CUDA程序优化之数据传输
Posted 帅的发光发亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA程序优化之数据传输相关的知识,希望对你有一定的参考价值。
CUDA程序优化之数据传输
一、设备端和主机端的数据相互拷贝
设备端指GPU端,数据存放在显存中;主机端指CPU,数据存放在内存中。一般情况下,一般情况下设备端是不能直接访问主机端内存的,而我们的数据通常情况下都是存放在主机端内存中,要在GPU中执行算法运算就必须先把数据拷贝至设备端,运算完成再把结果拷回至主机端。这个传输过程,显然是会耗时的。
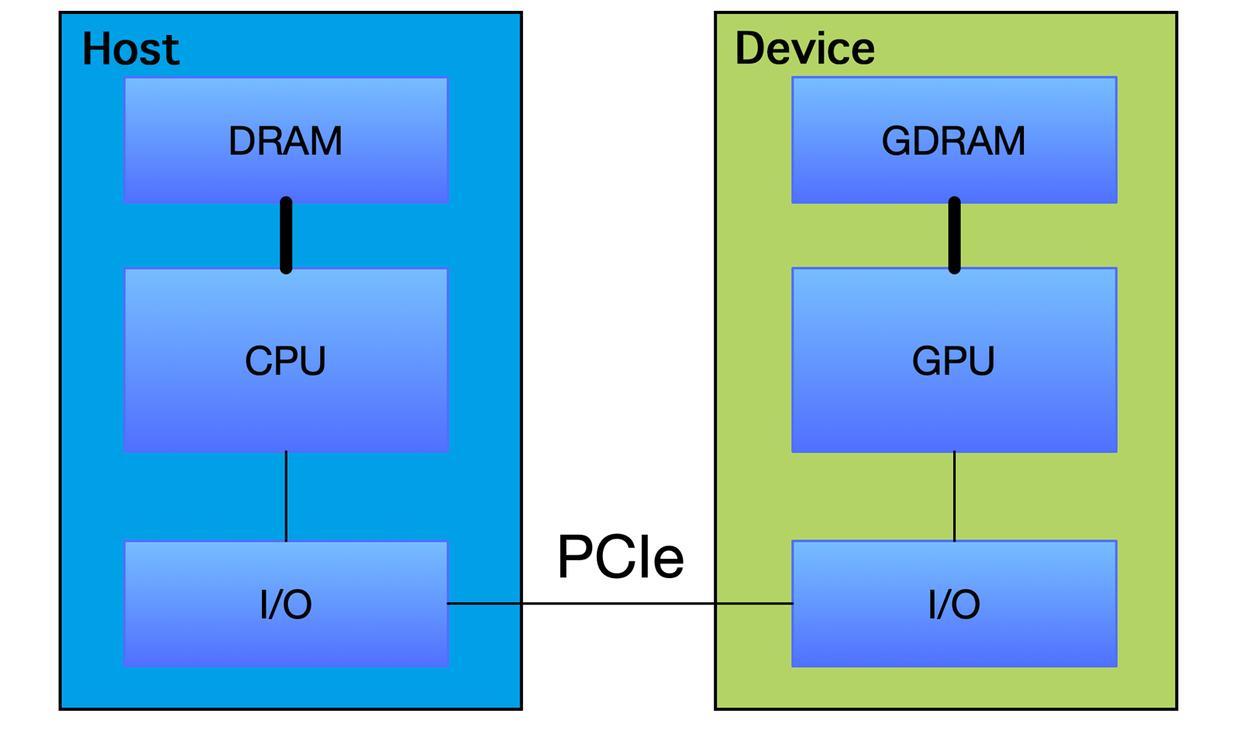
传输需要多少耗时? 这和PCIe总线带宽正相关。PCIe是CPU和GPU之间数据传输的接口,发展至今有多代技术,从之前的PCIe 1.0到现在的PCIe 3.0、PCIe 4.0,带宽越来越大,传输也是越来越快。一般PCIe会有多条Lane并行传输,理论传输速度成倍增加,我这里列一下多路PCIe 3.0、PCIe 4.0各自的带宽数值:

我用GPU-Z查了查我的MX150,显示是PCIe x4 3.0,对应上表中的400MB/s的带宽。
我们可以通过总线带宽来计算数据传输耗时,以一张1280x960的灰度图像为例,1个像素占1个字节,则传输数据量为 1280x960x1 B = 1228800 B = 1200 KB = 1.172 MB。若用我的MX150,则传输耗时 t = 1.172/4000 s ≈ 0.29 ms。看起来很少对不对,但我们算的可是理论峰值带宽,你见过有几个产品能到理论峰值的呢?最后的时间基本是要打较大折扣的,时间估计在0.35ms左右,你可能还是觉得很少,但是如果你传的是彩色图(一个像素3个字节)呢?要是一次需要传两张图呢?t = 0.35 x 3 x 2 = 2.1 ms,对于GPU算法来说,这个时间就不该被忽视了。
二、不同的内存分配/传输方式,传输效率有何不同?
(1)常规方式传输:cudaMemcpy
在CUDA中常规的传输接口是cudaMemcpy,我想这也是被使用最多的接口,他可以将数据从主机端拷贝至设备端,也可以从设备端拷贝至主机端,函数声明如下:
__host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
cudaMemcpyKind决定拷贝的方向,有以下取值:
cudaMemcpyHostToHost = 0
Host -> Host
cudaMemcpyHostToDevice = 1
Host -> Device
cudaMemcpyDeviceToHost = 2
Device -> Host
cudaMemcpyDeviceToDevice = 3
Device -> Device
cudaMemcpyDefault = 4
Direction of the transfer is inferred from the pointer values. Requires unified virtual addressing
该方式使用非常简单,很多情况下效率也足以满足性能需求。
(2)高维矩阵传输:cudaMemcpy2D/cudaMalloc3D
顾名思义,cudaMemcpy2D/cudaMalloc3D是应对2D及3D矩阵数据的。以图像为例,我们可以用cudaMalloc来分配一维数组来存储一张图像数据,但这不是效率最快的方案,推荐的方式是使用cudaMallocPitch来分配一个二维数组来存储图像数据,存取效率更快。
__host__ cudaError_t cudaMallocPitch ( void** devPtr, size_t* pitch, size_t width, size_t height )
相比于cudaMemcpy2D对了两个参数dpitch和spitch,他们是每一行的实际字节数,是对齐分配cudaMallocPitch返回的值。
__host__ cudaError_t cudaMemcpy2D ( void* dst, size_t dpitch, const void* src, size_t spitch, size_t width, size_t height, cudaMemcpyKind kind )
cudaMallocPitch有一个非常好的特性是二维矩阵的每一行是内存对齐的,访问效率比一维数组更高。而通过cudaMallocPitch分配的内存必须配套使用cudaMemcpy2D完成数据传输。C 中二维数组内存分配是转化为一维数组,连贯紧凑,每次访问数组中的元素都必须从数组首元素开始遍历;而 cuda 中这样分配的二维数组内存保证了数组每一行首元素的地址值都按照 256 或 512 的倍数对齐,提高访问效率,但使得每行末尾元素与下一行首元素地址可能不连贯,使用指针寻址时要注意考虑尾部。
- cudaMAllocPitch() 传入存储器指针 **devPtr,偏移值的指针 *pitch,数组行字节数 widthByte,数组行数 height。函数返回后指针指向分配的内存(每行地址对齐到 AlignByte 字节,为 256B 或 512B),偏移值指针指向的值为该行实际字节数(= sizeof(datatype) * width + alignByte - 1) / alignByte)。
- cudaMemcpy2D() 传入目标存储器的指针 *dst,目标存储器行字节数 dpitch,源存储器指针 *src,源存储器行字节数 spitch,数组行字节数 width,数组行数 height,拷贝方向 kind。这里要求存储器行字节数不小于数组行字节数,多出来的部分就是每行尾部空白部分。
- 整个测试代码。
并非说cudaMemcpy2D/cudaMemcpy3D比cudaMemcpy传输更快,而是对齐内存必须使用cudaMemcpy2D/cudaMemcpy3D来配套使用。
#include <stdio.h>
#include <malloc.h>
#include <cuda_runtime_api.h>
#include "device_launch_parameters.h"
__global__ void myKernel(float* devPtr, int height, int width, int pitch)
{
int row, col;
float *rowHead;
for (row = 0; row < height; row++)
{
rowHead = (float*)((char*)devPtr + row * pitch);
for (col = 0; col < width; col++)
{
printf("\\t%f", rowHead[col]);// 逐个打印并自增 1
rowHead[col]++;
}
printf("\\n");
}
}
int main()
{
size_t width = 6;
size_t height = 5;
float *h_data, *d_data;
size_t pitch;
h_data = (float *)malloc(sizeof(float)*width*height);
for (int i = 0; i < width*height; i++)
h_data[i] = (float)i;
printf("\\n\\tAlloc memory.");
cudaMallocPitch((void **)&d_data, &pitch, sizeof(float)*width, height);
printf("\\n\\tPitch = %d B\\n", pitch);
printf("\\n\\tCopy to Device.\\n");
cudaMemcpy2D(d_data, pitch, h_data, sizeof(float)*width, sizeof(float)*width, height, cudaMemcpyHostToDevice);
myKernel << <1, 1 >> > (d_data, height, width, pitch);
cudaDeviceSynchronize();
printf("\\n\\tCopy back to Host.\\n");
cudaMemcpy2D(h_data, sizeof(float)*width, d_data, pitch, sizeof(float)*width, height, cudaMemcpyDeviceToHost);
for (int i = 0; i < width*height; i++)
{
printf("\\t%f", h_data[i]);
if ((i + 1) % width == 0)
printf("\\n");
}
free(h_data);
cudaFree(d_data);
getchar();
return 0;
}
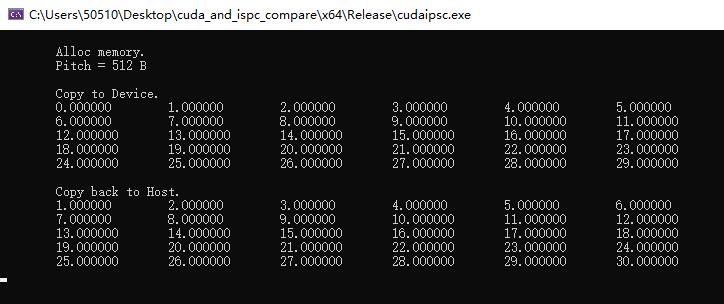
结果:
3D矩阵的配套API为:
__host__ cudaError_t cudaMalloc3D ( cudaPitchedPtr* pitchedDevPtr, cudaExtent extent )
__host__ cudaError_t cudaMemcpy3D ( const cudaMemcpy3DParms* p )
代码示例如下:
#include <stdio.h>
#include <malloc.h>
#include <cuda_runtime_api.h>
#include "device_launch_parameters.h"
#include <driver_functions.h>
__global__ void myKernel(cudaPitchedPtr devPitchedPtr, cudaExtent extent)
{
float * devPtr = (float *)devPitchedPtr.ptr;
float *sliceHead, *rowHead;
// 可以定义为 char * 作面、行迁移的时候直接加减字节数,取行内元素的时候再换回 float *
for (int z = 0; z < extent.depth; z++)
{
sliceHead = (float *)((char *)devPtr + z * devPitchedPtr.pitch * extent.height);
for (int y = 0; y < extent.height; y++)
{
rowHead = (float*)((char *)sliceHead + y * devPitchedPtr.pitch);
for (int x = 0; x < extent.width / sizeof(float); x++)// extent 存储的是行有效字节数,要除以元素大小
{
printf("\\t%f",rowHead[x]);// 逐个打印并自增 1
rowHead[x]++;
}
printf("\\n");
}
printf("\\n");
}
}
int main()
{
size_t width = 2;
size_t height = 3;
size_t depth = 4;
float *h_data;
cudaPitchedPtr d_data;
cudaExtent extent;
cudaMemcpy3DParms cpyParm;
h_data = (float *)malloc(sizeof(float) * width * height * depth);
for (int i = 0; i < width * height * depth; i++)
h_data[i] = (float)i;
printf("\\n\\tAlloc memory.");
extent = make_cudaExtent(sizeof(float) * width, height, depth);
cudaMalloc3D(&d_data, extent);
printf("\\n\\tCopy to Device.\\n");
cpyParm = {0};
cpyParm.srcPtr = make_cudaPitchedPtr((void*)h_data, sizeof(float) * width, width, height);
cpyParm.dstPtr = d_data;
cpyParm.extent = extent;
cpyParm.kind = cudaMemcpyHostToDevice;
cudaMemcpy3D(&cpyParm);
myKernel << <1, 1 >> > (d_data, extent);
cudaDeviceSynchronize();
printf("\\n\\tCopy back to Host.\\n");
cpyParm = { 0 };
cpyParm.srcPtr = d_data;
cpyParm.dstPtr = make_cudaPitchedPtr((void*)h_data, sizeof(float) * width, width, height);
cpyParm.extent = extent;
cpyParm.kind = cudaMemcpyDeviceToHost;
cudaMemcpy3D(&cpyParm);
for (int i = 0; i < width*height*depth; i++)
{
printf("\\t%f", h_data[i]);
if ((i + 1) % width == 0)
printf("\\n");
if ((i + 1) % (width*height) == 0)
printf("\\n");
}
free(h_data);
cudaFree(d_data.ptr);
getchar();
return 0;
}
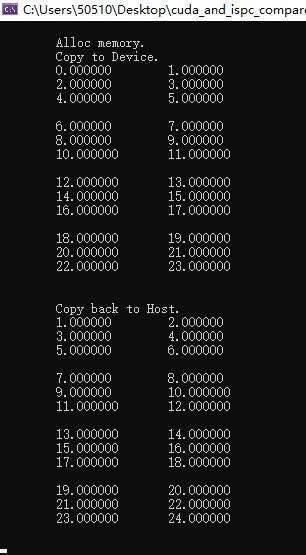
结果如下:
(3)异步传输:cudaMemcpyAsync / cudaMemcpy2DAsync / cudaMemcpy3DAsync
我们知道传输是走PCIe总线的,计算和PCIe总线里的数据流通完全独立,那么某些情况下,我们可以让计算和传输异步进行,而不是等数据传输完再做计算。
举个例子:我必须一次传入两张图像,做处理运算。常规操作是使用cudaMemcpy或者cudaMemcpy2D把两张图像都传输到显存,再启动kernel运算。传输和运算是串行的,运算必须等待传输完成。
而cudaMemcpyAsync / cudaMemcpy2DAsync / cudaMemcpy3DAsync 可以让传输和运算之间异步并行。上面的例子,如果用cudaMemcpyAsync或cudaMemcpy2DAsync,可以先传输第一张影像到显存,然后启动第一张影像的运算kernel,同时启动第二张影像的传输,此时第一张影像的运算和第二张影像的传输就是异步进行的,互相独立,便可隐藏掉第二张影像的传输耗时。

三个异步传输接口如下:
__host__ __device__ cudaError_t cudaMemsetAsync ( void* devPtr, int value, size_t count, cudaStream_t stream = 0 )
__host__ __device__ cudaError_t cudaMemcpy2DAsync ( void* dst, size_t dpitch, const void* src, size_t spitch, size_t width, size_t height, cudaMemcpyKind kind, cudaStream_t stream = 0 )
__host__ __device__ cudaError_t cudaMemcpy3DAsync ( const cudaMemcpy3DParms* p, cudaStream_t stream = 0 )
异步传输是非常实用的,当你一次处理多个数据时,可以考虑是否可以用异步传输来隐藏一部分传输耗时。
(4)锁页内存(Page-locked)
锁页内存是在主机端上的内存。主机端常规方式分配的内存(用new、malloc等方式)都是可分页(pageable)的,操作系统可以将可分页内存和虚拟内存(硬盘上的一块空间)相互交换,以获得比实际内存容量更大的内存使用。
可分页内存在分配后是可能被操作系统移动的,GPU端无法获知操作系统是否正在移动对可分页内存,所以不可让GPU端直接访问。实际的情况是,当从可分页内存传输数据到设备内存时,CUDA驱动程序首先分配临时页面锁定的主机内存,将可分页内存复制到页面锁定内存中 [copy 1],然后再从页面锁定内存传输到设备内存 [copy 2]。显然,这里面有两次传输。
所以我们能否直接分配页面锁定的内存?让GPU端直接访问,让传输只有一次!
答案是肯定的,我们可以在主机端分配锁页内存。锁页内存是主机端一块固定的物理内存,它不能被操作系统移动,不参与虚拟内存相关的交换操作。简而言之,分配之后,地址就固定了,被释放之前不会再变化。
GPU知道锁页内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,传输仅一次,效率更高。
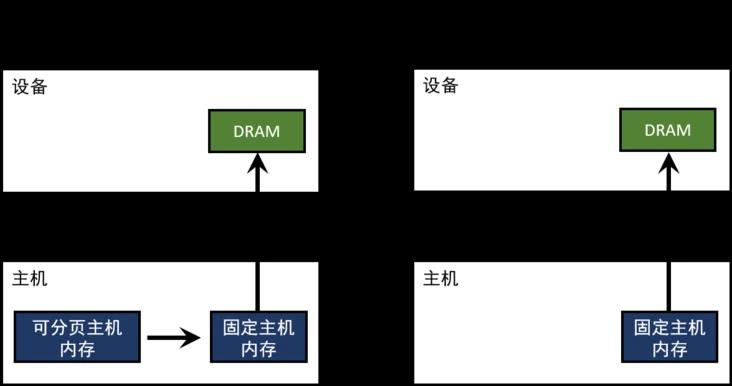
CUDA提供两种方式在主机端分配锁页内存
1. cudaMallocHost
__host__ cudaError_t cudaMallocHost ( void** ptr, size_t size )
2. cudaHostAlloc
pHost为分配的锁页内存地址,size为分配的字节数,flags为内存分配类型,取值如下:
-
cudaHostAllocDefault 默认值,等同于cudaMallocHost。
-
cudaHostAllocPortable
分配所有GPU都可使用的锁页内存 -
cudaHostAllocMapped。
此标志下分配的锁页内存可实现零拷贝功能,主机端和设备端各维护一个地址,通过 地址直接访问该块内存,无需传输。 -
cudaHostAllocWriteCombined 将分配的锁页内存声明为write-combined写联合内存,此类内存不使用L1和L2cache,所以程序的其它部分就有更多的缓存可用。此外,write-combined内存通过PCIe传输数据时不会被监视,能够获得更高的传输速度。因为没有使用L1、L2cache,所以主机读取write-combined内存很慢,write-combined适用于主机端写入、设备端读取的锁页内存。
分配的锁页内存必须使用cudaFreeHost接口释放。
对于一个已存在的可分页内存,可使用cudaHostRegister() 函数将其注册为锁页内存:
__host__ cudaError_t cudaHostRegister ( void* ptr, size_t size, unsigned int flags )
flags和上面一致。
锁页内存的缺点是分配空间过多可能会降低主机系统的性能,因为它减少了用于存储虚拟内存数据的可分页内存的数量。对于图像这类小内存应用还是比较合适的。
(5)零拷贝内存(Zero-Copy)
通常来说,设备端无法直接访问主机内存,但有一个例外:零拷贝内存!顾名思义,零拷贝内存是无需拷贝就可以在主机端和设备端直接访问的内存。
零拷贝具有如下优势:
- 当设备内存不足时可以利用主机内存
- 避免主机和设备间的显式数据传输
**准确来说,零拷贝并不是无需拷贝,而是无需显式拷贝。**使用零拷贝内存时不需要cudaMemcpy之类的显式拷贝操作,直接通过指针取值,所以对调用者来说似乎是没有拷贝操作。但实际上是在引用内存中某个值时隐式走PCIe总线拷贝,这样的方式有几个优点:
- 无需所有数据一次性显式拷贝到设备端,而是引用某个数据时即时隐式拷贝
- 隐式拷贝是异步的,可以和计算并行,隐藏内存传输延时
零拷贝内存是一块主机端和设备端共享的内存区域,是锁页内存,使用cudaHostAlloc接口分配。上一小结已经介绍了零拷贝内存的分配方法。分配标志是cudaHostAllocMapped。
对于零拷贝内存,设备端和主机端分别有一个地址,主机端分配时即可获取,设备端通过函数cudaHostGetDevicePointer函数获取地址。
__host__ cudaError_t cudaHostGetDevicePointer ( void** pDevice, void* pHost, unsigned int flags )
该函数返回一个在设备端的指针pDevice,该指针可以在设备端被引用以访问映射得到的主机端锁页内存。如果设备端不支持零拷贝方式(主机内存映射),则返回失败。可以使用接口cudaGetDeviceProperties来检查设备是否支持主机内存映射:
struct cudaDeviceProp device_prop
cudaGetDeviceProperties(&device_prop,device_num);
zero_copy_supported=device_prop.canMapHostMemory;
如上所述,零拷贝不是无需拷贝,而是一种隐式异步即时拷贝策略,每次隐式拷贝还是要走PCIe总线,所以频繁的对零拷贝内存进行读写,性能也会显著降低。
以下几种情况,可建议使用零拷贝内存:
- 在一大块主机内存中你只需要使用少量数据
- 你不会频繁的对这块内存进行重复访问,频繁的重复访问建议在设备端分配内存显式拷贝。最合适的情况,该内存的数据你都只需要访问一次
- 你需要比显存容量大的内存,或许你可以通过即时交换来获得比显存更大的内存使用,但是零拷贝内存也是一个可选思路
核心代码使用:
// allocate the memory on the CPU
cudaHostAlloc((void**) &a, size * sizeof(float),
cudaHostAllocWriteCombined | cudaHostAllocMapped);
cudaHostAlloc((void**) &b, size * sizeof(float),
cudaHostAllocWriteCombined | cudaHostAllocMapped);
cudaHostAlloc((void**) &partial_c, blocksPerGrid * sizeof(float),
cudaHostAllocMapped);
// find out the GPU pointers
cudaHostGetDevicePointer(&dev_a, a, 0);
cudaHostGetDevicePointer(&dev_b, b, 0);
cudaHostGetDevicePointer(&dev_partial_c, partial_c, 0);
(6)CUDA流的使用
CUDA流在加速应用程序方面起着重要的作用。CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,如核函数启动,内存复制等。将这些操作添加到流的顺序也就是他们的执行顺序。你可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。
1) 首先,选择一个支持设备重叠功能的设备。支持设备重叠功能的GPU能够在执行一个CUDA C/C++核函数的同时,还能在设备与主机之间执行复制操作。
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
if (!prop.deviceOverlap)
{
printf("Device will not handle overlaps, so no speed up from streams.\\n");
return 0;
}
2) 接下来,创建在应用程序中使用的流:
cudaStream_t stream;
cudaStreamCreate(&stream);
3) 然后是数据分配操作。注意,程序将使用主机上的固定内存,即调用cudaHostAlloc()来执行内存分配:
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
cudaError_t cudaStatus;
cudaStatus = cudaMalloc((void **)&dev_a, N * sizeof(int));
if (cudaStatus != cudaSuccess)
{
printf("cudaMalloc dev_a failed!\\n");
}
cudaStatus = cudaHostAlloc((void **)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
if (cudaStatus != cudaSuccess)
{
printf("cudaHostAlloc host_a failed!\\n");
}
4) 在执行核函数时,首先我们不会将输入缓冲区整体都复制到GPU,而是将输入缓冲区划分为更小的块,并在每个块上执行一个包含三个步骤(复制到GPU–运行核函数–复制回主机)的过程。需要这种方法的一种情形是:GPU的内存远小于主机内存,由于整个缓冲区无法一次性填充到GPU,因此需要分块进行计算:
for (int i = 0; i < FULL_DATA_SIZE; i += N)
{
cudaStatus = cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync a failed!\\n");
}
cudaStatus = cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync b failed!\\n");
}
kernel << <N / GPUBLOCKNUM, GPUTHREADNUM, 0, stream >> >(dev_a, dev_b, dev_c);
cudaStatus = cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if 以上是关于CUDA程序优化之数据传输的主要内容,如果未能解决你的问题,请参考以下文章