什么是自然语言处理?
Posted 人邮异步社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是自然语言处理?相关的知识,希望对你有一定的参考价值。
自然语言处理(Natural Language Processing,NLP)是AI的一个领域,旨在让计算机理解和使用人类语言,从而执行有用的任务。自然语言处理又划分为两个部分:自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG)。
近年来,AI改变了机器与人类的互动方式。AI可以帮助人类解决各种复杂问题,例如,根据个人喜好向用户推荐电影(推荐系统)。得益于高性能GPU和大量的可用数据,人们现在可以创造出具有类似人类的学习和行为能力的智能系统。
有许多库旨在帮助人们创建这种系统。本章会介绍一些著名的Python库,用来从原始文本中提取和清洗信息。完全理解并解读语言这件事本身是一项困难的任务。例如,“C罗进了3个球”这句话对机器来说是很难理解的,因为机器既不知道C罗是谁,也不知道进球的数量意味着什么。
NLP中最流行的主题之一是问答系统(Question Answering System,简称QA),而这种系统又包含了信息检索(Information Retrieval,IR)。这种系统通过在数据库中查询知识或信息来进行回答,也能够从自然语言文档库中提取回答。搜索引擎都是这样工作的。
如今,NLP在业界越来越流行,最新的NLP趋势包括在线广告匹配、情感分析、机器翻译,以及聊天机器人。
NLP面对的下一个挑战是会话代理,俗称“聊天机器人”。聊天机器人可以进行真正的对话,很多公司利用这种技术来分析客户的行为和观点,以便获取产品反馈或者发起广告宣传活动。NLP的一个很好的例子就是虚拟助手,并且它们已经被引入市场中了。著名的虚拟助手包括Siri、亚马逊的Alexa,以及Google Home。本书会创建一个聊天机器人,用来控制一个虚拟机器人,并且它能够理解我们希望虚拟机器人做什么事情。
3.1.1 自然语言处理
如前所述,NLP是AI中负责理解和处理人类语言的一个领域。NLP属于AI、计算机科学和语言学的重叠部分,该领域的主要目标是让计算机理解使用人类语言表达的语句或文字。它们之间的关系如图3.1所示。
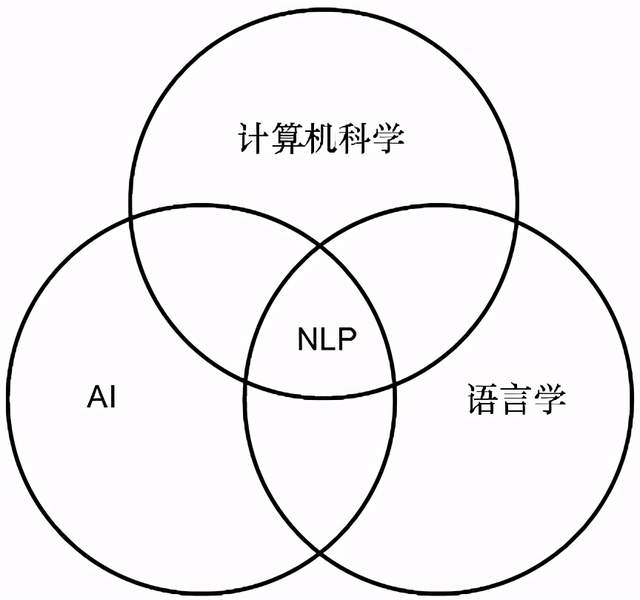
图3.1 NLP与AI、语言学和计算机科学的关系
语言学专注于研究人类语言,试图描绘和解释语言中的不同方法。
语言可以被定义为一组规则和一组符号,符号按照规则结合在一起,用来传播信息。人类语言是特殊的,不能简单描述为自然形成的符号和规则。上下文不同,词语的含义也可能不同。
NLP可以用来解决许多难题。由于可获取文本数据的数据量是非常大的,人们是不可能处理所有这些数据的。维基百科平均每天的新增文章数是547篇,文章总数则超过了500万篇。显然,一个人是无法阅读这么多信息的。
NLP面临着3个挑战,它们分别是收集数据、数据分类,以及提取相关信息。
NLP能够处理许多单调乏味的任务,例如垃圾邮件检测、词性标注,以及命名实体识别。利用深度学习,NLP还可以解决语音转文本的问题。NLP虽然显示出了强大的能力,但在人机对话、问答系统、自动文摘和机器翻译等问题上,还没有很好的解决方案。
3.1.2 自然语言处理的两个部分
如前所述,NLP可以划分为两个部分:NLU和NLG。
3.1.2.1 自然语言理解
NLP的这一部分旨在理解和分析人类语言,重点关注对文本数据的理解,通过对其进行处理来提取相关信息。NLU提供直接的人机交互,并执行和语言理解相关的任务。
NLU涵盖了AI面对的最困难的挑战,即文本解读。NLU所面对的主要挑战是理解对话。
NLP使用一组方法来生成、处理和理解语言,利用函数来理解文本的含义。
起初,人们使用树来表示对话,但许多对话的情况都无法使用这种方法表示。为了覆盖更多情况,就需要更多的树,每个对话的上下文对应一棵树,从而导致了很多句子重复,如图3.2所示。
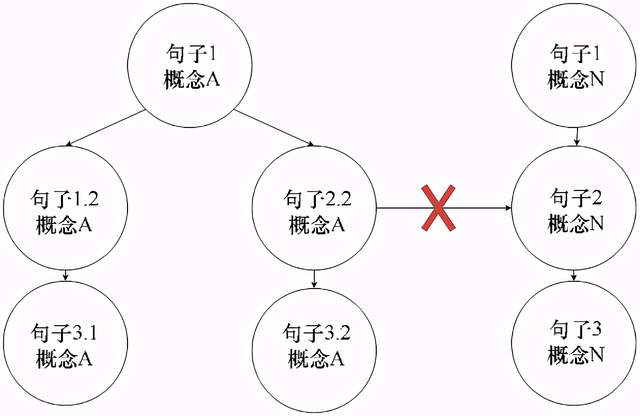
图3.2 使用树表示的一个对话
这种方法已经过时了,并且效率低下,因为它是基于固定规则的,本质上就是一种if-else结构。如今,NLU提出了另一种方法,那就是将对话表示为一个文氏图,其中的每个集合代表对话的一个上下文,如图3.3所示。
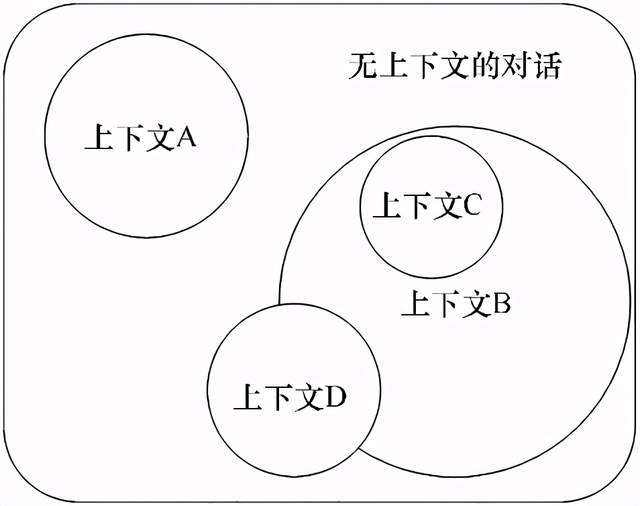
图3.3 使用文氏图表示的一个对话
NLU的这种方法改进了对话理解的结构,因为它不再是一个由if-else条件组成的固定结构。NLU的主要目标是解读人类语言的含义、处理对话上下文、消除歧义和管理数据。
3.1.2.2 自然语言生成
NLG是生成包含意义和结构的短语、句子和段落的过程,是NLP的一个不负责理解文本的领域。
为了生成自然语言,NLG的方法需要利用相关数据。
NLG由以下3个部分构成。
- 生成器:负责根据给定的意图,选择与上下文相关的文本。
- 表示的组件和层级:为生成的文本赋予结构。
- 应用:从对话中保存相关数据,从而遵循逻辑。
生成的文本必须使用一种人类可读的格式。NLG的优点是可以提高数据的可访问性,还可以用来快速生成报告摘要。
3.1.3 NLP的各层次
人类语言具有不同的表示层次,层次越高越复杂,理解难度也越大。
下面介绍了各个层次,其中前两个层次取决于数据类型(音频或文本)。
- 音位分析:对于语音数据,需要先分析音频,以获得句子。
- OCR/词例化:对于文本数据,需要先使用计算机视觉的光学字符识别(Optical Character Recognition,OCR)技术来识别字符,形成词语,或者需要先对文本进行词例化(即把句子拆分为文本单元)。
OCR用来识别图像中的字符,生成词语,以作为原始文本处理。
- 构词学分析:关注句子中的词语,分析词素。
- 句法分析:这一层关注句子的语法结构,理解句子的不同部分,例如主语和谓语。
- 语义表示:程序不能理解单独的词,而是通过一个词在句子中的用法来理解它的含义。例如,“cat”和“dog”这两个词对算法来说可能具有同样的含义,因为它们有同样的用法。通过这种方式理解句子,称为词语级别含义。
- 语篇处理:分析并识别文本中的连接句以及句子间的关系,从而理解文本的主题。
如今,NLP在业界展现出了非常大的潜力,但也有一些例外。在其中的一些例外情况中,使用深度学习可以获得更好的结果。
自然语言处理书籍
自然语言处理实战

本书是介绍自然语言处理(NLP)和深度学习的实战书。NLP已成为深度学习的核心应用领域,而深度学习是NLP研究和应用中的必要工具。本书分为3部分:第一部分介绍NLP基础,包括分词、TF-IDF向量化以及从词频向量到语义向量的转换;第二部分讲述深度学习,包含神经网络、词向量、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)网络、序列到序列建模和注意力机制等基本的深度学习模型和方法;第三部分介绍实战方面的内容,包括信息提取、问答系统、人机对话等真实世界系统的模型构建、性能挑战以及应对方法。
Python自然语言处理

本书是自然语言处理领域的一本实用入门指南,旨在帮助读者学习如何编写程序来分析书面语言。本书基于Python编程语言以及一个名为NLTK的自然语言工具包的开源库,但并不要求读者有Python编程的经验。全书共11章,按照难易程度顺序编排。第1章到第3章介绍了语言处理的基础,讲述如何使用小的Python程序分析感兴趣的文本信息。第4章讨论结构化程序设计,以巩固前面几章中介绍的编程要点。第5章到第7章介绍语言处理的基本原理,包括标注、分类和信息提取等。第8章到第10章介绍了句子解析、句法结构识别和句意表达方法。第11章介绍了如何有效管理语言数据。后记部分简要讨论了NLP领域的过去和未来。
本书的实践性很强,包括上百个实际可用的例子和分级练习。本书可供读者用于自学,也可以作为自然语言处理或计算语言学课程的教科书,还可以作为人工智能、文本挖掘、语料库语言学等课程的补充读物。
以上是关于什么是自然语言处理?的主要内容,如果未能解决你的问题,请参考以下文章