姿态估计 | 人体骨骼关键点检测综述(2016-2020)
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了姿态估计 | 人体骨骼关键点检测综述(2016-2020)相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :作者丨七酱@知乎
来源丨https://zhuanlan.zhihu.com/p/69042249
目录
一、前言
二、相关数据集
三、Ground Truth的构建
四、单人2D关键点检测的发展(2016-2019)
五、多人2D关键点检测的算法(Top-Down和Bottom-Up)
六、3D关键点检测的算法
七、2020CVPR姿态估计相关文章更新
八、技巧通用类文章(先挖坑)
一、前言
人体骨骼关键点检测是诸多计算机视觉任务的基础,例如动作分类、行为识别以及无人驾驶等。2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引到了众多研究者的注意。深度学习开始迎来超级发展时期,人体骨骼关键点检测效果也不断提升。
由于人体具有柔韧性,会出现各种姿态,人体任何部位的变化都会产生新的姿态,同时关键点的可见性受穿着、视角等影响非常大,而且还面临着遮挡、光照、雾等环境的影响,使得人体骨骼关键点检测成为计算机视觉领域中一个极具挑战性的课题。本文主要介绍单人2D人体骨骼关键点的近年来的相关算法,以及最新的多人2D人体骨骼关键点算法和3D人体骨骼关键点算法。
二、相关数据集
LSP(Leeds Sports Pose Dataset):单人人体关键点检测数据集,关键点个数为14,样本数2K,在目前的研究中作为第二数据集使用。
FLIC(Frames Labeled In Cinema):单人人体关键点检测数据集,关键点个数为9,样本数2W,在目前的研究中作为第二数据集使用。
MPII(MPII Human Pose Dataset):单人/多人人体关键点检测数据集,关键点个数为16,样本数25K,是单人人体关键点检测的主要数据集。
MSCOCO:多人人体关键点检测数据集,关键点个数为17,样本数多于30W,多人关键点检测的主要数据集,主流数据集;
AI Challenger:多人人体关键点检测数据集,关键点个数为14,样本数约38W,竞赛数据集;
human3.6M:是3D人体姿势估计的最大数据集,由360万个姿势和相应的视频帧组成,这些视频帧包含11位演员从4个摄像机视角执行15项日常活动的过程。数据集庞大将近100G。(很多人好像下载不了,有人想要的话,网盘分享给各位)
PoseTrack:最新的关于人体骨骼关键点的数据集,多人人体关键点跟踪数据集,包含单帧关键点检测、多帧关键点检测、多人关键点跟踪三个人物,多于500个视频序列,帧数超过20K,关键点个数为15。
三、Ground Truth的构建
在介绍多人关键点检测论文之前,首先介绍一下关键点回归的Ground Truth的构建问题,主要有两种思路,Coordinate和Heatmap,Coordinate即直接将关键点坐标作为最后网络需要回归的目标,这种情况下可以直接得到每个坐标点的直接位置信息;Heatmap即将每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率,比较自然的是,距离关键点位置越近的像素点的概率越接近1,距离关键点越远的像素点的概率越接近0,具体可以通过相应函数进行模拟,如Gaussian等,如果同一个像素位置距离不同关键点的距离大小不同,即相对于不同关键点该位置的概率不一样,这时可以取Max或Average。对于两种Ground Truth的差别,Coordinate网络在本质上来说,需要回归的是每个关键点的一个相对于图片的offset,而长距离offset在实际学习过程中是很难回归的,误差较大,同时在训练中的过程,提供的监督信息较少,整个网络的收敛速度较慢;Heatmap网络直接回归出每一类关键点的概率,在一定程度上每一个点都提供了监督信息,网络能够较快的收敛,同时对每一个像素位置进行预测能够提高关键点的定位精度,在可视化方面,Heatmap也要优于Coordinate,除此之外,实践证明,Heatmap确实要远优于Coordinate。最后,对于Heatmap + Offsets的Ground Truth构建思路主要是Google在CVPR 2017上提出的,与单纯的Heatmap不同的是,Google的Heatmap指的是在距离目标关键点一定范围内的所有点的概率值都为1,在Heatmap之外,使用Offsets,即偏移量来表示距离目标关键点一定范围内的像素位置与目标关键点之间的关系。
1.Towards accurate multi-person pose estimation in the wild(cvpr2017)
第一阶段使用faster rcnn做detection,检测出图片中的多个人,并对bounding box进行image crop;第二阶段采用fully convolutional resnet对每一个bonding box中的人物预测dense heatmap和offset; 最后通过heatmap和offset的融合得到关键点的精确定位。

下面这篇文章也使用到了offset这个概念。
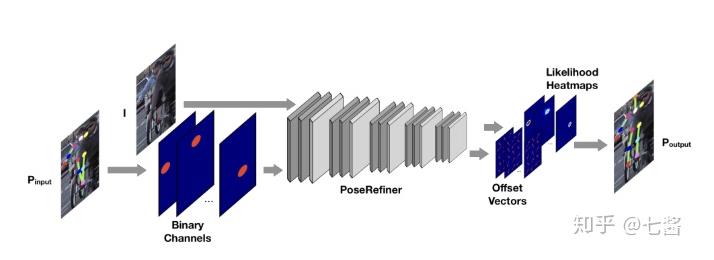
2.Learning to Refifine Human Pose Estimation(2018)
本文提出了训练一个新的模型, 来对某个pose estimation model产生的pose进行修正。文章引入了一种有效的后处理技术用于人体姿势估计中的身体关节细化任务。由于其前馈架构,简单且端到端的可训练,高效的。提出了一个培训数据增强方案纠错,使网络能够识别错误的身体关节预测和学习方法改进它们。
四、单人关键点检测的发展(2016-2019)
废话一下,2019开始专门做单人2d关键点的论文也太少了吧,很多文章都是做2d多人或者3d,然后把mpll的数据集的结果在文章后面贴一贴,这个数据集可能要到头了,建议萌新们要发文章直接做2d多人或者3d。入门练手就随意啦~
首先看下单人姿态估计数据集MPII(MPII Human Pose Dataset)官方列出的榜单:http://human-pose.mpi-inf.mpg.de/#results
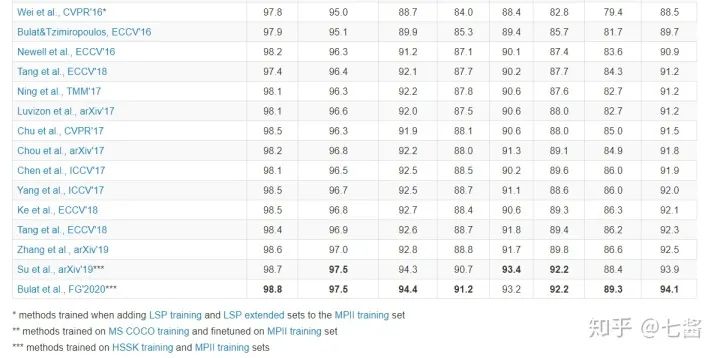
截图时间2020/07/27,最佳成绩已经达到94.1%。这篇结果是加了外源数据集的......大部分模型在mpll存在过拟合现象。
下面由单人关键点检测的经典论文开场吧。
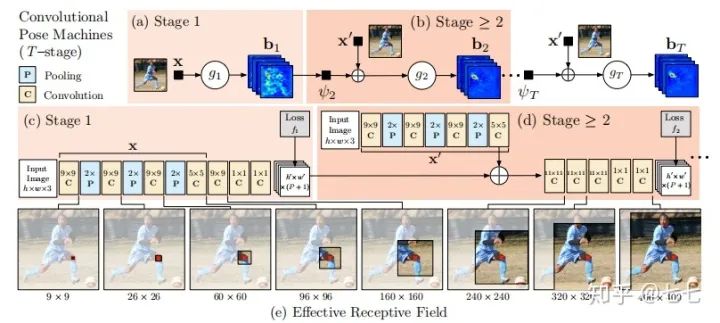
1.Convolutional Pose Machines(2016)
本论文将深度学习应用于人体姿态分析,同时用卷积图层表达纹理信息和空间信息。在2016年的MPII榜单中名列前茅。主要网络结构分为多个stage,各个阶段都有监督训练,避免过深网络难以优化的问题。通过改变卷积核大小来得到多个尺度输入的特征和响应,既能确保精度,又考虑了各个部件之间的远距离关系。其中第一个stage会产生初步的关键点的检测效果,接下来的几个stage均以前一个stage的预测输出和从原图提取的特征作为输入,进一步提高关键点的检测效果。
2.Learning Feature Pyramids for Human Pose Estimation (ICCV2017)
本文主要关注人体部件中的尺度问题,这种尺度变化主要发生在相机拍摄视角变化,设计了 Pyramid Residual Module (PRMs) 来增强 CNN 网络对尺度信息的提取能力。同时发现DCNNs多输入或者多输出层的初始化问题,以及发现在一些场景中激活变化累积是由identity mapping造成的, 对于这两个问题作者分别提出解决的方法。

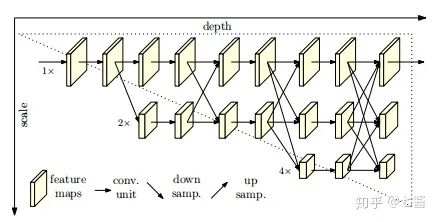
3.Stacked Hourglass Networks for Human Pose Estimation(2017)
Hourglass模块设计的初衷就是为了捕捉每个尺度下的信息,因为捕捉像脸,手这些部分的时候需要局部的特征,而最后对人体姿态进行预测的时候又需要整体的信息。为了捕获图片在多个尺度下的特征,通常的做法是使用多个pipeline分别单独处理不同尺度下的信息,然后再网络的后面部分再组合这些特征,而作者使用的方法就是用带有skip layers的单个pipeline来保存每个尺度下的空间信息。
在Hourglass模块中,卷积和max pooling被用来将特征降到一个很低的分辨率,在每一个max pooling步骤中,网络产生分支并在原来提前池化的分辨率下使用更多的卷积,当到达最低的分辨率的时候,网络开始upsample并结合不同尺度下的特征。这里upsample(上采样)采用的方法是最邻近插值,之后再将两个特征集按元素位置相加。当到达输出分辨率的时候,再接两个1×1的卷积层来进行最后的预测,网络的输出是一组heatmap,对于给定的heatmap,网络预测在每个像素处存在关节的概率。

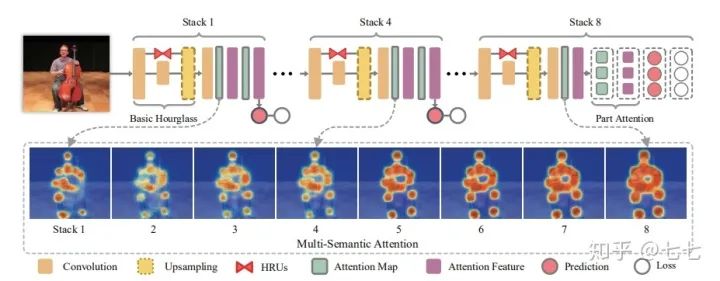
4.Multi-Context Attention for Human Pose Estimation(2018)
这篇文章整合多内容信息注意力机制(multi-context attention mechanism)到CNN网络,得到人体姿态估计 end-to-end 框架.采用堆积沙漏网络(stacked hourglass networks) 生成不同分辨率特征的注意力图(attention maps),不同分辨率特征对应着不同的语义.并同时结合了整体注意力模型和肢体部分注意力模型,整体注意力模型针对的是整体人体的全局一致性,部分注意力模型针对不同身体部分的详细描述. 因此,能够处理从局部显著区域到全局语义空间的不同粒度内容.另外,设计了新颖的沙漏残差单元(Hourglass Residual Units, HRUs),增加网络的接受野. HRUs 扩展了带分支的残差单元,分支的 filters 具有较大接受野;利用 HRUs 可以学习得到不同尺度的特征.
5.A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation(2018)
本文提出了三种新技术。为人类姿势巧妙地利用不同级别的特征进行估计。首先,初始化(IOI)块是旨在强调低级特征。其次,根据人体关节信息提出了注意机制来调整关节的重要性。第三,提出了一种级联网络来顺序定位关节强制从独立部件的关节传递消息像头部和躯干到手腕或脚踝等远程关节。

6.Deeply Learned Compositional Models for Human Pose Estimation(2018ECCV)
这篇文章利用深度神经网络来学习人体的组成。是具有分层组成架构和自下而上/自上而下的推理阶段的新型网络。

7.Human Pose Estimation with Spatial Contextual Information(2019)
目前大多数网络以多阶段的方式进行训练并加以优化精细。在这个出发点上,作者提出了两个简单但有效的模块,即Cascade Prediction Fusion(CPF)网络用来预测关键点和Pose Graph Neural Network(PGNN), 用来对上级预测的关键点进行修正。
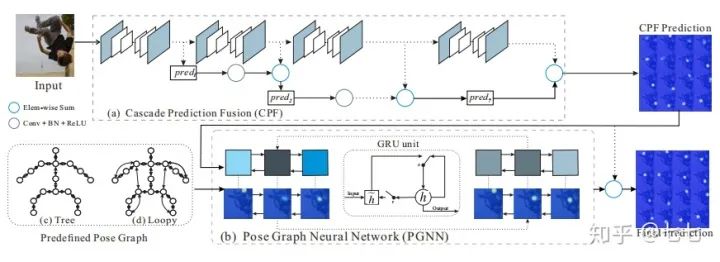
8.Cascade Feature Aggregation for Human Pose Estimation(2019)
这篇文章是2019年mpll数据集结果达到93.3%那篇,相比其他论文,这篇文章达到这么高的评分,主要有三点,一是,作者把stage2到stageN的heatmap的平均值作为最后输出;二是作者通过实验得出stage1把resnet101作为backbone,后面的stage采用resnet50作为backbone效果最佳;三是作者引入了AI Challenger的数据集来扩充训练数据。

9.Toward fast and accurate human pose estimation via soft-gated skip connections(2020)
这篇文章是2020年mpll数据集结果达到94.1%那篇。

五、多人关键点检测
多人关键点检测分自上而下和自下而上两种方法:
自上而下(Top-Down)的人体骨骼关键点检测算法主要包含两个部分,目标检测和单人人体骨骼关键点检测,对于目标检测算法,这里不再进行描述,而对于关键点检测算法,首先需要注意的是关键点局部信息的区分性很弱,即背景中很容易会出现同样的局部区域造成混淆,所以需要考虑较大的感受野区域;其次人体不同关键点的检测的难易程度是不一样的,对于腰部、腿部这类关键点的检测要明显难于头部附近关键点的检测,所以不同的关键点可能需要区别对待;最后自上而下的人体关键点定位依赖于检测算法的提出的Proposals,会出现检测不准和重复检测等现象,大部分相关论文都是基于这三个特征去进行相关改进。
自下而上(Bottom-Up)的人体骨骼关键点检测算法主要包含两个部分,关键点检测和关键点聚类,其中关键点检测和单人的关键点检测方法上是差不多的,区别在于这里的关键点检测需要将图片中所有类别的所有关键点全部检测出来,然后对这些关键点进行聚类处理,将不同人的不同关键点连接在一块,从而聚类产生不同的个体。而这方面的论文主要侧重于对关键点聚类方法的探索,即如何去构建不同关键点之间的关系。
Part1:多人2d关键点检测的算法(自上而下)
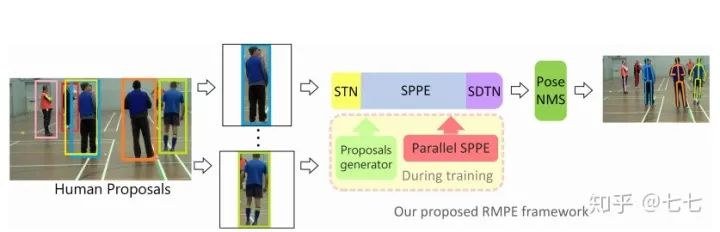
1.RMPE: Regional Multi-Person Pose Estimation(2018)
本论文主要考虑的是自上而下的关键点检测算法在目标检测产生Proposals的过程中,可能会出现检测框定位误差、对同一个物体重复检测等问题。检测框定位误差,会出现裁剪出来的区域没有包含整个人活着目标人体在框内的比例较小,造成接下来的单人人体骨骼关键点检测错误;对同一个物体重复检测,虽然目标人体是一样的,但是由于裁剪区域的差异可能会造成对同一个人会生成不同的关键点定位结果。本文提出了一种方法来解决目标检测产生的Proposals所存在的问题,即通过空间变换网络将同一个人体的产生的不同裁剪区 (Proposals)都变换到一个较好的结果,如人体在裁剪区域的正中央,这样就不会产生对于一个人体的产生的不同Proposals有不同关键点检测效果。
2.Cascaded Pyramid Network for Multi-Person Pose Estimation(cpn)(2018)
这篇文章是由Face++团队发表的COCO 17关键点的冠军方案,本论文主要关注的是不同类别关键点的检测难度是不一样的,整个结构的思路是先检测比较简单的关键点、然后检测较难的关键点、最后检测更难的或不可见的关键点。分为两个stage,GlobalNet和RefineNet其中GlobalNet主要负责检测容易检测和较难检测的关键点,对于较难关键点的检测,主要体现在网络的较深层,通过进一步更高层的语义信息来解决较难检测的关键点问题;RefineNet主要解决更难或者不可见关键点的检测,这里对关键点进行难易程度进行界定主要体现在关键点的训练损失上,使用了常见的Hard Negative Mining策略,在训练时取损失较大的top-K个关键点计算损失,然后进行梯度更新,不考虑损失较小的关键点。

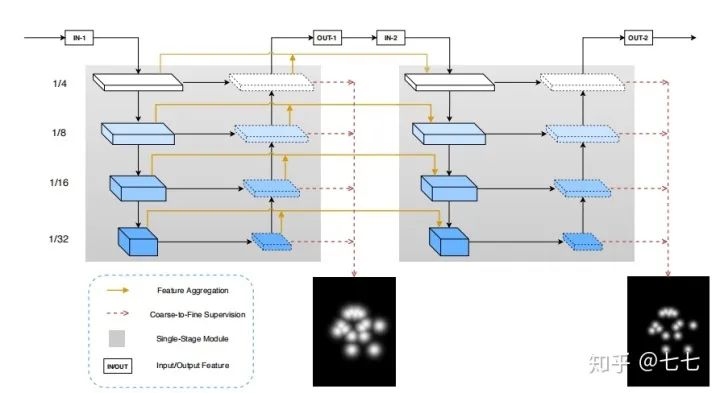
3.Rethinking on Multi-Stage Networks for Human Pose Estimation(2019)
时隔一年,Face++团队又拿下了COCO 18关键点检测冠军。提出了多阶段姿态估计网络(MSPN)有三个新的技术。首先,当前多阶段方法中的单级模块远非最优。例如,沙漏在所有块中使用相等宽度的通道用于向下和向下提取。这种设计与当前网络架构设计(ResNet)不一致。作者发现采用现有良好的网络结构进行下采样路径和简单的上采样路径要好很多。其次,由于重复的向下和向上采样步骤,信息更容易丢失,优化变得更加困难。作者建议在不同阶段汇总特征以加强信息流动并减轻培训的难度。最后,观察姿势定位精度逐渐提高。在多阶段,作者采取粗到细的多监督方式。
4.Spatial Shortcut Network for Human Pose Estimation(2019)
现有的基于姿态估计的方式,是通过逐像素分类实现的,这种方式是考虑不到大范围的空间信息的。举例来说:由于肘关节的外观与膝关节非常相似,对于一个感受野仅能覆盖肘关节本身的小特征提取器,很难将两者区分开来。但如果感受野能同时看到附近的手腕或肩膀,那么将其归类为肘部就容易得多。在涉及姿态估计的方法中,需要抑制非主要人体部位的检测。对卷积网络而言,只要将网络变的更深,或者增大卷积核,就能够促进空间信息流动,我们就可以增加最终特征的感受野。感受野增加了,上述提到的问题能够被较好的解决。然而不论是大卷积核还是深网络,这对计算和训练都带来了较大的挑战。为了空间信息能够低成本的流动,本文提出了一种针对于姿态估计任务的空间连接网络,使信息在空间上的流动更容易。本文提出的网络为spatial shortcut network (SSN)。该网络将特征映射移动和注意机制结合在一个称为特征移动模块feature shifting module(FSM)中。该模块在参数数量和计算成本上都与普通卷积层一样轻量,并可以插入到网络的任何部分来补充空间信息。

5.Deep High-Resolution Representation Learning for Human Pose Estimation (2019CVPR)
HRNet的体系结构。它由并行的高到低分辨率子网组成,并在多分辨率子网之间进行重复的信息交换(多尺度融合)。即模型是通过在高分辨率特征图主网络中逐渐并行的加入低分辨率特征图子网络,不同网络实现多尺度融合与特征提取实现的。
Part2:多人2d关键点检测的算法(自下而上)
1.OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE2019)
目前,已经有了许多关于检测的工作。许多的检测方式都是先想办法检测出身体的部位的关节点,然后再连接这些部位点得到人的姿态骨架。本文的工作差不多也是这个套路,但是为了快速的把点连到一起,提出了Part Affinity Fields这个概念来实现快速的关节点连接。

2.Single-Network Whole-Body Pose Estimation(ICCV2019)
本文提出了第一个二维全身姿态估计的单网络方法,它要求同时定位身体、脸、手和脚的关键点。方法在OpenPose的基础上有了很大的改进,OpenPose是目前为止唯一能够在速度和全局精度方面进行全身姿态估计的方法。与OpenPose不同的是,本文的方法不需要为每只手和每一张脸的候选对象运行一个额外的网络,这使得它在多人场景中运行速度大大提高。速度: 在测试时,无论检测到多少人,本文的单网络方法都提供了一个恒定的实时推断,大约比最先进的(OpenPose)的n人图像快n倍。准确性: 方法也比之前的OpenPose产生了更高的准确性,特别是在脸部和手部关键点检测上,更适用于遮挡、模糊和低分辨率的脸部和手部。

六、3D关键点检测的算法
可参见《3D Pose Estimation关键点检测的算法整理》
链接:https://zhuanlan.zhihu.com/p/164603050
七、2020CVPR姿态估计相关文章跟新
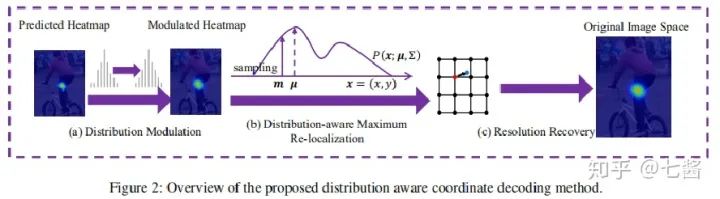
1.Distribution-Aware Coordinate Representation for Human Pose Estimation (2020cvpr)
在这项工作中,本文第一次系统地研究了在图像中用于人体姿势估计的坐标表示(包括编码和解码)在很大程度上被忽略但仍很重要的问题。不仅揭示了该问题的真正意义,而且还提出了一种新颖的关键点坐标表示(DARK),以进行更具判别性的模型训练和推理。作为现成的插件组件,现有的最新模型可以从此方法中无缝受益,而无需进行任何算法调整。
论文地址:https://arxiv.org/abs/1910.06278
代码:https://github.com/ilovepose/DarkPose
2.The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation(2020cvpr)
解决两个方面的问题:一个是在测试过程中,如果使用flip ensemble时,由翻转图像得到的结果和原图得到的结果并不对齐。另外一个是使用的编码解码(encoding-decoding)方法存在较大的统计误差。
论文地址:https://arxiv.org/abs/1911.07524

3.4D Association Graph for Realtime Multi-person Motion Capture Using Multiple Video Cameras(2020cvpr)
用图网络进行多人3d姿态估计并且具有实时性。
论文地址:https://arxiv.org/abs/2002.12625

4.VIBE: Video Inference for Human Body Pose and Shape Estimation(2020cvpr)
贡献:
1、改进了回归器model-based fitting-in-the-loop的训练方法,并应用到视频上;
2、使用了AMASS数据集来进行对抗训练,来使回归器产生更加逼真与合理的人体形态;
3、通过定量实验比较了3D人体形态估计方法的不同temporal结构;
4、通过使用运动捕捉数据的大型数据集来训练鉴别器,实现了SOTA的性能。
论文地址:https://arxiv.org/abs/1912.05656
代码:https://github.com/mkocabas/VIBE

发文章初衷是学习笔记,如有不对的地方还请多多指教~
参考资料:https://blog.csdn.net/sigai_csdn/article/details/80650411
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于姿态估计 | 人体骨骼关键点检测综述(2016-2020)的主要内容,如果未能解决你的问题,请参考以下文章
人体姿态估计(人体关键点检测)2D Pose训练代码和Android源码
人体姿态估计(人体关键点检测)2D Pose训练代码和Android源码