[翻译]Go与C#对比 第三篇:编译运行时类型系统模块和其它的一切
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[翻译]Go与C#对比 第三篇:编译运行时类型系统模块和其它的一切相关的知识,希望对你有一定的参考价值。
Go vs C#, Part 3: Compiler, Runtime, Type System, Modules, and Everything Else | by Alex Yakunin | ServiceTitan — Titan Tech | Medium
目录
译者注
相似性
编译
垃圾回收
模块
类、结构、接口
错误处理
相等性(==, !=)
基础类库
两种语言中存在的其他类似特征
类似的反模式/设计错误
C#中缺少的Go功能
Go中缺少的C#功能
异步执行 第一部分回顾
Sequences, Rx, IAsyncEnumerable
运行时性能
后记
译者注
本文90%通过机器翻译,另外10%译者按照自己的理解进行翻译,和原文相比有所删减,可能与原文并不是一一对应,但是意思基本一致。
译者水平有限,如果错漏欢迎批评指正
本文发表于2020年1月,当时使用的.NET Core版本应该是3.1,Go版本应该是1.13版本。而现在.NET版本已经到6 Pre5,Go也到了1.16,经过这么多版本的迭代,Go和.NET的性能都有很大提高,所以数据仅供参考,当然也欢迎大家能在新的版本上跑一下最新的结果发一篇帖子出来。
译者@Bing Translator、@InCerry,另外感谢@晓青、@贾佬、@晓晨、@黑洞、@maaserwen、@帅张、@3wlinecode、@huchenhao百忙之中抽出时间帮忙review和检查错误。
原文链接:https://medium.com/servicetitan-engineering/go-vs-c-part-3-compiler-runtime-type-system-modules-and-everything-else-faa423dddb34
这一个系列中还有其他两篇文章:
第一篇:Goroutines vs Async-Await 【中文翻译版】
第二篇:Garbage Collection. 【垃圾回收-中文翻译版】

想知道谁在这里吗?请一直读到最后。
这是本系列中最后一篇,希望是最有趣的一篇。第一篇和第二篇主要研究了Golang的协程和几乎无暂停的GC,这篇文章补充了所有缺失的部分。
相似性
两种语言的相似性:
可以编译成本机代码
可以在多个平台上运行
依赖于垃圾收集
支持模块【.NET中是程序集(assemblies)】
支持类【在Go中叫结构(structs)】,接口【interfaces】和函数指针【function pointers .NET中叫委托(delegates)】
提供一套错误处理的选项
支持异步执行
拥有丰富的基础类库
具有类似的运行时性能
但是在这些功能的实现上,差异多于相同之处。让我们跳到这一部分 ????
编译
Go编译成本机二进制文件,也就是说它的二进制文件是与它所编译的操作系统“捆绑”在一起的【作者应该指的是平台相关性】。
.NET Core默认编译跨平台的二进制文件,你需要通过.NET Core Runtime 的 "dotnet [executable]"命令来运行程序;这些二进制文件包含了MSIL代码,这是一种类似Native Code的代码,通过.NET的JIT【即时编译器】来编译。JIT编译的效率很高,它缓存了以前编译的模块【当你安装.NET Core时,BCL的大多数模块都被预先编译和缓存了】,它的速度很快,默认情况下,它在第一次调用时生成没有复杂优化的代码,当它发现方法被频繁调用时,就会生成一个优化的版本【分层编译】。也就是说你可以免费得到一个"轻量级的PGO【Profile Guided Optimization】"。
你一样可以使用.NET Native来制作一个完全AOT的本地二进制文件【应该是指NGen和NativeAOT】。
垃圾回收
在表面上,两者非常相似,但是他们的实现过程存在巨大的差异。
.NET的GC是针对于吞吐量(内存分配速率)和运行时性能进行优化的【.NET GC 分代+标记整理算法】:
它是分代的,这也就意味着它的构建对CPU的缓存非常友好,当你的代码在运行时,它最近分配或者使用过的对象很可能都在CPU的L0(那是0代的位置)或者在L1缓存中(那是1代的位置)。
因为它是一个具有整理功能的分代GC,所以在C#中分配内存的消耗很低:基本上就是一个指针自增+比较,也就是说堆内存和栈内存分配消耗一样的小。
劣势也是因为它需要进行整理。它分配的每个对象可能会在堆中移动几次(每代(Gen0~Gen2)之间的转移 + Full GC),更糟糕的是,整理意味着.NET必须修正它所移动的任何对象的引用指针【由于整理后对象地址发生变化,需要重新建立引用】,对象可能在CPU寄存器中,在栈上或者在队中,所以它在整理时需要更长的暂停时间来进行修正工作【详情可参考垃圾回收过程】。
与之相反,GO的垃圾回收被设计成几乎无暂停的【Go GC】:
它对缓存不那么友好,老实说,除了让相同类型的对象彼此能靠近外,它对缓存不友好。
Go没有分代GC,所以每一次GC都是Full GC,如果你的应用程序快速的分配和取消引用对象,你更有可能看到OOM或者分配失败,因为GC没有足够快的扫描对象图来释放未引用的对象。
但是它同样没有整理和指针修复带来的问题,这意味着Go应该有一个完全无暂停的GC,Go需要为每个指针都花费一点额外的时间(如在GC的"标记"阶段,标记每个目标引用都为"活着"状态,当然,细节是很复杂的)。但是Go并不是从一开始就没有暂停,在2017年左右,开发者设法将其暂停时间减少到毫秒内。
Go中低停顿时间是用牺牲性能的代价来替换的,如果你想了解更多的细节,请翻阅本系列的第二篇,不过那里的比较是在.NET Core 2.1下进行的,我计划下周分享我最新的更新,将使用.NET Core 3.1和Go 1.13.6,但是初步来看,差距很大。
下图,突发分配速度-单位GB/s(越大越好)
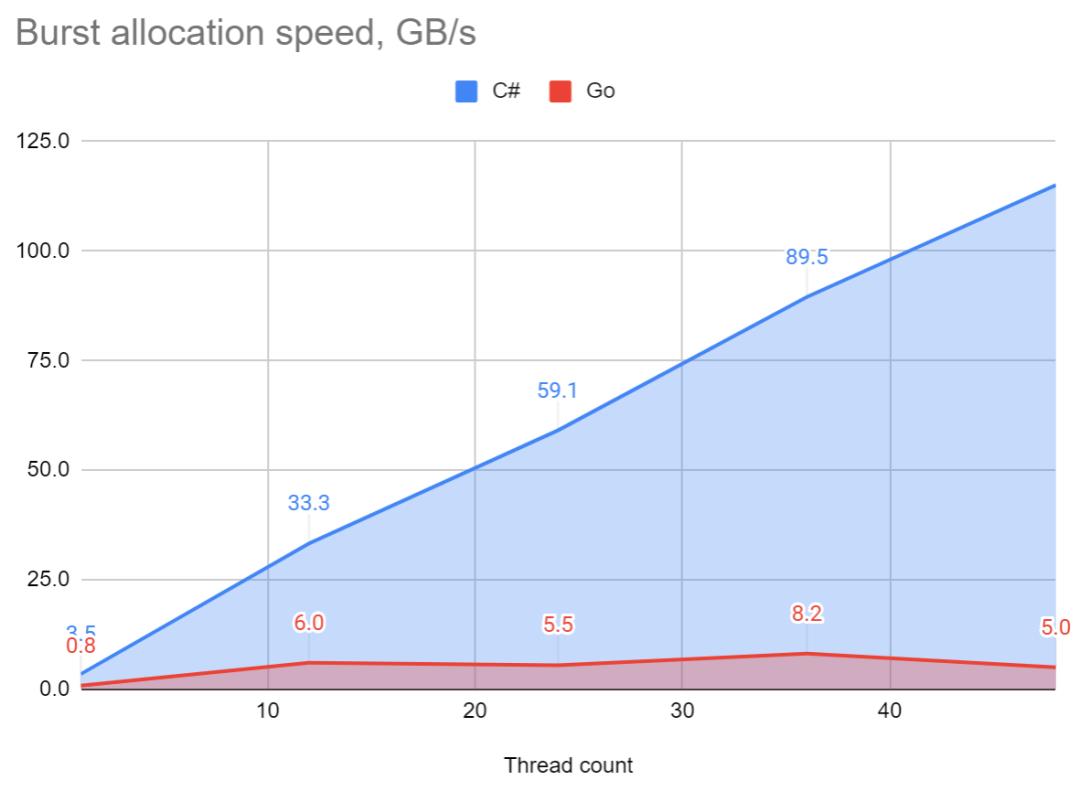
在单线程突发内存分配测试中,C#要快4.5倍。当线程数量到到48个时,差异将增长到23倍。C#每秒7.7亿次分配与Go的0.34亿次分配。
在分配速度与.NET上的线程数和核心数呈线性关系(测试机上1至48核心),至于Go,它在12至36个线程范围内达到最大值,但是当它接近48个线程时,分配速率下降了近40%(0.33亿次)。
对于分配速度和STW暂停时间,我们可以比较在48核上使用36个线程分配32GB静态集合的结果:
.NET 10.05GB/s的分配速度,最大暂停时间2.6秒,百分之99.99%的暂停时间72ms。
Go 2.89GB/s的分配速度,最大暂停时间0.1秒,99.99%的暂停时间46ms。
"我们可以比较…."意味着这是Go在128GB上能够完成的最复杂的测试;它在每一次的测试中都以OOM的方式崩溃(静态集合>=1GB 和 线程数=48/48核心)。此外,它在(静态集合>=64GB, 线程数=36/48核心)上使Windows桌面管理器奔溃,目前为止还不清楚怎么回事,感觉它是在OOM时是冻结了而不是终止所以导致Windows桌面管理器崩溃。
.NET Core完成了所有测试,并且没有OOM。
下图:持续分配速度-单位GB/S(越大越好)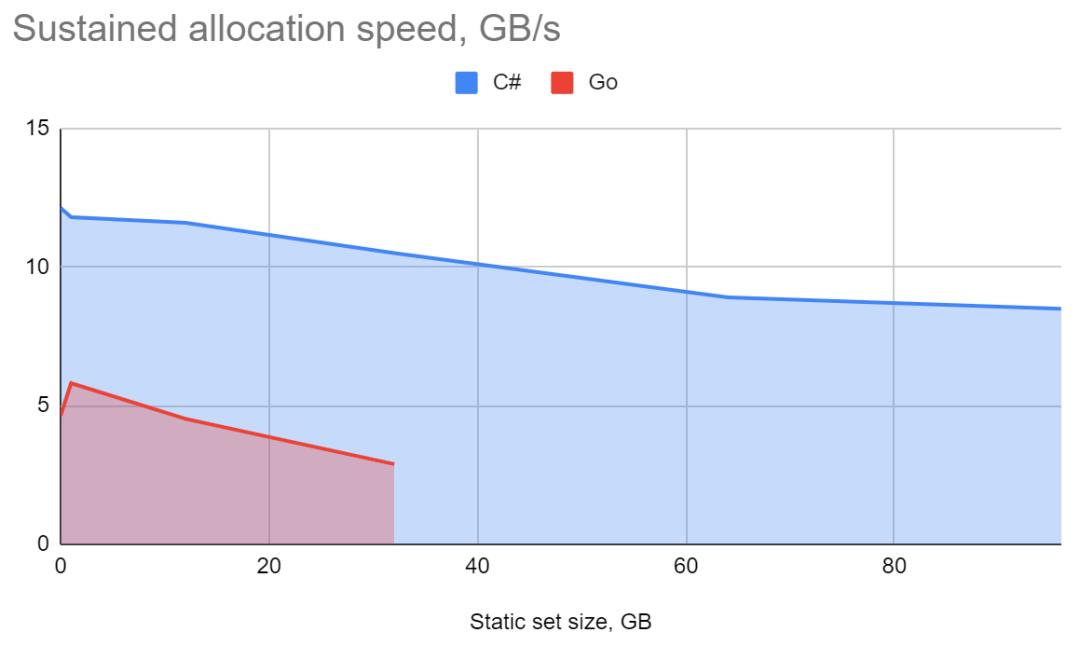
下图:最大STW停顿时间-单位ms(越小越好)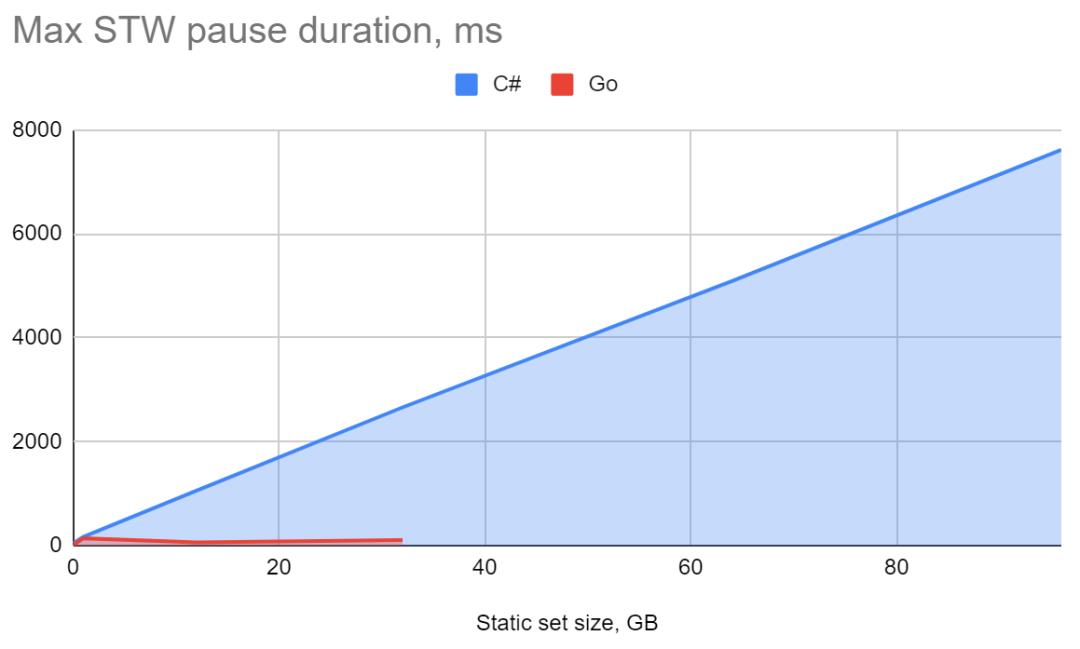
下图:STW停顿时间-99.99%基线 单位ms(越小越好)
如果你对详情感兴趣,可以点击链接看原始的测试数据【机器配置:AMD 线程撕裂者3960x 和 128GB内存】,现在只有Windows上的测试。
模块
同样的,表面上一样,但是本质上非常不同。
Go中的相关概念:
包【Package】:一个有源代码的文件夹。所以添加一个包意味着你在你的项目中添加更多的源代码。每个包只有在它或者它依赖的包发生变更时才会被重新编译。只有Go关注包编译版本,你甚至不应该知道它的存在。包最终会产生库或者可执行的文件,尽管库没有明确的编译结果,它们最终是以源代码的形式被使用的。
模块【Module】(1.13版本新增):一个包含了模块的版本、所有依赖关系、源码和.mod的文件夹。它可以被发布到Go模块库。
同样,在C#中也有3个与模块相关的概念:
项目【Project】:一个包含了C#文件 + .csproj文件的文件夹,该文件描述了他所有依赖关系和程序集的属性。
程序集【Assembly】:它是一个项目编译结果,它包含了MSIL代码+描述它的元数据(方法、类型等)。记住,.NET依靠它的JIT编译器来运行代码,所以基本上.NET程序集像C语言中的.obj(或.o) + .h/.hpp文件的混合体。它们不存储源代码,尽管所有的符号和编译后的实现都在那里。同样,程序集可以库,也可以是可执行文件,或者两者都是(没有什么可以阻止你从包含入口的程序中导入任何你想要的东西【作者应该是说可以通过Assembly.Load在运行时加载程序集,通过反射来调用程序集的方法,或者直接在项目中依赖一个可执行文件】)。
NuGet包【Nuget package】:一个.nuget文件(实际上它是一个zip压缩的文件),包含.NET程序集 + 其它你想要的东西 + .nuspec文件,这样的文件通常被发布到公共的NuGet仓库中,你也可以使用私人仓库。通常情况下,你引用NuGet包而不是你C#解决方案中的项目(.csproj文件);当你的项目被构建时(例如使用"dotnet build"命令),它会自动下载和安装。但由于NuGet格式与.NET无关,也可以使用其它工具如Chocolatey将其用于自己的包。
所以两者的区别就是Go的软件包含有源代码,而.NET的包没有源码吗?
不,最大的区别是.NET可以在运行时加载和卸载程序集,将其中的类型与当前的主程序集整合在一起,特备是以下这几种情况。
插件:你可以在你的应用程序中声明一个IMyAppPlugi接口,实现一个逻辑从Plugins文件夹中加载所有程序集,在那里创建所有实现了IPlugin类型的实例,并通过IPlugin.Embed(myApp)方式调用。这就是为什么.NET应用程序是具有扩展性的。
运行时代码生成:.NET有Reflection.Emit 和 LambdaExpression.Compile 方法(它底层使用Reflection.Emit)。两者都可以生成动态的程序集,而且几乎是实时的。你可以生成任何.NET代码,这个新代码可以使用当前运行时内所有类型,也可以生成自己的类型。这一特性被大量用于加速复杂的逻辑(所有主要的.NET序列化程序都使用这一特性;编译后的Regex实现性能让其它语言的实现方式都望尘莫及,包括Go)或者依赖注入的逻辑(大多数的IOC容易都依赖它),这也使得AOP方案成为可能。
代码层面的自检:由于你的代码可以访问应用程序任何部分的MSIL和元数据,你的代码可以自检(像Cecil这样的工具对此帮助很大);例如,生成在GPU上并行运行的版本(查看这个样例子ILGPU)。
所有这些都使一些奇怪的(但显然是相当有趣的)场景成为可能:例如,即使是那些从来没有想过要扩展的应用程序,也因为这个而以黑客的方式得到扩展。我所知道的最明显的现代例子是Beat Saber,过去两年中最流行的VR游戏,我是它的忠实粉丝。不同的人为它制作了50多个插件和20000多个社区制作的地图,尽管这个游戏没有官方的插件API。怎么做到的?嗯,它主要是一个.NET应用程序 - Beat Saber是建立在Unity上的,它使用C#/.NET作为其主要的 "脚本 "语言。有许多针对.NET的开源工具(Fody, Harmony)能够对已经编译好的程序集进行后处理,以嵌入、改变或删除你喜欢的东西。所以有人为Beat Saber制作了BSIPA,它将插件的调用端点直接嵌入到游戏程序集中,并确保游戏在启动时加载插件。Viola! Oculus Quest版本的Beat Saber有一个类似的mod(BMBF),即使Quest运行在android上(但Unity for Android仍然运行.NET)。
Go提供了"插件"包,技术上允许你动态加载.so文件,但是:
只能工作在Linux和Mac OS上
主机和插件的编译环境必须完成相同,特别是所有包引用必须完全匹配。
还有很多其他的缺点,所以 "很多人误解了插件今天能做什么。他们目前不容易使第三方为你的应用程序制作插件;[......]在实践中,只有原始构建系统可以可靠地构建插件。这些问题充满了人们在构建环境中发现的所有小差异。"
这就解释了为什么Hashicorp(Terraform、Consul、Vault等背后的公司--他们要求第三方供应商提供一种编写插件的方法)依靠他们自己的插件API在子进程中托管插件并通过IPC调用它们。
类、结构、接口
C# 同时具有类和结构体(值类型):
类总是生活在堆中,结构体生活在调用栈和堆中。如果生活在堆中,要么是作为其它类的字段,或者以装箱的形式存在。因此"new"关键字:对于类,进行堆分配+调用它的构造函数。对于结构体:只是调用构造函数,此时已经为结构体保留了内存空间(在当前的栈上,或者堆上的类或结构体中)
类永远都是引用传递,结构体默认是值传递,你可以通过(in/ref/out parameter/ref return/ref struct,在有些情况下手受限的)【详情戳我】进行引用传递。
类可以有虚方法也可以继承其他类,结构体没有虚方法也不能继承。
当打包成数组时,结构体需要的内存大小就是它各个字段每项的大小。类的话是指针(64位系统占用8字节)+ 显然还有它本身实例的内存。
每个实例在堆中都有两个指针,一个指向虚方法表(类型描述符)和一个系统保留的指针大小的数据(存储一个用来比较的伪随机值+为GC和同步保留几个byte)。
所有接口类型的值都需要一个指针。
然后Go只有结构体,但是:
它们支持通过嵌入的方式进行集成【组合模式】。
结构体能存在于堆中或者调用栈上:
默认的情况下,你创建结构体时不会明确的指定它应该在哪创建,逃逸分析可以帮助编译器决定其放置在哪里,调用栈或者堆上。据我所知它可以把它放在调用栈上,然后在移动到堆上,你也可以明确的在堆上分配结构体。
Go中的堆存储对象没有对象头,因此结构体在goroutine栈、堆、其他结构体的字段以及数组/片中占用相同的空间。没有堆头意味着没有好的方法来实现此类对象的基于引用的相等比较。如果你没有发现其中的联系,不要担心,我将在后面的 "相等【Equality:相等性,平等,按照上下文意思判断两个实例是否一样】"部分解释。
结构体没有虚方法,但是结构体可以实现接口。所以你可以将一个结构体强转成接口。
有趣的是,它的接口类型的值需要两个指针(所以它们在64位的平台上需要16字节或者两个CPU寄存器):第一个指针指向底层的结构体,而第二个指针指向接口的方发表,所以类型信息在.NET上是和对象一起呆着,因为类型信息在实例header里面。而Go中类型信息是通过指针指向的。
这两种方法都有明显的优点和缺点。
总的来说,Go中的结构体与.NET中的结构体工作原理非常类似。只是.NET中的结构体还需要有一些改进(嵌入+转换到接口时不需要装箱)。
.NET需要更多的时间来调用接口成员(虽然它缓存了对接口方法表的引用,但是仍然需要更多的时间)。
Go需要更多的空间来传递接管口的引用(在寄存器中,在调用栈中,在数组和切片中,等等)。
这里值得一提的是,Go:
需要从几乎所有可能失败的方法中返回"err"值(错误类型,这是一个接口)。
总是通过调用堆栈来传递值,而不是通过寄存器。另外,请注意每个调用的不寻常的“序言”,它检查堆栈扩展的潜在需求【作者应该是说Go为了实现协程的协作式抢占,sysmon 协程标记某个协程运行过久,需要切换出去,该协程在运行函数时会检查栈标记,然后让出当前线程给其它协程用,详情可以看这篇文章】。这是Go实现协程付出的代价,其它大多数的静态语言在每次调用时都不做这样的额外检查【据我所知,在Go 1.14版本通过SIGURG信号的方式实现了异步抢占,但是不清楚会不会带来其他性能问题】。
因此,这个额外的 "err "需要在调用栈上增加16字节。此外,从调用中得到 "err "的代码必须对 "err == nil "进行额外的检查......这种每个调用的 "额外"(调用栈上的16字节+两次比较)是不是有点太昂贵了?
还有一些其它看法:
在Go中,接口字段的大小超过了机器字的大小,所以它不能被原子化地更新。我不确定这是否会造成任何大的问题,但我知道在.NET中经常会有指针被原子化更新(例如,指向一些共享的不可变模型的根)。尽管在大多数情况下,将接口指针包装成一个结构并使用它的指针的解决方法可能是可行的--只是访问速度会慢一点(解决一个额外的指针)+ 更新时需要额外分配。
从好的方面看,这个功能(似乎--我没有检查过)允许Go将任何结构(例如存储在数组中或另一个结构的字段中)投向它所支持的接口,而不需要装箱。对于.NET来说,这是不可能的(尽管你可以在通用方法中实现类似的功能,也就是说,有一些变通方法可以让你在类似情况下摆脱额外的分配)。
总体而言,Go模式似乎更简单/更有吸引力:
没有对象头(我猜如果需要分代GC,你还是需要对象头)。
没有值类型和引用类型。
结构体嵌入+接口的集成似乎更容易理解,而且更接近于底层。
但这一切都不足以成为交易的障碍;此外,Go也有自己的问题,例如,我发现了逃逸分析有一些缺陷;早些时候,我写过关于切片的一个类似问题,下面的 "相等性 "部分描述了另一个问题。因此,我觉得可能会有更多这样的问题......尽管我对它还不够了解,不能肯定地声称这一点。
目前的结论是两者打平。
错误处理
C# 使用"经典"的异常处理,如果你对此细节感兴趣,可以查看我的这篇Exception Handling 101文章。
Go 选择了一条相当独特的道路,有两种选择:
显式错误传递:有一个优雅的约定,一个可能失败的方法返回的最后一个值必须是"err"(错误类型),如果一切正常,则为nil(空指针),如果不正常,则为某个对象,调用者必须明确的检查nil。
还有defer、panic和recover,这是不优雅的失败处理。
但是我不得不提的是,Go的模式显然更耗性能:
.NET经典的异常处理方式只有在发生异常的时候才会有性能损耗,否则几乎没有性能损耗。
相反,Go的异常处理模式让你的程序为每一个返回"err"的调用和每一个"defer"买单。
最后,如果panic→recover模式与常规异常处理没有太大区别,您是否仍然觉得到处返回“错误”的最初想法在概念上仍然是好的——否则为什么你需要两者?
相等性(==, !=)
它在.NET和Go中的工作方式完全不同。
首先,简单介绍一下:相等性通常需要的两个操作:
比较两个实例是否相等
以符合相等性的方式来计算实例的hashcode【实例相等hashcode必然相等】
这意味着如果实例相等那么hashcode必须是相等的,对于不相等的实例则hashcode极有可能不相等(它们是可能相等的,这被称为哈希碰撞)。换句话说,如果你比较实例的hash值,如果它们不相等,那么实例肯定不相等;如果hash值相等,那也说明不了什么,这些实例也可能不相等。
最后,对于不可变的实例来说,hash值不应该随时间而变化。Set、Map和集合都依赖于hash值,如果你把(key1,value1)放到一个hashmap中,然后key1的hash值改变了,那么map[key1]将查找不到value1。
所有这一切意味着相等和Hash对于可变对象几乎没有意义——除非你在 Equals 和 GetHashCode 操作中只使用它们的不可变部分:
如果没有GC压缩,内存中的对象地址就符合“不可变部分”的特征。它对于每个对象都是唯一的,而且永远不会改变。
还有一些对象从其公共API方面看是不可变的,但其内部状态是可变的,例如,因为它们缓存了一些东西。例如,它可能是你自己的字符串包装器,它缓存了字符串的哈希代码以避免重新计算(假设你处理的字符串可能很长)。它的全部状态是可变的,但其中公开的部分是不可变的。这就是为什么你可以为它实现相等性和哈希代码的计算。
在.NET上,相等性大多是用户定义的,你必须为结构体(逐值传递类型)手动编码,而且【详情可以看如何重写Equals方法】:
通常情况下,你会将大部分的结构标记为只读(不可变)。GetHashCode和Equals可以直接的实现。
如果你在写非只读结构,你应该应用我上面描述的规则,即理想情况下,只比较不可变的部分。
Visual Studio和Rider可以自动生成Equals和GetHashCode的实现。
与结构体相反,类(pass-by-reference类型)自动获得基于引用的平等:如果两个引用指向同一个实例,那么它们就是平等的。通常情况下,你不会改变这一点,尽管你可以。
基于引用的平等需要在具有压缩GC的语言中进行一些额外的处理。你不能假设指针在未被触动的情况下保留其价值--指针在堆压缩时被GC修正。这个问题给基于指针的平等带来了额外的问题:也许你可以实现比较(你需要原子地读取和比较两个指针),但你如何计算哈希值,它必须对同一个指针保持不变,即使它改变了?
在.NET中,这个 "额外 "是一个存储在对象头中的伪随机数,它作为一个哈希代码用于引用平等。不幸的是,我不知道它是如何计算的,尽管它很可能是由对象地址和一些种子(很可能是一个加法)衍生出来的,这些种子会随着时间的推移而变化(如果你有压缩,可能会匹配到很多地址)。
但在GO中却非常不同,在GO中,总是进行结构上相等比较。我猜这是由于两个因素。
所有的结构都表现得像是通过值传递的,尽管指针是在幕后传递的。由于指针是你在这里不应该考虑的东西,从相等性的角度来看,忽略它也是合乎逻辑的。
我写道,基于引用的相等性需要头或类似的东西,在一个有压缩GC的语言中。尽管Go还没有压缩的GC,但它保留了在未来添加它的可能性。这就是为什么它明确地禁止你假设指针是稳定的。但是由于Go中的所有对象都没有头,基于引用的相等性在这里是不可能的。
这样做的后果之一是接口的相等性如何:如果底层实例具有相同的类型,并且在结构上是相等的,它们就是相等的。对于比较而言,在.NET和Java中,如果且仅当它们属于同一个实例时,接口是相等的(即基于引用的相等)。
此外,在Go中:
你不能重写相等性的工作方式,即使对于你自己的类型。结构相等性是你所拥有的全部【作者的意思应该是只没办法通过自定义的方式两个实例是否相等,比如在一个结构中有id,name这些字段,在业务场景中只要id字段相等就认为是相等,C#可通过重写Equals实现,Go则不行】。
没有标准的哈希函数/API用于相等判断,也没有办法在Go中调用map类型使用的内部哈希函数,所以如果你需要为你自己的集合提供哈希,Go不能帮你解决这个问题。而且据我所知,甚至关于如何暴露它的讨论也还没有结束。
似乎没有办法让例如map依赖你自己的相等比较器(有时你需要这样做),而且说实话,我不知道如何实现一个假设相等总是结构性的变通方法,例如,即使你开始用你自己的包装器替代键,包装器仍然不能覆盖他们自己的平等/哈希,所以...
像往常一样,有利有弊。
在这里,Go胜在比较简单:是的,Go里面更容易理解平等的作用。
而在其他方面上都输了:有很多非常通用的情况下,你确实需要一个自定义的相等判断逻辑或基于引用的相等性判断。
基础类库
这里最显著的区别是.NET BCL有相当数量的方法和接口被C#编译器特别对待(尽管编译器并没有寻找特定的接口。它寻找的是具有相同名称的方法)。一些例子【这可能说的就是鸭子类型】。
IDisposable/IAsyncDisposable:在 "using "语句中使用,提供对资源处置的支持/(类似stream.Close的情况)。在实现中,编译器会寻找是否存在Dispose/DisposeAsync方法。如果你需要处理托管或非托管资源,你要实现这些接口中的一个。
IEnumerable<T> & IAsyncEnumerable<T>:在 "foreach "循环和带有 "yield return "的方法中使用,提供对序列枚举的支持。在实现中,编译器会寻找GetEnumerator方法。
Task/Task<T>/ValueTask/ValueTask<T>:用于 "await "表达式,提供对异步完成通知的支持。在现实中,编译器会寻找GetAwaiter方法。
Enumerable/Queryable.Select/Where/...(数十种其他扩展方法):用于LINQ表达式(见 "from"、"where"、"select"、"group "及其他关键字);编译器将这些表达式转换为方法调用链。
IEquatable<T>和IComparable<T>接口:NET中所有的通用集合都依赖它们来测试相等或相对顺序。特别是,Dictionary<TKey, TValue>使用IEquatable<T>来比较相等和获取HashCode。
即使是最基本的类型,Object也提供了GetHashCode()和Equals(...),你可以在子类中重写,+ GetType()和其他一些你可以调用的方法。
相反,Go只为系统类型(切片、映射等)提供语言支持(即特殊语法),但没有任何接口或类型可以实现或扩展,这些都是语言所支持的。
主要内容:
C#与它的BCL很好地结合在一起。相等性/哈希、序列/LINQ、资源释放--所有这些都被C#部分地支持。
Go采取了不同的方式,尽可能少地提供这种集成。
两种语言中存在的其他类似特征
Go的切片(Slice)约等于.NET中的Span
扩展方法:非常类似,你可以自由地将方法 "附加 "到Go或者.NET中的任何结构(类)和接口上。
这两种语言都支持不安全指针/不安全代码。
类似的反模式/设计错误
这两种语言都有null/nil指针的十亿美元的错误,但C#在几个月前通过nullable引用类型解决大部分问题【作者应该是指null指针是个坑爹的东西,绝大多数的问题都是因为null指针】。
大括号,为什么,为什么不只是缩进?????【我觉得大括号挺好的,(逃】
C#中缺少的Go功能
类似Go的异步执行模型,下面有专门的章节介绍goroutines和async-await【这其实本质是stackcopy和stackless协程实现方式的区别】。
公共/私有成员的约定而不是额外的关键字,C# 成员声明中的修饰符的数量有时甚至会吓到老手:“protected internal static readonly 真的吗?真的”【我也觉得这个比较复杂,常用的也就public protected private】 。
主要就是这样。
Go中缺少的C#功能
拿起一杯咖啡,这个列表很长。
泛型 - 说实话,这很重要。如果你看看其他任何现代静态编译语言,泛型都在那里。而我担心要把它们添加到Go中是相当困难的,主要是因为其静态类型系统。我将进一步展开,但这的主要后果是:
在Go上设计真正有效的通用数据结构和算法比较困难(尽管它的一些特性,主要是接口的实现方式,部分地缓解了这一问题)。
很明显,由于这个原因,你在编译器支持的类型检查方面受到了更多限制。同样,这不是你不能没有的东西,但泛型和类型检查是(可以说)开发人员越来越倾向于使用TypeScript而不是javascript的主要原因。
有一种观点认为Go中没有添加泛型以使事情更简单 ,这显然不是真的。 泛型根本就没有那么容易实现。在一种旨在在运行时具有静态类型系统的语言中。在这种情况下,它不是添加,而是一次重大的重构;此外,这可能是 Go 路线图上最基本的功能。这解释了为什么泛型是在大约 2.5 年前宣布的,但仍然没有与之相关的 PR/问题(我尽了最大努力寻找这个;也许我错了)。
泛型影响着你写的一切,但最主要的是--你的BCL。老实说,你应该早些加入它们,而不是晚些--你越是等待,你的BCL的大部分内容就会在你加入它们之后变得过时。.NET的前4年(2002年...2006年)没有泛型,而且有些遗留问题仍然存在(例如Hashtable和System.Collections的其他非类型集合/接口仍然在BCL中--甚至在.NET Core中)。而Go现在已经有10年历史了。
Lambda表达式;更确切地说,Go提供了匿名函数(闭包),但没有对参数进行类型推理,所以依赖它们的代码看起来很丑。
序列生成器(带有 "yield return "的方法)。
LINQ(语言集成查询):有一些模块试图为Go实现LINQ-to-Enumerable。但即使快速浏览一下这些例子,也会发现那里既不方便,性能也不好。
缺少Lambda会让你写更多的代码。
缺少的泛型使你把每个函数参数从interface{}类型(它类似于C#中的Object)转换为它的实际类型,这是对函数的每次调用都要评估的标准。
编译器不能帮助你进行任何类型检查--所有的序列都有相同的类型(像.NET中的IEnumerable)。
操作符重载,在某些情况下相当有用(例如,像BigInteger和Vector
这样的类型明显受益于此;重载==和≠也很常见)。所有这些都意味着DSL(特定领域的语言)在Go中更难构建。相反,它们在C#中很容易建立,而F#,它的引号、计算工作流和类型提供者,简直是DSL构建者的天堂。但是DSL重要吗?好吧,这里有一些关于.NET的DSL的例子:
WebSharper将任何F#底阿妈(在F#上特别装饰的代码)转化为JS,有效地将F#本身变成DSL。
像ILGPU(免费软件)、AleaGPU (商业的,虽然对消费级GPU来说是免费的)和Hybridizer(商业的)这样的项目使你能够在任何.NET语言上编写CUDA内核(即在GPU上运行你的代码),或者使用GPU以高度并行的方式处理你的数据,而这是不需要使用任何其他语言。
LINQ数据提供者形成了另一个子集,实际上是建立在C#之上的DSL--这就是你在那里主要用来访问和处理数据的东西。LINQ to enumerable的使用相当频繁,可能,在每一个处理某种序列的其他方法中。如果你对它很熟悉,写几行代码而不是像".GroupBy(x ⇒ x.Name).OrderBy(g ⇒ -g.Count).ToList() "这样的单行字,感觉相当不方便。
元组,肯定也很有用。注意,Go中的多个返回值完全不是一回事;Tuples+out参数是你在C#中类似情况下使用的。
Nullable<T>/Option<T>类型,我想Go需要泛型来做这个,所以......
表达式树--LINQ-to-Queryables/LINQ提供者的一个重要部分。
模式匹配。
枚举?迭代器?
特性【Attributes】,同样是相当频繁使用的功能。
"using "关键字/IDisposable接口,显然Go没实现是一个很大的失误
SIMD【单指令多数据流,可以利用CPU的指令集如SEE、Avx2等等】内建支持,是的,它们可以帮助你在一些问题上达到近乎C++的速度。
而且还有很多不那么重要的功能:
动态绑定
字符串插值
属性自动完成
匿名类型
事件,虽然不是什么大问题,我想Rx正在到处取代事件,而且委托足以实现你自己的这些版本
索引和范围、范围表达式、输出参数、默认参数值、默认接口方法、只读成员、nameof表达式...
异步执行 第一部分回顾
如果你对goroutines和async-await的详细比较感兴趣,请查看第一部分【比较结果已经比较老了,不过还具有一些参考意义,文章开始放了国内大佬的翻译版本】,要点是:
Go吊打了C#,如果我们比较C#和Go异步编程的便利性,你在Go中基本上是免费获得的(就编码而言),尽管你为这种便利性付出了每一次调用的一小部分性能。
如果你可以看到数以百计的async-await语句,你也会对C#感到满意。但在学习了Go中的工作方式后,你不会喜欢那里的async-await,尽管几乎所有其他语言都使用同样的模型(async-await)【C++、Rust、Js、Python都实现await/async】。
值得一提的是,C#中的async-await机制允许你实现你自己的类似任务的对象,例如你自己的轻量级任务。感觉就像一个加分项,虽然到目前为止我还没有使用过这个:)。
因为执行模型非常不同,所以性能很难比较。没有最近的基准;至于过去的基准(大约1-2年的时间),C#和Go非常接近。
Sequences, Rx, IAsyncEnumerable<T>
本节主要是为了证明为什么goroutines几乎和泛型一样重要。
.NET BCL至少提供3种类型的序列:
IEnumerable<T>是用于交互式("拉")和同步序列的。调用者(通常--通过 "foreach "循环)从一个序列中 "拉 "出项目,这使得枚举者做一些工作来提供它。它是同步的,因为所有的处理程序都是同步的。
IObservable<T>是用于反应式编程("推")和同步序列的。调用者将项目(事件)"推送 "到一个事件序列中,其订阅者因此而运行一些计算(例如,在他们自己的序列中产生项目)。
IAsyncEnumerable<T>是反应式-交互式同步-异步序列。它的调用者可以异步地等待这样一个流中的下一个项目,因此它的处理程序既可以是同步的也可以是异步的(而且,你不会为此付出很大的代价--IAsyncEnumerator<T>.MoveNext()返回ValueTask<bool>,也就是说,同步调用不应该有分配)。
除此之外,C#还提供了一种特殊的语法糖,允许你以一种非常方便的方式编写返回IEnumerable<T>和IAsyncEmumerable<T>(序列生成器)的方法(使用 "yield return "来返回下一个项目)。
所以C#在这里有很多花哨的东西,Go则没有。现在有一个你可能没想到的说法:任何Go的序列实现都会自动提供所有这3种序列类型的特征。等等,什么?好吧,Go中的任何函数都是同步的和异步的。所以要在Go里面创建一个反应式的序列,你需要:
一个反应式的项目生产者+一个类似IEnumerator的类型,在其MoveNext()方法中等待生产者通道中的下一个项目。
一个IEnumerable.Consume()方法,在一个新创建的goroutine中枚举该序列,直到结束。
但是(一个很大的 "但是")。Go没有泛型,没有lambdas,所以没有类型检查,语法更加冗长,需要把每个处理程序的参数投到它的实际类型,性能更差,等等,也就是说,我所描述的只是一个梦,现实要黑暗得多。
向语言开发人员提出几个问题:
你如何证明人类,而不是机器必须处理与异步编程相关的相当愚蠢的工作--假设我们现在写的几乎所有代码至少是潜在的异步的?
为什么Go是唯一能很好解决这个问题的语言?从表面上看,goroutines肯定比泛型更容易实现。那么为什么其他语言的开发者忽视了简单复制一个好的解决方案的机会呢?
运行时性能
总的来说,它是相似的。但值得一提的是,目前C#在大多数测试中几乎吊打了Go @Computer Language Benchmark Game:
下图运行速度,越大越好

C#唯一输掉的测试是数学问题,这有点令人惊讶。迅速检查一下就会发现。
“pidigits”依赖于一个大整数的外部库,也就是说,它更像是一个对这个库的性能测试+外部函数调用测试。
"mandelbrot "的第一个 "for "循环假设Vector<double>.Count(硬件SIMD寄存器的双倍数大小)总是2,尽管实际上它与硬件有关,在现代CPU上它至少应该是4,最有可能的是,这个测试仅仅由于一个错误而慢了2倍。
"n-body "不使用SIMD--无论是C#还是Go。这就解释了为什么两者的性能都很低(+/-JIT时间,这实际上包括在C#的每一个计时中),也解释了为什么C++(7.30s)在这方面领先这么多:它的代码通过SIMD内在因素进行了大量的优化。Rust如此,Fortran也是如此--也就是说,所有优秀的性能都依赖于SIMD。
速度系数的几何平均值是1.53倍,它是显著的。
你要知道:几年前,C#在这些测试中落后于Java--但这主要是因为CLBG上的所有测试都是在Ubuntu上运行的,而Mono(开源的跨平台.NET运行时,曾经比.NET Framework慢了2倍)是在.NET Core之前在Ubuntu上运行C#代码的唯一方法。最后,.NET Core本身明显比.NET Framework 4.X快--即使在Windows上。
后记
为什么开发人员会从一种编程语言转到另一种?有大量的因素:
该语言是否越来越流行?
学习曲线有多陡峭?
我是否能找到一份需要这种语言的好工作?
它能为我的下一个项目提供理想的性能吗?
我喜欢它的语法吗?
而一旦你有了更多的经验,你肯定会在自己的类似列表中增加一项:你每天要写多少丑陋的代码来解决你的典型问题。
这就是为什么我非常喜欢C#(F#也是,但这是另一个故事):
LINQ和IEnumerable<T>的方法调用比一组嵌套的 "for "循环短得多--此外,它们同样快速,更容易阅读和理解。
泛型允许你有一个单一的抽象实现,对其任何类型的参数都同样有效,所以你不必手工维护一组版本,这些版本大多是相互模仿的。
我显然可以继续下去,但是......。
我开始研究Go,希望能看到类似的东西。尽管Go有近乎完美的异步编程模型(你所有的代码都自动既是同步的又是异步的),而且我们现在写的大部分代码都有可能是异步的,但这足够吗?
老实说,不,一点也不。如果你忽略了goroutines,就很难找到其他令人信服的理由来使用这种语言。
而且不幸的是,不仅仅是我在抱怨--还有很多人在抱怨。我强烈建议你去看看《Go:好的、坏的和丑的》,不幸的是,我是在已经写好这份文件的时候才发现它的,否则,它可能会大大缩短。这正是我对Go的感觉:它是好、坏、丑的混合体。这篇文章中的两句名言。
......看起来Go的设计发生在一个平行宇宙中[......],在那里,90年代和2000年代发生在编译器和编程语言设计中的大部分事情都没有发生。
......一方面,我可以谈论几个小时关于Go是多么可怕的事情。另一方面,Go显然是一种非常好的语言。
所以我目前对C#与Go的立场是。
目前,.NET几乎在所有方面都处于领先地位,唯一大的例外是异步执行。
如果.NET实现了Go风格的同步-异步执行模型,我就找不到令人信服的技术理由去看Go了,你可能会注意到,Go中的其他东西几乎都不如.NET,尽管它当然还有其他一些(但要小得多)的瑰宝。
同样,一旦Go实现了泛型和lambdas,我肯定会开始更加关注它。但说实话,它需要的东西太多了......

如果你了解我,你也知道我是个爱猫人士
请注意,对于地鼠先生来说,情况并不像看起来那么糟糕--如果你没有注意到,他在这张照片上用枪对付猫先生。所以他绝对是安全的,而猫显然有点害怕。谁知道呢--也许再过几年,地鼠先生再多长几磅,他甚至不需要枪了 ????
Go在人们心目中的简单性对开发者来说无疑是有吸引力的。我在挖掘各种文档和例子时的观察是,在Goland有很多真正的编程大师,也有纯粹的高手。像这样的帖子(其作者显然不了解Go的独特之处,但仍对其大加赞赏)让我觉得自己又回到了.NET的早期,我确信我过去也写过类似的关于.NET的东西:)
如果.NET核心团队@微软--在忙于增加数以千计的ReadWriteLockUnlockAcquireReleaseCopyPasteAsync重载的同时,赢得了每一场微小的战斗,却因为忽略了一次解决所有这些问题的机会而输掉了战争,这实在令人遗憾。
同样,如果Golang团队再花几年时间继续容忍没有泛型、相当糟糕的分配/GC性能("为了微小的STW暂停花费了多少?一切。"),以及相当多的其他领域(例如,感觉Golang "否认 "了函数式编程,简单地避免了与FP有关的任何东西:),那就太可惜了。).
因此,如果你喜欢这个系列和/或想引起微软和谷歌对这里强调的一些问题的注意,请分享/加注/发送给你认识的有影响力的人 ????
P.S. 查看我们的新项目。Stl.Fusion是一个适用于.NET Core和Blazor的开源库,力争成为您的实时应用程序的第一选择。它的统一状态更新管道确实很独特,让人心动。
另外插播一个小广告

[苏州-同程旅行] - .NET后端研发工程师
招聘中级及以上工程师,优秀应届生也可以,我会全程跟进,从职位匹配,到面试建议与准备,再到面试流程和每轮面试的结果等。大家可以直接发简历给我。
工作职责
负责全球前三中文在线旅游平台机票业务系统的研发工作,根据需求进行技术文档编写和编码工作任职要求
拥有至少1年以上的工作经验,优秀的候选人可放宽
熟悉.NET Core和ASP.Net Core
C#基础扎实,了解CLR原理,包括多线程、GC等
有DDD 微服务拆分 重构经验者优先
能对线上常见的性能问题进行诊断和处理
熟悉mysql Redis MongoDB等数据库中间件,并且进行调优
必须有扎实的计算机基础知识,熟悉常用的数据结构与算法,并能在日常研发中灵活使用
熟悉分布式系统的设计和开发,包括但不限于缓存、消息队列、RPC及一致性保证等技术
海量HC 欢迎投递~
薪资福利
月薪:15K~30K 根据职级不同有所不同
年假:10天带薪年假 春节提前1天放假 病假有补贴
年终:根据职级不同有 2-4 个月
餐补:有餐补,自有食堂
交通:有打车报销
五险一金:基础五险一金,12%的公积金、补充医疗、租房补贴等
节日福利:端午、中秋、春节有节日礼盒
通讯补贴:根据职级不同,每个月有话费补贴 50~400
简历投递方式
大家把简历发到我邮箱即可,记得一定要附上联系(微信 or 手机号)方式哟~
邮箱(这是啥格式大家都懂):aW5jZXJyeUBmb3htYWlsLmNvbQ==
以上是关于[翻译]Go与C#对比 第三篇:编译运行时类型系统模块和其它的一切的主要内容,如果未能解决你的问题,请参考以下文章