大厂二面高可用之Redis哨兵策略
Posted 如月之恒-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大厂二面高可用之Redis哨兵策略相关的知识,希望对你有一定的参考价值。
前言
笔者在二面某知名大厂时,从Redis的高可用问到kafka的高可用、mysql的高可用,又让我阐述从高可用的角度设计自己应用程序的高可用,自己回答得不够好,特别是自己项目在QPS陡增时如何设计系统,快速承接大量请求时。
本文针对Redis实现高可用的方法-哨兵策略做了详细介绍和图解,希望大家多提意见和问题。
笔者的知识脉络
- 哨兵策略要解决什么问题(作用)?
- 哨兵策略如何实现?
-
- 如何实现哨兵高可用?既然要保证Redis的高可用,那么哨兵自己也要具备高可用。所以第一个我们要说明哨兵如何确保自己高可用。
-
- 如何监控Redis集群状态?确保哨兵系统自己不会出问题后,就要监控Redis服务器了。
-
- 如何发现服务器故障?哨兵监控的Redis服务器的目的在于发现问题和处理问题,那就要先能发现故障。
-
- 如何进行故障转移。既然发现了问题,就要解决问题,故障转移就是哨兵策略解决问题的关键。
哨兵策略要解决什么问题?
背景:我们都知道Redis作为快速缓存,存储在内存中,既然是存储在内存的数据就会面临的数据丢失的问题,那怎么办?Redis提供了两个解决办法,一个是持久化数据到硬盘(后续有需要再讲),一个是高可用。
高可用你就可以很简单的理解,本来我们Redis只部署了一台机器,一旦这台机器挂了,我们的缓存机制就无效了。现在为了防止这个问题,我们部署主从架构,一台Master四台Slave。Redis的主从架构主要是为了提高并发量,主写从读。那么现在问题来了,现在Master机器挂掉了,其他机器都是Slave,没办法写,我们只能读缓存数据了。等下运维发现机子挂了,赶紧帮忙重启,那这段时间的请求怎么办?手动响应是高延迟的一个操作啊。这么一说,你就会发现这样解决问题很蠢。
所以Redis的哨兵机制就是为了解决这个愚蠢的问题。在Redis服务器集群出现问题时及时处理,进行故障转移(主备切换),这就是哨兵策略要解决的最重要的问题。既然我们知道了哨兵模式要解决的问题了,那么我们就学习下哨兵模式是如何解决这个问题了。
哨兵策略的实现原理
哨兵策略如何实现高可用
哨兵集群,哨兵机器通过Sentinel_hello频道自动发现,组成哨兵集群,各哨兵互相监控。
需要部署几台机器
既然哨兵系统是要实现Redis的高可用,那么哨兵系统自己也肯定是要高可用。
哨兵系统实现高可用的方案就是集群,我们为了避免单点故障,就是只能采取多部几台机子。
一般哨兵系统至少需要三台机子。你可以想问,为什么不可以是两台呢,两台我也可以检查心跳啊。一台有故障我就可以马上告知管理员啊。
这就涉及到了哨兵模式“选举领头Sentinel”和“客观下线”这两个功能,都是需要各位哨兵群策群力进行投票的(特别是选举领头Sentinel)。所以至少需要三台机子,机子最好是奇数。
注释:Sentinel 本质上是特殊模式的Redis的服务器,运行的命令与普通Redis服务器命令不同。一个哨兵系统够可以监控多个Redis集群。
现在既然知道了哨兵策略需要几台机器才能实现高可用,那么我们就来讲解下流程吧。
Sentinel机器部署流程
- 我们会在部署充当哨兵的机子上配置文件。该配置文件主要涵盖Master的ip、port信息。
- 初始化Sentinel服务器。
与初始化普通Redis服务器类似,但有些功能不可用:比如set、持久化功能等等,有些功能是Sentinel自己独有的:slaveOf等等。 - 使用Sentinel专用命令。
使用sentinelcmds作为命令列表,如INFO、sentinel,有些普通Redis可以执行命令Sentinel执行不了,就是因为sentinelcmds没有包含这些命令。 - 初始化
SentinelState实例结构
这个实例结构保存中所有Sentinel功能的相关状态,是我们理解哨兵策略的基础,哨兵策略的实现就是对实例结构中的数据进行修改来完成的。
图:sentinelState 实例结构
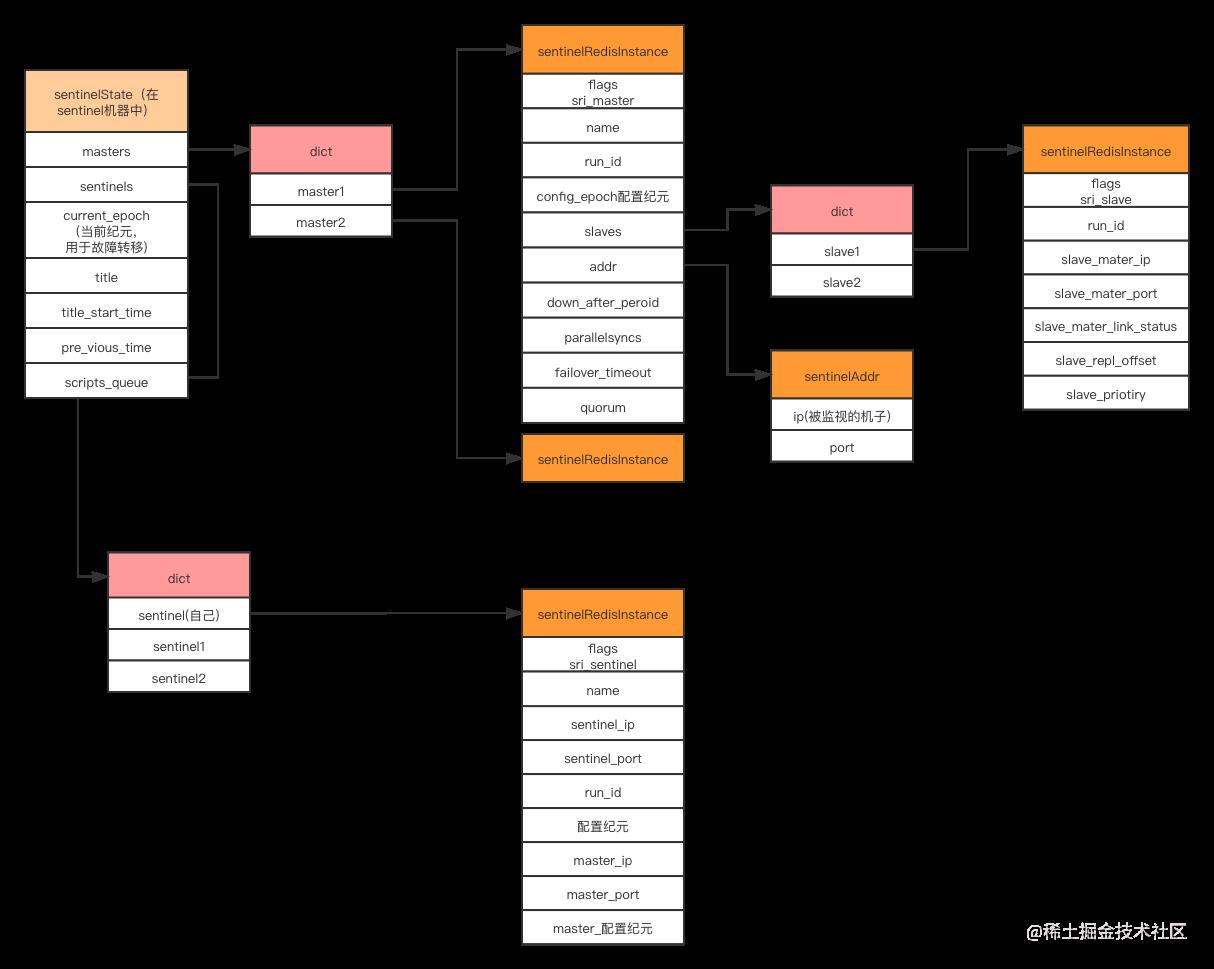
-
创建连向主服务器的网络连接:创建命令连接、创建订阅连接-Master服务器的sentinel_:hello频道。
命令连接的作用: 与Master服务器通信。
订阅连接的作用: 各个Sentinel相互发现,后续主备切换的通知等等。 -
创建连向各从服务器的网络连接:创建命令连接、创建订阅连接。
那我们应该如何配置哨兵集群呢。
自动发现,与其他哨兵连接;维护其他哨兵的状态信息;Sentinel_hello信道;
哨兵系统如何监控Redis集群?
上文中我们提到了Sentinel会与Master进行命令连接和订阅连接,那么Sentinel系统如何构建起完整的监控体系呢?
发现从服务器、其他sentinel
- Sentinel向Master每隔10秒发送一次INFO命令。
- Master返回INFO信息,包括其角色和slaves的地址信息等等,这样Sentinel就知道了slaves的信息了。从而得以自动发现Master的从服务器。
- 发现后也会向从服务器发送创建命令连接和创建订阅连接。
- Sentinel订阅Master的 SENTINEL:hello频道。
- Sentinel向主服务器和从服务器每隔两秒发送PUBLISH sentinel:hello <sentinel_info><master_info>
- 所有订阅该频道的Sentinel都会收到这个消息。根据这个信息,各个Sentinel就可以自动发现其他Sentinel,进而完整地构建出整个Sentinel系统的结构。
- 就可以直接向其他的Sentinel发送创建命令连接。
到这一步,我们整个哨兵系统完成了对Redis集群的监控,每个Sentinel都维护着完整的sentinel集群和Redis集群的服务器的信息,这个信息就是存在每台Sentinel的sentinelState中。有了这份信息,我们就可以对开始设计如何进行故障转移了。
故障转移如何实现?
图:故障转移示意图(文末有在线图片访问链接)
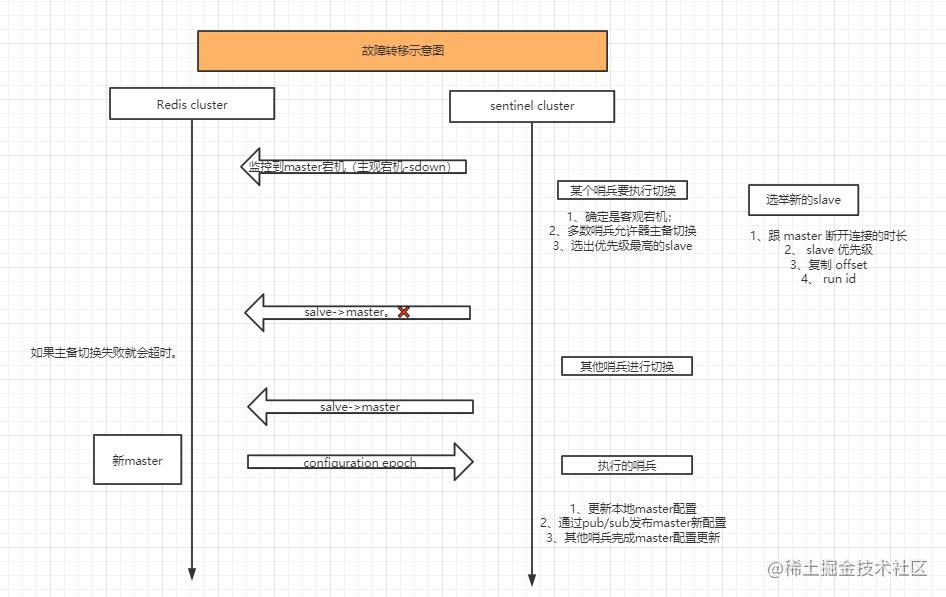
所有机器都有可能出现宕机和下线(网络不通)的情况,Master、slave、sentinel的机器都存在这种情况。Redis哨兵的故障转移机制是针对Master节点的,其他的机器出现问题,我们默认哨兵通过通知运维人员,运维人员检查机子状态,就可以得到解决。因为Master是负责写的,一旦出现问题,如果通过人工进行切换,那么会很麻烦。(单单部署主从架构的情况下,就是需要运维手动来进行Master的维护)。
故障转移步骤
那现在我们就来探讨下故障转移的实现过程,分为以下几步骤:
- 确定Master下线:sdown、odown
- 选举领头Sentinel
- 领头Sentinel执行故障转移:
选出最优Slave;
将最优Slave设置为新Master:
告知其他Slave从新Master复制数据;告知连接Redis的应用客户端改变Master地址;
旧Mater重新上线设置为Slave.
1、判断Master下线
主观下线
根据我们之前设置的Sentinel文件,我们在维护的SentinelState中配置了监控的master的下线判断参数down_after_peroid=5000,这就表示Sentinel通过每秒发送的Ping命令,超过5秒没有返回就判定这个Master主观下线了。将SentinelRedisInstance中的flag添加设置sri_master|sri_s_down
根据每个Sentinel都有自己的Sentinel配置文件,那么就可以配置不同down_after_peroid的值,每个Sentinel就可以实现不同的主观下线判断,即一个认为5秒,一个认为是50秒也可以。
这就是主观下线的实现,很明显就会带来问题,大家各自都有自己的算法,你要求5秒,别人要求50秒,那Master到底是什么时候下线呢?所以为了解决这个问题,就有了客观下线。
客观下线
又回到SentinelState中的属性,我们之前设置了quorum参数,quorum=2,那么就是说其他两台Sentinel也认为这个机子主观下线,那么当前Sentinel就可以将flag添加设置sri_master|sri_s_down|sri_o_down。
实现客观下线标记的过程,笔者将下一节选举领头Sentinel中一并讲解。
选举领头Sentinel
如何实现这个客观下线的标记呢?
- 当前Sentinel向其他Sentinel发送
Sentinel is_down_master_by_addr<ip><port><current_epoch><runid>命令 - 其他Sentinel返回信息<down_state><leader_runid><leader_epoch>
- 分析返回的信息,判断其他Sentinel是否判断Master主观下线,根据quorum来将Master设置为客观下线;是否把自己设置为局部领头Sentinel。
- Sentinel获得超过半数的其他Sentinel将其设置为局部领头Sentinel,那么他就是最终领头的Sentinel。
举个例子说明:
有3台sentinel:
Sentinel1:down_after_peroid=5000、quorum=1;
sentinel2:down_after_peroid=8000、quorun=1;
sentinel3:down_after_peroid=30000、quorun=2;
根据这样的设置sentinel3基本上是没有可能成为领头的,因为一旦出现问题,基本上前两台早就成为领头进行切换了。
注释:选举失败的话,Sentinel会再选一次。
现在我们选出了领头Sentinel了,那么就可以执行故障转移了哦。
执行故障转移
三个主要步骤
- 选出最优的slave。
- 设置Slave从新Master复制数据。
- 旧Master成为Slave。
本质上就是根据一大堆规则选择出最优,包括判断在线状态啊、复制偏移量等等一大堆规则,你可以理解成就是一大堆排序和if判断的结果。
选出最优Slave后,我们就要把他设置成Master了。过程如下:
图:执行故障转移(文末有在线图片访问链接)
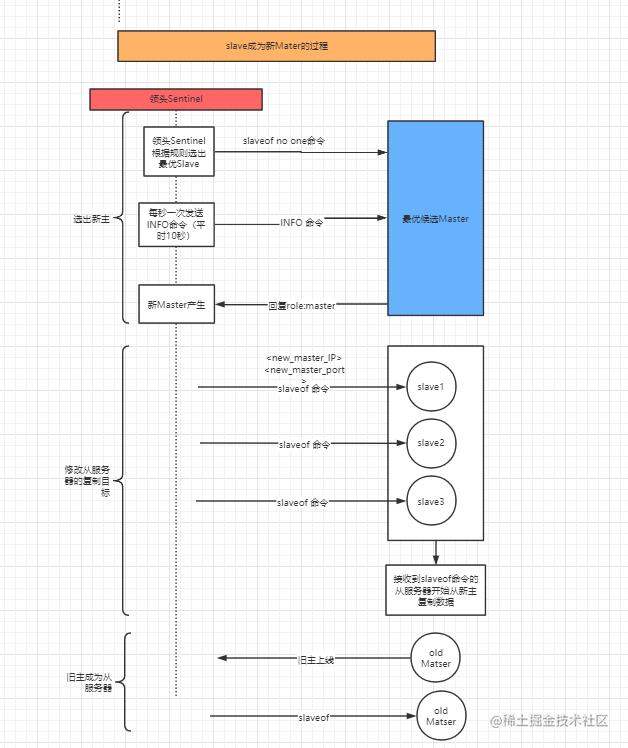
- 领头Sentinel向最优Slave发送
slave no one命令。 - 领头Sentinel会每秒(平时是10秒)向最优Slave发送INFO命令,直到Slave返回其role=master。证明升级成功。
- 向之前的Slave发送
slaveof <new_master_ip><new_master_port>命令,让其改为从新Master节点复制数据。 - 旧Master节点重新上线后,也向其发送
slaveof <new_master_ip><new_master_port>命令,让其成为Slave。
哨兵策略的应用会引发什么问题。
每一项技术的使用必然引发新的问题,所有方案都是权衡利弊的结果。如果你的系统用户不多,对缓存要求不高,那么连主从架构都不需要引入。
那么引入哨兵策略会带来什么问题呢?
- 系统架构变得更为复杂,机器资源(钱)要求更多。
- 一定程度上会降低Redis的性能。
- 包括但不限于以上两点,欢迎读者指点。
参考资料
- 《redis的设计与实现》-黄健宏
{kind=link}
后言
- 文章是个人知识点整理总结,如有错误和不足之处欢迎指正。
- 如有疑问、或希望与笔者探讨技术问题(包括但不限于本章内容),欢迎添加笔者微信(o815441)。请备注“探讨技术问题”。欢迎交流、一起进步。
以上是关于大厂二面高可用之Redis哨兵策略的主要内容,如果未能解决你的问题,请参考以下文章