仅480块GPU搞出万亿参数大模型!达摩院3个月打造,出手即商用
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了仅480块GPU搞出万亿参数大模型!达摩院3个月打造,出手即商用相关的知识,希望对你有一定的参考价值。
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
不要6000张GPU!不要2000张TPU!
只要480,万亿参数大模型“抱回家”!
还没完,更惊艳的在后边。
同为万亿“体量”,能耗降低超八成,效率还能提升11倍。

当真有这好事?
没错,这就是阿里巴巴刚刚发布的万亿巨模型M6。
用绿油油的“低碳版”来形容很是恰当了。
今年3月,M6作为中国首个千亿多模态大模型发布时,前OpenAI政策主管Jack Clark曾发文点赞道:
这个模型的规模和设计都非常惊人。

这次,万亿M6的问世又顺利拿下了个中国第一——国内首个实现商业化落地的多模态大模型。
而且是离你很近的那种哦~
不仅是画画、写作,你的支付宝、淘宝就在用!
自从大模型变得流行起来之后,它所具备的创意能力,一直是被世人所津津乐道。
例如OpenAI的DALL·E,给自家设计出来的公司门面,是这样的:

风格多变、设计多样倒是没错了。
甚至被网友们一度称赞为“甲方克星、乙方福音”。
但讲真,要是拿到现实来商用,真的能hold得住吗?
不见得。
单是从效果图来看,字体扭曲便是一个大问题。
而要商用,图片还需要一个非常硬性的要求——得够清晰啊!
但DALL·E生成图片的分辨率,却仅为256x256。
那到了万亿参数规模,情况是否有所好转?
直接来看下M6设计的作品效果:

不难看出,万亿参数大模型所生成的图,在清晰度上有了较大的提升,分辨率直接翻倍,达到了1024x1024,放大后还能看清衣物纹理。
或许你会说,除了M6之外,目前国内外已经诞生了几个万亿“体量”的大模型。
那阿里此次提出的大模型,又有什么独到的特点?
一大特点是,M6不仅公开了实现的详尽细节、模型的收敛情况(详见文末论文链接),而且还是国内首个实现商业落地的万亿参数多模态大模型。
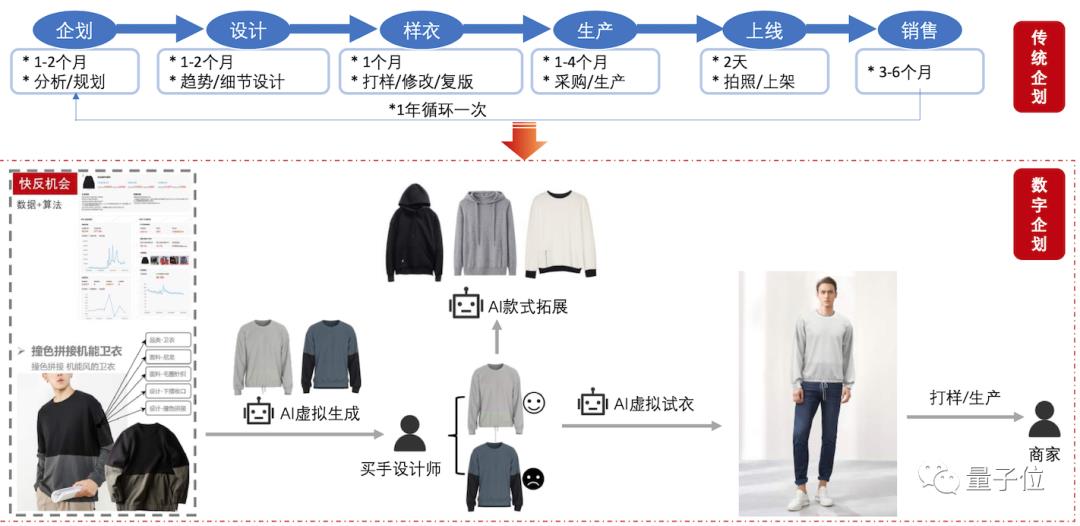
还是以生成图片为例,阿里已经初步将成果投入到了生产场景当中——阿里新制造平台犀牛智造。
目前,M6主要参与一些基础款的设计。但可预期的是,随着实践经验的丰富,M6的水平将不断进化。

据了解,M6计划在一年内生成上万款高清服装设计图。
什么概念?
这个数量就相当于一些快时尚品牌数百人设计团队的年出款量。
再具体一些,结合大数据预测的潮流趋势,M6可以实现快速设计和上身模拟,再经人类设计师进行筛选。
这么一套流程下来,原本以月计的新款服饰开发周期,被压缩到了以周来计算。
或许你会觉得这样的商业落地,离自己太远了。
不不不,M6还可能会出现在你经常用到的App哦——支付宝、淘宝。
懂“搜索”的人都知道,传统的搜索过程就是,查询语句与商品title的一个语义匹配过程。
但现在的年轻人搜索商品可不按照套路出牌。
举个例子,他们会搜“凹凸的咖啡杯”。
其实他们想搜索的就是一种日式风格的咖啡杯,但商家可不会把这些细节写进商品title中。

这时候,大模型就开始发挥它的看家本领了。
M6会根据商家提供的图片,以及用户的查询,做一个跨模态的搜索。
即使商家没有在title中描述关键词,M6可以根据图片中的信息,然后推荐出你想要的产品。
这时候你又会说了,其它万亿参数大模型说不定也能做到!
或许可以。
但如果说,M6只烧了480张GPU就做到了呢?
而且能耗比之前已有万亿参数模型低了8成,效率还提升了11倍!
不仅如此,达到这种惊人效果,从千亿到万亿参数规模,阿里只花了3个月时间。
3个月打造万亿参数模型,怎么做到的?
首先要了解的一点是,3个月时间的工作,并非是一蹴而就。
早在今年1月份,阿里便推出了百亿参数模型,而当时谷歌就已经提出来了1.6万亿参数的Switch Transformer。
谷歌能够达到这个量级,所借助的就是一个叫做MoE (Mixture of Experts)的架构。
于是,阿里从百亿开始的“规模升级”过程中,便借鉴了这个架构,仅耗时2个月,便发布千亿参数大模型,而且只用了32个 V100 GPU。
不得不说,MoE这个架构确实好用。
它能够做到的在扩展模型容量并提升模型效果的基础上,不显著增加运算FLOPs,这样就可以实现高效训练大规模模型的目的。
但阿里在却在研究过程中发现了一个问题:
MoE负载不均衡。
简单来说,原理是这样的。
大模型常用到的Transformer分布式训练中,通常是各个GPU同一FFN层中,使用同一份参数。
而MoE就不同了,上述的这部分参数会在GPU之间共享,一份FFN参数被称为1个“专家”(expert),每个GPU上将存放若干份参数不同的“专家”。
(如下图中标红框部分所示)
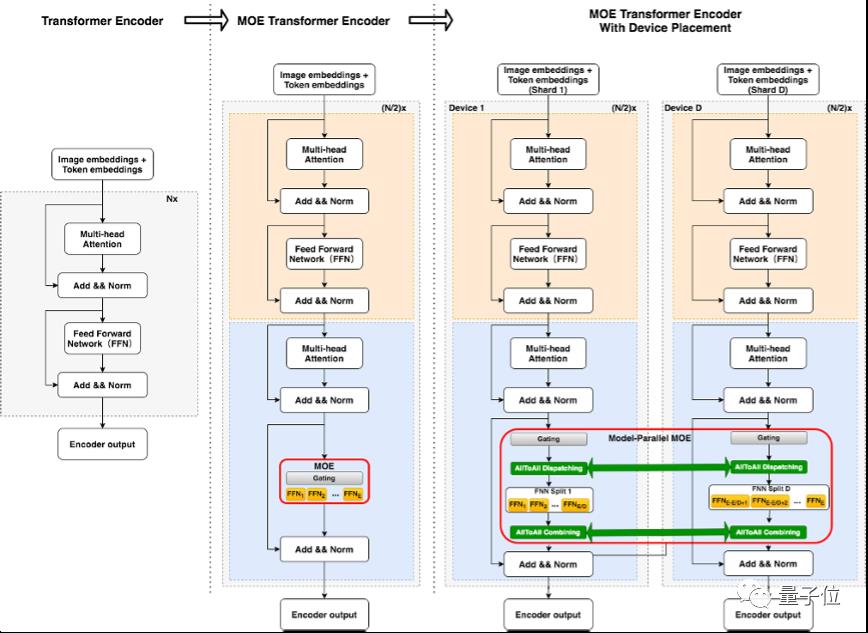
但阿里却发现,在原来MoE的训练过程中,非常容易只选择top的几位“专家”,这就使得头部效应非常严重。
于是乎,阿里便对MoE的这个问题进行了改良。
研究人员对“专家”做了一个分组工作,即expert prototyping。
具体而言,先是把“专家”分成k个组,在每组中再进行top-k的操作(通常采用top-1,便于理解)。然后再将k组的结果进行组合,也称之为k top-1。
这种方式实现上更直接简便,并且允许组和组之间并行做top-k操作,更加高效。
例如在百亿模型下游image captioning任务上,甚至能观察到优于top-k的表现:

而且在阿里与谷歌交流过程中,谷歌的研究人员也认可了这种改良思路,他们认为非常精巧。
除此之外,算子精度也是阿里此次改良的工作之一。
谷歌在做Switch Transformer时,为了将模型体积压下来,选择了BF16。
但精度的降低会带来非常大的技术挑战,就是如何保证模型收敛的问题。
而且阿里还要做到“低碳版”,不能烧太多的GPU,因此相比谷歌在算子精度方面的工作,阿里可谓走了一条更加“极端”的路线。
具体而言,XLA优化、混合精度训练、半精度通信等训练效率优化技术,并采用了Adafactor优化器,成功在480张NVIDIA V100-32GB上完成万亿模型的训练。
并且在训练中,他们采用绝对值更小的初始化,适当减小学习率,保证了训练的稳定性,实现正常的模型收敛,而训练速度也达到了约480samples/s。
以上便是阿里“低碳版”万亿参数大模型的核心奥秘了。
而抛开技术本身,细品阿里在大模型的规划路线,不免让人产生另一个问题:
阿里为什么这么“急”?
从百亿参数到千亿参数,用了2个月。
从千亿参数到万亿参数,用了3个月。
而且不同于其它大模型堆TPU、GPU,阿里选择的还是一条极端的“低碳”路线:
千亿参数模型仅需32张GPU,万亿参数模型只要480张GPU。
“急”,确实有点“急”。
但纵观全球大模型的发展,阿里的这种“急”也就不难理解了。
谷歌1月份提出1.6万亿参数大模型Switch Transformer
英伟达的“威震天”4月份也对万亿参数模型进行了训练
智源研究院于本月初发布1.75万亿参数大模型悟道2.0
……
除了万亿规模,这期间还穿插着像阿里、华为等大厂发布的百亿、千亿参数大模型。
而更早的,谷歌的BERT、OpenAI的GPT-3等,可以说是开启了大模型了一股热潮。
好一副“百家争鸣”之势。

为什么会这样?
因为这是必然,是大势所趋。
就好比十几年前深度学习的崛起一样,国内外各大厂商看到了这个技术的正确性。
于是纷纷前赴后继地入局于此,各式各样的深度学习模型不断涌现。
现如今大模型的这种盛世,就与深度学习时代极其相似。
而且比起深度学习,大模型的迭代速度只会更快。
因为深度学习时代之下,并没有出现很多应用场景。
但现如今,单是面向C端用户群里的大流量场景便应接不暇,搜索、推荐、广告等等。
因此,在大模型的研发上,不仅仅是阿里“急”,可以说全球各大厂商和研究机构,都很“急”。
而从技术本身来看,大模型还逐渐浮现出了无限的创造价值。
简而言之,就是在模型参数越发巨量的趋势之下,模型可能会做到更多“意想不到”的事情。
还是以M6生成图片为例,很多人会有一个质疑:
这些生成的图片,会不会是拼接的,而不是真正意义上的生成。
据阿里内部人士透露,还真不是这样:
它是真的有了认知和创造力。
最简单的验证方式,就是拿这些图片去各种搜索引擎搜一下,结果定然是完全找不到。
除此之外,技术应当有益于人类的发展。
在这一点上,M6大模型还有计划“上岗”助农扶贫的工作了。
具体而言,它将参与到帮助农民卖货的一个环节,可以帮助他们快速设计包装的logo以及各种IP衍生品。
而在此之前,这些环节的人力成本相对来说还是较高的。
综上来看,大模型的发展迭代、落地,确实是一个很“急”,但又正确的大趋势了。
……
最后一个问题,既然万亿规模参数已来,按照如此迭代速度,更大量级的大模型,还会远吗?
按现在的趋势,答案是肯定的,只是时间问题。
但据阿里的介绍,接下来在大模型的研究工作中,不仅是要追求参数规模的迭代,更要追求通用性和商业落地。
那么对于接下来的大模型,你期待了吗?
论文地址:
https://arxiv.org/abs/2105.15082
以上是关于仅480块GPU搞出万亿参数大模型!达摩院3个月打造,出手即商用的主要内容,如果未能解决你的问题,请参考以下文章
仅用 480 块 GPU 跑出万亿参数!全球首个“低碳版”巨模型 M6 来了
512张GPU炼出10万亿参数巨模型!5个月后达摩院模型再升级,今年双十一已经用上了...