YUV-MultiNet用于自动驾驶的实时YUV多任务CNN
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YUV-MultiNet用于自动驾驶的实时YUV多任务CNN相关的知识,希望对你有一定的参考价值。

摘要
本文提出了一种针对低功耗车用SoC优化的多任务卷积神经网络(CNN)结构。我们介绍了一个基于统一架构的网络,其中编码器由检测和分割两个任务共享。该网络以25FPS运行,分辨率为1280×800。简要讨论了直接利用原生YUV图像、优化图层和要素图、应用量化等优化网络结构的方法。
在我们的设计中,我们也关注内存带宽,因为卷积是数据密集型的,而大多数SOC都有带宽瓶颈。然后,我们展示了我们提出的用于专用CNN加速器的网络的效率,给出了从硬件执行和相应的运行时间获得的检测和分割任务的关键性能指标(KPI)。
1. Introduction
目前先进驾驶辅助系统(ADAS)领域的改进将证实,深度学习对于提出基于摄像机传感器的有效解决方案至关重要。目前,卷积神经网络(CNNs)成功地处理了各种视觉感知任务,包括语义分割、包围盒目标检测或深度估计。
然而,这些成功的应用大多需要很高的计算能力,这在当前的嵌入式系统中是不现实的。本文提出了一种新的用于目标检测和语义分割的实时多任务网络。与最近的解决方案相比,我们的论文提出了两个主要的改进。首先,我们提出了一个由YUV4:2:0图像馈送的多任务网络。其次,我们提出了一个全面设计的网络,以考虑到有效的嵌入式集成的所有关键因素。

2. Background
几年来,CNN的架构一直致力于单一任务,如分类任务[6]、[13]、[5]、检测任务[10]、[8])、语义分割任务[16]、[7]、[2]或视觉SLAM[9]。最近一年,我们观察到了专门为处理几项任务而设计的新CNN架构的出现。
在这些新方法中,2016年,Teichmann[15]提出了一个统一的编解码器架构,它可以同时执行三个任务(分类、检测、分割)。2018年,[14]发表了一篇基于Multinet的论文,在低功耗嵌入式系统上实现了30fps。除了这些论文外,其他几篇论文[4]、[1]证实了使用多任务学习(MTL)方法的好处,特别是在考虑计算效率或确保网络的最佳泛化和准确性方面。
我们的工作是受到这些论文的启发,但我们建议建立一个更加轻量的网络,通过直接输入YUV4:2:0图像来降低带宽,并在低功耗SoC上进行了实验。
2013年,Sermanet和LeCun[12]提出将YUV图像空间用于行人检测应用。我们的网络的输入层序列直接来自于他们的工作,除了我们提出了调整内核维数(5×5和3×3而不是7×7和5×5)和其他一些细节来满足SoC约束之外。
3. Network architecture optimization
输入数据形状优化
为了满足所选SoC提供的特定数据格式,必须修改网络输入层。事实上,所选的SoC针对其在前置摄像头中的应用进行了优化。在我们的例子中,使用的相机是鱼眼相机。这种类型的相机比固定式相机提供了更宽的视野,这对汽车应用很有用。
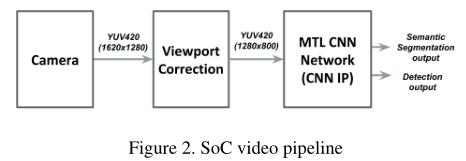
图像信号处理器(ISP)在视频流水线开始时提供的图像格式不是BGR格式,而是YUV格式。这种格式在嵌入式系统中比较常见,但在深度学习领域并不经常使用这种格式。为我们的应用程序选择的YUV格式是YUV4:2:0格式。与普通的BGR图像相比,对摄像机捕获的信息进行编码的三个通道的分辨率不同。表示色度分量的通道U和V是表示亮度的通道Y的一半分辨率。这意味着通道U或V中的一个像素对对应于Y通道中的2x2像素块的色度信息进行编码。
图3中显示的两个选项在CNN IP上的成本完全相同。然而,YUV4:2:0选项有两个主要优势:内存带宽减少2倍,并且不需要额外的转换(YUV4:2:0到BGR)模块。
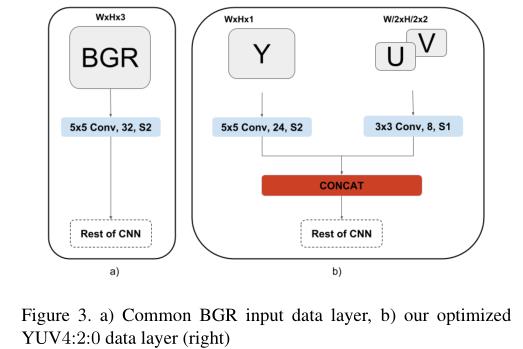
让我们假设一个1280×800的8位输入图像。对于bgr选项,提供给网络的内存流量大约是3MB,对于YUV4:2:0选项,大约是1.5MB。YUV4:2:0选项的另一个优点是不需要额外的模块进行YUV4:2:0到BGR的转换。使用bgr选项,这将是强制性的,才能提供一些有效的东西作为CNN的输入。
Encoder stage : V2N9Slim
在最常见的统一编解码器架构中,最昂贵的部分通常是编码器部分。基于VGG[13]或ResNet[5]的网络编码器基本上是我们在最近的论文中能找到的最常见的编码器。不幸的是,这些编码器既宽又深,实际上并不是低功耗嵌入式系统的理想候选者。为了满足嵌入式系统的要求,采用了一种新的光编码器V2N9Slim。
V2N9Slim 是一个9层编码器(9个卷积层或池层),编码器体系结构如图4所示。对于多任务实验,使用ImageNet数据集对编码器部分进行分类任务的预训练。
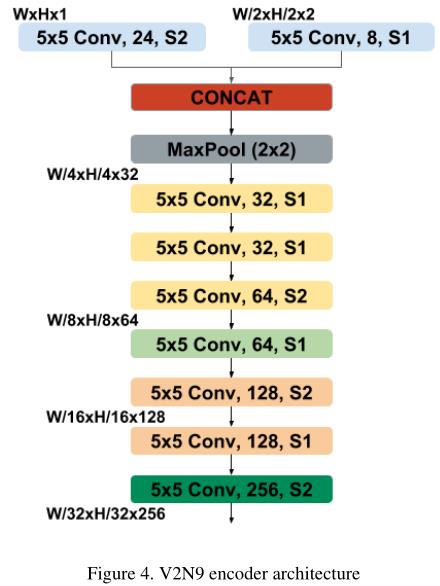
V2N9超轻量架构是RESNET和VGG架构的混合体。实际上,我们的网络的分层顺序主要是受RESNET的普通网络的启发,我们的网络没有采用符合VGG架构的捷径连接。不使用快捷连接的动机来自以前的实验,作者证明,在浅层网络中,捷径连接并不能显著提高精度,我们的9层编码器就是这种情况。此外,快捷连接对于嵌入式系统来说也是昂贵的,因为它们涉及额外的计算以及增加的存储器占用和存储器传输。
Decoders
我们提出的解决方案的解码器是用于检测部分的YoloV2解码器和用于分割部分的基于FCN的解码器。Y oloV2解码器包括在编码器的末尾增加一个卷积层,以重塑编码器特征映射到边界框预测。然后,在ARM处理器上执行额外的后处理,以将YoloV2解码器的输出转换为边界框坐标和置信度。基于FCN的解码器是一个具有5个转置卷积层级的解码器。这些层中的每一层都按因子2(即FCN2)对输入进行向上采样(使用5×5核),以检索原始输入图像分辨率。FCN2解码器完全运行在SoC上的专用CNN IP上。
Quantization steps
我们提出的优化架构已经使用基于KERAS的浮点精度框架进行了训练。为了在16位定点精度上执行以浮点精度训练的网络,需要量化步骤以在专用硬件上运行网络。为了尽可能地减少这一阶段的饱和度等问题,所有卷积层之后都有一个批次归一化层,以获得具有单位方差的特征地图分布。由于浮点范围受批归一化的限制,它还使得浮点数到16位数的编码更加准确。
4. Results
我们在我们的私人鱼眼相机数据集上进行了一系列实验。此数据集的大小为5000个带注释的帧。图像分辨率为1280×800。针对语义分割和检测任务对帧进行注释。对于语义分割,帧上的每个像素被注释为属于以下4个类别之一:[背景、道路、车道、路缘]。对于检测类,帧中的对象被标注在两个类之间:[行人、汽车]。
评估了两种类型的网络:

在表1中,总结了这两种网络的性能。我们可以观察到,两个网络在分割任务和检测任务上的KPI非常接近。我们提出的网络能够达到与Multinet参考网络相同的精度水平,甚至更好。然而,我们提出的网络比参考网络快65%,这证明了本部分中提出的优化阶段的效率。

5. Conclusion
本文针对自动驾驶应用,提出了一种优化的多任务网络。首先,我们简要介绍了我们的低功耗SoC,并提出了使用多任务方法的必要性。然后,我们描述了所提出的网络以及为实现嵌入约束所做的优化。最后,我们分享了在我们自己的鱼眼数据集和低功耗SoC上的实验结果。
我们可以合理地认为,本文提出了三个主要贡献:一个专用于YUV4:2:0图像空间的输入数据层,一个面向低功耗SoC的CNN核心的网络,以及一个高度精简的网络,其精度接近于原始的Multinet网络,但速度要快得多。研讨会的演示提案是一个很好的机会,可以突出这些贡献,并现场展示我们网络的效率。
以上是关于YUV-MultiNet用于自动驾驶的实时YUV多任务CNN的主要内容,如果未能解决你的问题,请参考以下文章