SQL进阶篇
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL进阶篇相关的知识,希望对你有一定的参考价值。
🐾今天我们来说一说SQL进阶篇的一些操作,主要的内容包含一些特殊函数介绍,例如:字符函数,时间函数,窗口函数等。详细内容请看下面👇:
目录
1.字符函数
1.1 拼接两个字段
--CONCAT函数
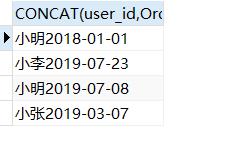
SELECT CONCAT(user_id,Order_date) #拼接两个字段
from ord;
结果如下:
1.2 转换大小写
--LOWER与UPPER
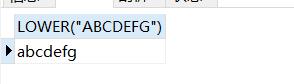
SELECT LOWER("ABCDEFG");#转换为小写
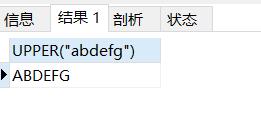
SELECT UPPER("abdefg");#转化为大写
结果如下:
1.3 获取字符
--LEFT(str,n)取str左边起前n个字符
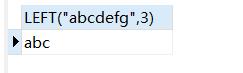
SELECT LEFT("abcdefg",3)#返回字符串右边3个字符
结果如下:
1.4 替换字符
--REPLACE(str,"s1","s2")使用s2代替str中的s1
SELECT REPLACE("ABCDEFG","CDE","cde");#使用cde代替字符串ABCDEFG 中的CDE
结果如下:
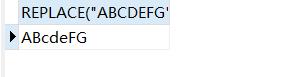
1.5 反转字符
-- REVERSE()函数
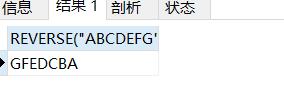
SELECT REVERSE("ABCDEFG");#反转字符
结果如下:
2.日期时间函数
2.1 获取当前日期时间
-- now()函数
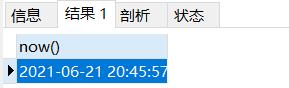
SELECT now() #选择当前日期时间
结果如下:
2.2 获取当前日期
--CURDATE()函数
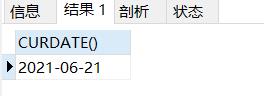
SELECT CURDATE()#选择当前日期
结果如下:
2.3 获取当前时间
--CURTIME()获取当前时间点
SELECT CURTIME()#选择当前时间点
结果如下:
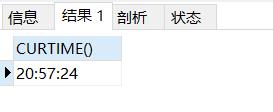
2.4 获取年、月、日
--YEAR(),MONTH(),DAY()#选择当前的年,月,日
SELECT YEAR(NOW()),MONTH(NOW()),DAY(NOW())#选择当前的年,月,日
结果如下:
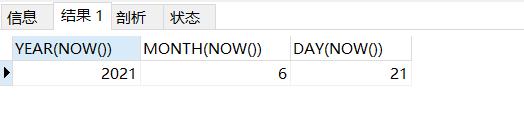
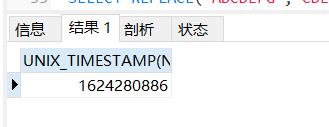
2.5 格林威治时间至某时间的秒数
--UNIX_TIMESTAMP()函数
SELECT UNIX_TIMESTAMP(NOW())#选择从1970-01-01到现在的秒数
结果如下:
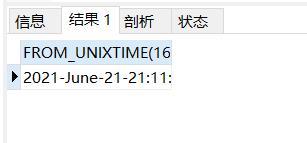
也可以将秒数转换回去
--FROM_UNIXTIME()#反转秒数
SELECT FROM_UNIXTIME(1619712170,'%Y-%M-%d-%T')#将时间反转回去
结果如下:
2.6 天数之差
--DATEDIFF()#两日期之差,单位为天数。
SELECT DATEDIFF("2021-04-20","2021-04-10")#时间差,以天数为单位
结果如下:

2.7 转换时间格式
--DATE_FORMAT转换时间格式
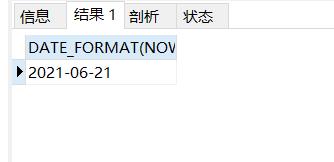
SELECT DATE_FORMAT(NOW(),'%Y-%m-%d')#转换时间格式
结果如下:
3.窗口函数
常见的窗口函数:
- 聚合类
sum()/count()/avg()/max()/min()over() - 排序窗口函数
rank()over( ) 考虑数据重复,如1,1,3
dense_rank()over()考虑数据重复 ,如1,1,2
row_number()over()不考虑数据重复,如 1,2,3 - 分组窗口函数
ntile(n)over() - 偏移分析窗口函数
lag(expr,n,default)over()
lead(expr,n,default)over()
这里说一下窗口函数的范围,其实每个窗口函数后面都需要增加rows between来指定窗口的范围。

3.1 按照年份分组然后求和
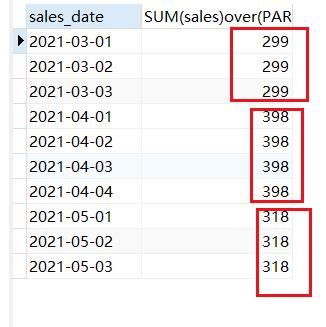
#根据年与月份分组,然后求和
SELECT sales_date,SUM(sales)over(PARTITION by DATE_FORMAT(sales_date,'%Y-%m'))
FROM sales_rank;
结果如下:
3.2 按照年份分组然后求和(指定求和行)
#指定窗口的前后行
SELECT sales_date,AVG(sales)over(PARTITION by MONTH(sales_date) ORDER BY sales_date rows BETWEEN 1 preceding AND 1 following)
from sales_rank
结果如下:
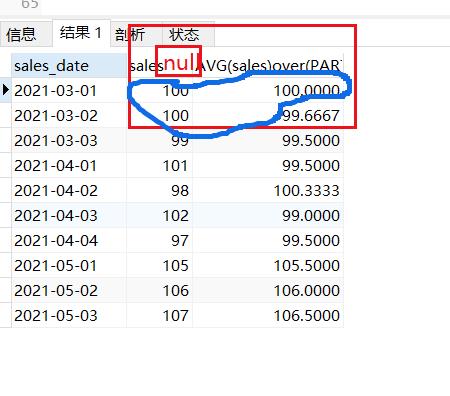
解释一下:这里的第一行只有后面一行,前面没有行,所以计算的只有前两行的平均值,3-02只有前两个没有后两个。所以是(100+99)/ 2=99.5。
3.3 排序函数
rank() 考虑数据重复,挤占坑位
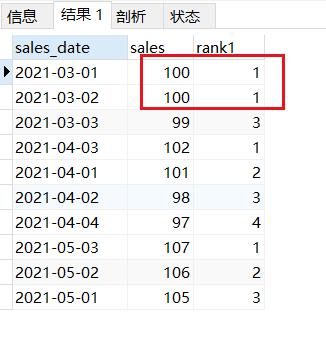
--rank排序
SELECT sales_date,sales,rank()over(PARTITION by MONTH(sales_date) ORDER BY sales DESC) rank1
FROM sales_rank;
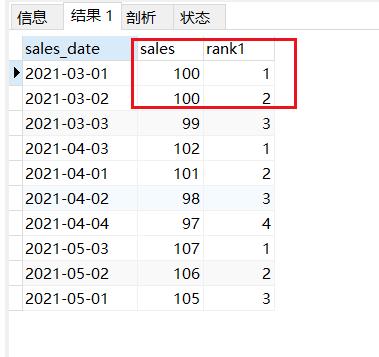
结果如下:1,1,3
row_number() 考虑数据重复,不挤占坑位
#row_number()排序
SELECT sales_date,sales,row_number()over(PARTITION by MONTH(sales_date) ORDER BY sales DESC) rank1
FROM sales_rank;
结果如下:1,2,3
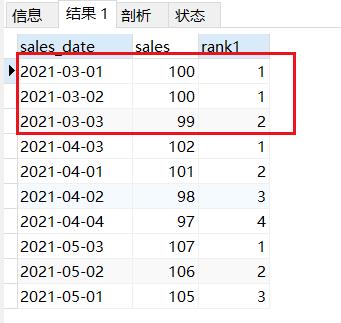
dense_rank() 不考虑数据的重复性,按照顺序依次标号
SELECT sales_date,sales,dense_rank()over(PARTITION by MONTH(sales_date) ORDER BY sales DESC) rank1
FROM sales_rank;
结果如下:1,1,2
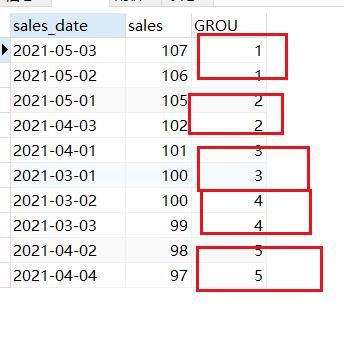
3.4 分组函数ntile
这个函数可以获取前百分之n的数据。
--ntile函数
select sales_date,sales,NTILE(5)over(ORDER BY sales DESC) GROU
FROM sales_rank;
结果如下:
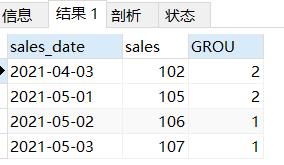
我们怎么获取前百分之n的数据呢?我们可以做一个子查询。
--做一个子查询,取1,2标签的值,就去取出了40%的数据
SELECT *
FROM (
select sales_date,sales,NTILE(5)over(ORDER BY sales DESC) GROU
FROM sales_rank
)tmp
WHERE GROU IN (1,2)
ORDER BY sales_date;
3.5 lag向前偏移
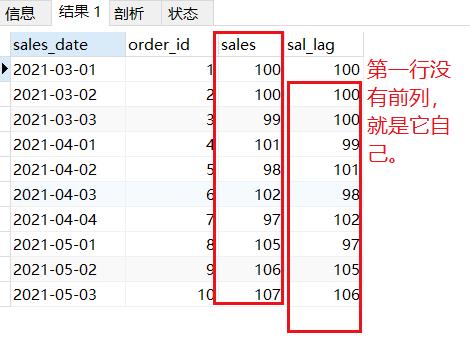
--LAG(sale,n,sale)向前n行偏移。
SELECT * ,LAG(sales,1,sales)over(ORDER BY sales_date) sal_lag
FROM sales_rank;
3.6 lead向前偏移
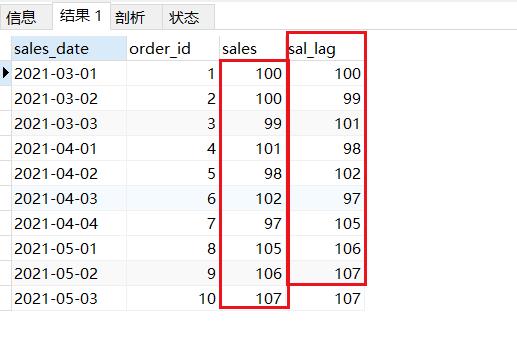
--## lead向上偏移
SELECT * ,LEAD(sales,1,sales)over(ORDER BY sales_date) sal_lag
FROM sales_rank;
结果如下:向上偏移
以上就是本章节的全部内容,有什么错误还行小伙伴们指点!
以上是关于SQL进阶篇的主要内容,如果未能解决你的问题,请参考以下文章