仅用 480 块 GPU 跑出万亿参数!全球首个“低碳版”巨模型 M6 来了
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了仅用 480 块 GPU 跑出万亿参数!全球首个“低碳版”巨模型 M6 来了相关的知识,希望对你有一定的参考价值。

继今年 3 月阿里达摩院发布国内首个千亿参数多模态大模型 M6(MultiModality-to-MultiModality MultitaskMega-transformer,以下简称 M6) 之后,6 月 25 日,达摩院宣布对 M6 进行全新升级,带来“低碳版”巨模型 M6,在全球范围内首次大幅降低了万亿参数超大模型训练能耗,更加符合业界对低碳、高效训练 AI 大模型的迫切需求。
通过一系列突破性的技术创新,达摩院团队仅使用 480 卡 GPU,即训练出了规模达人类神经元 10 倍的万亿参数多模态大模型 M6,与英伟达、谷歌等海外公司实现万亿参数规模相比,能耗降低超八成、效率提升近 11 倍。
在本文中,我们将从万亿参数多模态大模型 M6 所带来的创新突破为起点,分享其背后所采用的 MoE 架构原理和实现,以及达摩院对 MoE 架构的探索与发现。

何为大模型?
大模型将成下一代人工智能基础设施,在 AI 圈内已成共识。与生物体神经元越多往往越聪明类似,参数规模越大的 AI 模型,往往拥有更高的智慧上限,训练大模型或将让人类在探索通用人工智能上更进一步。然而,大模型算力成本也相当高昂,很大程度阻碍了学界、工业界对大模型潜力的深入研究。
对此,达摩院与阿里云机器学习 PAI 平台、EFLOPS 计算集群等团队改进了 MoE(Mixture-of-Experts)框架,大大扩增了单个模型的承载容量。同时,通过加速线性代数、混合精度训练、半精度通信等优化技术,大幅提升了万亿模型训练速度,且在效果接近无损的前提下有效降低了所需计算资源。

万亿参数的 M6-MoE 模型
大模型研究的一大技术挑战是,模型扩展到千亿及以上参数的超大规模时,将很难放在一台机器上。如果使用模型+流水并行的分布式策略,一方面在代码实现上比较复杂,另一方面由于前向和反向传播 FLOPs 过高,模型的训练效率将非常低,在有限的时间内难以训练足够的样本。
为了解决这一难题,达摩院智能计算实验室团队采用了 Mixture-of-Experts(MoE)技术方案,该技术能够在扩展模型容量并提升模型效果的基础上,不显著增加运算 FLOPs,从而实现高效训练大规模模型的目的。
普通 Transformer 与 MoE 的对比如下图所示。在经典的数据并行 Transformer 分布式训练中,各 GPU 上同一 FFN 层使用同一份参数。当使用图中最右侧所示的 MoE 策略时,则不再将这部分参数在 GPU 之间共享,一份 FFN 参数被称为 1 个 expert,每个 GPU 上将存放若干份参数不同的 experts。
在前向过程中,对于输入样本的每个 token,达摩院团队使用 gate 机制为其选择分数最高的 k 个 experts,并将其 hiddenstates 通过 all-to-all 通信发送到这些 experts 对应的 GPU 上进行 FFN 层计算,待计算完毕后发送回原 GPU,k 个 experts 的输出结果根据 gate 分数加权求和,再进行后续运算。为了避免部分 experts 在训练中接收过多 tokens 从而影响效率,MoE 往往设定一个 capacity 超参指定每个 expert 处理 token 的最大数量,超出 capacity 的 token 将在 FFN 层被丢弃。不同的 GPU 输入不同的训练数据分片。通过这种 expert 并行的策略,模型的总参数和容量大大扩增。由于单个样本经过 gate 稀疏激活后只使用有限个 experts,每个样本所需要的计算量并没有显著增加,这带来了突破千亿乃至万亿规模的可能性。

在 MoE 模型的具体实现上,谷歌的工作依赖 mesh tensorflow 和 TPU。达摩院则使用阿里云自研框架 Whale 开发万亿 M6-MoE 模型。将 FFN 层改造成 expert 并行,达摩院主要使用了 Whale 的算子拆分功能。在实现基本 MoE 策略的基础上,达摩院团队进一步整合 Gradient checkpointing、XLA 优化、混合精度训练、半精度通信等训练效率优化技术,并采用了 Adafactor 优化器,成功在 480 张 NVIDIA V100-32GB 上完成万亿模型的训练。
在训练中,他们采用绝对值更小的初始化,并且适当减小学习率,保证了训练的稳定性,实现正常的模型收敛,而训练速度也达到了约480 samples/s。通过对比1000亿、2500亿和10000亿参数规模的模型收敛曲线(如下图所示),达摩院团队发现参数规模越大确实能带来效果上的进一步提升。
然而,值得注意的是,目前扩参数的方式还是横向扩展(即增加expert数和intermediate size),而非纵向扩展(即扩层数),未来该团队也将进一步探索纵向扩展,寻求模型深度与宽度的最优平衡。

探索 MoE,进一步提升模型效果!
除了规模扩展外,达摩院对 MoE 架构开展了更进一步的探索研究,观察哪些因素对 MoE 模型的效果和效率影响较大。利用 MoE 架构扩大模型规模的一大关键是 expert 并行。而在 expert 并行中,几大因素决定着模型的计算和通信,包括负载均衡策略,topk 策略及对应的 capacity 设计等。
在 M6 团队对负载均衡在 MoE 实验的观察过程中,他们考虑到负载均衡的问题,通过采用启发式的方法解决该问题,如上述的 expert capacity 和对应的 residual connection 的方法。Google 的 Gshard 和 SwitchTransformer 沿用了 MoE 原文经典的做法加入了 auxiliaryload balancing loss。
目前还没有相关工作观察负载均衡的情况究竟有多严重,以及它是不是真的会影响模型的效果。达摩院团队在小规模的 M6 模型上进行了对 auxiliary loss 的消融实验,观察到该 loss 对最终模型效果影响甚微,甚至没有带来正向效果,然而它确实对 loadbalance这个问题非常有效。如下图所示:

上图彩色曲线线表示各个层的 expert 接收有效 token 的变异系数随着训练进行的变化,灰色曲线表明训练阶段的 log PPL。图中变异系数 CV 表明每一层 expert 负载均衡情况,各曲线表明其随着训练步数的变化。
不难发现,训练初期所有模型均有较严重的负载不均衡问题,刚开始少数的 expert 接收了绝大部分的 token,导致很多 token 直接被丢弃,但它们均能实现快速下降,尤其具备 auxiliary loss 的模型 CV 能降低到 0.3 左右,也可观察到在该水平下均衡程度很高,每个 expert 都能接收大量有效 token。然而与之相反,不加 auxiliary loss 的模型表现非常不同,有的层甚至在训练后期出现 CV 的飙升。但不管对比训练阶段的 log PPL,还是对比下游语言模型任务的 PPL,不带 auxiliary loss 的模型都表现更优。这一定程度上反映其实负载均衡对最终效果的影响并不大。
达摩院 M6 团队进一步探索了关键的 top-k gating 策略 k 值和 capacity(C) 的选择。首先,他们简单地将 k 值扩大,发现k值越大其实效果越好。但考虑到选用不同的 k 值,C 则对应根据公式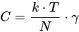 进行调整。通过对 C 调整到 k=1 的水平,观察不同 k 值的 MoE 模型的表现,达摩院团队观察到 k 值更大模型依然表现越好,尽管 k 值增加带来的优势逐渐不太明显。
进行调整。通过对 C 调整到 k=1 的水平,观察不同 k 值的 MoE 模型的表现,达摩院团队观察到 k 值更大模型依然表现越好,尽管 k 值增加带来的优势逐渐不太明显。
但 k 值的增加根据 Gshard top-2 gating 的实现,除了存在实现层面上一定的冗余和困难外,循环 argmax 的操作也会导致速度变慢。此外,第二个 expert 的行为会受到第一个 expert 的影响,让训练和测试存在差异。
达摩院团队用 expert prototyping 的简单方式替代,相较 baseline 实现了效果提升,且未显著增加计算成本。expert prototyping,即将 expert 分成 k 组,在每组中再进行 top-k 的操作(通常采用top-1,便于理解),然后将k组的结果进行组合,也称之为k top-1。这种方式实现上更直接简便,并且允许组和组之间并行做top-k操作,更加高效。
达摩院团队观察到,在不同规模的模型上,expert prototyping都能取得比baseline更好的效果,同时速度和计算上也相比top-k更有优势。且其在更大规模的模型上优势变得更大,在百亿模型下游imagecaptioning任务上甚至能观察到优于top-k的表现:

因此达摩院团队将该方法推广到万亿参数M6超大模型,并对应和上述的万亿baseline做了对比。目前,万亿参数模型训练了大约3万步,已经显著优于同等规模的基线模型,呈现约5倍的收敛加速。

沿着这个方向,值得做的工作还有很多:考虑到分组的特性,应当让组和组之间产生足够的差异,让每个组选出来的experts尽可能实现组合的效果等等。

M6:首个实现商业化落地的多模态大模型
随着万亿参数 M6 模型的落地,阿里达摩院在超大规模预训练模型领域迈上新的台阶,且 M6 巨模型也成为国内首个实现商业化落地的多模态大模型。
在商业应用层面,M6 拥有超越传统 AI 的认知和创造能力,它擅长绘画、写作、问答,在电商、制造业、文学艺术等诸多领域拥有广泛应用前景。其中以 AI 领域为例,M6 将作为 AI 助理设计师正式上岗阿里新制造平台犀牛智造,通过结合潮流趋势进行快速设计、试穿效果模拟,有望大幅缩短快时尚新款服饰设计周期。随着实践经验的增长,M6 设计的能力还将不断进化。
结合阿里的电商背景,M6 团队希望通过 M6 大模型优异的文字到图片生成能力,和电商领域产业链深度融合,挖掘潜在的应用价值。此前 OpenAI DALL·E 生成图片清晰度达 256×256,M6 则将图片生成清晰度提升至 1024×1024。

(以上为 M6 生成的高清服装设计图的示例)
解放设计师双手,以下为 M6 参与新款服装设计的流程图:

除文生图外,M6 还可以在工业界直接落地图生文能力,能够快速为商品等图片提供描述文案。该能力目前已在淘宝、支付宝部分业务上试应用。同时,多模态大模型为精准的跨模态搜索带来可能。目前M6已建立从文本到图片的匹配能力,未来,或将建立从文字到视频内容的认知能力,为搜索形态带来变革。
达摩院资深算法专家杨红霞表示,“接下来,M6 团队将继续把低碳 AI 做到极致,推进应用进一步落地,并探索对通用大模型的理论研究。”
参考文献
[1] Lepikhin,Dmitry, et al. "Gshard: Scaling giant models with conditional computationand automatic sharding." ICLR, 2021.
[2] Fedus, William, Barret Zoph, and Noam Shazeer. "Switch Transformers:Scaling to Trillion Parameter Models with Simple and Efficient Sparsity."arXiv preprint arXiv:2101.03961 (2021).
[3] Shazeer, Noam, and Mitchell Stern. "Adafactor: Adaptive learning rateswith sublinear memory cost." International Conference on Machine Learning.PMLR, 2018.
[4] Wang, Ang, et al. "Whale: A Unified Distributed TrainingFramework." arXiv preprint arXiv:2011.09208 (2020).

以上是关于仅用 480 块 GPU 跑出万亿参数!全球首个“低碳版”巨模型 M6 来了的主要内容,如果未能解决你的问题,请参考以下文章