ClickHouse如何在字节跳动内部演化的,详解(建议收藏)
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse如何在字节跳动内部演化的,详解(建议收藏)相关的知识,希望对你有一定的参考价值。


关注公众号,获取更多一线大厂最新技术

 安排!~
安排!~

本文摘要:今天分享的主要内容是ClickHouse在字节跳动内部的技术演化
分享时间:2021年5月28日
内容分享:陈*星
摘要整理:皮卡丘
主要内容:
1、ClickHouse简介
2、字节跳动如何使用ClickHouse
3、问题与解决方案


一、ClickHouse简介
1.1 简介:
1. Developed by Yandex, and open source since 2016
2. 查询性能优越的分析型引擎
3. 主要特点:
面向列+向量执
本地连接存储(非Hadoop生态系统)
线性可扩展且可靠(分片+副本)
标准SQL接口
快!!!(为什么会快?)
1.2 性能优越的因素:
1. Data Skipping
分区以及分区剪枝
数据局部有序(LSM-like engine, zone map)
2. 资源的垂直整合
并发 MPP+ SMP(plan level)
Tuned执行层实现 (multi-variant agg implementation…, SIMD)
3. C++ Template Code
1.3 适用场景与不足:
1. 适用场景:
单表分析\\大宽表
绝大多数请求都是用于读访问的
2. 不足:
不持事务、不支持真正的删除/更新
不支持高并发,官方建议qps为100
不支持二级索引
有限的SQL支持,Join实现与众不同
注:ClickHouse版本更新速度贼快,未来这些不足可能都会得到解决

二、字节跳动如何使用ClickHouse
2.1. 选择ClickHouse的原因:
交互式分析能力 (in seconds)
查询模式多变
以大宽表为主
数据量大
开源MPP OLAP引擎-(性能、特性、质量)
2.2.1. 字节跳动如何使用ClickHouse:
几千个节点, 最大集群1200个节点
数据总量 ~ 几十PB
日增数据 ~ 100TB
查询响应时间(mostly) ~ ms - 30s
覆盖产品运营、分析师、开发人员、少量广告类用户、openapi
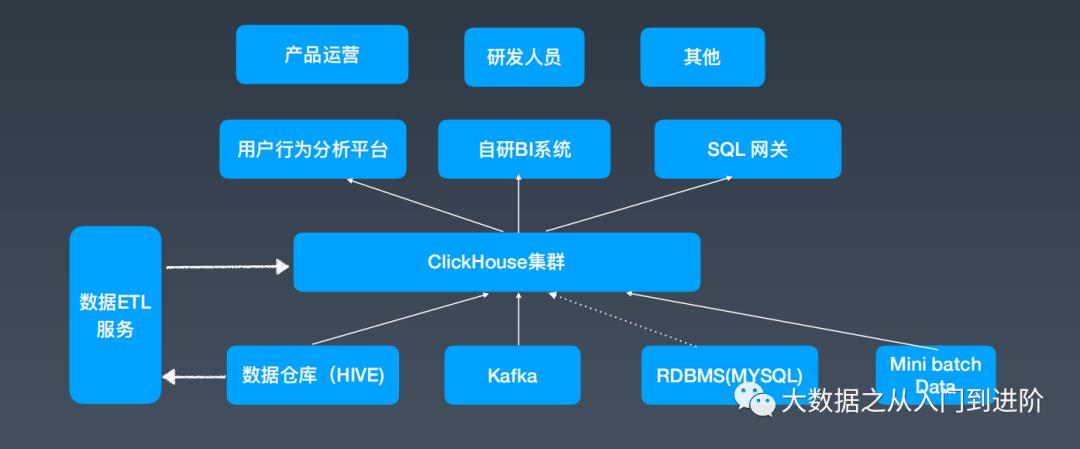
2.2.2. 字节跳动如何使用ClickHouse:
多种数据源 (离线 + 实时 + …) ,如上图
交互式分析
数据处理链路对业务方透明
满足数据中台对数据查询需求

三、问题与解决(老师说该划重点了!!)
3.1 数据源-->ClickHouse服务化:
上架构图:
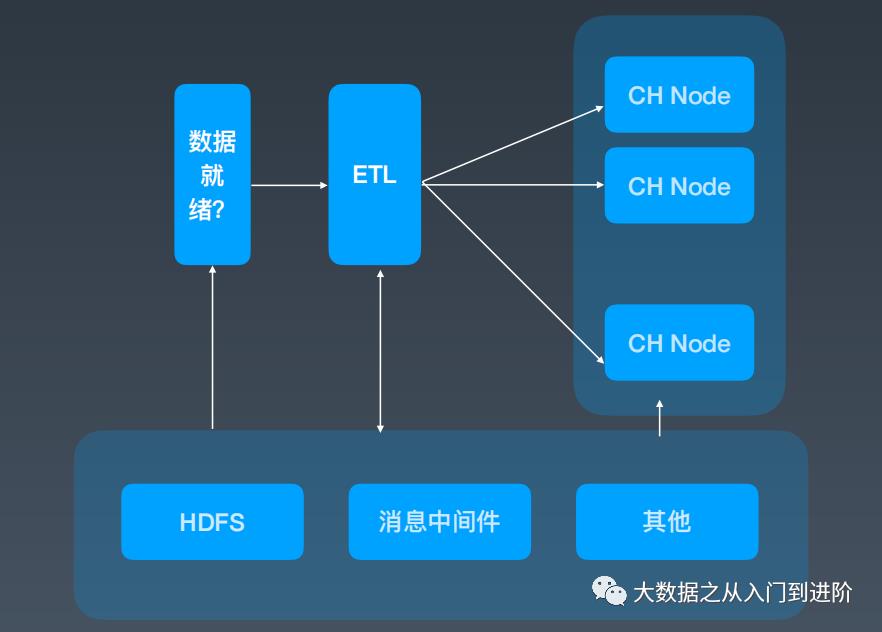
问题描述:
HDFS数据访问
数据导入过程中Failover
CK数据就绪速度(Part生成)
解决方案:
增加HDFS数据访问能力(HDFS client porting from HAWQ)
ETL服务维护外部事务保障数据一致性(fail over)
INSERT INTO LOCAL TABLE
数据构建与查询分离 (experimental feature)
3.2 Map数据类型-动态Schema:
问题描述:
客户端上报字段多变 (自定义参数)
数据产品需要相对固定schema
性能需求:访问MAP 键值需要与访问POD 类型的列速度一致
实现方式:LOB ?Two-implicit column? Other
问题调研:
数据特征:# keys 总量可控, 局部有限
局部(PART level)展平模型 (自描述)

解决方案:
MAP键访问自动改写
"select c_map{'a'} from table" will be rewrote to "select c_map_a from table"
MAP列访问 (代价较大)
select c_map from table
Merge阶段优化(无需重构MAP column)
收益:
自动化接入
Table schema 简化
极大简化数据构建(ETL)逻辑
语法示范:
Create table t(c1 UInt64, c2 Map(String, UInt8)) ENGINE=MergeTree….
insert into t values(1, {'abc':1, 'bcd':2})
Select c2{'abc'} from t
3.3 Zookeeper使用问题:
问题背景:
两副本保障数据
ReplicatedMergeTree in ClickHouse (Issue)
- Async Master-Master replication
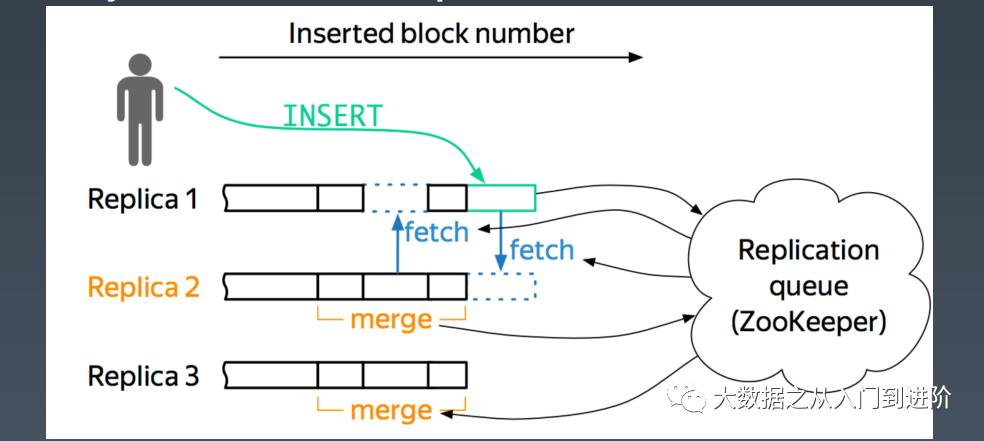
问题描述:
ReplicatedMergeTree的问题
ZooKeeper压力大,znode太多
400 Nodes 集群, 半年数据, 800万znodes
ReplicatedMergeTree use ZK to store:
Table schema
副本状态(part info & log info)
分片(shard) 状态
问题调研:
数据继续增长会导致ZK无法服务
社区mini checksum in zk能缓解内存使用,但不能解决问题
基于MergeTree开发HA 方案
解决方案:【HaMergeTree】
ZooKeeper只用作coordinate
Log Sequence Number(LSN) 分配
数据Block ID 分配
元数据管理
节点维护local log service (action log)
Log 在分片内部节点间通过Gossip协议交互
数据信息(parts) 按需交互
外部接口与社区兼容(例如:multi-master写入)
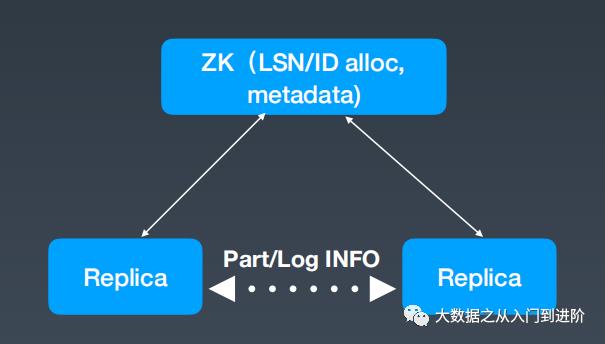
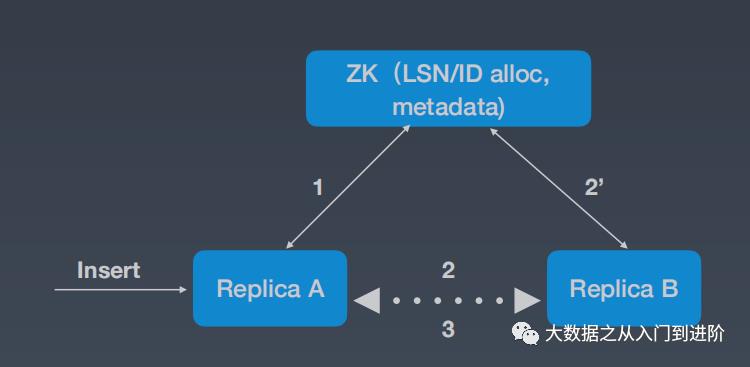
解决方案:
1. A 获取LSN和Block ID
2.1 A Push log to active replica B
2.2 B get its log lags from ZK and pull logs from A
3. B redo the log and get Block from A
收益:
ZooKeeper压力不会随着数据量增长
~ 3M znodes in ZK
保障数据&服务高可用
3.4 String 类型处理效率-Global Dictionary:
问题描述:
String 类型的滥用(from HIVE), 处理低效
Why not LowCardinalityColumn?
算子尽量在压缩域上执行(actionable compression)
pure dictionary compression
predication (equality family)
group by (single/composite keys)
问题背景:
Per replica字典(异步)构建
why not cluster level/shard level?
Support xxMergeTree only
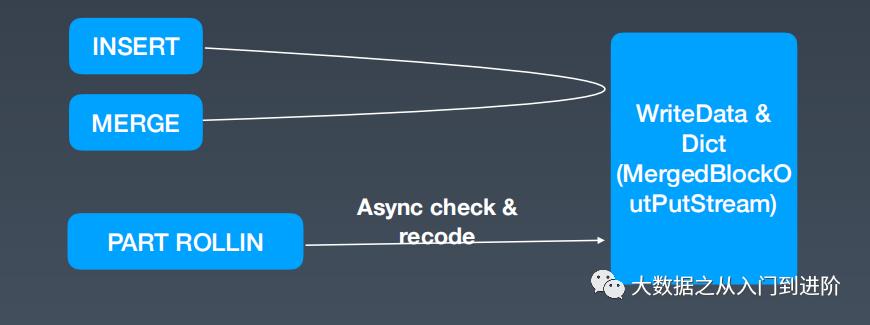
解决方案:
压缩域执行
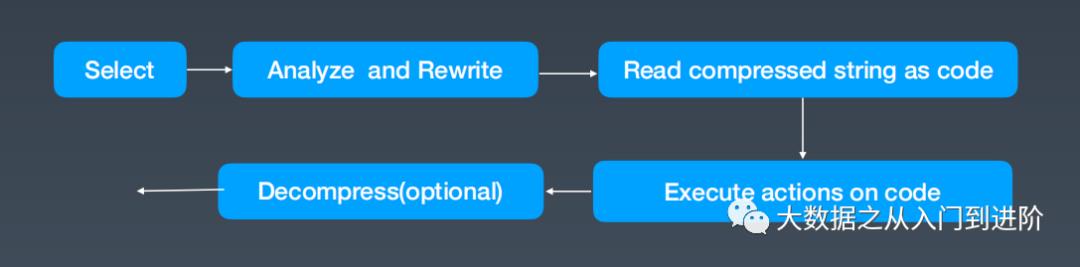
分布式表字典 (per shard, per replica)
分布式表压缩域执行
收益:
性能提升约 20% ~ 30%
3.5 特定场景内存OOM - Step-ed Aggregation:
问题描述:
Query:60天内用户转化率/行为路径,以及对应每天转化率
内存使用量大,OOM对服务稳定性影响
Aggregator无法感知底层数据特性
解决方案:
Aggregator 由执行HINT控制
HINT 感知数据分区/指标语义
Blocked Aggregator 按partition pipeline计算指标
收益:
内存使用比默认方式降低约五倍
3.6 Array类型处理 - BloomFilter & BitMap index:
问题描述:
Array类型用来表示实验ID
Query:命中某些实验的用户指标
单条记录Array(实验)~ 几百 or 上千

解决方案:
需要辅助信息减少 Array column materialize
Two scale BloomFilter (Part level, MRK range level)
减少Long Array column in Runtime Block
Transform hasAny into BitMap index OR-ing
Array Column —> value+BitMap 集合
has(array, value) —> get BitMap (执行层自动改写)

四、写在最后
内容整理不易,欢迎感兴趣的小伙伴关注,我会定期分享各个大厂的技术资料,欢迎留言讨论。
识别下方二维码,关注后,点击 “资料获取”,即可获取免费学习资料,并且资料在不断更新中。记得关注点赞、点点在看哦!ღ( ´・ᴗ・` )笔芯~

END
以上是关于ClickHouse如何在字节跳动内部演化的,详解(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章
深度学习核心技术精讲100篇(三十)-ClickHouse在字节跳动广告业务中的应用
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
吊打面试官了解一下?2021年字节跳动春招面试题详解(附详细答案)