Java虚拟机之内存模型
Posted 愉悦滴帮主)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java虚拟机之内存模型相关的知识,希望对你有一定的参考价值。
前言:
我们在学习JVM的内存模型的时候,需要先了解JDK相关的知识作为铺垫。
一、 JDK体系结构
1、JDK概念图
JDK: JDK提供了编译、运行Java程序所需的各种资源和工具;包括Java编译器,Java运行时环境【JRE】;开发工具包括编译工具(javac.exe) 打包工具(jar.exe)等。
- JRE: 即JAVA运行时环境,JVM就是包括在JRE中,以及常用的JAVA类库等;
- SDK: SDK是基于JDK进行扩展的,是解决企业级开发的工具包。如JSP、JDBC、EJB等就是由SDK提供的 ;

2、JDK常用的基础命描述:
javac:Java编译器,将Java源代码换成字节代
java:Java解释器,直接从类文件执行Java应用程序代码
appletviewer(小程序浏览器):一种执行html文件上的Java小程序类的Java浏览器
javadoc:根据Java源代码及其说明语句生成的HTML文档
jdb:Java调试器,可以逐行地执行程序、设置断点和检查变量
javah:产生可以调用Java过程的C过程,或建立能被Java程序调用的C过程的头文件
Javap:Java反汇编器,显示编译类文件中的可访问功能和数据,同时显示字节代码含义
jar:多用途的存档及压缩工具,是个java应用程序,可将多个文件合并为单个JAR归档文件。
htmlConverter——命令转换工具。
native2ascii——将含有不是Unicode或Latinl字符的的文件转换为Unicode编码字符的文件。
serialver——返回serialverUID。语法:serialver [show] 命令选项show是用来显示一个简单的界面。输入完整的类名按Enter键或"显示"按钮,可显示serialverUID。
3.Java的跨平台性
大多数开发者在刚接触Java语言的时候应该都写过:(向控制台打印一句Hello Word)这种代码。
我们的Java代码如何实现跨平台的呢?请看下图:
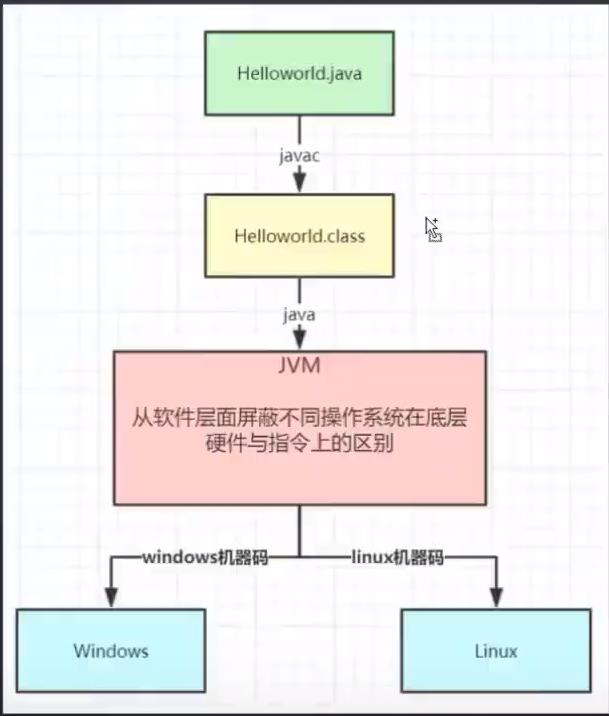
首先通过javac编译字节码文件,再通过Java命令运行编译后的字节码文件生成对应的二进制机器码。那么在Windows环境下生成的机器码与Linux环境下生成的机器码是不一样的。
那么为什么说Java是一次编译到处运行的呢?
我们当初在安装JDK时会选择不同环境下的版本,如Windows环境对应的版本和Linux环境对应的版本。如果想要执行字节码文件,目标平台必须要安装对应环境的JVM(java虚拟机),JVM会将字节码翻译为相依与平台的计算机指令;进而从软件层面屏蔽不同操作系统底层硬件与指令上的区别;有了JVM,Java程序就达到了“编译一次到处运行”的跨平台目的。所以到这里。我们就知道了java程序跨平台性好的根本原因就是java虚拟机JVM存在的原因。
二、JVM之类加载过程
学习Java的类加载过程一定绕不开jvm的内存模型,想必大家看过很多相关概念,但是发现JVM的概念太抽象不能理解,作者我也看不懂。所以我们通过对比代码来分析Java的类加载过程与JVM的内存模型。代码示例如下:
public class Math {
public static final int initData = 666;
public static User user = new User();
/**
* 一个方法对应一块栈帧内存区域
* @return
*/
public int compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
math.compute();
}
}上述代码很简单:调用main方法计算出c的值。那么在JVM中是如何运行的呢?如下图:
宏观:首先通过javac命令把Math.java这个类编译成字节码文件,然后再通过java命令再Java虚拟机额中去运行它。
微观:通过javac命令把Math.java这个类编译成字节码文件后执行Java命令的时候,Java虚拟机就已经开始工作了,Java虚拟机首先通过类装载子系统会像编译好的字节码文件装载到内存区里面去,也就是我们的运行时数据区(内存模型),然后通过调用字节码执行引擎去执行内存模型中的代码(注意这里的代码是指编译后的字节码)。
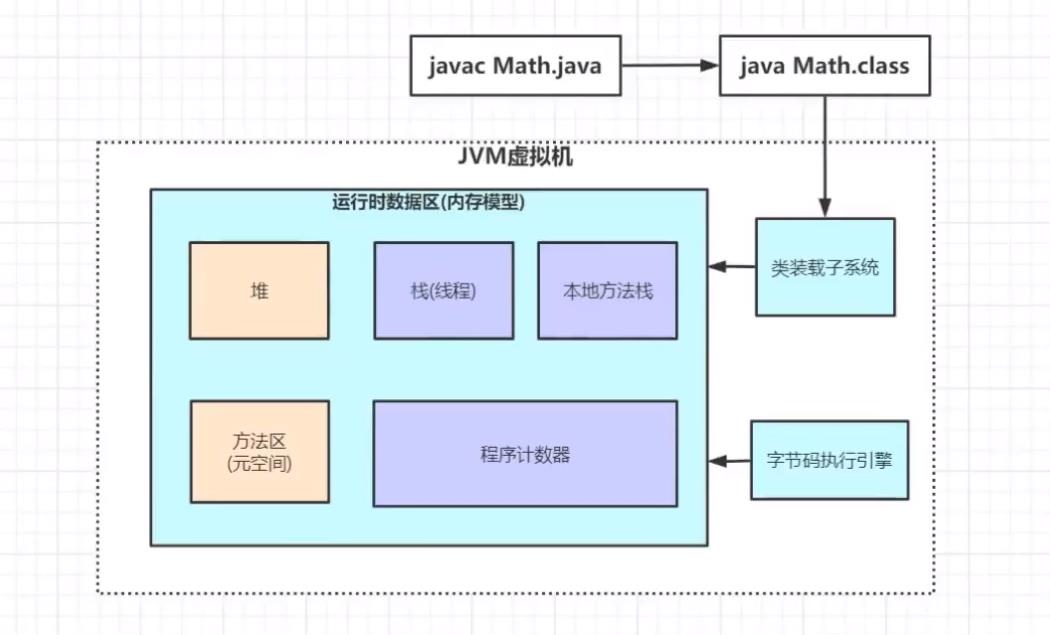
运行时数据区(内存模型)
不想看概念的小伙伴可以直接跳过该段落。继续阅读下一段落。不过建议看一下加深印象。
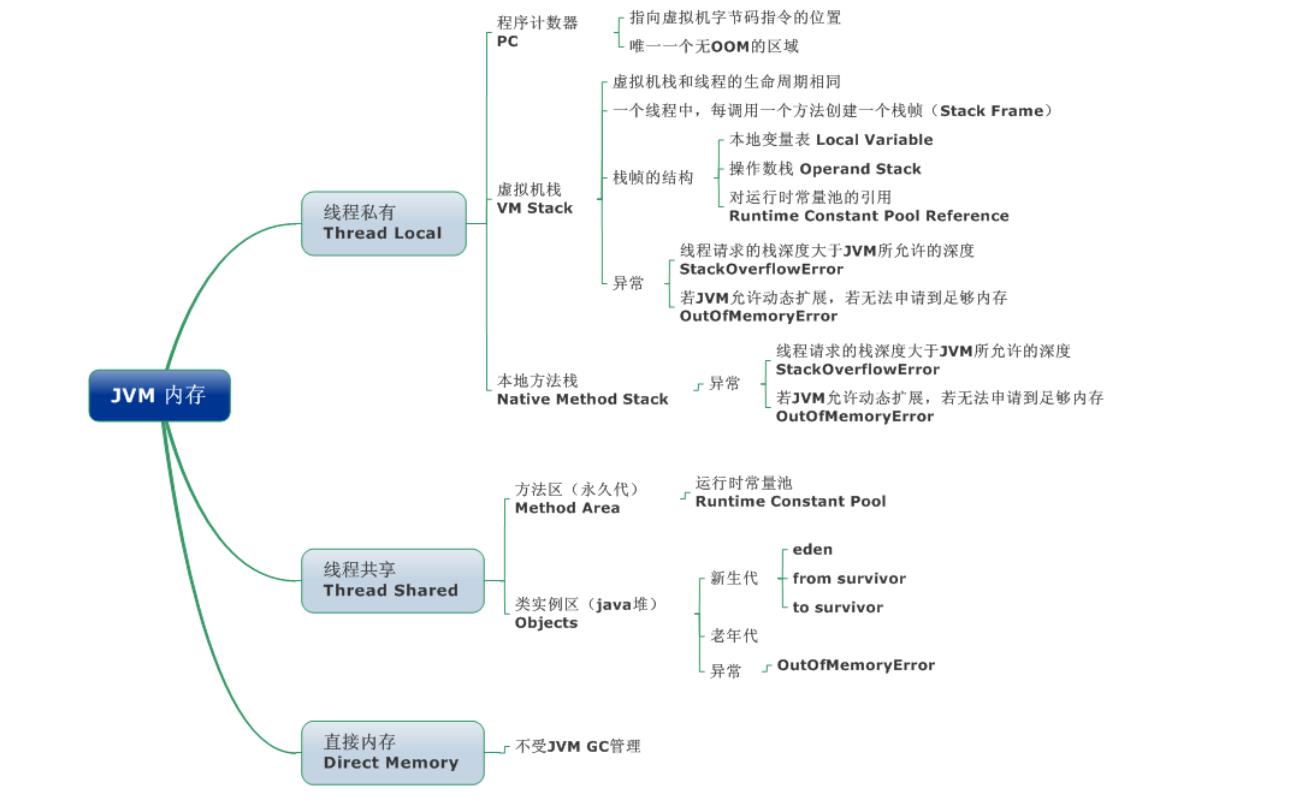
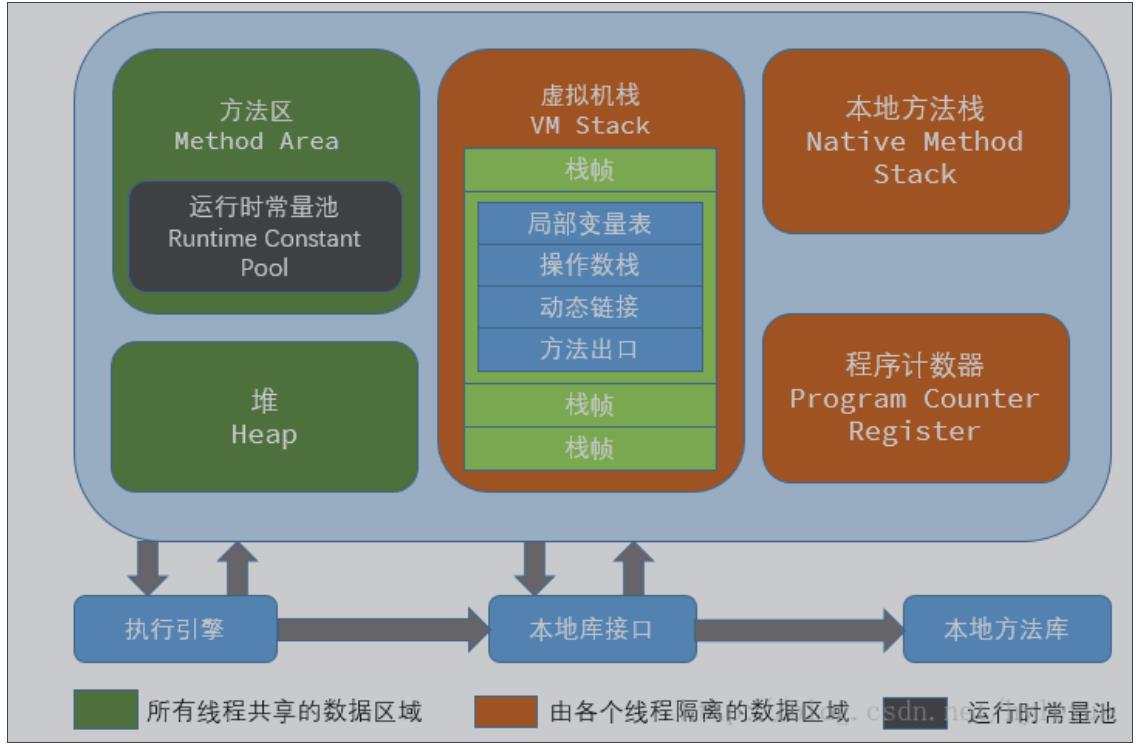
1. 程序计数器(线程私有)
2. 虚拟机栈(线程私有)
是描述java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame) 用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成 的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
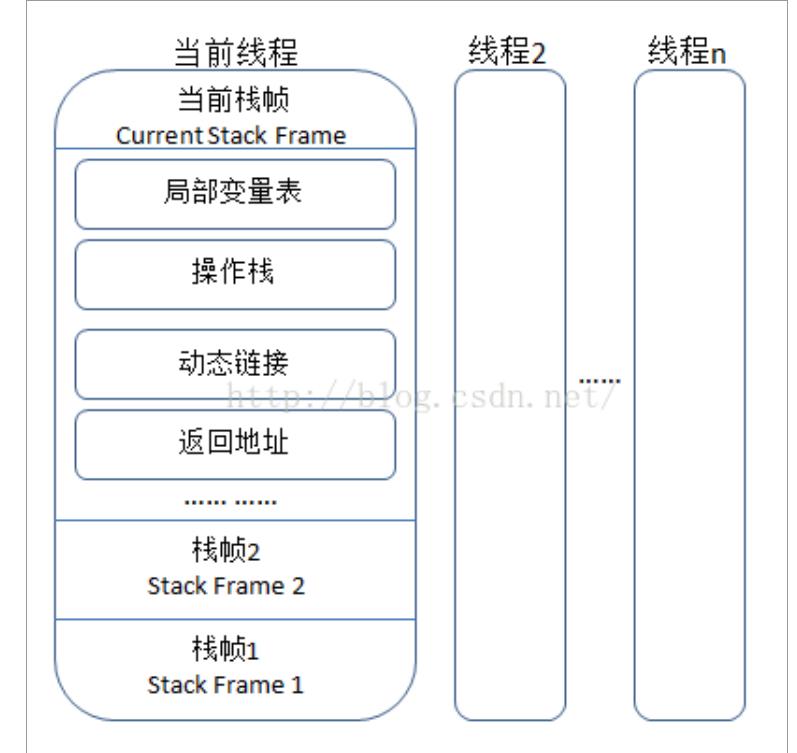
3. 本地方法区(线程私有)
4. 堆(Heap线程共享)-运行时数据区
5. 方法区/永久代(线程共享)
白话解释Java内存模型
我们还是回到上述代码。不记得的小伙伴可以看下图。
public class Math {
public static final int initData = 666;
public static User user = new User();
/**
* 一个方法对应一块栈帧内存区域
* @return
*/
public int compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
math.compute();
}
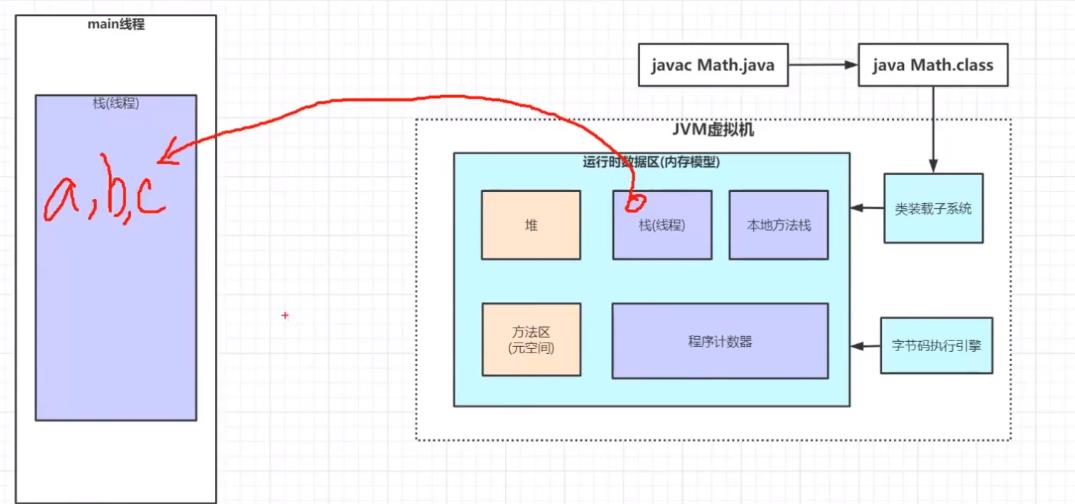
}我们调用主方法也就是main线程去运行compute()方法的时候,Java虚拟机会为主线程分配一块专属的内存区域,这个内存区域我们称之为栈。这块栈区域用来存放主线程的一些局部变量等信息。如果有其他线程Java虚拟机同样会为其分配一块内存区域。
如图:
上面我们说了栈的由来,说到栈肯定会涉及一个概念叫做栈帧。
那什么是栈帧?
我们上面提到只要主线程也就是我们的main方法运行,Java虚拟机就会为主线程分配一块内存空间。因为主线程里面要调用一些其他的方法,如:math.compute();方法。Java虚拟机也会在该方法运行时分配一块内存空间。用来放方法中定义的一些局部变量,如:a,b,c。那么为主线程里面的方法分配的内存区域称之为栈帧。
也就是说compute()方法在执行的时候会创建一个栈帧(Stack Frame),再栈帧中先开辟一块内存空间用于存储局部变量表、操作数栈、动态链接、方法出口等信息。如a,b,c。这些局部变量在方法执行完毕后会被销毁,也就是出栈。
我们知道栈的特性是先进后出,为什么呢?
我们结合代码分析:首先主线程main方法入栈,然后math.compute()方法入栈,等math.compute()方法运行结束后出栈,最后主线程出栈。这就是栈的先进后出的设计理念。
结构示例如图:
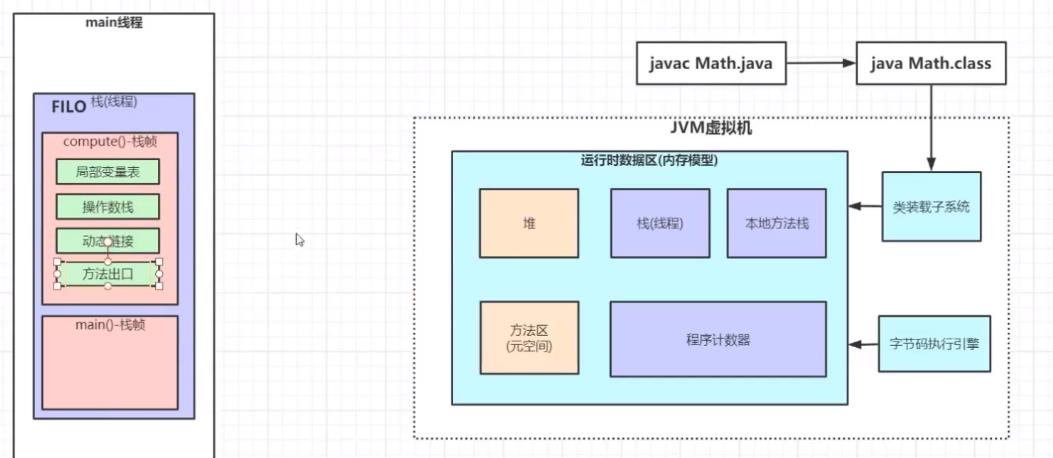
栈帧中也包括局部变量表、操作数栈、动态链接、方法出口等信息。我们要解释这些概念我们首先需要看下Java的字节码文件。我们查看Math .java的字节码文件。如下:

打开上述字节码文件我们并不能看懂,Oracle对该字节码文件有相应的API查看手册,有兴趣的小伙伴可以查看。这里我们运用JDK自带的指令。javap工具命令,如下图:
用法: javap <options> <classes>
其中, 可能的选项包括:
-help --help -? 输出此用法消息
-version 版本信息
-v -verbose 输出附加信息
-l 输出行号和本地变量表
-public 仅显示公共类和成员
-protected 显示受保护的/公共类和成员
-package 显示程序包/受保护的/公共类
和成员 (默认)
-p -private 显示所有类和成员
-c 对代码进行反汇编
-s 输出内部类型签名
-sysinfo 显示正在处理的类的
系统信息 (路径, 大小, 日期, MD5 散列)
-constants 显示最终常量
-classpath <path> 指定查找用户类文件的位置
-cp <path> 指定查找用户类文件的位置
-bootclasspath <path> 覆盖引导类文件的位置
运用javap -c命令对我们的字节码进行反编译生成我们能看的懂的代码。可以理解为Java虚拟机看的代码。如下图:
Compiled from "Math.java"
public class com.jvm.Math {
public static final int initData;
public static com.jvm.User user;
public com.jvm.Math();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int compute();
Code:
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: bipush 10
9: imul
10: istore_3
11: iload_3
12: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/jvm/Math
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method compute:()I
12: pop
13: return
static {};
Code:
0: new #5 // class com/jvm/User
3: dup
4: invokespecial #6 // Method com/jvm/User."<init>":()V
7: putstatic #7 // Field user:Lcom/jvm/User;
10: return
}
上述代码中的指令可以在Orcale官网中搜索。这里只列举上述代码对应指令的意思。
我们分析compute方法中的指令。首先来看前两行代码:
0:iconst_1 将int类型常量1压入操作数栈。
1:istore_1 将int类型的值存入局部变量1。
意思是:生成一个常量值为1的常量,放入操作树数中。然后生成一个局部变量a,并且将操作数栈中的常量1存到局部变量中。也就是 int a = 1;
后两行代码意思与前两行代码意思一样。int b =1;
2: iconst_2 将int类型常量2压入操作数栈
3: istore_2 将int类型的值存入局部变量2
如下图:
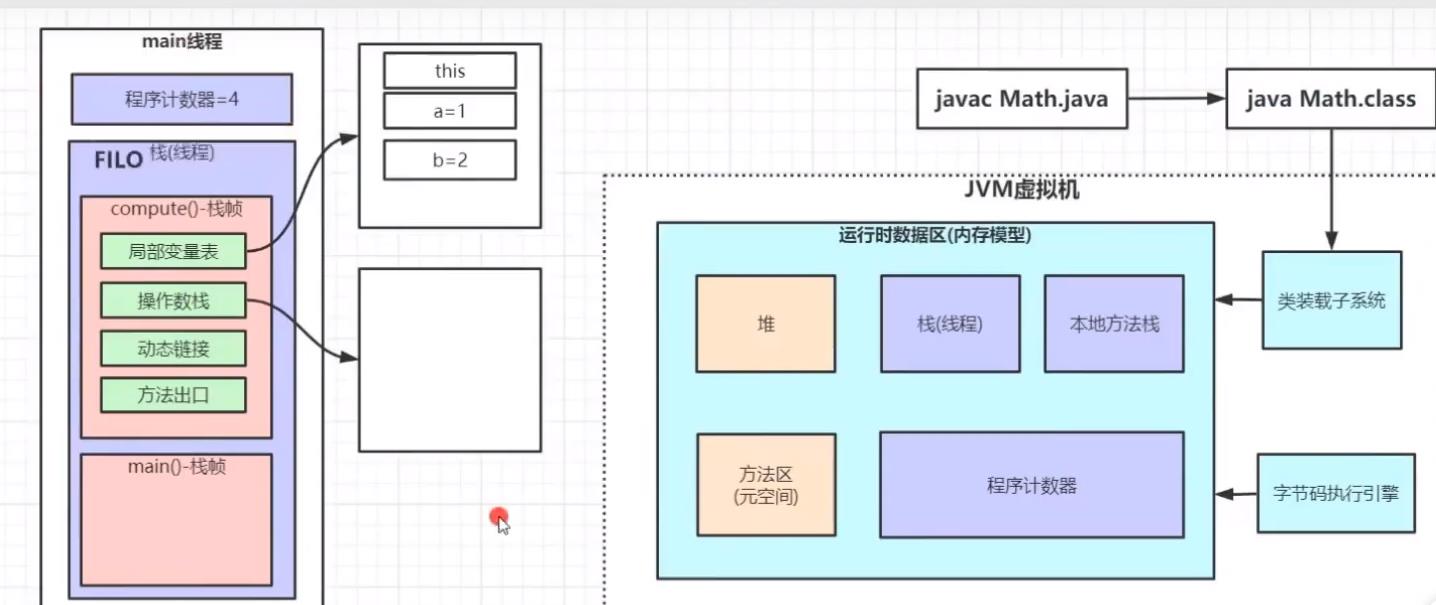
讲到这里我需要插播一下程序记录器。程序计数器同样的是在主方法或其他方法调用时Java虚拟机为其开辟一块内存空间,主要用来记录代码执行到第几行。 比如正在执行: 4: iload_1,表示正在执行第四行。实际上程序计数器储存的是这些代码在方法区存放的内存地址。我们后面分析方法区。
那我们Java虚拟机为什么要设计程序计数器呢?
大家都知道Java程序是多线程执行的,比如我们正在运行一个线程1,线程1的时间片到期,cpu轮询。这时候来个优先级很高的线程2,线程2抢到cpu,cpu去执行这个线程1,线程2只能暂时挂起。等到线程2执行完毕后再去执行线程1,这时候cpu是继续执行线程1中的代码,还是从头执行线程1 的代码?这时候就用到程序计数器,程序记录器记录了线程1暂时挂起的代码执行位置,这就是程序记录器设计的初衷。
回到正文,继续分析上述代码执行过程。
4: iload_1 从局部变量1中装载int类型的值。
5: iload_2 从局部变量2中装载int类型的值。
这两行代码意思就是:把局部变量a的值取出来,放到操作数栈中。把局部变量b的值取出来,放到操作数栈中。
6: iadd 执行int类型的加法。
Java虚拟机中会从操作数栈顶弹出1和2这两个结果,然后将这两个结果相加等于3,最后将3重新压入操作数栈。
7: bipush 10 将10压入操作数栈中
9: imul 执行int类型的乘法
Java虚拟机中会从操作数栈顶弹出3和10这两个结果,然后将这两个结果相乘等于30,最后将30重新压入操作数栈。
10: istore_3 将int类型的值存入局部变量3
11: iload_3 从局部变量3中装载int类型的值。
这两步代码上面已经讲过了,主要完成 int c = 30这一步骤
12: ireturn 返回结果
如下图:
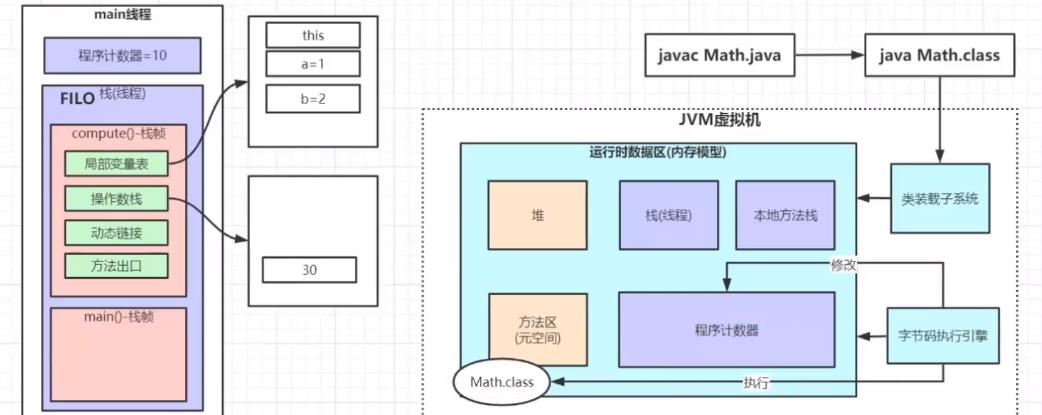
我们上面讲到程序记录器是用来记录代码执行的行号,那么谁来修改程序记录器呢?
我们知道Math.class的字节码文件主要加载到内存模型的方法区,由字节码执行引擎区执行代码,并修改程序计数器中的值。
以上解释了栈帧中的局部变量表,与操作数栈。
动态链接:我们在调用math.compute()方法的时候,会去找compute里面对应的代码,这些代码放在Java虚拟机里面的方法区中,动态链接就是用来存放这些方法里面对应代码的内存地址。也就是根据动态链接提供的地址能够早方法区找到对应方法的内存地址,然后才能去执行它。
方法出口:调用math.compute()方法执行完毕后,需要继续执行主方法,我们需要知道继续执行主方法的第几行代码,方法出口就是用来记录主方法的位置。

在这里我们需要特别介绍下:main主线程的局部变量表。主方法中Math math = new Math()有这么一行代码,我们知道对象都放在堆中,所以我们在局部变量表中需要开辟一块空间用来指向堆中的对象地址。这就是堆栈之间的关系。
方法区:
即我们常说的永久代(Permanent Generation), 用于存储被 JVM 加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。如图:
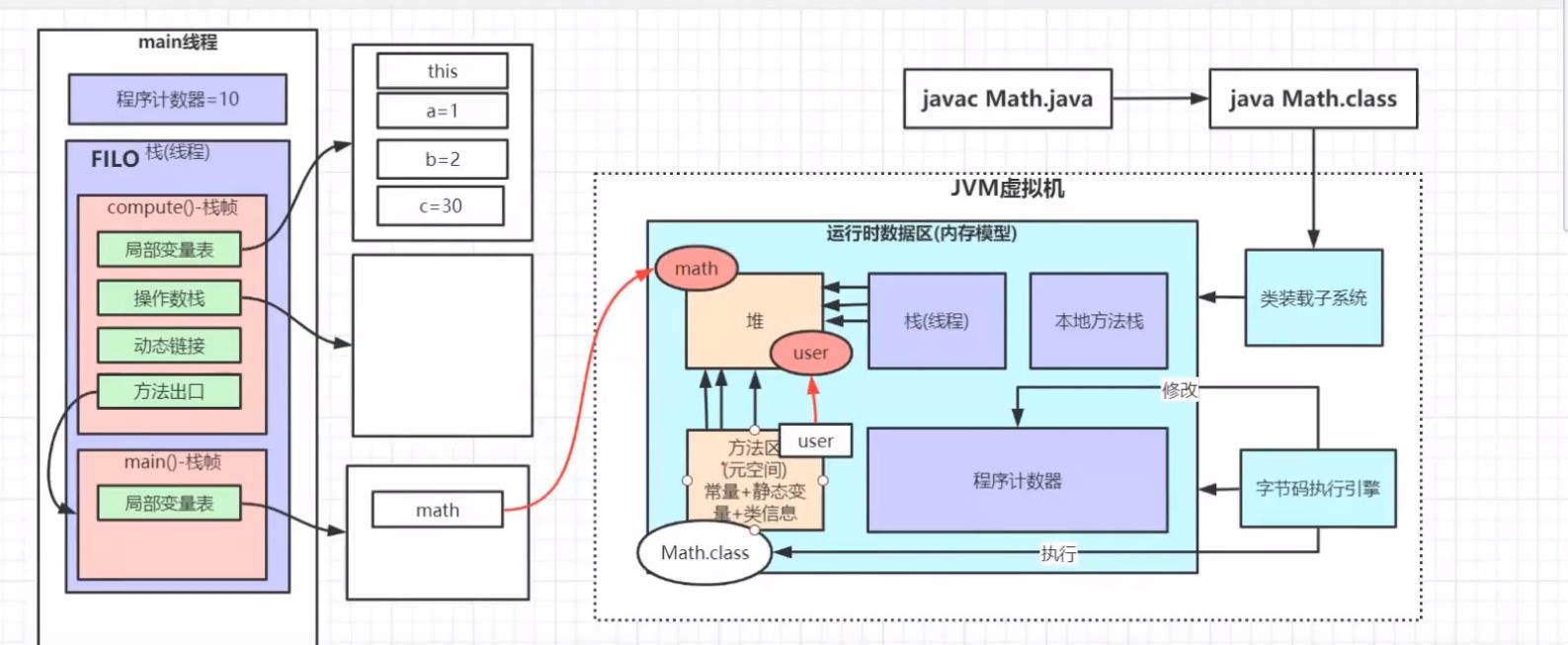
方法区如果静态变量如果是一个对象,那么方法区存储的就是该对象指向堆中的地址。这就将方法区与堆联系上了。
到这里已经介绍完了内存模型中的堆,栈,方法区,程序计数器。
private native void start0();被native修饰的就是本地方法。本地方法底层是用c++语言实现的。那么我们的本地方法在执行的时候也需要一块内存空间,这块空间就是本地方法区。
以上就是内存模型相关介绍,小伙伴门学会了吗。
以上是关于Java虚拟机之内存模型的主要内容,如果未能解决你的问题,请参考以下文章