优雅地把Html解析为Java/Kotlin实体对象
Posted 周文凯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优雅地把Html解析为Java/Kotlin实体对象相关的知识,希望对你有一定的参考价值。
使用Java如何优雅地爬取网页内容,并解析为实体对象呢?由于我对android平台比较熟悉,在项目中我们使用的Retrofit、Okhttp、Kotlin协程、LoganSquare解析把Server返回的Json解析为实体对象。那爬网页的时候是不是也可以使用这套模型,只不过是把解析的地方改为其他的方式呢?毕竟Json解析和html解析还是差别非常大的。
一、Html解析器
很自然的想到了Jsoup,记得初学Android时,还使用Jsoup爬取CSDN文章,写了一个简易的CSDN客户端。
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- 根据URL解析
只需要传入一个URL,就会自动下载该URL的HTML内容,并解析为Document doc = Jsoup.connect("https://en.wikipedia.org/").get(); log(doc.title()); Elements newsHeadlines = doc.select("#mp-itn b a"); for (Element headline : newsHeadlines) { log("%s\\n\\t%s", headline.attr("title"), headline.absUrl("href")); }Document。 - 解析HTML内容
Document doc = Jsoup.parse(htmlContent); log(doc.title()); Elements newsHeadlines = doc.select("#mp-itn b a"); for (Element headline : newsHeadlines) { log("%s\\n\\t%s", headline.attr("title"), headline.absUrl("href")); }
不管是根据URL解析还是直接解析HTML内容,都是需要先解析为Document,再进行类似jQuery的方式获取数据。
二、为啥要网络模型搭建
我们在开始说要用Retrofit、Okhttp、Kotlin协程等搭建网络模型,那根据我们前面说的,直接使用Jsoup解析URL不就完事了?
OK,我们直接使用试一下:
val doc = Jsoup.connect("https://home.meishichina.com").get()
val title = doc.title()
findViewById<TextView>(R.id.tv_content).text = title
上面的代码比较简单,直接把美食中国的首页地址传递给Jsoup,然后把解析出的title赋值给Android界面上的TextView显示。我们运行以下,果不其然,崩溃了!
android.os.NetworkOnMainThreadException
主线程不允许进行网络访问,聪明的同学已经想到解决方案。
- 问:主线程不能进行网络访问怎么办?
答:既然Android不允许主线程进行网络访问,那我开一个子线程就可以了。 - 问:子线程访问回来的数据不能在子线程更新UI怎么办?
答:这还不简单,我用Handle再调度回主线程啊。 - 由于网络访问量很大,如何最大化提高性能呢?
答:这里难不倒我,我维护一个线程池,不可能每次都创建一个线程的。 - 问:… …
答:… … - 问:已经有这样的轮子了,为什么要自己重复造呢?
答:我 …
那我们还是用经典的轮子吧。
三、网络模型搭建
3.1 添加依赖
添加retrofit依赖,大家使用时可以去官方看下最新的版本,再加一个日志拦截器,用于输出详细的网络访问情况。
dependencies {
// ... ...
implementation 'com.squareup.retrofit2:retrofit:2.9.0'
implementation 'com.squareup.okhttp3:logging-interceptor:4.9.0'
}
眼尖的同学已经发现,没有添加okHttp的依赖啊。通过查看依赖树可以看到,retrofit内部已经依赖了。
+--- com.squareup.retrofit2:retrofit:2.9.0
| \\--- com.squareup.okhttp3:okhttp:3.14.9 -> 4.9.0
| \\--- com.squareup.okio:okio:1.17.2
当然,我们添加了com.squareup.okhttp3:logging-interceptor:4.9.0也会引入okhttp的4.9.0版本,这里的4.9.0会覆盖掉retrofit因入的3.14.9版本的okhttp,如果大家项目里还有其他依赖不能升级okhttp到最新版本,这里引入的相关依赖库的版本也要对应修改。
3.2 网络模型
private fun createRetrofit(baseUrl: String): Retrofit {
val okHttpClient = OkHttpClient.Builder()
.apply {
val loggingInterceptor = HttpLoggingInterceptor(::println)
loggingInterceptor.level = HttpLoggingInterceptor.Level.BODY
addInterceptor(loggingInterceptor)
addInterceptor(UserAgentInterceptor())
}.build()
return Retrofit.Builder()
.baseUrl(baseUrl)
.client(okHttpClient)
.apply {
addConverterFactory(HtmlConverterFactory.create())
}
.build()
}
这里也比较简单,创建了一个okHttpClient作为创建Retrofit的参数,在okHttpClient中添加了一个日志拦截器和一个UA拦截器,值得注意的是我们添加了一个HtmlConverterFactory,这个就是把HTML解析为实体对象的实现。
当然,这里的封装基本最精简了,在实际项目中,要根基自己的需要再添加其他的配置。
3.3 网络模型使用
- 创建Retrofit接口
interface APIService { @GET("/recipe.html") suspend fun recipeHome(): RecipeHomeEntity } - Retrofit接口初始化
private val apiService: APIService by lazy { createRetrofit("https://home.meishichina.com/") .create(APIService::class.java) } - 访问接口,并显示数据
// 获取菜谱首页数据 GlobalScope.launch(Dispatchers.Main) { val recipeHome = apiService.recipeHome() recipeHome.recipeList?.forEach { println("title = ${it.title}, url = ${it.url}, totalCount = ${it.totalCount}") } // 显示数据 val contentView = findViewById<TextView>(R.id.tv_content) contentView.text = recipeHome.recipeList?.get(0)?.title ?: "" }
嗯,想要的就是这样的,和接口返回Json时解析的方式没有任何区别。当然这里是最简化的,具体的还要根据项目进行再次封装,比如使用MVVM架构时的将返回结果解析为实体对象后还要结合接口成功失败封装为LivaData对象等。
Ksoup实现
解析原理
简单的网络模型架子我们搞好了,剩下的就是核心的HTML解析了,再结合我们开头的Jsoup,我们入口就是HtmlConverterFactory的封装,在进行封装之前我们先来思考下,怎么实现解析呢?先看下需要解析的页面结构。
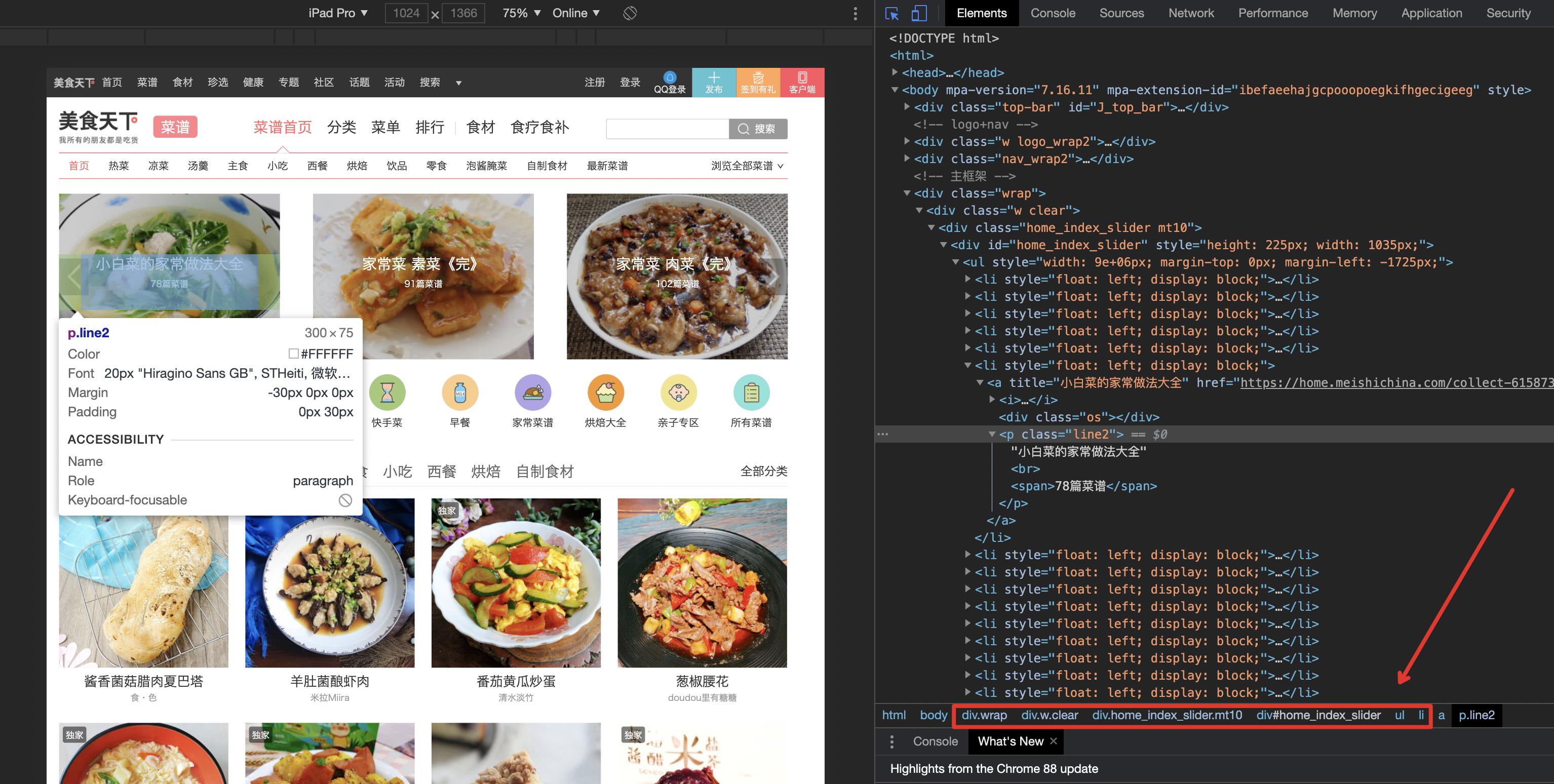
比如我们需要获取上方的大图入口,通过查看页面元素,再加上浏览器的神助攻,很容易找到筛选条件。
val doc = Jsoup.connect("https://home.meishichina.com/recipe.html").get()
val elements = doc.select("div.wrap div.w.clear div.home_index_slider.mt10 div#home_index_slider ul li")
通过Debug,我们看到解析的elements数据如下:

这是查到来一个list,那如果想要获取里面的title内容呢?
val doc = Jsoup.connect("https://home.meishichina.com/recipe.html").get()
val elements = doc.select("div.wrap div.w.clear div.home_index_slider.mt10 div#home_index_slider ul li")
elements.forEach { element ->
val title = element.select("a").attr("title")
println(title)
}
如法炮制,我们只要在之前list的elements遍历下,获取a标签的title属性即可。

大家是不是发现,哇,竟然如此简单,只要按照对应的规则就可以使用Jsoup轻松提取出我们想要的数据。
这里是手动解析一个数据,那怎么映射到实体对象的字段上呢?在使用Json解析时,如果字段和Json数据不一致,我们可以给字段加注解。
@JsonField(name = "is_force")
public int isForce = 0;
那我们的解析是不是也可以这么干呢?当然了,我们想怎么定就怎么定。
@Pick("body")
class RecipeHomeEntity {
@Pick("div.wrap div.w.clear div.home_index_slider.mt10 div#home_index_slider ul li")
var recipeList: List<RecipeEntity>? = null
}
class RecipeEntity {
@Pick("a", attr = Attrs.TITLE)
var title: String = ""
}
有了实现原理,我们心里就有底了,甚至不用我再讲下面的具体实现,大家都可以自己实现解析的功能。
Pick注解
@Retention(AnnotationRetention.RUNTIME)
@Target(AnnotationTarget.FIELD, AnnotationTarget.ANNOTATION_CLASS, AnnotationTarget.CLASS)
annotation class Pick(
val value: String = "",
val attr: String = Attrs.TEXT,
val regex: String = ""
)
定义一个运行时注解,包含默认的value字段,attr用于指定获取的标签的属性,比如上面我就指定获取a标签的title属性。
regex的作用是什么呢?由于通过Jsoup只能获取String类型数据,那如果是数字类型的呢?可以通过正则表达式提取数字,是不是很巧妙呢,哈哈。
HtmlConverterFactory
在上面我们提到过HtmlConverterFactory是解析的入口,具体是为什么,大家可以翻下Retrofit的源码,或者如果有需要大家可以在文章下发留言,我来写下Retrofit的源码分析。
关于自定义解析器部分其实很简单,Retrofit不知道怎么给你转换数据,需要你告诉它,你想要怎么转换,你要是不告诉它,它遇到不知道怎么转换的时候就会异常给你看。那我们这里需要的是什么呢?再把我们的Retrofit接口和对数据模型义拿过来搂一眼。
interface APIService {
@GET("/recipe.html")
suspend fun recipeHome(): RecipeHomeEntity
}
@Pick("body")
class RecipeHomeEntity {
@Pick("div.wrap div.w.clear div.home_index_slider.mt10 div#home_index_slider ul li")
var recipeList: List<RecipeEntity>? = null
}
class RecipeEntity {
@Pick("a", attr = Attrs.TITLE)
var title: String = ""
}
发现了吧,我们返回的直接就是数据模型,并且这个数据模型被Pick注解修饰了,由于这个注解是我们自定义的,肯定是只要有这个注解的就是需要使用解析转换器进行处理的。
class HtmlConverterFactory private constructor(private val ksoup: Ksoup) : Converter.Factory() {
override fun responseBodyConverter(type: Type, annotations: Array<Annotation>, retrofit: Retrofit): Converter<ResponseBody, *>? {
return if (type is Class<*> && type.getAnnotation(Pick::class.java) != null) {
Converter<ResponseBody, Any> { value ->
val result = ksoup.parse(value.string(), type)
value.close()
result
}
} else null
}
companion object {
fun create(): HtmlConverterFactory {
return HtmlConverterFactory(Ksoup())
}
}
}
同样很简单,判断如果返回结果是被Pick修饰的,我们就进行处理,不是的话返回null,爱谁管谁管。Retrofit的责任链模式,会去检查看谁还能处理,再分发给它处理。
Jsoup实现
仿照Json的解析,我们定义Jsoup的解析入口,入参数两个,html内容,需要映射转换的模型class。
/**
* This method deserializes the specified html into an object of the specified class.
*
* @param T the type of the desired object
* @param html the string from which the object is to be deserialized
* @param clazz the class of T
* @return an object of type T from the string.
*/
fun <T : Any> parse(html: String, clazz: Class<T>): T {
return parse(Jsoup.parse(html), clazz)
}
OK,有了入口下面的就简单了,我们的思路是这样的,先根据模型的class,反射创建一个实体对象,再遍历该对象的参数,获取参数的类型、Pick注解、进行字段的映射。
由于需要反射创建模型对象,所以一定要保留无参的构造函数,如果没有的话,主动抛出错误。
/**
* This method deserializes the specified html into an object of the specified class.
*
* @param T the type of the desired object
* @param document the document from which the object is to be deserialized
* @param clazz the class of T
* @return an object of type T from the string.
*/
fun <T : Any> parse(document: Document, clazz: Class<T>): T {
val rootNode = getRootNode(document, clazz)
val obj: T
try {
obj = clazz.getConstructor().newInstance()
} catch (e: NoSuchMethodException) {
throw KsoupException("No-args constructor for class $clazz does not exist.", e)
} catch (e: Exception) {
throw KsoupException(e)
}
rootNode?.let {
clazz.declaredFields.forEach { field ->
getFieldValue(rootNode, obj, field)
}
}
return obj
}
再看一下具体的字段解析,同样不复杂,根据字段的类型,进行对应数据的解析。
/**
* Parsing HTML to assign values to the specified object field.
*
* @param node the element
* @param obj the object
* @param field the target field
*/
internal fun getFieldValue(node: Element, obj: Any, field: Field) {
field.isAccessible = true
val defVal = field[obj]
when (field.type) {
Int::class.java -> field[obj] =
IntTypeExtractor.extract(node, field, defVal as Int?, this)
Long::class.java -> field[obj] =
LongTypeExtractor.extract(node, field, defVal as Long?, this)
Float::class.java -> field[obj] =
FloatTypeExtractor.extract(node, field, defVal as Float?, this)
String::class.java -> field[obj] =
StringTypeExtractor.extract(node, field, defVal as String?, this)
Double::class.java -> field[obj] =
DoubleTypeExtractor.extract(node, field, defVal as Double?, this)
Boolean::class.java -> field[obj] =
BooleanTypeExtractor.extract(node, field, defVal as Boolean?, this)
List::class.java -> field[obj] =
ArrayTypeExtractor.extract(node, field, defVal as ArrayList<*>?, this)
else -> throw KsoupException("Type ${field.type} is not supported.")
}
}
好,解析的代码就贴到这里吧,具体的实现会在文章末尾贴出gayhub的地址。
源码
源码传送门 》》》 Jsoup
以上是关于优雅地把Html解析为Java/Kotlin实体对象的主要内容,如果未能解决你的问题,请参考以下文章