携程二面:讲讲 MySQL 中的 WAL 策略和 CheckPoint 技术
Posted 飞天小牛肉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了携程二面:讲讲 MySQL 中的 WAL 策略和 CheckPoint 技术相关的知识,希望对你有一定的参考价值。
前段时间我在准备暑期实习嘛,这是当时面携程的时候二面的一道问题,我一脸懵逼,赶紧道歉,不好意思不知道没了解过,面试官又解释说 redo log,我寻思着 redo log 我知道啊,WAL 是啥?给面试官整无语了(滑稽),为我当时的无知道歉。后来回去百度了一下才知道,最近又在丁奇大佬的《mysql 实战 45 讲》 中看到了 WAL,遂来写篇文章总结下。
InnoDB 体系架构
在说 WAL 之前,有必要简单介绍下 InnoDB 存储引擎的体系架构,方便我们理解下文,并且 redo log 也是 InnoDB 存储引擎所特有的。
如下图,InnoDB 存储引擎由内存池和一些后台线程组成:
内存池
先来解释下内存池。
首先,我们需要知道,InnoDB 存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可将其视为基于磁盘的数据库系统(Disk-base Database),在这样的系统中,众所周知,由于 CPU 速度与磁盘速度之间的不匹配,通常会使用缓冲池技术来提高数据库的整体性能。
所以这里的内存池也被称为缓冲池(简单理解为缓存就好了)。
具体来说,缓冲池其实就是一块内存区域,在 CPU 与磁盘之间加入内存访问,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。
拥有了缓冲池后,“读取页” 操作的具体步骤就是这样的:
-
首先将从磁盘读到的页存放在缓冲池中 -
下一次再读相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
“修改页” 操作的具体步骤就是这样的:
-
首先修改在缓冲池中的页;然后再以一定的频率刷新到磁盘上。
所谓 ”脏页“ 就发生在修改这个操作中,如果缓冲池中的页已经被修改了,但是还没有刷新到磁盘上,那么我们就称缓冲池中的这页是 ”脏页“,即缓冲池中的页的版本要比磁盘的新。
至此,综上所述,我们可以得出这样的结论:缓冲池的大小直接影响着数据库的整体性能。
后台线程
后台线程其实最大的作用就是用来完成 “将从磁盘读到的页存放在缓冲池中” 以及 “将缓冲池中的数据以一定的频率刷新到磁盘上” 这俩个操作的,当然了,还有其他的作用。以下是《MySQL 技术内幕:InnoDB 存储引擎 - 第 2 版》对于后台线程的描述:
后台线程的主要作用就是刷新内存池中的数据,保证内存池中缓存的是最近的数据;此外将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下 InnoDB 能恢复到正常运行状态。
另外,InnoDB 存储引擎是多线程的模型,也就是说它拥有多个不同的后台线程,负责处理不同的任务。这里简单列举下几种不同的后台线程:
-
Master Thread:主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性 -
IO Thread:在 InnoDB 存储引擎中大量使用了 AIO(Async IO)来处理写 IO 请求,这样可以极大提高数据库的性能。IO Thread 的工作主要是负责这些 IO 请求的回调(call back)处理 -
Purge Thread:回收已经使用并分配的 undo 页 -
Page Cleaner Thread:将之前版本中脏页的刷新操作都放入到单独的线程中来完成。其目的是为了减轻原 Master Thread 的工作及对于用户查询线程的阻塞,进一步提高 InnoDB 存储引擎的性能
redo log 与 WAL 策略
上文我们提到,当缓冲池中的某页数据被修改后,该页就被标记为 ”脏页“,脏页的数据会被定期刷新到磁盘上。
倘若每次一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是非常大的。并且,如果热点数据都集中在某几个页中,那么数据库的性能将变得非常差。另外,如果在从缓冲池将页的新版本刷新到磁盘时发生了宕机,那么这个数据就不能恢复了。
所以,为了避免发生数据丢失的问题,当前事务数据库系统(并非 MySQL 所独有)普遍都采用了 WAL(Write Ahead Log,预写日志)策略:即当事务提交时,先写重做日志(redo log),再修改页(先修改缓冲池,再刷新到磁盘);当由于发生宕机而导致数据丢失时,通过 redo log 来完成数据的恢复。这也是事务 ACID 中 D(Durability 持久性)的要求。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
举个简单的例子,假设你非常热心且 rich 的,借出去了很多钱,但是你非常 old school,不会使用电子设备并且记性不太好,所以你用一个小本本记下了所有欠你钱的人的名字和具体金额。这样,别人还你钱的时候,你就翻出你的小本本,一页页地找到他的名字然后把这次还的钱扣除掉。
但是呢,其实你平常是非常忙碌的,没办法随时随地翻小本本做记录,因此你就想出了一个主意:每当有人还你钱的时候,你就在一张白纸上记下来,然后挑个时间对照小本本把白纸上的账目都给清了。
这就是 WAL。白纸就是 redo log,小本本就是磁盘。
当然了,redo log 可不是白纸这么简单,一张用完了换一张就行了,这里有必要详细解释下。
每个 InnoDB 存储引擎至少有 1 个重做日志文件组( redo log group),每个文件组下至少有 2 个重做日志文件(redo log file),默认的话是一个 redo log group,其中包含 2 个 redo log file:ib_logfile0 和 ib_logfile1 。
一般来说,为了得到更高的可靠性,用户可以设置多个镜像日志组(mirrored log groups),将不同的文件组放在不同的磁盘上,以此提高 redo log 的高可用性。在日志组中每个 redo log file 的大小一致,并以循环写入的方式运行。
所谓循环写入,也就是为啥我们说 redo log 不像白纸那样用完一张换一张就行,举个例子,如下图,一个 redo log group,包含 3 个 redo log file:
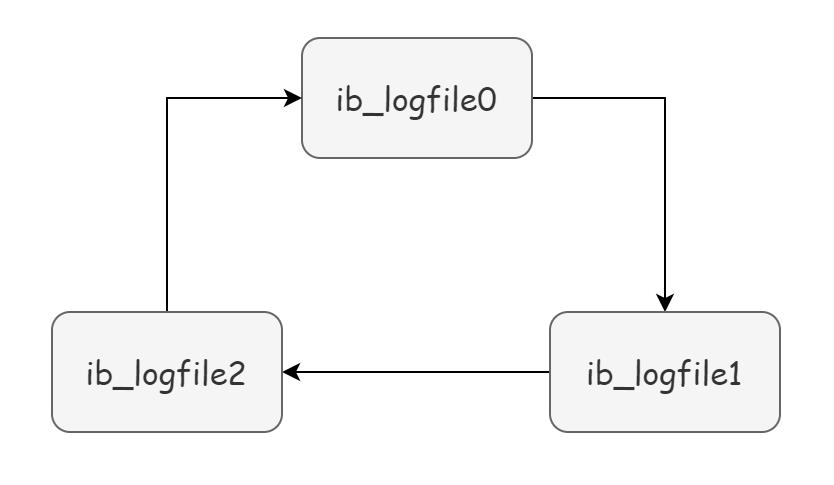
InnoDB 存储引擎会先写 redo log file 0,当 file 0 被写满的时候,会切换至 redo log file 1,当 file 1 也被写满时,会切换到 redo log file 2 中,而当 file 2 也被写满时,会再切换到 file 0 中。
可以看出,redo log file 的大小设置对于 InnoDB 存储引擎的性能有着非常大的影响:
-
redo log file 不能设置得太大,如果设置得很大,在恢复时可能需要很长的时间 -
redo log file 又不能设置得太小了,否则可能导致一个事务的日志需要多次切换重做日志文件
CheckPoint 技术
有了 redo log 就可以高枕无忧了吗?显然不是这么简单,我们仍然面临这样 3 个问题:
1)缓冲池不是无限大的,也就是说不能没完没了的存储我们的数据等待一起刷新到磁盘
2)redo log 是循环使用而不是无限大的(也许可以,但是成本太高,同时不便于运维),那么当所有的 redo log file 都写满了怎么办?
3)当数据库运行了几个月甚至几年时,这时如果发生宕机,重新应用 redo log 的时间会非常久,此时恢复的代价将会非常大。
因此 Checkpoint 技术的目的就是解决上述问题:
-
缓冲池不够用时,将脏页刷新到磁盘 -
redo log 不可用时,将脏页刷新到磁盘 -
缩短数据库的恢复时间
所谓 CheckPoint 技术简单来说其实就是在 redo log file 中找到一个位置,将这个位置前的页都刷新到磁盘中去,这个位置就称为 CheckPoint(检查点)。
针对上面这三点我们依次来解释下:
1)缩短数据库的恢复时间:当数据库发生宕机时,数据库不需要重做所有的日志,因为 Checkpoint 之前的页都已经刷新回磁盘。故数据库只需对 Checkpoint 后的 redo log 进行恢复就行了。这显然大大缩短了恢复的时间。
2)缓冲池不够用时,将脏页刷新到磁盘:所谓缓冲池不够用的意思就是缓冲池的空间无法存放新读取到的页,这个时候 InnoDB 引擎会怎么办呢?LRU 算法。InnoDB 存储引擎对传统的 LRU 算法做了一些优化,用其来管理缓冲池这块空间。
总的思路还是传统 LRU 那套,具体的优化细节这里就不再赘述了:即最频繁使用的页在 LRU 列表(LRU List)的前端,最少使用的页在 LRU 列表的尾端;当缓冲池的空间无法存放新读取到的页时,将首先释放 LRU 列表中尾端的页。这个被释放出来(溢出)的页,如果是脏页,那么就需要强制执行 CheckPoint,将脏页刷新到磁盘中去。
3)redo log 不可用时,将脏页刷新到磁盘:
所谓 redo log 不可用就是所有的 redo log file 都写满了。但事实上,其实 redo log 中的数据并不是时时刻刻都是有用的,那些已经不再需要的部分就称为 ”可以被重用的部分“,即当数据库发生宕机时,数据库恢复操作不需要这部分的 redo log,因此这部分就可以被覆盖重用(或者说被擦除)。
举个例子来具体解释下:一组 4 个文件,每个文件的大小是 1GB,那么总共就有 4GB 的 redo log file 空间。write pos 是当前 redo log 记录的位置,随着不断地写入磁盘,write pos 也不断地往后移,就像我们上文说的,写到 file 3 末尾后就回到 file 0 开头。CheckPoint 是当前要擦除的位置(将 Checkpoint 之前的页刷新回磁盘),也是往后推移并且循环的:
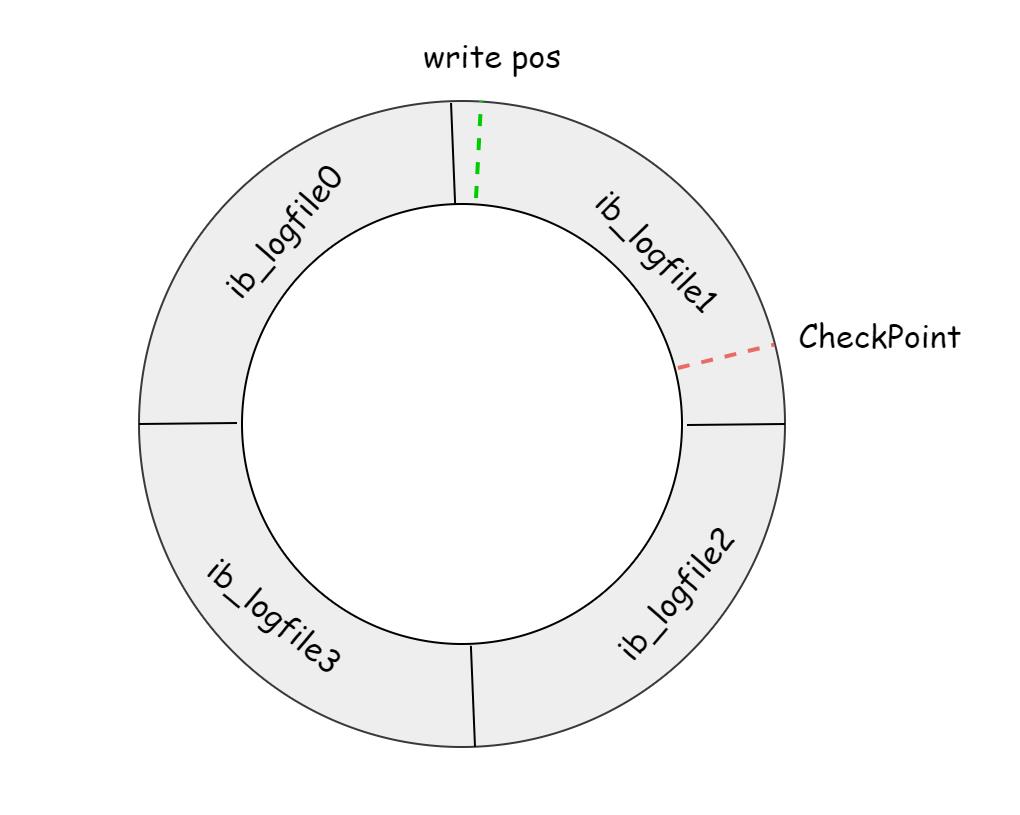
write pos 和 CheckPoint 之间的就是 redo log file 上还空着的部分,可以用来记录新的操作。如果 write pos 追上 CheckPoint,就表示 redo log file 满了,这时候不能再执行新的更新,得停下来先覆盖(擦掉)一些 redo log,把 CheckPoint 推进一下。
综上所述,Checkpoint 所做的事情无外乎是将缓冲池中的脏页刷新到磁盘。不同之处在于每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发 Checkpoint。在 InnoDB 存储引擎内部,有两种 Checkpoint,分别为:
-
Sharp Checkpoint:发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,参数 innodb_fast_shutdown=1 -
Fuzzy Checkpoin:InnoDB 存储引擎内部使用这种模式,只刷新一部分脏页,而不是刷新所有的脏页回磁盘。关于 Fuzzy CheckPoint 具体的情况这里就不再赘述了。
有了 bin log 为什么还需要 redo log?
前文我们讲过,MySQL 架构可以分成俩层,一层是 Server 层,它主要做的是 MySQL 功能层面的事情;另一层就是存储引擎,负责存储与提取相关的具体事宜。
redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,包括错误日志(error log)、二进制日志(binlog)、慢查询日志(slow query log)、查询日志(log)。
其他三个日志顾明思意都挺好理解的,需要解释的就是 binlog(二进制日志,binary log),它记录了对 MySQL 数据库执行更改的所有操作,但是不包括 SELECT 和 SHOW 这类操作,因为这类操作对数据本身并没有修改。也就是说,binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如 “给 ID=1 这一行的 a 字段加 1”。
可以看出来,binlog 日志只能用于归档,因此 binlog 也被称为归档日志,显然如果 MySQL 只依靠 binlog 等这四种日志是没有 crash-safe 能力的,所以为了弥补这种先天的不足,得益于 MySQL 可插拔的存储引擎架构,InnoDB 开发了另外一套日志系统 — 也就是 redo log 来实现 crash-safe 能力。
这就是为什么有了 bin log 为什么还需要 redo log 的答案。
回顾下 redo log 存储的东西,可以发现 redo log 是物理日志,记录的是 “在某个数据页上做了什么修改”。
另外,还有一点不同的是:binlog 是追加写入的,就是说 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志;而 redo log 是循环写入的。

-
博主小硕在读,深耕 Java,目前在维护一个教程类仓库 CS-Wiki「Gitee 官方推荐项目,现已 1.8k+ star,仓库地址:https://gitee.com/veal98/CS-Wiki」,公众号上的文章也会在此同步更新,欢迎各位前来交流学习。 -
准备春招秋招的小伙伴可以参考我的这个论坛项目 Echo「Gitee 官方推荐项目,现已 900+ star,仓库地址:https://gitee.com/veal98/Echo」。配套教程正在同步更新中,公众号后台回复 "Echo" 即可免费获取。 -
另外,虽然现在本号仍然很小,粉丝也没多少,不过我还是建了一个交流群『 小牛肉和它的小伙伴们』,感兴趣的各位可以下方扫码加我微信回复 "进群",我拉你进群:
以上是关于携程二面:讲讲 MySQL 中的 WAL 策略和 CheckPoint 技术的主要内容,如果未能解决你的问题,请参考以下文章