英文垃圾邮件分类机器学习篇——带你一次看个爽
Posted weixin_46570668
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英文垃圾邮件分类机器学习篇——带你一次看个爽相关的知识,希望对你有一定的参考价值。
英文垃圾邮件分类机器学习篇——带你一次看个爽——朴素贝叶斯、SVM、逻辑回归、随机森林、XGBoost
今天我们开始数据挖掘的一个经典分类项目,垃圾邮件分类,话不多说,我们直接开始吧。
首先我们导入一些用到的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
from sklearn import feature_extraction, model_selection, naive_bayes, metrics, svm
from IPython.display import Image
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import jieba
import re
from sklearn.model_selection import train_test_split
我们读入数据,一起来看一下数据是什么样子的
data = pd.read_csv('spam.csv', encoding = "ISO-8859-1")
data.head(n=10)
csv文件里总共有五列数据,第一列数据是标签ham就是正常邮件,spam就是垃圾邮件;第二列是邮件内容;之后的三列都是空的,是我们用不到的内容。
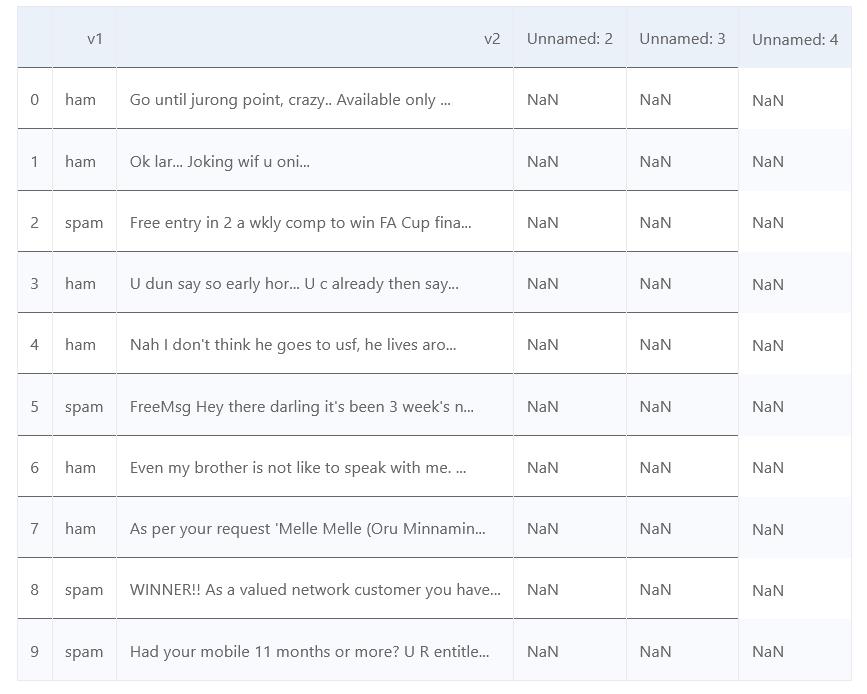
因为用不到后三列,所以将后三列去掉,只保留前两列。
# 去除无用数据,后3列是无用数据
data = data[['v1', 'v2']]
data.head()
 接下来,为了不影响特征提取,将标点符号都去掉
接下来,为了不影响特征提取,将标点符号都去掉
# 去除标点符号及两个以上的空格
data['v2'] = data['v2'].apply(lambda x:re.sub('[!@#$:).;,?&]', ' ', x.lower()))
data['v2'] = data['v2'].apply(lambda x:re.sub(' ', ' ', x))
data.head()
 将单词都转化为小写形式
将单词都转化为小写形式
# 单词转换为小写
data['v2'] = data['v2'].apply(lambda x:" ".join(x.lower() for x in x.split()))
data.head()
 使用词袋模型进行特征提取,也就是说一个词就是一个特征,去除停用词。
使用词袋模型进行特征提取,也就是说一个词就是一个特征,去除停用词。
#词袋模型处理
f = feature_extraction.text.CountVectorizer(stop_words = 'english')
X = f.fit_transform(data["v2"])
np.shape(X)
划分训练集和测试集,前5000为训练集,后面的为测试集
data["v1"]=data["v1"].map({'spam':1,'ham':0})
X_train=X[:5000]
X_test=X[5000:]
y_train=data['v1'][:5000]
y_test=data['v1'][5000:]
朴素贝叶斯
直接调用MultinomialNB进行训练
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import confusion_matrix
# 利用贝叶斯的方法
clf = MultinomialNB()
clf.fit(data_train_cnt, y_train)
score = clf.score(data_test_cnt,y_test)
print('朴素贝叶斯准确率:',score)
result_clf = clf.predict(data_test_cnt)
print('朴素贝叶斯混淆矩阵:','\\n',confusion_matrix(y_test, result_clf))
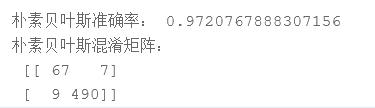
调整朴素贝叶斯的平滑参数
#多项式模型的贝叶斯 调整平滑参数 将每次模型的预测结果评价放入数组中
list_alpha = np.arange(1/100000, 20, 0.11)
score_train = np.zeros(len(list_alpha))
score_test = np.zeros(len(list_alpha))
recall_test = np.zeros(len(list_alpha))
precision_test= np.zeros(len(list_alpha))
count = 0
for alpha in list_alpha:
bayes = naive_bayes.MultinomialNB(alpha=alpha)
bayes.fit(X_train, y_train)
score_train[count] = bayes.score(X_train, y_train)
score_test[count]= bayes.score(X_test, y_test)
recall_test[count] = metrics.recall_score(y_test, bayes.predict(X_test))
precision_test[count] = metrics.precision_score(y_test, bayes.predict(X_test))
count = count + 1
大致看一下各个模型的效果如何
matrix = np.matrix(np.c_[list_alpha, score_train, score_test, recall_test, precision_test])
models = pd.DataFrame(data = matrix, columns =
['alpha', 'Train Accuracy', 'Test Accuracy', 'Test Recall', 'Test Precision'])
models.head(12)
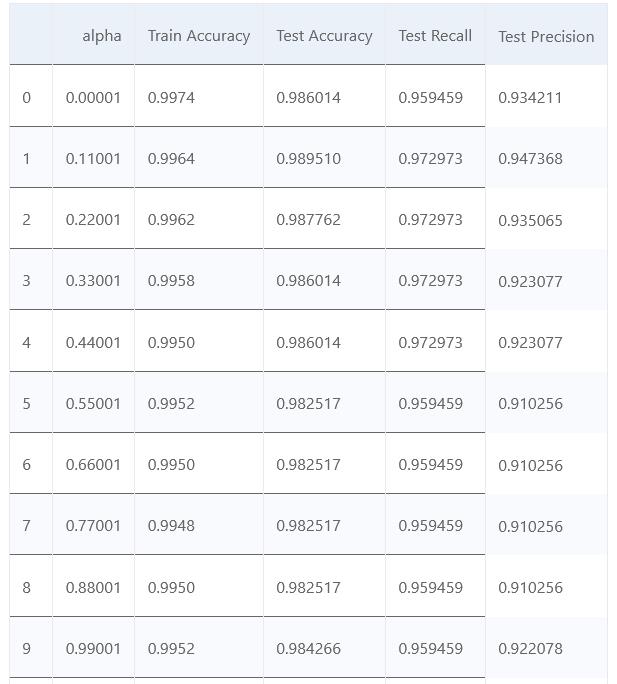
将准确率画一下图看看
plt.plot(models['alpha'], models['Test Accuracy'])
plt.show()
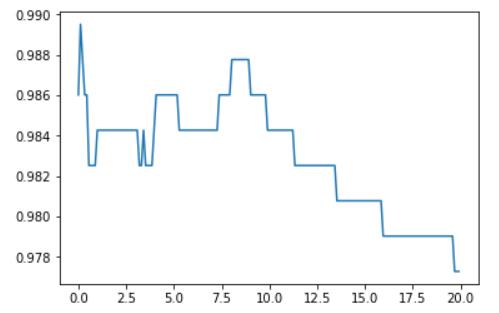
#找到训练集预测准确度最高的模型
best_index = models['Test Accuracy'].idxmax()
models.iloc[best_index, :]

SVM
直接调用sklearn.svm.LinearSVC
from sklearn.svm import LinearSVC
# 利用SVM的方法
svm = LinearSVC()
svm.fit(data_train_cnt, y_train)
score = svm.score(data_test_cnt,y_test)
print('SVM准确率:',score)
result_svm = svm.predict(data_test_cnt)
print('SVM混淆矩阵:','\\n',confusion_matrix(y_test, result_svm))
也是调整一下惩罚系数
list_C = np.arange(1, 10, 1) #100000
score_train = np.zeros(len(list_C))
score_test = np.zeros(len(list_C))
recall_test = np.zeros(len(list_C))
precision_test= np.zeros(len(list_C))
count = 0
for C in list_C:
svc = svm.SVC(C=C)
svc.fit(X_train, y_train)
score_train[count] = svc.score(X_train, y_train)
score_test[count]= svc.score(X_test, y_test)
recall_test[count] = metrics.recall_score(y_test, svc.predict(X_test))
precision_test[count] = metrics.precision_score(y_test, svc.predict(X_test))
count = count + 1
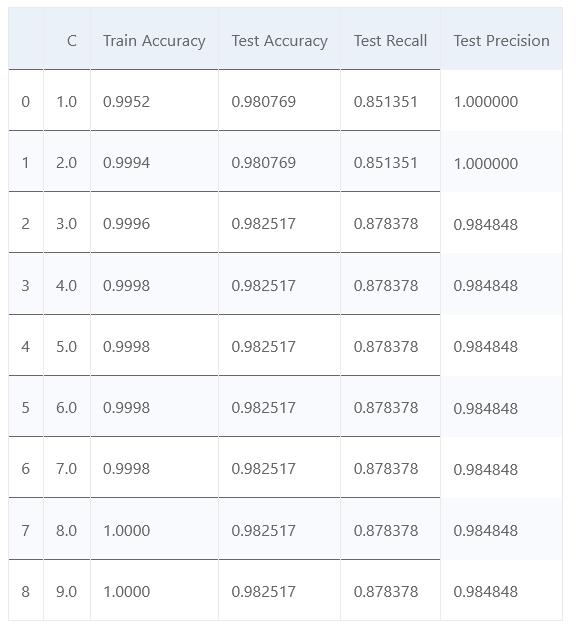
matrix = np.matrix(np.c_[list_C, score_train, score_test, recall_test, precision_test])
models = pd.DataFrame(data = matrix, columns =
['C', 'Train Accuracy', 'Test Accuracy', 'Test Recall', 'Test Precision'])
models.head(n=10)
matrix = np.matrix(np.c_[list_C, score_train, score_test, recall_test, precision_test])
models = pd.DataFrame(data = matrix, columns =
['C', 'Train Accuracy', 'Test Accuracy', 'Test Recall', 'Test Precision'])
models.head(n=10)
plt.plot(models['C'], models['Test Accuracy'])
plt.show()
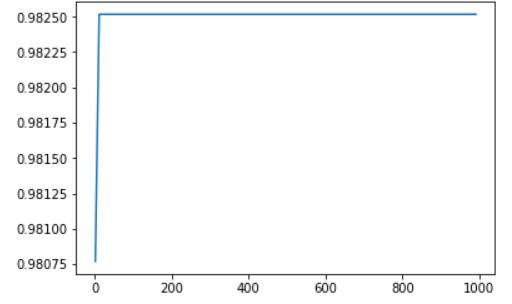
best_index = models['Test Accuracy'].idxmax()
models.iloc[best_index, :]

逻辑回归
from sklearn.linear_model import LogisticRegression
# 利用逻辑回归的方法
lr = LogisticRegression()
lr.fit(data_train_cnt, y_train)
score = lr.score(data_test_cnt,y_test)
print('逻辑回归准确率:',score)
result_lr = lr.predict(data_test_cnt)
print('逻辑回归混淆矩阵:','\\n',confusion_matrix(y_test, result_lr))

随机森林
from sklearn.ensemble import RandomForestClassifier
# 利用随机森林的方法
frc = RandomForestClassifier()
frc.fit(data_train_cnt, y_train)
score = frc.score(data_test_cnt,y_test)
print('随机森林准确率:',score)
result_frc = frc.predict(data_test_cnt)
print('随机森林混淆矩阵:','\\n',confusion_matrix(y_test, result_frc))

XGBoost
from xgboost import XGBClassifier
# 利用XGBoost的方法
xg = XGBClassifier()
xg.fit(data_train_cnt, y_train)
score = xg.score(data_test_cnt,y_test)
print('XGBoost准确率:',score)
result_xg = xg.predict(data_test_cnt)
print('XGBoost混淆矩阵:','\\n',confusion_matrix(y_test, result_xg))

完整的数据集和代码已经上传资源喽,欢迎大家来下载!
链接: https://download.csdn.net/download/weixin_46570668/19685853.
以上是关于英文垃圾邮件分类机器学习篇——带你一次看个爽的主要内容,如果未能解决你的问题,请参考以下文章
时序数据预测机器学习篇——带你一次看个爽——以JetRail高铁的乘客数量为例
时序数据预测机器学习篇——带你一次看个爽——以JetRail高铁的乘客数量为例