些对象中的每一个都是活的。换句话说,如果对象Q可以从某个活着的对象A处到达,Q也是活着的【可达性分析】。
"死 "对象是堆中除了"活着的"所有其他对象。它们是 "死 "的,因为代码没有办法在将来以某种方式获得它们中任何一个对象的指针。没有办法找到它们,因此也没有办法使用它们。
一个很好的现实世界的比喻是:假设你从有机场(GC根)的任何城市开始旅行,你想找出哪些城市(对象)是可以通过公路网到达的。

围绕单一原点的可达区域的可视化。图片来源 https://www.graphhopper.com/blog/2018/07/04/high-precision-reachability/
这个定义也解释了垃圾收集算法的基本部分:它必须不时地检查什么是可触及的(活着的),并删除其他一切。下面是通常的步骤:
冻结所有线程。
将所有GC根(从CPU寄存器、定位器/调用堆栈框架或静态字段引用的对象,即所有正在使用或立即可用的东西)标记为活的。
把每一个可以从GC根部接触到的物体也标记为活的,其他的都视为死的。
让死亡对象分配的内存再次可用,例如,你可以把它标记为 "可供未来分配",或者通过移动所有活着的对象来整理堆,使之没有空隙。
最后,解冻所有线程。
这里所描述的通常被称为 "标记和清扫 "GC,它是最直接的实现,但不是最有效的。它意味着我们必须暂停一切来执行GC,这就是为什么有这种暂停的收集器也被称为Stop-the-World,或者STW收集器--与无暂停收集器相反pauseless collectors.。
在解决问题的方式上,无暂停与STW收集器没有什么不同,它们将与你的代码同时进行几乎所有的工作。显然,这是很棘手的,如果我们回到现实世界中的城市和道路的比喻,这就像试图绘制从机场可以到达的城市的地图,假设:
你实际上没有地图,但有一个由你操作的车队。
当这些车辆行驶时,新的城市和道路被建造,一些道路被摧毁。
所有这些都使问题变得更加复杂,特别是在这种情况下,你不能像以前那样修建道路:你必须检查舰队目前是否正在运行(即GC正在寻找活着的对象),以及它是否已经通过了你新修建的道路的起点城市(即GC已经将该城市标记为活着)。如果是这样,你必须通知车队(GC)回到那里,找到所有可以通过新路到达的城市。
翻译成我们的非虚构案例,它意味着当GC运行时,任何指针写操作都需要一个特殊的检查了(写屏障),而且它会拖慢你的代码。
无暂停和STW GC之间没有黑白之分,这只是关于STW停顿的时间。
STW的暂停时间如何取决于不同的因素?例如,它是固定的,还是与活着的对象集的大小成比例(O(alive_set_size)【时间复杂度】)?
如果这些停顿是固定的,那么实际的持续时间是多少?如果它对你的特定情况来说是很小的,那么它就~与完全无暂停的 GC 相同。
如果这些暂停不是固定的,我们能否确保它们永远不会超过我们能承受的最大限度?
最后,请注意,不同的GC实现可能针对不同的方面进行优化:
由GC引起的整体减速(或整体程序吞吐量):即大致上,花在GC上的时间百分比+所有相关性能损耗(例如上面例子中的写障碍检查)。
STW暂停时间的分布:显然,越短越好(抱歉,这里没有双关语)+理想情况下,你不希望有O(aliveSetSize)停顿。
总的来说,花在GC上的内存的百分比,或由于其具体的实现。额外的内存可能被分配器或GC直接使用,也可能因为堆碎片化而不可用,等等。
内存分配的吞吐量:GC通常与内存分配器紧密结合。特别是,分配器可能会触发当前线程暂停来完成GC的一部分工作,或者使用更昂贵的数据结构来实现某种GC。
等等。- 这里还列举了很多因素。
最糟糕的是:你显然不能得到所有的好处,也就是说,不同的GC实现有它们自己的好处和取舍。这就是为什么很难写出一个好的GC基准:)
什么是GCBurn?
GCBurn是我们精心设计的一个基准,用于直接测量最重要的GC性能指标--即通过实际来直接测量【作者的意思应该是直接通过观察OS报告的进程状态,来观测】,而不是查询运行时提供的性能计数器或API。
直接测量提供了一些好处:
移植性:将我们的基准移植到大多数的运行时中是相当容易的,它是否具有允许以某种方式查询我们所测量的内容的API根本就不重要。而且我们绝对欢迎你这样做。例如,我真的很想看看Java与Go和.NET Core的对比情况。
更少的有效性问题:也更容易验证你得到的数据是否真的有效:从运行时得到同样的数字总是会引起一些问题,比如 "你怎么能确定你得到的是正确的数字?",而这些问题的良好答案意味着你可能会花更多的时间研究特定的GC实现和收集指标的方式,而不是编写一个类似的测试。
其次,GCBurn的设计是为了将苹果与苹果进行比较,也就是说,它的所有测试都做了几乎完全相同的动作/分配序列--依赖相同的分布、相同的随机数生成器,等等。这就是为什么它对不同语言和框架的测试结果可以直接进行比较。
GCBurn进行了两项测试:
峰值分配吞吐量("速度测试")
这里的意图是测量峰值突发分配率,假设没有其他东西(特别是GC)会减慢内存分配的速度:
启动T个线程/goroutines,其中每个线程:
尽可能快地分配16字节的对象(有两个int64字段的对象)。
循环进行,持续时间为1ms,跟踪分配的总次数。
等待所有的线程完成,以及分配率(每秒的对象)。
重复这个过程~30次,并打印最大的测量分配率。
GCBurn 测试
这是一个更复杂的测试:
持续分配的峰值吞吐量(对象/秒,字节/秒)--即在一个相对较长的时间段内测得的吞吐量,假设我们分配、保持并最终释放每个对象,并且这些对象的大小和保持时间遵循接近于现实生活的分布。
由GC引起的线程暂停的频率和持续时间分布,50%百分位数(p50)、p95、p99、p99.9、p99.99+最小、最大和平均值。
由GC引起的STW(全局)停顿的频率和时间分布。
下面是测试的工作方式:
分配适当大小的 "静态集"(我会进一步解释)。
启动T线程/goroutines,其中每个线程:
按照预先生成的大小和寿命分布模式分配对象(实际上是int64s的数组/片)。该模式实际上是一个由3个值组成的图元列表:(size, ~floor(log10(duration)), str(duration)[0] - '0')。最后两个值编码 "保持时间",它的指数和它的十进制表示法中的第一个数字,单位是微秒。这是一项优化,允许 "释放 "操作相当有效,每个分配的对象有O(1)的时间复杂度,我们在这里用一点精度来换取速度。
每16次分配,尝试释放那些保持时间已经过期的分配对象。
对于每个循环迭代,测量当前迭代所花费的时间。如果花费的时间超过10微秒(通常情况下,迭代的时间应该小于0.1微秒),假设有一个GC暂停,所以将其开始和结束时间记录在这个线程的列表中。
追踪分配的数量和分配对象的总大小。D秒后停止。
等待所有的线程都完成。
当上述部分完成后,每个线程的情况如下:
它能够执行的分配的数量,以及它们的总大小(字节)。
它所经历的停顿(停顿间隔)列表。
有了每个线程的这些列表,就有可能计算出STW暂停的时间间隔列表(即每个线程暂停的时间段),只需将所有这些列表相交即可。
了解了这些,就很容易产生上述的统计数据。
现在,一些重要的细节:
我已经提到,分配序列(模式)是预先生成的。这样做主要是因为我们不想为每一次分配花费CPU周期来生成一组随机数。生成的序列是由~ 1M个~(大小,log(持续时间))的项目组成。参见BurnTester.TryInitialize(C# / Go)以查看实际实现。
每个GCBurn线程使用相同的序列,但从那里的一个随机点开始。当它到达终点时,它从序列的开头继续。
为了确保每种语言的模式绝对相同,我们使用了自定义的随机数发生器(见StdRandom.cs / std_random.go)。实际上,它是C++ 11的minstd_rand实现,移植到C#和Go。
而且总的来说,我们确保所有我们使用的随机值在不同的平台上都是相同的,分配序列中的线程起点,这个序列中的大小和持续时间,等等。
大小
我们使用的对象大小和保持时间分布(见样例, C#, Go)是为了接近现实的实际情况。
99%的 "典型 "对象 + 0.99%的 "大型 "对象+0.01%的 "超大型",其中:
"典型"大小遵循正态分布,平均值=32字节,stdDev=64字节
"大"尺寸遵循对数正态分布,基础正态分布的平均值=log(2 Kb)=11,stdDev=1。
"超大"尺寸遵循对数正态分布,基础正态分布的平均值=log(64 Kb)=16,stdDev=1。
尺寸被截断以适应[32B ... 128KB]的范围,然后转化为数组/片断尺寸,考虑到C#的参考尺寸(8B)和数组头尺寸(24B),以及Go的片断尺寸(24B)。
对象保持时间
同样,它由95%的 "方法级 " + 4.9%的 "请求级 " + 0.1%的 "长效 "保持时间组成,其中:
方法级"保持时间遵循正态分布变量的绝对值,平均值=0微秒,stdDev=0.1微秒
"请求级"保持时间遵循类似的分布,但stdDev=100ms(毫秒)。
"长寿"保持时间遵循正态分布,平均值=stdDev=10秒。
保持时间被截断以适应[0 ... 1000秒]范围。
最后,静态集是一组遵循完全相同的大小分布的对象,在测试过程中从未释放过,换句话说,它是我们的活体集。如果你的应用程序在RAM中缓存或存储了大量的数据(或有一些内存泄漏),它将会很大。同样,对于简单的无状态应用程序(如简单的网络/API服务器),它应该是小的。
如果你读到这里,你可能急于看到结果,结果在这里。
GC Burn测试结果
我们已经在一组非常不同的机器上运行了test-all(或Windows上的Test-All.bat),并将输出转存到了结果文件夹.。
Test-all运行以下测试:
峰值分配吞吐量测试("速度测试"):使用1、25%、50%、75%和100%的最大。# 系统实际可以并行运行的线程数。因此,例如,对于Core i7-8700K,"100%线程"=12个线程(6个核心*每个核心2个线程/超线程)。
GCBurn测试:对于静态设置大小=0MB、1MB、10%、25%、50%和75%的测试机器上的总内存,并使用100%的最大线程。# 线程数。每个测试运行2分钟。
GCBurn测试:所有的设置与前面的情况相同,但使用75%的最大。# 系统实际可以并行运行的线程数的75%。
最后,它以3种模式对.NET运行所有这些测试--服务器GC+SustainedLowLatency(你可能会在你的生产服务器上使用这种模式),服务器GC+Batch,以及工作站GC。我们对Go也做了同样的测试--唯一相关的选项是GOGC,但我们在将其设置为50%后没有注意到任何区别:似乎Go在这个测试中连续运行GC~。
所以我们开始吧。你也可以打开Google电子表格,里面有我用于制作图表的所有数据,以及GitHub上的 "结果"文件夹,里面有原始测试输出(那里有更多的数据)。
下图峰值吞吐量(越大越好),单位M ops/秒,测试平台12核非虚拟化的英特尔酷睿i7-8700K CPU @ 3.70GHz

下图峰值吞吐量(越大越好),M ops/秒,测试平台96核AWS m5.24xlarge实例(硬件CPU:Intel Xeon Platinum 8175M CPU @ 2.50GHz)
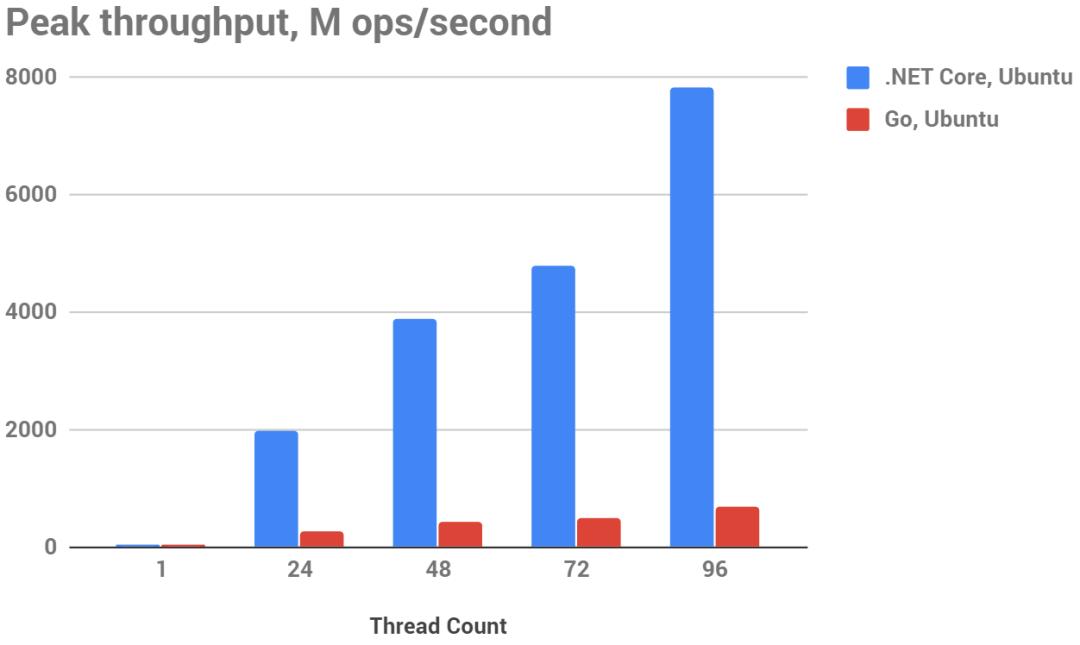
提醒一下,这个测试的1个操作=分配一个16字节的对象。
在突发分配方面,.NET显然胜过Go:
它不仅在单线程测试中快了3倍(Ubuntu)......5倍(Windows),而且随着线程数量的增加,它的扩展性也更好,在96核的怪物m5.24xlarge上,差距扩大到12倍。
堆分配在.NET上是几乎不损耗性能的操作。如果你看一下数字,它们实际上只是比栈分配多耗3-4倍性能:你在每个线程上每秒进行约10亿的简单调用,与3亿的堆分配成本差不多。
看起来.NET在Windows上更快一些,相反,Go在Windows与Linux上相比几乎慢了2倍。
下图持续吞吐量(越大越好),M ops/秒,12线程,测试平台12核非虚拟化的英特尔酷睿i7-8700K CPU @ 3.70GHz

下图持续吞吐量(越大越好),M ops/秒,16线程,测试平台96核AWS m5.24xlarge实例(硬件CPU:Intel Xeon Platinum 8175M CPU @ 2.50GHz)

在这个测试上的一个操作是按照前面描述的模拟现实生活分布进行的一次分配;此外,在这个测试上分配的每个对象都有一个按照另一个模拟现实场景分布的寿命。
在这个测试中,.NET仍然更快,尽管差距并不大,20 ... 50%取决于操作系统(Linux上更小,Windows上更大)和静态集大小。
你可能还注意到,Go不能通过 "静态集合大小=50%内存/75%内存 "的测试,它以OOM(内存不足)失败。在75%的可用CPU核心上运行测试有助于Go通过 "静态集=50% RAM "测试,但在75%的情况下仍然无法通过。
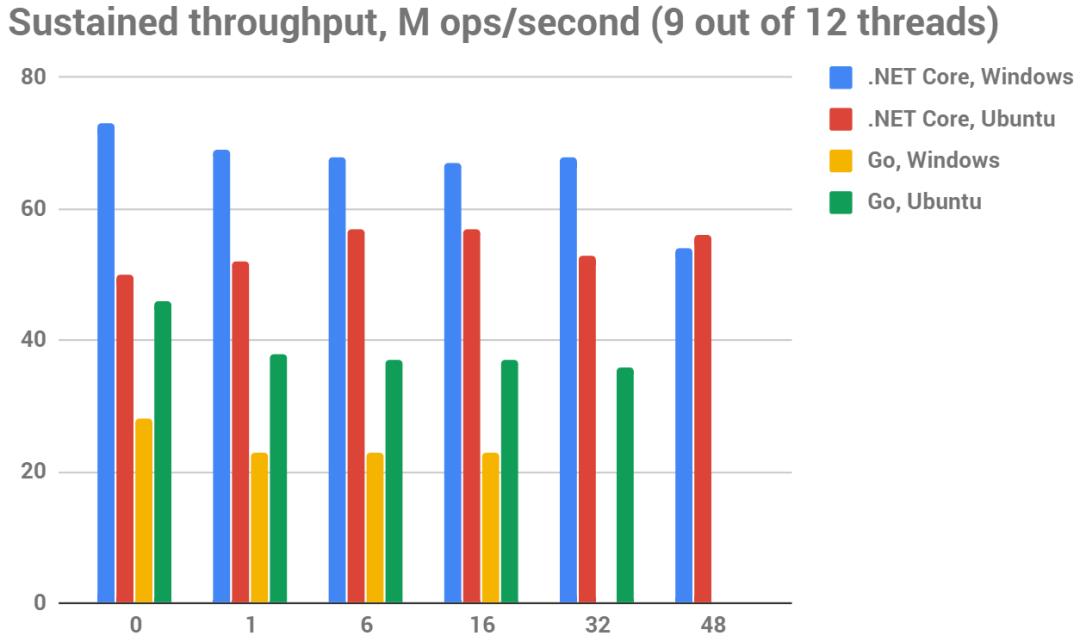
下图持续吞吐量(越大越好),M ops/秒,9-12线程,测试平台12核非虚拟化的英特尔酷睿i7-8700K CPU @ 3.70GHz
下图持续吞吐量(越大越好),M ops/秒,12-16线程,测试平台96核AWS m5.24xlarge实例(硬件CPU:Intel Xeon Platinum 8175M CPU @ 2.50GHz)
延长测试时间(这里是2分钟的测试时间)会导致Go在 "静态集=50%内存 "的测试中几乎每次都发生OOM,从结果上来看,如果活着的静态集足够大,那么GO的GC无法跟上分配速度。
除此之外,使用100%和75%的CPU核心测试吞吐量率之间没有任何显著变化。
同样明显的是,Go和.NET的分配器都没有随着核心数量的增加而得到吞吐量的增加。这个图表证明了这一点。
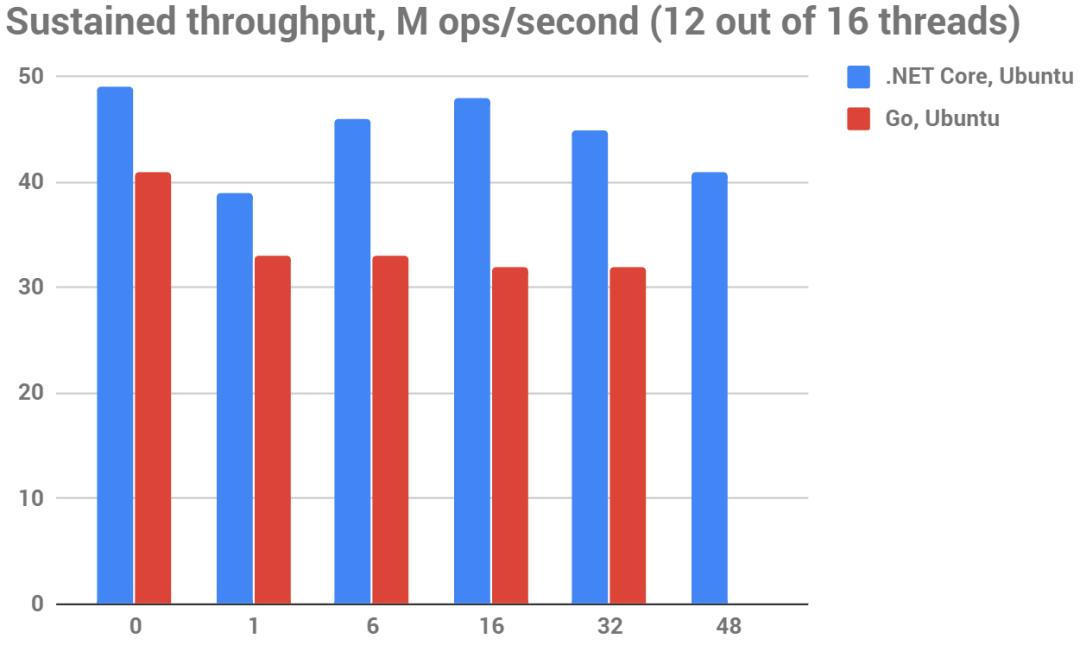
下图持续吞吐量(越大越好),M ops/秒,72-96线程,测试平台96核AWS m5.24xlarge实例(硬件CPU:Intel Xeon Platinum 8175M CPU @ 2.50GHz)

正如你所看到的,多出5倍的CPU核心数量在这里只转化为2.5倍的速度提升。
看起来内存带宽并不是瓶颈:~70 M ops/sec.转换为~6.5 GB/sec.,这只是Core i7机器上可用内存带宽的10%。
同样有趣的是,Go在 "静态集=50%内存 "的情况下开始击败.NET。你想知道为什么吗?
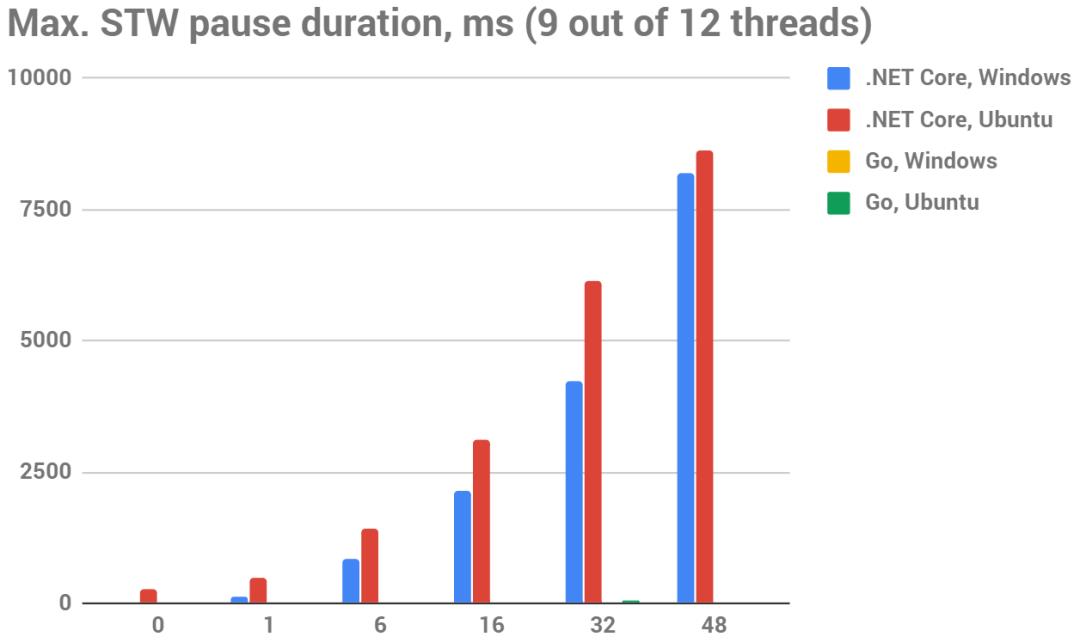
下图最大STW停顿时间(越小越好),ms,9-12线程,测试平台12核非虚拟化的英特尔酷睿i7-8700K CPU @ 3.70GHz
下图最大STW停顿时间(越小越好),ms,72-96线程,测试平台96核AWS m5.24xlarge实例(硬件CPU:Intel Xeon Platinum 8175M CPU @ 2.50GHz)
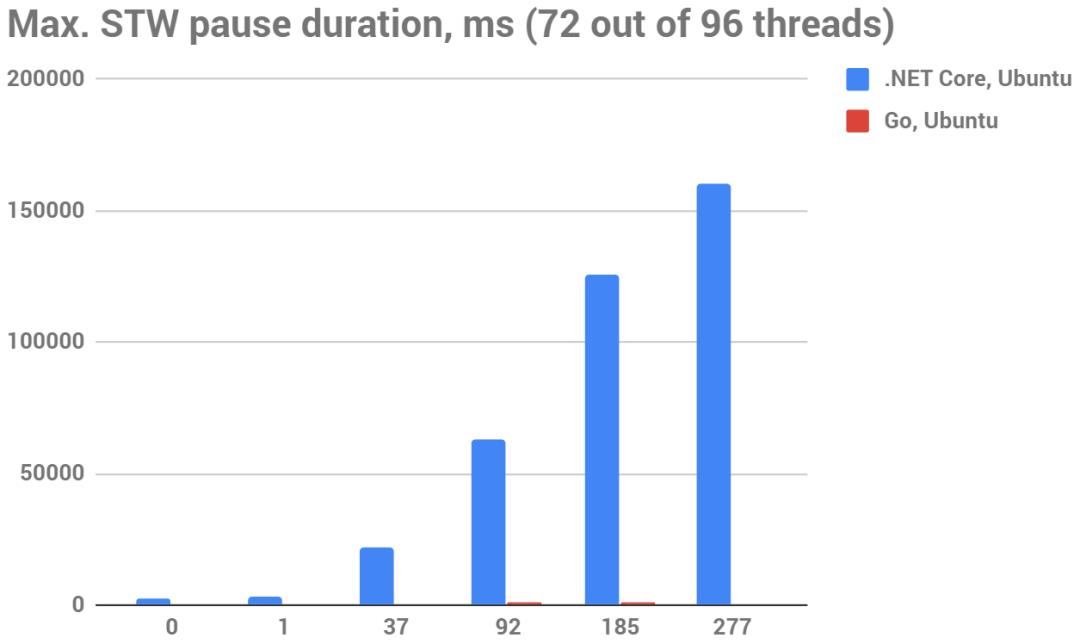
是的,这对.NET来说是一个绝对可耻的部分:
Go的暂停在这里几乎看不出来,因为暂停时间很小。我能够测量到的最大暂停时间是1.3秒,作为比较,.NET在同一测试案例中得到125秒的STW暂停。
Go中几乎所有的STW停顿都是亚毫秒级的。如果你看一下更多真实的测试案例(例如这个文件),你会发现在一个~普通的16核服务器上的16GB静态设置意味着你最长的停顿=50ms(与.NET的5s相比),99.99%的停顿都短于7ms(.NET的92ms)!
对于.NET和Go来说,STW的暂停时间似乎与静态集的大小成线性关系。但如果我们比较较大的暂停,Go的暂停时间要短100倍。
总结。Go的增量GC确实有效;而.NET的并发GC则不然。
好吧,可能我在这一点上把所有的.NET开发者都吓坏了,特别是假设我已经提到GCBurn的设计是接近真实生活的。那么你是否有望在.NET上得到类似的停顿?是的,也不是。
185GB(这是约20亿个对象,GC暂停时间实际上取决于这个数字,而不是工作集的GB大小)的静态集远远超出了你在现实生活中的预期。可能,即使是16GB的静态集也远远超出了你在任何设计良好的应用程序中可能看到的情况。
"设计良好"实际上意味着。"根据这里的发现,没有哪个正常的开发者会使用这么多GB的静态集来制作一个.NET应用程序"。有很多方法可以克服这个限制,但最终,所有这些方法都迫使你把数据存储在巨大的托管数组中,或者存储在非托管缓冲区中。.NET Core 2.1 --更确切地说,它的ref结构、Span<T>和Memory<T>大大简化了这些工作。
除此之外,"精心设计"还意味着"没有内存泄漏"。正如你可能注意到的,如果你在.NET中泄漏引用,你会看到有越来越长的STW暂停。很明显,你的应用程序最终会崩溃,但请注意,在崩溃发生之前,它也可能变得暂时没有反应--所有这些都是因为STW暂停时间越来越长。而你额外内存泄漏的越多,情况就会越糟糕。
追踪最大。GC暂停时间和Gen2后的GC工作集大小对于确保你不会因为内存泄漏而遭受p95-p99延时越来越大来说,一定是至关重要的。
作为.NET开发者,我真的希望.NET核心团队能早点解决max_STW_pause_time = O(static_set_size)的问题。除非它得到解决,否则.NET开发者将不得不依赖变通方法,这实际上一点也不好。最后,即使它的存在也会对许多潜在的.NET应用起到阻碍作用--想想物联网、机器人和其他控制应用;高频交易、游戏或游戏服务器等。
至于Go,这个问题在那里得到了很好的解决,令人惊讶。值得注意的是,Go团队从2014年开始就一直在与STW暂停作斗争--最终,他们成功地杀死了所有O(alive_set_size)暂停(正如该团队所声称的--似乎测试并不能证明这一点,但也许这只是因为GCBurn走得太远而暴露了这一点 ???? ). 无论如何,如果你对那里发生的细节感兴趣,这个帖子是一个很好的开始:https://blog.golang.org/ismmkeynote
我在问自己,在这两个选项中,我更喜欢哪一个,即.NET更快的分配器和Go的微小GC暂停。坦率地说,我更倾向于Go--主要是因为它的分配器的性能看起来还不错,但在大堆上100倍的短暂停顿是相当有吸引力的。至于大堆上的OOM(或需要2倍以上的内存来避免OOM)--嗯,内存很便宜。虽然如果你在同一台机器上运行多个Go应用,这可能更重要(想想桌面应用和微服务)。
总而言之,STW停顿的这种情况让我羡慕Go开发者所拥有的东西--可能,这是第一次。
好了,还有最后一个话题要讲--即.NET上的其他GC模式(剧透:它们不能拯救世界,但仍然值得一谈)【.NET GC有很多的模式,想知道详情可以点我】。
下图突发吞吐量(越大越好),M ops/秒
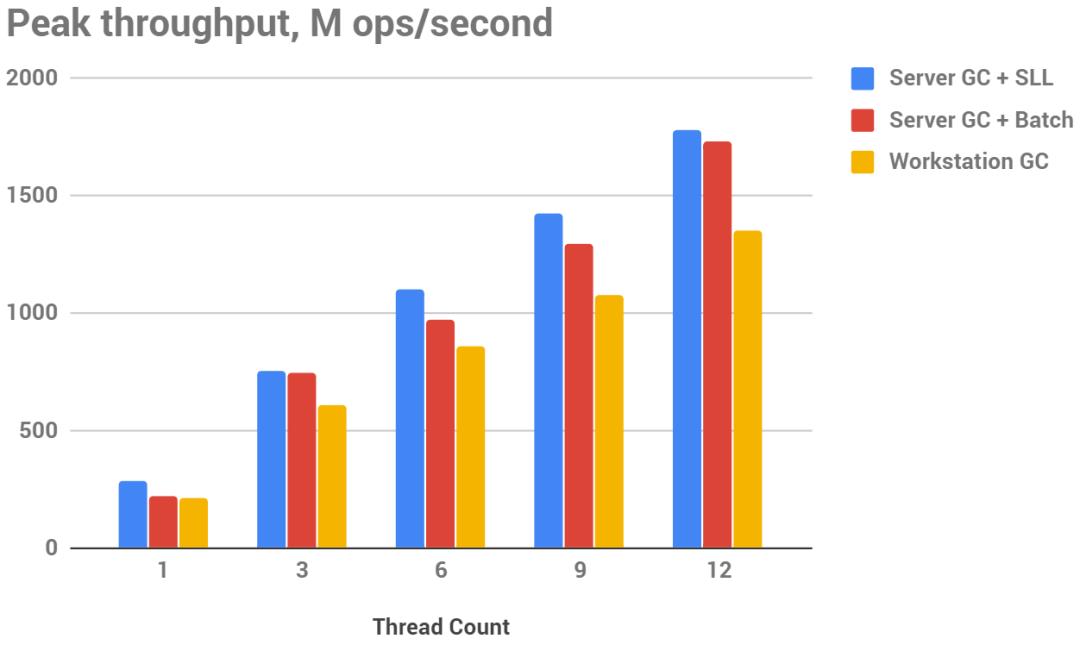
并发模式下的服务器GC(SustainedLowLatency或Interactive)提供了最高的峰值吞吐量,尽管与Batch的差别很小。
下图持续吞吐量(越大越好),M ops/秒
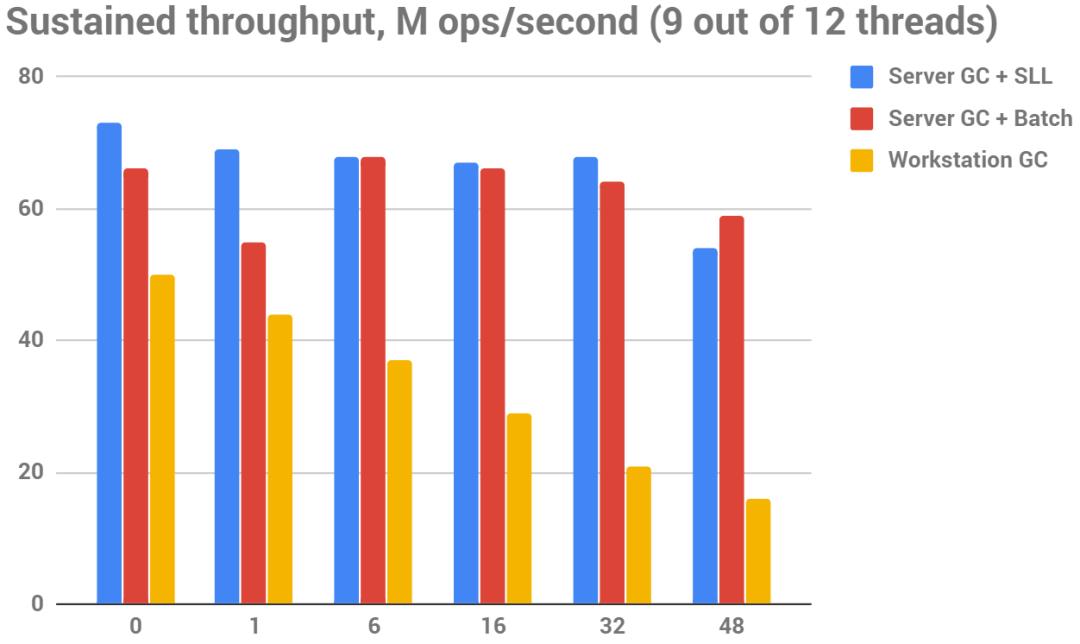
在服务器GC+SLL模式下,持续的吞吐量也是最高的。服务器 GC + 批量模式也非常接近,但工作站 GC 根本无法随着静态集规模的增长而扩展。
最后,STW时间:
下图最大STW停顿时间(越小越好),ms
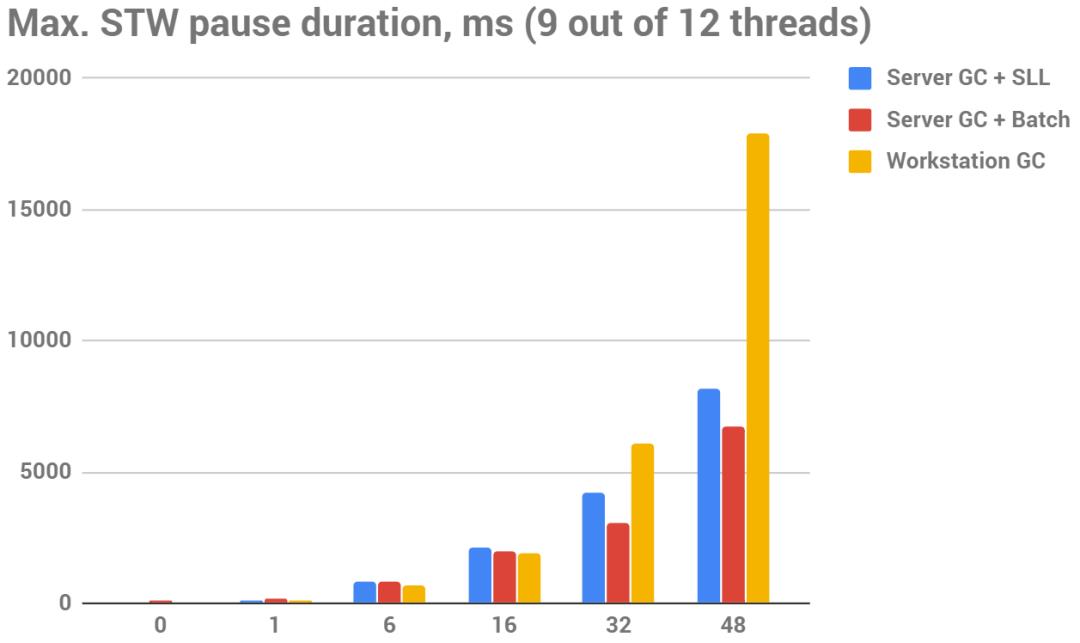

我不得不添加这个表格(来自提到的谷歌电子表格--见那里的最后一张表格)来展示具体的数据:
工作站GC实际上只有在静态集大小< 16 GB时才有较小的STW停顿;超过16 GB后,从这个角度来看,工作站GC的STW越来越大--与服务器GC + Batch模式相比,在48 GB的情况下,工作站GC的STW时间几乎增加了3倍。
有趣的是,在静态集大小≥16GB时,服务器GC+Batch开始击败服务器GC+SLL--也就是说,在大堆上,批处理模式的GC实际上比并发GC的暂停时间要小。
最后,服务器GC + SLL和服务器GC + Batch在暂停时间方面实际上是相当相似的。也就是说,.NET上的并发GC显然没有做太多的并发工作--尽管它在我们的具体案例中实际上可能是相当高效的。我们在主测试之前创建了静态集,所以似乎没有必要重新定位--几乎所有GC要做的工作就是标记活着的对象,而这正是并发GC应该做的事。因此,为什么它产生了与批处理GC几乎一样的可耻的长停顿,这完全是个谜。
你可能会问,为什么我们没有测试服务器GC+Interactive mode--事实上,我们做了,但没有注意到与服务器GC+SLL的明显区别。
结论
.NET Core
在Gen2集合上有O(alive_object_count) STW暂停时间--无论你选择什么GC模式。很明显,这些暂停时间可以是任意长的--完全取决于你的活体集的大小。我们在200GB的堆上测量了125秒的暂停时间。
在分配突发事件上快得多(3 ... 12倍)--这种分配真的类似于.NET上的堆栈分配。
在持续的吞吐量测试中,通常会快20 ... 50%。"静态集大小=200GB "是唯一的情况,当Go继续前进。
你永远不应该在.NET Core服务器上使用工作站GC--或者至少你应该准确地知道你的工作集小到足以让它受益。
并发模式(SustainedLowLatency或Interactive)下的服务器GC似乎是一个很好的默认值--尽管它与Batch模式没有什么区别,这实际上是很令人惊讶的。
Go
没有O(alive_object_count)的STW暂停--更准确地说,似乎它实际上有O(alive_object_count)的暂停,但它们仍然比.NET的短100倍。
几乎所有的暂停都短于1ms;我们看到的最长的暂停是1.3秒--在一个巨大的~200GB的活体集上。
在GCBurn测试中,它比.NET慢。Windows + i7-8700K是我们测量到最大差异的地方--也就是说,似乎Go在Windows上的内存分配器有一些问题。
Go无法处理 "静态集=75%内存 "的情况。Go上的这个测试总是触发OOM。同样,如果你运行这个测试足够长的时间(2分钟=~50%的失败几率,10分钟--我记得只有一个案例没有崩溃),它在"静态集合=50%内存 "的情况下也会可靠地失败。似乎,GC根本无法跟上那里的分配速度,而像"只使用75%的CPU核心进行分配"这样的事情也没有帮助。不过不知道这在现实生活中是否可能很重要:分配是GCBurn的全部工作,而大多数应用程序并不只是做这个。另一方面,持续的并发分配吞吐量通常低于非并发的峰值吞吐量,所以现实生活中的应用程序在多核机器上产生类似的分配负荷看起来并不虚构。
但是,即使考虑这些,在GC无法跟上分配速度的情况下,做什么更好也是可以争论的:是暂停应用几分钟,还是以OOM方式失败。我打赌大多数开发者实际上更喜欢第二种选择。
两者的相同点
峰值分配速度与突发分配测试中的核心数呈线性关系。
另一方面,持续并发分配的吞吐量通常低于非并发的峰值吞吐量--也就是说,持续并发的吞吐量不能很好地扩展,无论是对于Go还是对于.NET。似乎不是因为内存带宽的问题:总的分配速度可以比可用带宽低10倍。
免责声明和后记
GCBurn被设计用来测量一些非常具体的指标。我们试图让它在某些方面接近现实生活,但显然,这并不意味着它所输出的数据就是你在实际应用中一样的。就像任何性能测试一样,它的设计是为了测量它应该测量的极值--而忽略了其他几乎所有的东西。因此,请不要对它抱有更大的期望 ????
我知道方法论是可以争论的--坦率地说,在这里很难找到不可以争论的东西。因此,撇开小问题不谈,如果你对为什么像我们这样评价GC可能是大错特错,请留下你的意见。我一定会很乐意讨论这个问题。
我相信有一些方法可以改进测试,而不需要大幅增加工作量或代码。如果你知道如何做到这一点,请你也留下评论,或者干脆作出贡献。
同样,如果你在那里发现了一些bug,请你也这样做。
我有意不关注GC的实现细节(代数、压缩等)。这些细节显然很重要,但有很多关于这方面的帖子,以及关于现代垃圾收集的一般帖子。不幸的是,几乎没有关于实际GC和分配性能的帖子。这就是我想做的事情。
如果你愿意把这个测试翻译成其他语言(如Java),并写一个类似的帖子,那将是非常了不起的。
至于我的 "Go vs C#"系列,下一篇文章将讨论运行时和类型系统。由于我不认为有必要为此写几千个LOC测试,所以应该不会花那么多时间--敬请期待吧
P.S. 查看我们的新项目。Stl.Fusion是一个适用于.NET Core和Blazor的开源库,力争成为您的实时应用程序的第一选择。它的统一状态更新管道确实很独特,让人心动。
另外插播一个小广告
[苏州-同程旅行] - .NET后端研发工程师
招聘中级及以上工程师,优秀应届生也可以,我会全程跟进,从职位匹配,到面试建议与准备,再到面试流程和每轮面试的结果等。大家可以直接发简历给我。
工作职责
负责全球前三中文在线旅游平台机票业务系统的研发工作,根据需求进行技术文档编写和编码工作
任职要求
拥有至少1年以上的工作经验,优秀的候选人可放宽
熟悉.NET Core和ASP.Net Core
C#基础扎实,了解CLR原理,包括多线程、GC等
有DDD 微服务拆分 重构经验者优先
能对线上常见的性能问题进行诊断和处理
熟悉mysql Redis MongoDB等数据库中间件,并且进行调优
必须有扎实的计算机基础知识,熟悉常用的数据结构与算法,并能在日常研发中灵活使用
熟悉分布式系统的设计和开发,包括但不限于缓存、消息队列、RPC及一致性保证等技术
海量HC 欢迎投递~
薪资福利
月薪:15K~30K 根据职级不同有所不同
年假:10天带薪年假 春节提前1天放假 病假有补贴
年终:根据职级不同有 2-4 个月
餐补:有餐补,自有食堂
交通:有打车报销
五险一金:基础五险一金,12%的公积金、补充医疗、租房补贴等
节日福利:端午、中秋、春节有节日礼盒
通讯补贴:根据职级不同,每个月有话费补贴 50~400
简历投递方式
大家把简历发到我邮箱即可,记得一定要附上联系(微信 or 手机号)方式哟~
邮箱(这是啥格式大家都懂):aW5jZXJyeUBmb3htYWlsLmNvbQ==
以上是关于[翻译]Go与C#的比较,第二篇:垃圾回收的主要内容,如果未能解决你的问题,请参考以下文章