MultiNet用于自动驾驶的多模态多任务学习网络
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MultiNet用于自动驾驶的多模态多任务学习网络相关的知识,希望对你有一定的参考价值。

本文发表于2019年的IEEE计算机视觉应用冬季会议上,是一篇有关自动驾驶领域多模态多任务网络应用的文章。本文将多模态学习与MTL(Multi-task Learning)相结合,提出了一种多行为模式下非结构化自动驾驶的新方法。
摘要
自动驾驶需要在不同的行为模式下运行,比如车道跟随、交叉路口转弯和停车。然而,现有的自主驾驶深度学习方法大多没有在训练策略中考虑行为模式。
本文描述了一种通过多模式多任务学习在单个深度神经网络中学习多个不同行为模式的技术。我们研究了这种名为 MultiNet 的方法的有效性,该方法使用自动驾驶模型车在人行道和未铺设的道路等非结构化环境中驾驶。使用我们的1/10比例模型车车队100多个小时的标记数据,我们训练了不同的神经网络,以预测不同行为模式下车辆的转向角和行驶速度。
我们的实验表明,在每种情况下,MultiNet 在使用参数总数的一小部分的情况下,优于在单个模式下训练的网络。
1. INTRODUCTION
本文将多模态学习与MTL相结合,提出了一种多行为模式下非结构化自主驾驶的新方法。在该方法中,MTL辅助任务由附加的推断速度和转向值组成,它们形成规划的轨迹。我们引入了多种不同的驾驶行为或行为模式,车辆可以在这些行为模式下操作。
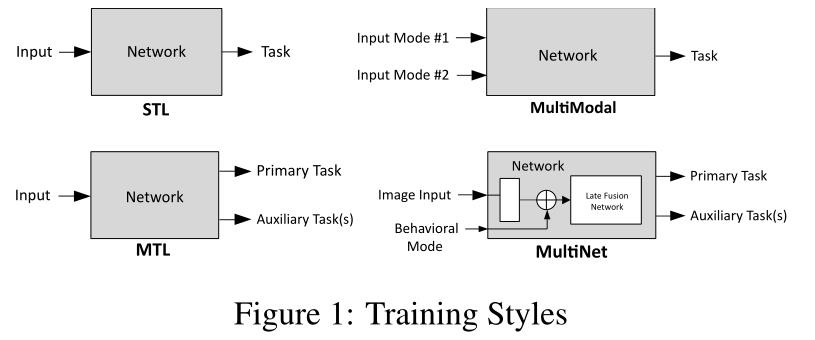
我们的主要创新是使用行为模式作为网络的第二种输入,它与输入图像处理流连接在一起,以允许在单个多模式网络中形成单独的驾驶行为。
我们还提供了我们独特的1/10比例模型车在非结构化条件下行驶的数据集,例如人行道、小径和未铺设的道路。人行道驾驶数据集与解决交付中的最后一英里问题相关,对于这一问题,自动驾驶模型车被认为是一个可行的解决方案。此外,模型车的小尺寸允许对非典型驾驶行为进行安全实验,并收集涉及车辆制造和从错误中恢复的有价值的数据。

2. DATASET
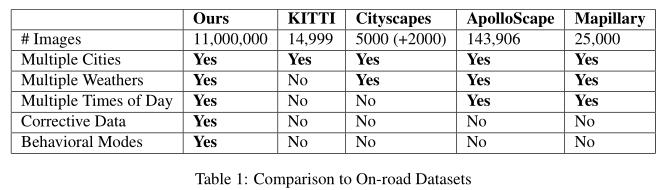
我们的数据集包含在不同的地理、照明和天气条件下100多个小时的驾驶时间(图3)。该数据集包括来自各种传感器的连续记录数据流,包括立体图像、加速度计读数、GPS数据、转向位置和电机速度值。在本工作中仅使用原始立体图像、方向盘和马达速度值。表1将我们的数据集与现有的道路驾驶数据集进行了比较。
采集的数据集部分图样本如下:

3. METHODOLOGY
网络架构
为了进行推断,我们使用了NVIDIA Jetson TX1系统,并以20 Hz的频率运行我们称为Z2Color的自定义网络。该网络由两个卷积层组成,其后是两个完全连接的层,如下图所示。
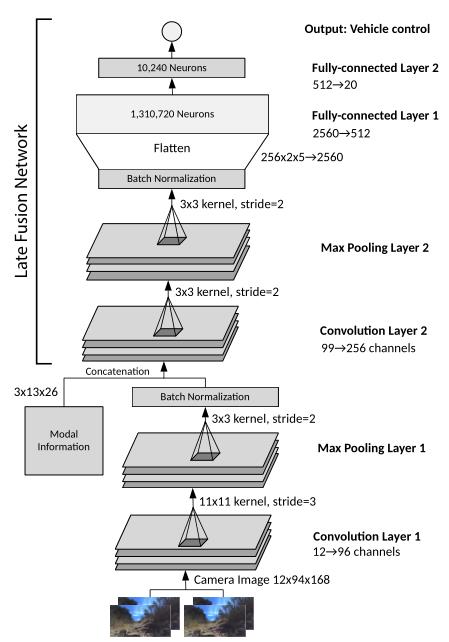
在每一卷积层之后进行最大池化和批量归一化。Max Pooling使我们能够有效地降低维度,BN层阻止内部协变量移位。步幅和内核大小是通过多次训练和道路评估的经验发现的。卷积层被设计为用作特征提取层,而最终的完全连通层用作转向控制器。但是,网络是以端到端的方式进行培训的,因此我们没有将不同形式的处理隔离到网络的特定部分。
模态信息
从汽车收集数据时,除了电机、转向和图像数据外,我们还存储汽车正在运行的行为模式。我们已经训练了有行为信息插入和没有行为信息插入的网络,当添加行为信息时,网络更明显地显示出个人的模态行为。
没有这种模态信息的网络可能会明显地学习多个行为模式,但是需要大量的仔细训练才能将每个行为模态的过滤器分开。通过在处理流中添加模式信息,网络更容易为每个行为模式创建独立的过滤器。
行为信息被插入为三个通道的二进制张量,其中每个通道代表不同的行为模态。为了与通过卷积网络的图像连接,在空间维度中复制行为信息以形成大小为3x13x26的二进制张量。
网络中的行为模式信息插入点被选择在Z2Color中的第一卷积层之后,从而允许较早的卷积层概括输入数据的基本图像处理,而无需考虑单个模态的行为。
4. EXPERIMENTS
训练
为了训练我们的网络,我们使用了PyTorch深度学习框架。这些网络是使用Adadelta Optimizer进行训练的。用于训练和验证的损失函数是均方误差(MSE)损失。在训练阶段,对网络输出的所有值(即,遵循公式的所有十个时间步长)计算损失。
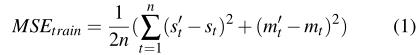
在验证过程中,使用了类似的MSE损失度量,不同之处在于该损失仅针对两个最终发动机和转向输出进行了计算,如所给出的:
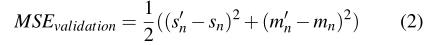
每个网络都使用相同数量的数据进行训练。这些网络都是在同一个看不见的验证集上进行评估的。所有的实验都用随机初始化的网络和洗牌后的数据集重复了8次。这里的结果描述了这些试验的平均值,误差条代表95%的置信区间。
我们的均衡训练数据集包含大约193万个可用于训练和验证的数据时刻。10%的收集数据被保存在看不见的验证数据集中,用于网络评估。所有数据在训练和验证集中平均分配给每种模态。
多模态比较
在我们的初始实验中,我们将在直接、跟随和隐藏的多模式数据集中训练的多网络Z2Color网络与分别在直接、跟随和隐藏模式下训练的三个MTL Z2Color网络进行了比较。这些网络中的每一个都接受了相同数量的数据矩的训练。然后使用公式(2)中描述的验证损失测量对网络进行评估。
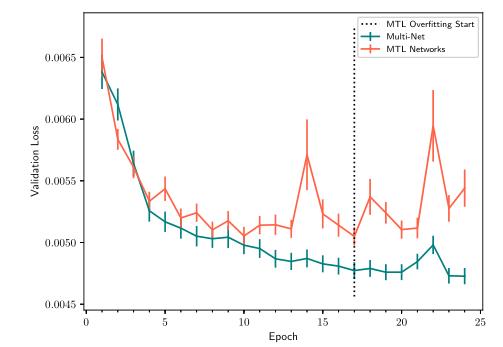
单个模式下的性能
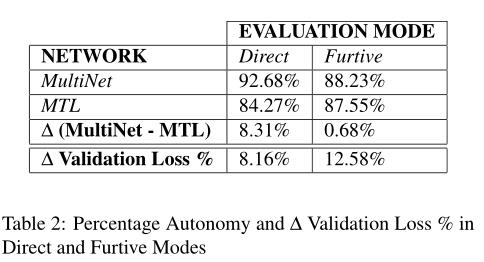
Direct 和 Furtive 模式下的性能对比如下表所示:
对模型车的评价
对于现场实验,MTL和MultiNet网络都是在一个200米的人行道弯道(图9)上进行评估的,在一小时的间隔内有足够的障碍物。在评价汽车时,只使用直接模式和偷偷摸摸的模式,而不使用跟随模式,因为领头车的行驶可能会在不同的运行中有所不同,这使得定量分析变得不切实际。道路评估网络的选择是在试验的平均验证误差最小的点上进行的,也就是说,我们选择了使MultiNet和MTL网络的平均验证误差都最小的时段和试验。这一最低值出现在一项特定试验的第23纪元,当时两个网络都还没有开始超负荷运行。

结果验证
为了验证文中验证度量的结果,我们根据验证损失计算性能差异的百分比,以在现场实验中将MSE损失度量与autonomy metric 进行比较。验证损失的百分比差异使用以下公式计算:

5. CONCLUSION & FUTURE WORKS
本文提出了一种训练 DNN 在几种不同行为模式下工作的方法 MultiNet。这种方法将行为信息直接插入到网络的处理流中,允许在相关模式之间共享参数。
此外,我们还展示了我们独特的数据集,其中包括从一组在不同条件下行驶的模型车记录的 100 多个小时的人行道和越野数据。我们在预留的验证数据集以及现场实验中的模型汽车上测试了我们的 MultiNet 方法。
我们的 MULTINET 方法被证明在使用更少的参数的情况下超过了针对特定行为模式训练的单个网络的性能。在我们目前的研究中,双目摄像机图像作为输入,未来的工作可能会将其他传感器融入整合到系统中,例如 GPS 和加速计数据,这些数据已经在我们的数据集中可用。
最后,本文所描述的通用 MultiNet 方法也可用于其他应用,如使用包含目标类上下文信息的模态张量进行目标检测。
以上是关于MultiNet用于自动驾驶的多模态多任务学习网络的主要内容,如果未能解决你的问题,请参考以下文章
YUV-MultiNet用于自动驾驶的实时YUV多任务CNN