网络协议系列十八 - 网络爬虫/HTTP缓存/IPv6
Posted 1024星球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络协议系列十八 - 网络爬虫/HTTP缓存/IPv6相关的知识,希望对你有一定的参考价值。
本文仅仅是常见协议的扫盲,具体技术点可参考其他相关文档。
一、VPN
VPN(Virtual Private Network),虚拟私人网络。它可以在公共网络上建立专用网络,进行加密通讯。
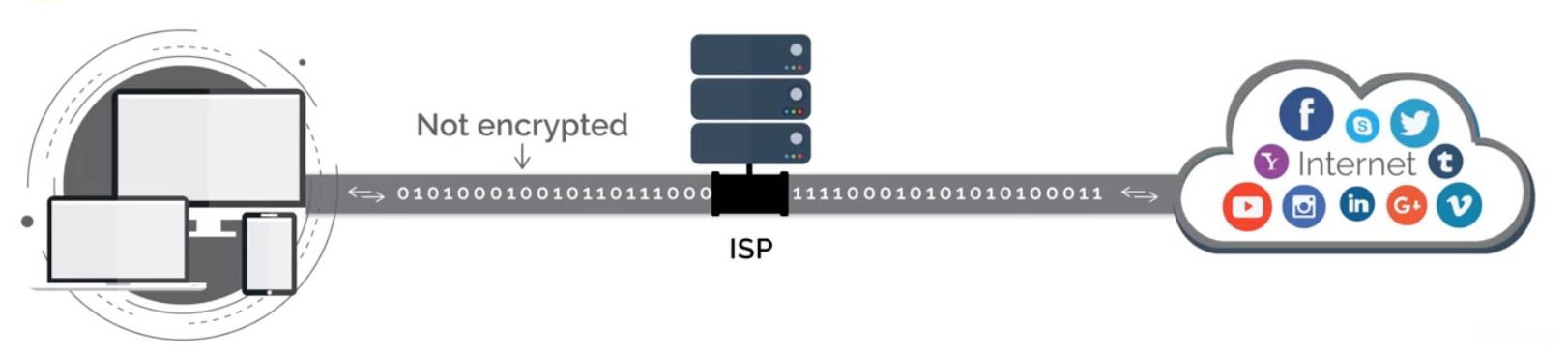
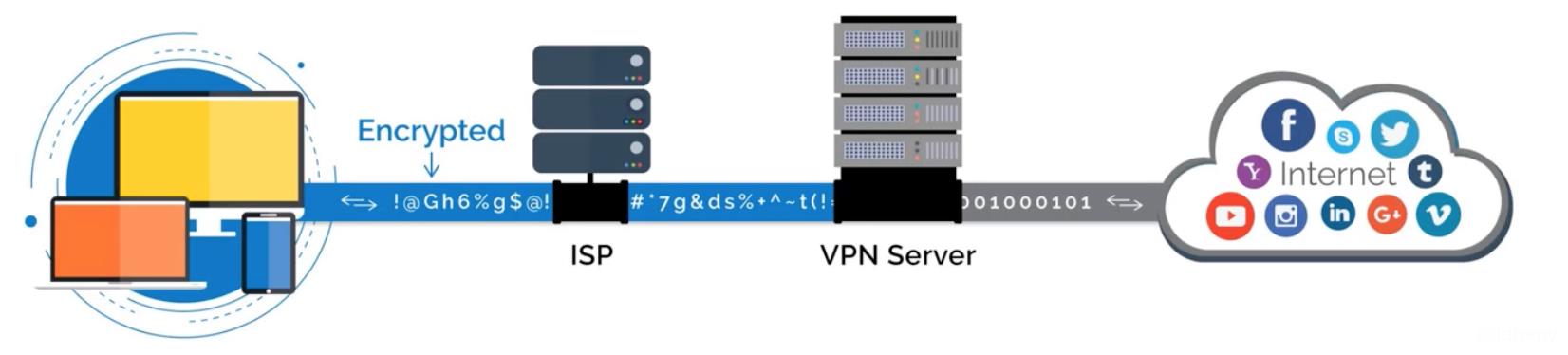
1.1. 作用
- 提高上网的安全性(加密数据)
- 保护公司内部资料
- 隐藏上网者的身份(VPN Server转发数据)
- 突破网站的地域限制
- 有些网站针对不同地区的用户展示不同的内容
- 突破网络封锁(科学上网)
- 因为有GWF(Great Firewall of China,中国长城防火墙)的限制,有些网站在国内上不了
1.2. 与代理的区别
- 软件
- VPN一般需要安装VPN客户端软件
- 代理不需要安装额外的软件
- 安全性
- VPN默认会对数据进行加密
- 代理默认不会对数据进行加密(数据最终是否加密取决于使用的协议本身)
- 费用
- 一般情况下,VPN比代理贵
1.3. 实现原理
VPN的实现原理是:使用了隧道协议(Tunneling Protocol)。
常见的VPN隧道协议(应用在传输层或数据链路层):
- PPTP(Point to Point Tunneling Protocol):点对点隧道协议
- L2TP(Layer Two Tunneling Protocol):第二层隧道协议
- IPsec(Internet Protocol Security):互联网安全协议
- SSL VPN(如OpenVPN)
- …
二、tcpdump
tcpdump是Linux平台的抓包分析工具(命令行),Windows版本是WinDump
使用手册:https://www.tcpdump.org/manpages/tcpdump.1.html
教程:https://danielmiessler.com/study/tcpdump
三、网络爬虫
网络爬虫(Web Crawler),也叫做网络蜘蛛(Web Spider)。模拟人类使用浏览器操作页面的行为,对页面进行相关的操作。
常用的爬虫工具:Python的Scrapy框架。
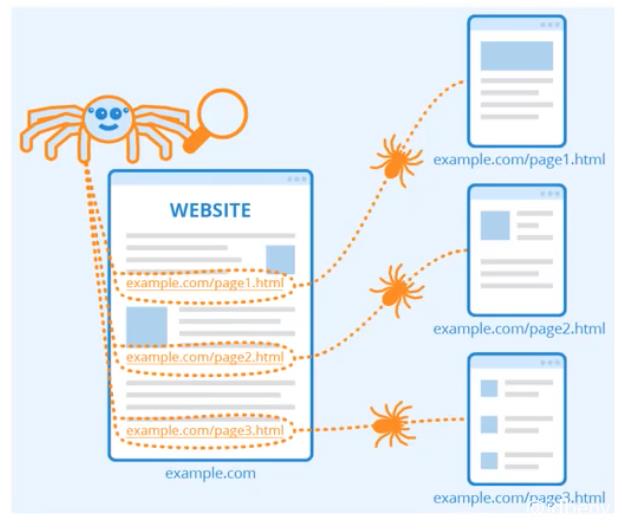
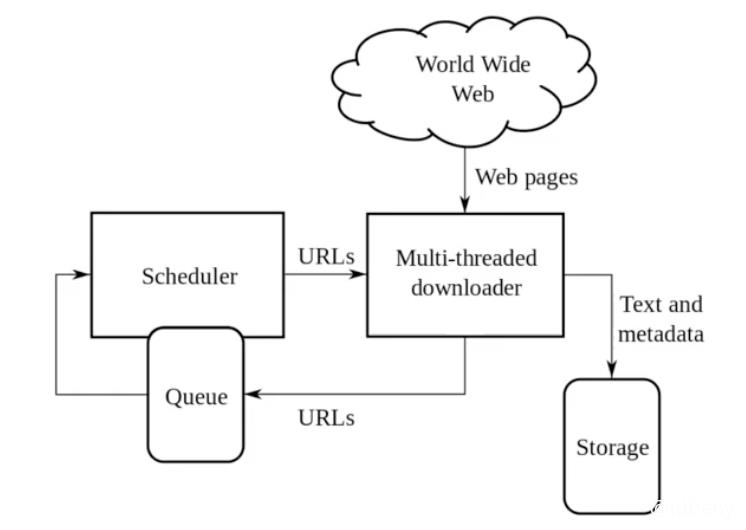
3.1. 搜索引擎
我们在百度或Google搜索的一些内容是怎么出现在搜索列表中的?其实搜索引擎也用到了爬虫技术,把其他网站数据进行分析建库,当用户搜索关键词时,就会从之前的数据库中筛选出合适的数据给用户。
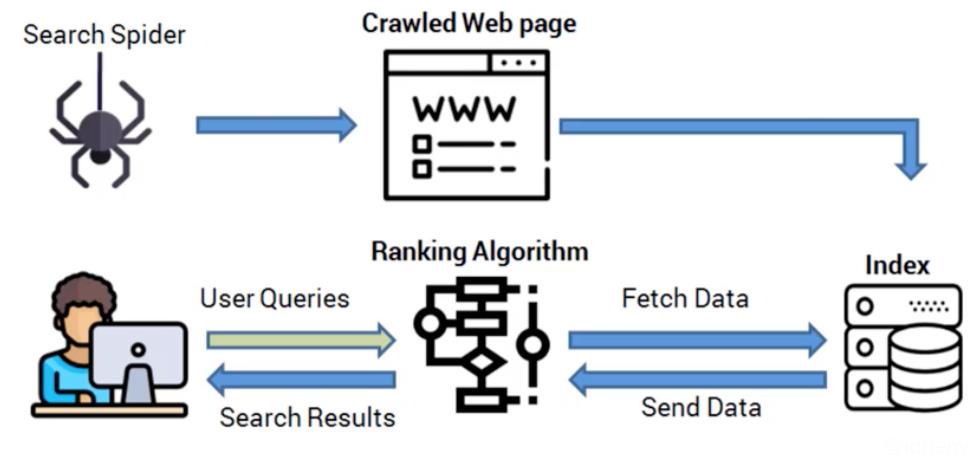
3.2. 简易实例
可以使用Java的一个小框架Jsoup爬一些简单的数据。
jar包:
- https://jsoup.org/packages/jsoup-1.13.1.jar
- https://mirror.bit.edu.cn/apache/commons/io/binaries/commons-io-2.8.0-bin.zip
爬取目标:360应用市场-https://ext.se.360.cn/webstore/category
String url = "https://ext.se.360.cn/webstore/category";
Elements apps = Jsoup.connect(url).get().select(".appwrap");
for (Element app : apps) {
String img = app.selectFirst("img").attr("src");
String name = app.selectFirst("h3").text();
String intro = app.selectFirst(".intro").text();
System.out.println(name + "_" + intro + "_" + img);
String filepath = "/Users/Developer/Desktop/test/imgs/" + name + ".jpg";
FileUtils.copyURLToFile(new URL(img), new File(filepath));
}
3.3. robots.txt
robots.txt是存放于网站根目录下的文本文件,比如https://www.baidu.com/robots.txt。用来告诉爬虫哪些内容是不应被爬取的,哪些是可以被爬取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。
它并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私(只能防君子,不能防小人)。
允许所有的爬虫:
User-agent: *
Disallow:
// 另一种写法:
User-agent: *
Allow: /
仅允许特定的爬虫(name_spider是爬虫名字):
User-agent: name_spider
Allow:
拦截所有的爬虫:
User-agent: *
Disallow: /
仅禁止爬虫访问特定目录:
User-agent: name_spider
Disallow: /private/
禁止所有爬虫访问特定目录:
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Disallow: /tmp/
Disallow: /private/
禁止所有爬虫访问特定文件类型:
User-agent: *
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
四、HTTP缓存
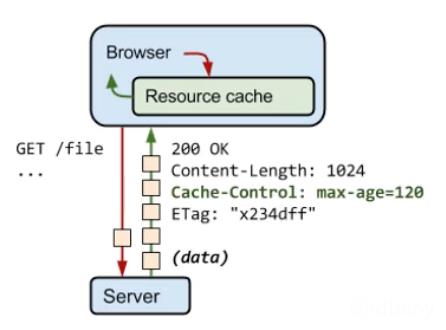
实际上,HTTP的缓存机制远远比上图的流程要复杂。
通常会缓存的情况:GET请求 + 静态资源(比如HTML、CSS、JS、图片等)。
浏览器强制刷新(忽略缓存):Windows:
Ctrl + F5;Mac:command + shift + R。
4.1. 响应头
Pragma:作用类似于Cache-Control,HTTP/1.0的产物Expires:缓存的过期时间(GMT格式),HTTP/1.0的产物Cache-Control:设置缓存策略no-storage:不缓存数据到本地public:允许用户、代理服务器缓存数据到本地private:只允许用户缓存数据到本地max-age:缓存的有效时间(多上时间不过期),单位:秒no-cache:每次需要发请求给服务器询问缓存是否有变化(状态码304-Not Modified),再来决定如何使用缓存
优先级:Pragma > Cache-Control > Expires
Last-Modified:资源的最后一次修改时间ETag:资源的唯一标识(根据文件内容计算出来的摘要值)
优先级:ETag > Last-Modified
4.2. 请求头
-
If-None-Match
- 如果上一次的响应头中有ETag,就会将ETag的值作为请求头的值
- 如果服务器发现资源的最新摘要值跟If-None-Match不匹配,就会返回新的资源(状态码200),否则就不会返回资源的具体数据(状态码304)
-
If-Modified-Since
- 如果上一次的响应头中没有ETag,有Last-Modified,就会将Last-Modified的值作为请求头的值
- 如果服务器发现资源的最后一次修改时间晚于If-Modified-Since,就会返回新的资源(状态码200),否则就不会返回资源的具体数据(状态码304)
4.3. Last-Modified和ETag的比较
Last-Modified的缺陷:
- 只能精确到秒级别,如果资源在1秒内被修改了,客户端将无法获取最新的资源数据。
- 如果某些资源被修改了(最后一次修改时间发生了变化),但是内容并没有任何变化。会导致相同的数据重复传输,没有使用到缓存。
以上的缺陷,ETag都可以满足:
- 只要资源的内容没有变化,就不会重复传输资源数据
- 只要资源的内容发生了变化,就会返回最新的资源数据给客户端
4.4. 缓存的使用流程
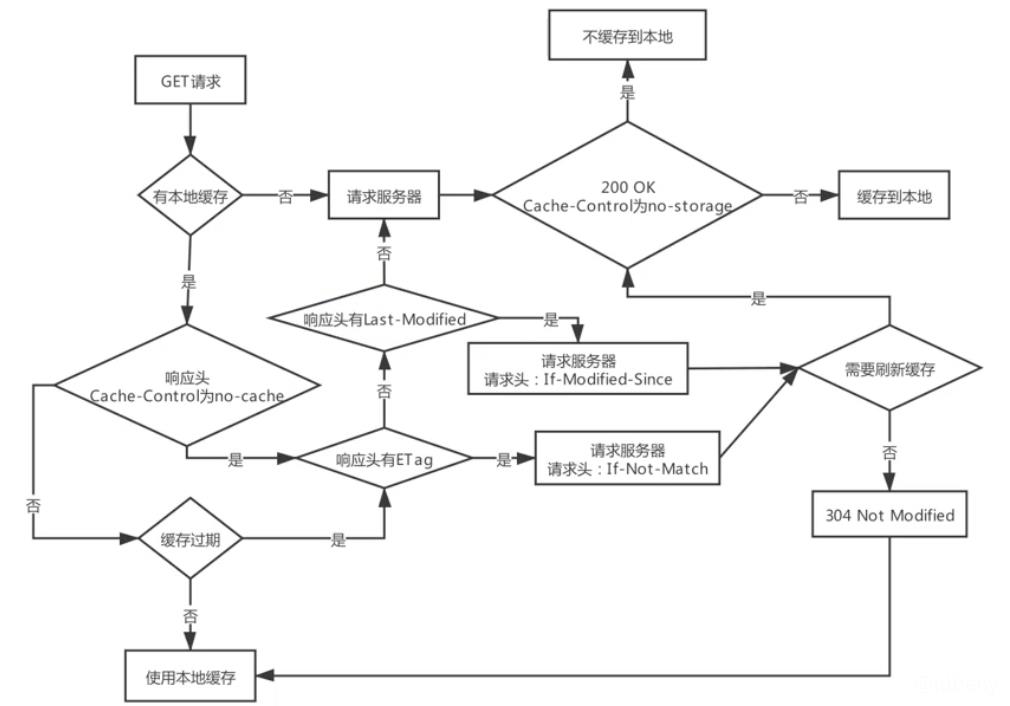
五、IPv6
IPv6(Internet Protocol version 6),网络协议第6版。
用它来取代IPv4主要是为了解决IPv4地址枯竭问题,同时它也在其他方面对于IPv4有许多改进。然而长期以来IPv4在互联网流量中仍占据主要地位,IPv6的使用增长缓慢。在2019年12月,通过IPv6使用Google服务的用户百分率首次超过30%(因为网络协议处在网络层,需要设备和操作系统内核升级支持IPv6)。
IPv6采用128位的地址,而IPv4使用的是32位。支持2^128(约3.4 * 10^38)个地址,就以地球人口70亿计算,每人平均可分得约4.86 * 10^28个IPv6地址。
5.1. 地址格式
IPv6地址为128bit,每16bit一组,共8组。每组以冒号“:”隔开,每组以4位十六进制方式表示,例如2001:0db8:86a3:08d3:1319:8a2e:0370:7344。
类似于IPv4的点分十进制,同样也存在点分十六进制的写法:2.0.0.1.0.d.b.8.8.6.a.3.0.8.d.3.1.3.1.9.8.a.2.e.0.3.7.0.7.3.4.4。
每组前面连续的0可以省略,下面的IPv6地址是等价的:
2001:0db8:02de:0000:0000:0000:0000:0e13`
// 等价于
2001:db8:2de:0:0:0:0:e13
可以用双冒号“::”表示一组0或多组连续的0,但只能出现一次(出现多次会造成歧义),下面的IPv6地址是等价的:
2001:db8:2de:0:0:0:0:e13
// 等价于
2001:db8:2de::e13
::1是本地环回地址(0:0:0:0:0:0:0:1)。
5.2. 首部格式
IPv4的首部格式比较复杂,但Ipv6的首部格式就简单很多:
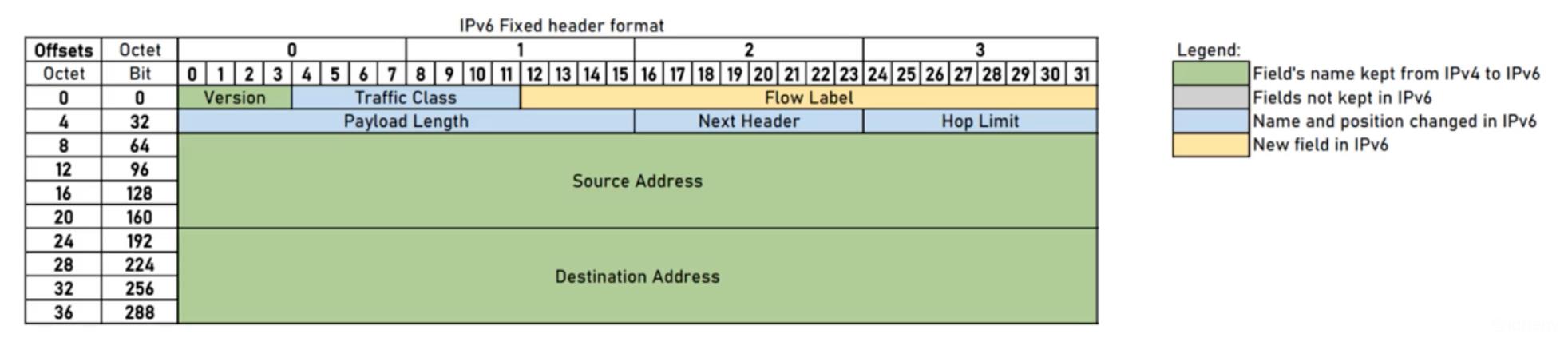
Ipv6和IPv4的首部字段对比:
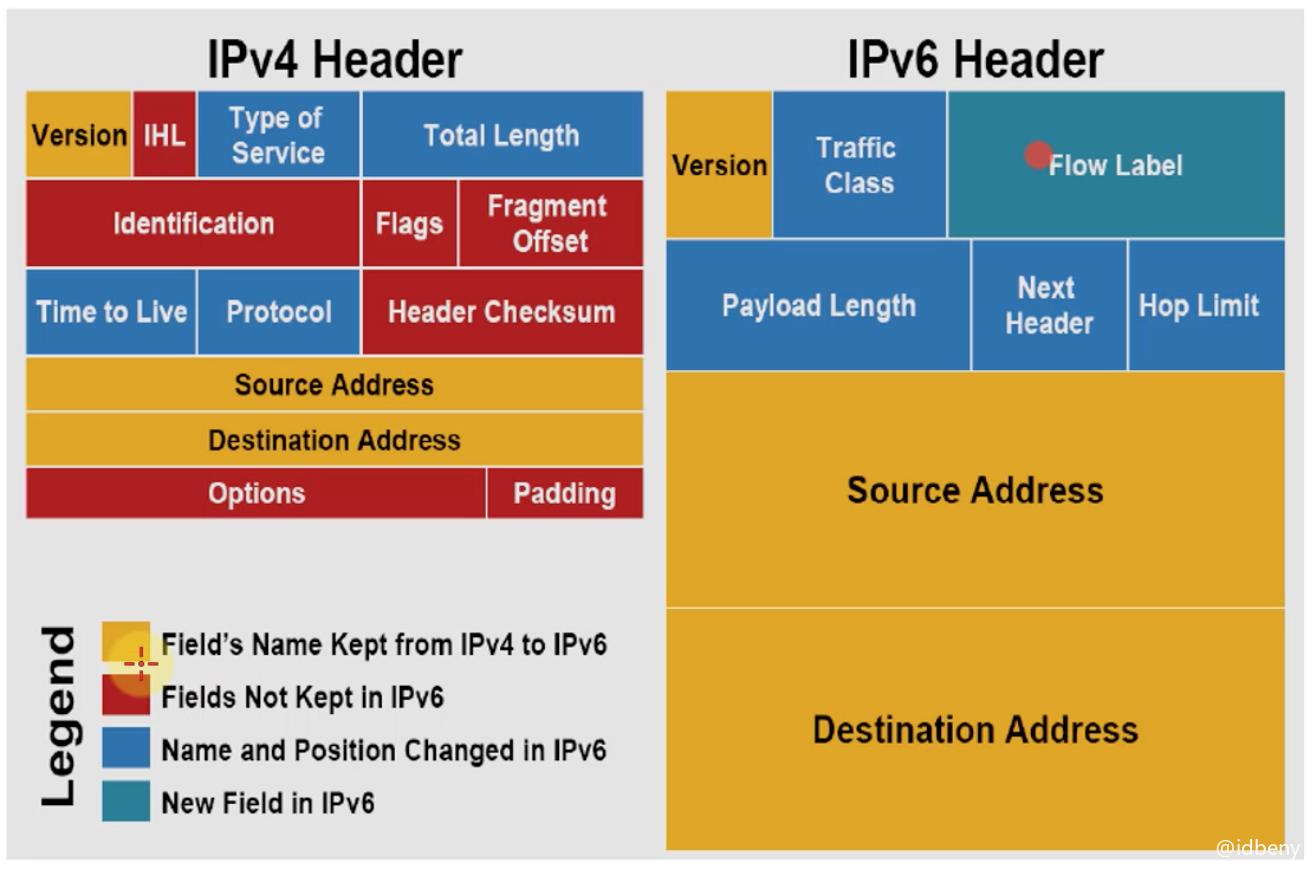
黄颜色:IPv6保留IPv4的字段
红颜色:IPv6丢弃IPv4的字段
蓝颜色:字段名字和位置发生变化
绿颜色:IPv6新的字段
- Version(占4bit,0110):版本号
- Traffic Class(占8bit):交通类别
- 指示数据包的类别或优先级,可以帮助路由器根据数据包的优先级处理流量。如果路由器发生拥塞,则优先级最低的数据包将被丢弃。
- Payload Length(占16bit):有效负载长度
- 最大值:65535字节,包括了扩展头部、上层(传输层)数据的长度。
- Hop Limit(占8bit):跳数限制,与IPv4数据包中的TTL相同。
- Source Address(占128bit):源IPv6地址
- Destination Address(占128bit):目的IPv6地址
- Flow Label(占20bit):流标签
- 指示数据包属于哪个特定序列(流),用数据包的源地址、目的地址、流标签标识一个流
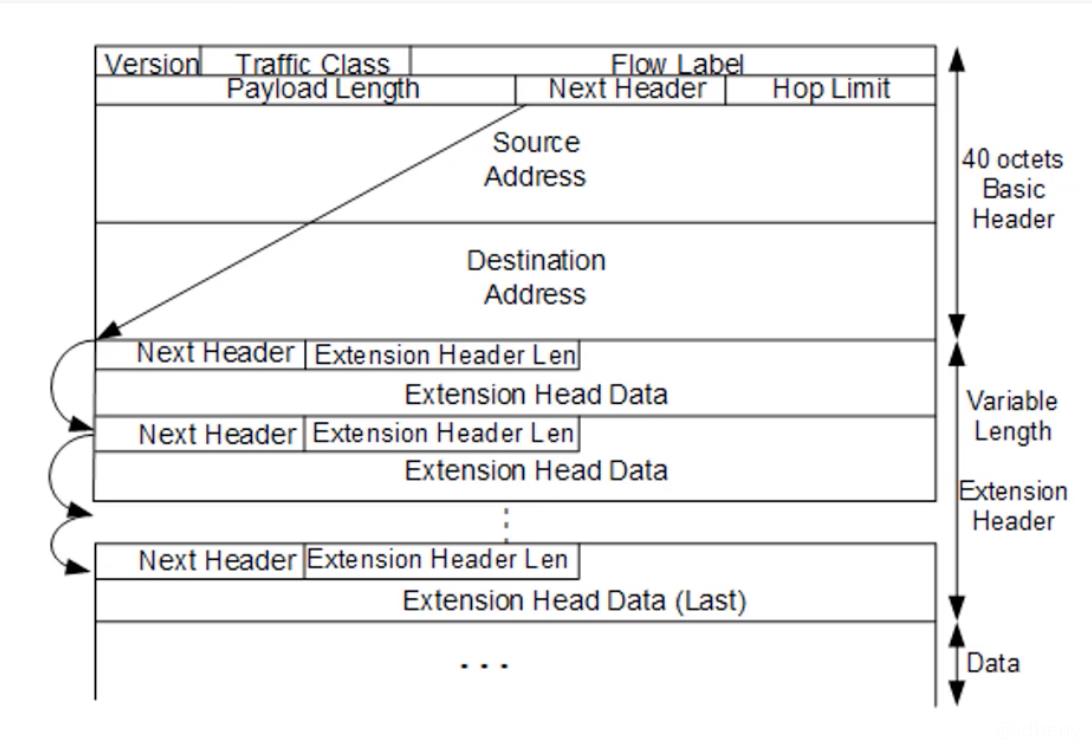
5.3. 扩展头部
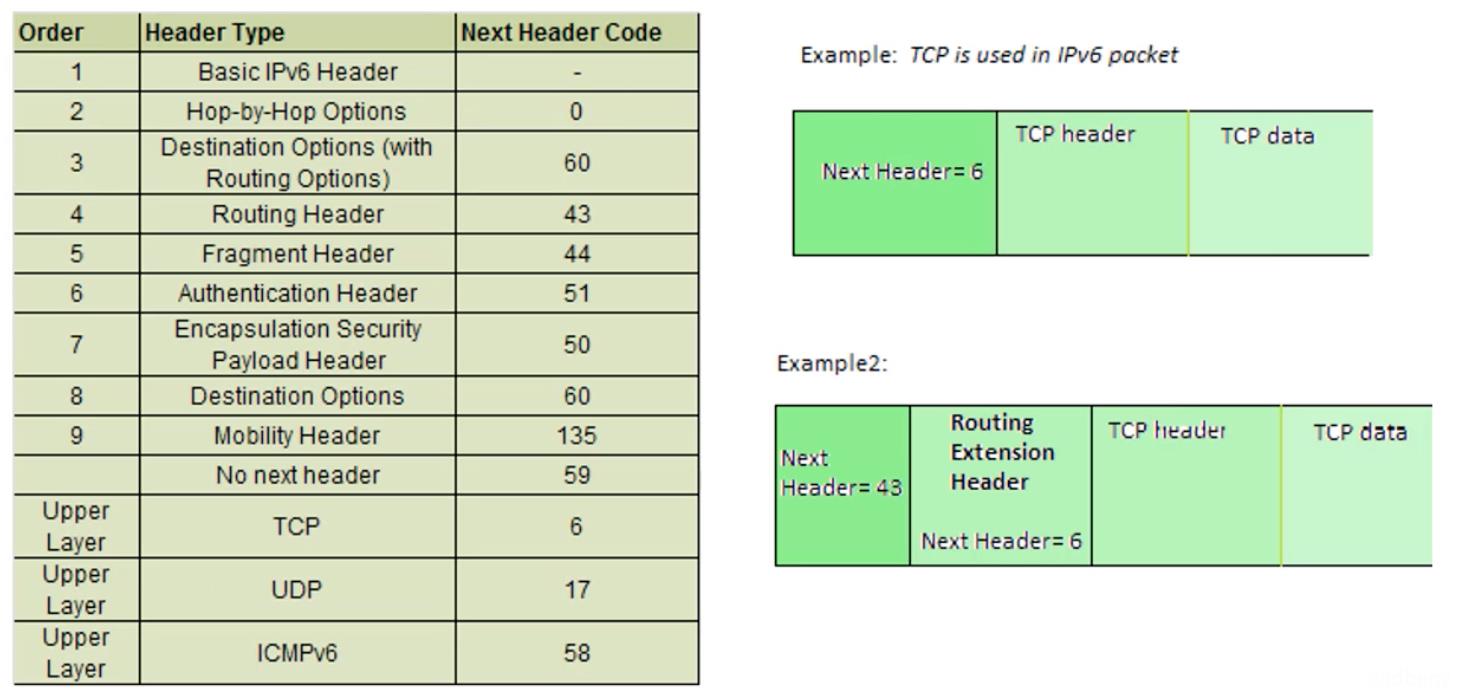
Next Header(占8bit):下一个头部,指示扩展头部(如果存在)的类型,上层数据包的协议类型(例如TCP、UDP、ICMPv6)。

Next Header类型和对应值:
六、即时通信
即时通信(Instant Messaging,简称:IM),平时用的QQ、微信都属于典型的IM应用。
国内的IM开发者社区:http://www.52im.net
IM云服务:网易云信、腾讯云、环信等。
常用的协议:XMPP、MQTT、自定义协议。
6.1. XMPP
XMPP(Extensible Messaging and Presence Protocol),可扩展消息与存在协议,前身是Jabber。基于TCP,默认端口是5222、5269。
特点:
- 使用XML格式进行传输,体积较大。
- 比较成熟的IM协议,开发者接入方便。
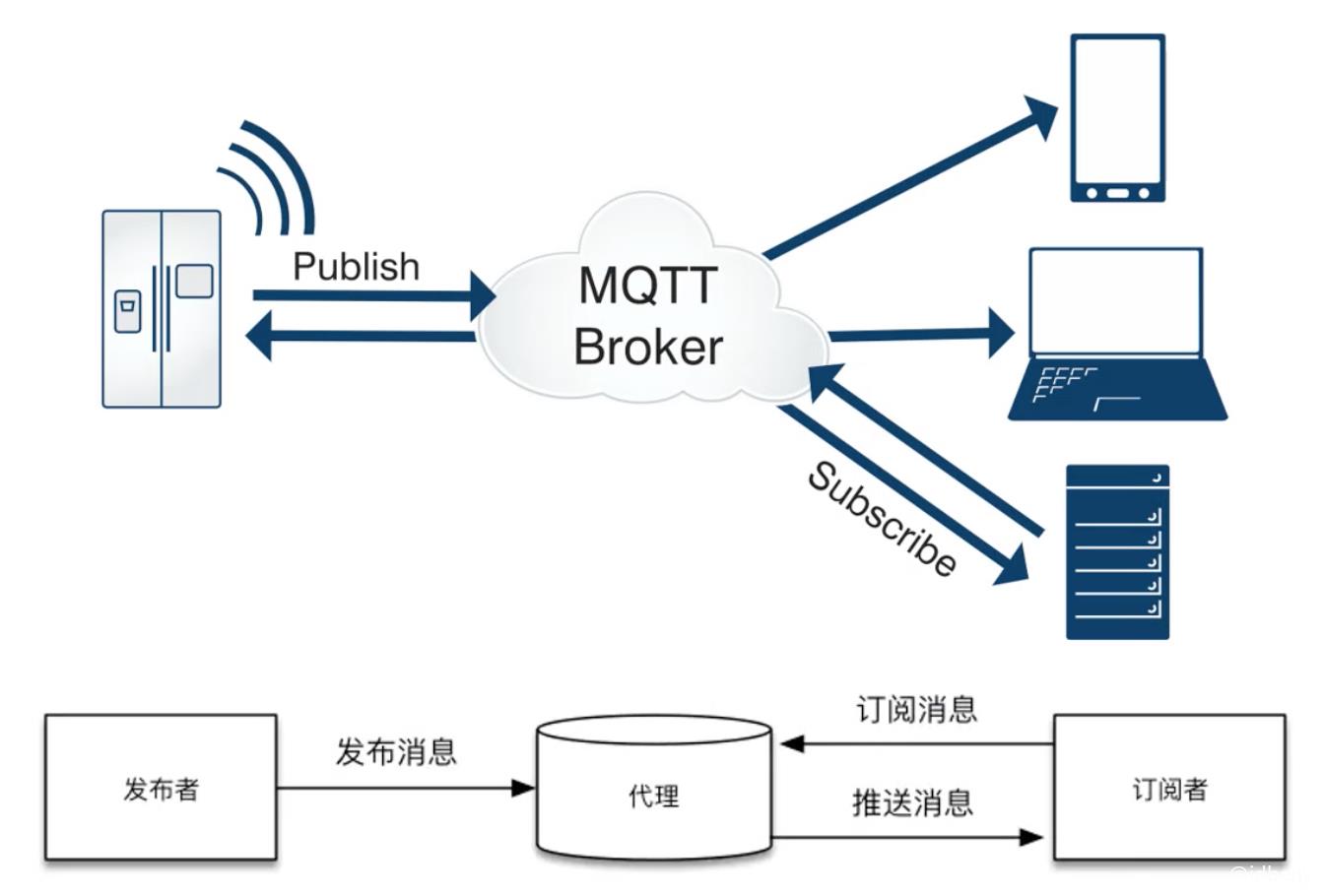
6.2. MQTT
MQTT(Message Queuing Telemetry Transport),消息队列遥测传输。基于TCP,默认端口是1883、8883(带SSL/TLS)。
特点:
- 开销很小,以降低网络流量,信息冗余远小于XMPP。
- 不是专门为IM设计的协议,很多功能需要自己实现。
- 很多人认为MQTT是最适合物联网(Internet of Things,简称:loT)的网络协议。
采用的是订阅者模式:
七、流媒体
流媒体(Streaming Media),又叫流式媒体。是指将一连串的多媒体数据压缩后,经过互联网分段发送数据,在互联网上即时传输影音以供观赏的一种技术。此技术使得资料数据包得以像流水一样发送,不使用此技术,就必须在使用前下载整个媒体文件。
常见协议:
RTP(Real-Time Transport Protocol),实时传输协议。是基于UDP的,可参考RFC_3550、RFC_3551。
RTCP(Real-Time Transport Control Protocol),实时传输控制协议。基于UDP,使用RTP的下一个端口。参考RFC_3550。
RTSP(Real-Time Streaming Protocol),实时流协议。RFC_7820。基于TCP、UDP的554端口。
RTMP(Real-Time Messaging Protocol),实时消息传输协议。由Adobe公司出品。默认基于TCP的1935端口。
HLS(HTTP Live Streaming),基于HTTP的流媒体网络传输协议,苹果公司出品。参考RFC_8216。

以上是关于网络协议系列十八 - 网络爬虫/HTTP缓存/IPv6的主要内容,如果未能解决你的问题,请参考以下文章