分布式一致性算法Raft
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式一致性算法Raft相关的知识,希望对你有一定的参考价值。

导语 | 对于很多工程人员来说,Paxos算法不容易理解和落地实现。因此斯坦福学者提出了一个更易理解和实现的共识算法Raft。本文主要介绍Raft的基本原理、算法流程以及和Paxos的区别。
一、Raft算法背景
在学术理论界,分布式一致性算法的代表还是Paxos。但是少数理解的人觉得很简单,尚未理解的觉得很难,大多数人还是一知半解。Paxos的可理解性和工程落地性的门槛很高。斯坦福学者也花了很多时间理解Paxos,于是他们又研究出Raft。
二、Raft算法基本原理
共识算法就是保证一个集群的多台机器协同工作,在遇到请求时,数据能够保持一致。即使遇到机器宕机,整个系统仍然能够对外保持服务的可用性。
Raft将共识问题分解三个子问题:
Leader election 领导选举:有且仅有一个leader节点,如果leader宕机,通过选举机制选出新的leader;
Log replication 日志复制:leader从客户端接收数据更新/删除请求,然后日志复制到follower节点,从而保证集群数据的一致性;
Safety 安全性:通过安全性原则来处理一些特殊case,保证Raft算法的完备性;
所以,Raft算法核心流程可以归纳为:
首先选出leader,leader节点负责接收外部的数据更新/删除请求;
然后日志复制到其他follower节点,同时通过安全性的准则来保证整个日志复制的一致性;
如果遇到leader故障,followers会重新发起选举出新的leader;
这里先介绍一下日志同步的概念:服务器接收客户的数据更新/删除请求,这些请求会落地为命令日志。只要输入状态机的日志命令相同,状态机的执行结果就相同。所以Raft的核心就是leader发出日志同步请求,follower接收并同步日志,最终保证整个集群的日志一致性。

1. Leader Election 领导选举
集群中每个节点只能处于Leader、Follower和Candidate三种状态的一种:
(1)follower从节点:
节点默认是follower;
如果刚刚开始或和leader通信超时,follower会发起选举,变成candidate,然后去竞选leader;
如果收到其他candidate的竞选投票请求,按照先来先得 & 每个任期只能投票一次的投票原则投票;
(2)candidate候选者:
follower发起选举后就变为candidate,会向其他节点拉选票。candidate的票会投给自己,所以不会向其他节点投票;
如果获得超过半数的投票,candidate变成leader,然后马上和其他节点通信,表明自己的leader的地位;
如果选举超时,重新发起选举;
如果遇到更高任期Term的leader的通信请求,转化为follower;
(3)leader主节点:
成为leader节点后,此时可以接受客户端的数据请求,负责日志同步;
如果遇到更高任期Term的candidate的通信请求,这说明candidate正在竞选leader,此时之前任期的leader转化为follower,且完成投票;
如果遇到更高任期Term的leader的通信请求,这说明已经选举成功新的leader,此时之前任期的leader转化为follower;
具体的节点状态转换参考下图:

Raft算法把时间轴划分为不同任期Term。每个任期Term都有自己的编号TermId,该编号全局唯一且单调递增。如下图,每个任务的开始都 Leader Election 领导选举。如果选举成功,则进入维持任务Term阶段,此时leader负责接收客户端请求并,负责复制日志。Leader和所有follower都保持通信,如果follower发现通信超时,TermId递增并发起新的选举。如果选举成功,则进入新的任期。如果选举失败,TermId递增,然后重新发起选举直到成功。
举个例子,参考下图,Term N选举成功,Term N+1和Term N+2选举失败,Term N+3重新选举成功。

具体的说,Leader在任期内会周期性向其他follower节点发送心跳来维持地位。follower如果发现心跳超时,就认为leader节点宕机或不存在。随机等待一定时间后,follower会发起选举,变成candidate,然后去竞选leader。选举结果有三种情况:
(1)获取超过半数投票,赢得选举:
当Candidate获得超过半数的投票时,代表自己赢得了选举,且转化为leader。此时,它会马上向其他节点发送请求,从而确认自己的leader地位,从而阻止新一轮的选举;
投票原则:当多个Candidate竞选Leader时
一个任期内,follower只会投票一次票,且投票先来显得;
Candidate存储的日志至少要和follower一样新(安全性准则),否则拒绝投票;
(2)投票未超过半数,选举失败:
当Candidate没有获得超过半数的投票时,说明多个Candidate竞争投票导致过于分散,或者出现了丢包现象。此时,认为当期任期选举失败,任期TermId+1,然后发起新一轮选举;
上述机制可能出现多个Candidate竞争投票,导致每个Candidate一直得不到超过半数的票,最终导致无限选举投票循环;
投票分散问题解决:Raft会给每个Candidate在固定时间内随机确认一个超时时间(一般为150-300ms)。这么做可以尽量避免新的一次选举出现多个Candidate竞争投票的现象;
(3)收到其他Leader通信请求:
如果Candidate收到其他声称自己是Leader的请求的时候,通过任期TermId来判断是否处理;
如果请求的任期TermId不小于Candidate当前任期TermId,那么Candidate会承认该Leader的合法地位并转化为Follower;
否则,拒绝这次请求,并继续保持Candidate;
简单地说,Leader Election 领导选举通过若干的投票原则,保证一次选举有且仅可能最多选出一个leader,从而解决了脑裂问题。
2. Log Replication 日志复制
选举leader成功后,整个集群就可以正常对外提供服务了。Leader接收所有客户端请求,然后转化为log复制命令,发送通知其他节点完成日志复制请求。每个日志复制请求包括状态机命令 & 任期号,同时还有前一个日志的任期号和日志索引。状态机命令表示客户端请求的数据操作指令,任期号表示leader的当前任期。
follower收到日志复制请求的处理流程:
(1)follower会使用前一个日志的任期号和日志索引来对比自己的数据:
如果相同,接收复制请求,回复ok;
否则回拒绝复制当前日志,回复error;
(2)leader收到拒绝复制的回复后,继续发送节点日志复制请求,不过这次会带上更前面的一个日志任期号和索引;
(3)如此循环往复,直到找到一个共同的任期号&日志索引。此时follower从这个索引值开始复制,最终和leader节点日志保持一致;
(4)日志复制过程中,Leader会无限重试直到成功。如果超过半数的节点复制日志成功,就可以任务当前数据请求达成了共识,即日志可以commite提交了;
综上,Log Replication 日志复制有两个特点:
(1)如果在不同日志中的两个条目有着相同索引和任期号,则所存储的命令是相同的,这点是由leader来保证的;
(2)如果在不同日志中的两个条目有着相同索引和任期号,则它们之间所有条目完全一样,这点是由日志复制的规则来保证的;
举个例子,最上面表示日志索引,这个是保证唯一性。每个方块代表指定任期内的数据操作,目前来看,LogIndex 1-4的日志已经完成同步,LogIndex 5的正在同步,LogIndex6还未开始同步。Raft 日志提交的过程有点类似两阶段原子提交协议2PC,不过和2PC的最大区别是,Raft要求超过一般节点同意即可commited,2PC要求所有节点同意才能commited。
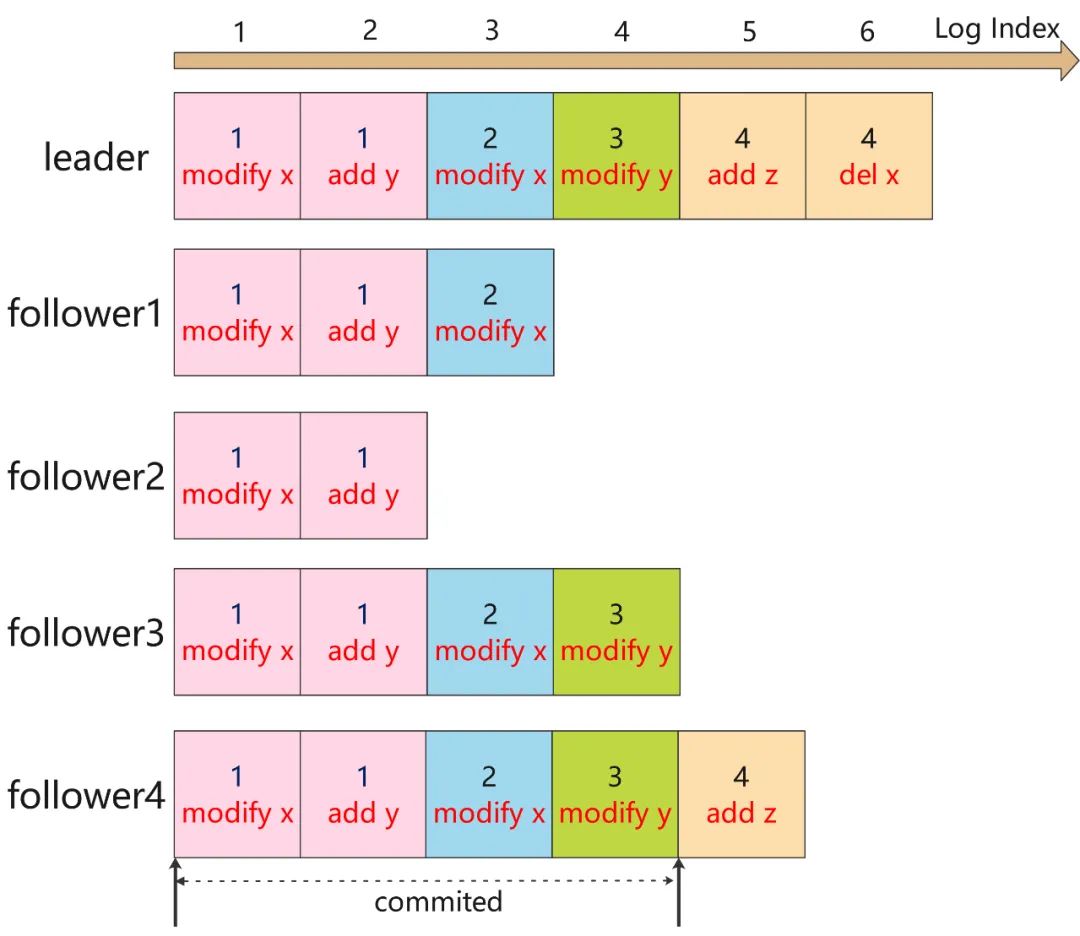
日志不一致问题:在正常情况下,leader和follower的日志复制能够保证整个集群的一致性,但是遇到leader崩溃的时候,leader和follower日志可能出现了不一致的状态,此时follower相比leader缺少部分日志。
为了解决数据不一致性,Raft算法规定follower强制复制leader节日的日志,即follower不一致日志都会被leader的日志覆盖,最终follower和leader保持一致。简单的说,从前向后寻找follower和leader第一个公共LogIndex的位置,然后从这个位置开始,follower强制复制leader的日志。但是这么多还有其他的安全性问题,所以需要引入Safety 安全性规则。
3. Safety 安全性
当前的Leader election 领导选举和Log replication 日志复制并不能保证Raft算法的安全性,在一些特殊情况下,可能导致数据不一致,所以需要引入下面安全性规则。
(1)Election Safety 选举安全性:避免脑裂问题
选举安全性要求一个任期Term内只能有一个leader,即不能出现脑裂现象,否者raft的日志复制原则很可能出现数据覆盖丢失的问题。Raft算法通过规定若干投票原则来解决这个问题:
一个任期内,follower只会投票一次票,且先来先得;
Candidate存储的日志至少要和follower一样新;
只有获得超过半数投票才有机会成为leader;
(2)Leader Append-Only 日志只能由leader添加修改
Raft算法规定,所有的数据请求都要交给leader节点处理,要求:
leader只能日志追加日志,不能覆盖日志;
只有leader的日志项才能被提交,follower不能接收写请求和提交日志;
只有已经提交的日志项,才能被应用到状态机中;
选举时限制新leader日志包含所有已提交日志项;
(3)Log Matching 日志匹配特性
这点主要是为了保证日志的唯一性,要求:
如果在不同日志中的两个条目有着相同索引和任期号,则所存储的命令是相同的;
如果在不同日志中的两个条目有着相同索引和任期号,则它们之间所有条目完全一样;
(4)Leader Completeness 选举完备性:leader必须具备最新提交日志
Raft规定:只有拥有最新提交日志的follower节点才有资格成为leader节点。具体做法:candidate竞选投票时会携带最新提交日志,follower会用自己的日志和candidate做比较。
如果follower的更新,那么拒绝这次投票;
否则根据前面的投票规则处理。这样就可以保证只有最新提交节点成为leader;
因为日志提交需要超过半数的节点同意,所以针对日志同步落后的follower(还未同步完全部日志,导致落后于其他节点)在竞选leader的时候,肯定拿不到超过半数的票,也只有那些完成同步的才有可能获取超过半数的票成为leader。
日志更新判断方式是比较日志项的term和index:
如果TermId不同,选择TermId最大的;
如果TermId相同,选择Index最大的;
下面举个例子来解释为什么需要这个原则,如下图,假如集群中follower4在LogIndex3 故障宕机,经过一段时间间,任期Term3的leader接收并提交了很多日志(LogIndex1-5已经提交,LogIndex6正在复制中)。然后follower4恢复正常,在没有和leader完成同步日志的情况下,如果leader突然宕机,此时开始领导选举。再假设在Term4 follower4当选leader。根据日志复制的规则,其他follower强制复制leader的日志,那么已经提交却没完成同步的日志将会被强制覆盖掉,这回导致已提交日志被覆盖。

(5)State Machine Safety 状态机安全性:确保当前任期日志提交
考虑到当前的日志复制规则:
当前follower节点强制复制leader节点;
假如以前Term日志复制超过半数节点,在面对当前任期日志的节点比较中,很明显当前任期节点更新,有资格成为leader;
上述两条就可能出现已有任期日志被覆盖的情况,这意味着已复制超过半数的以前任期日志被强制覆盖了,和前面提到的日志安全性矛盾。
所以,Raft对日志提交有额外安全机制:leader只能提交当前任期Term的日志,旧任期Term(以前的数据)只能通过当前任期Term的数据提交来间接完成提交。简单的说,日志提交有两个条件需要满足:
当前任期;
复制结点超过半数;
下面举个例子来解释为什么需要这个原则,如下图:

任期Term2:
follower1是leader,此时LogIndex3已经复制到follower2,且正在给follower3复制,此时follower突然宕机;
任期Term3:
leader选举。follower5发起投票,可以得到自己、follower3、follower4的票(3/5),最终成为leader;
在任期Term3内,提交接收客户请求并提交LogIndex3-5,但是暂时未复制到其他节点,然后宕机;
任期Term4:
leader选举,follower1发起选举,可以得到自己、follower2、follower3、follower4的票(4/5),最终成为leader;
此时follower1将LogIndex3复制到follower3,此时LogIndex3复制超过半数,接着在本地提交了LogIndex4,然后宕机;
任期Term4:
leader选举:follower5发起选举,可以得到自己、follower2、follower3、follower4的票(4/5),最终成为leader;
此时其他节点需要强制复制follower5的日志,那么follower1、follower2、follower3的日志被强制覆盖掉。即虽然LogIndex3被复制到了超过半数节点,但也有可能被覆盖掉;
如何解决这个问题呢?Raft在日志项提交上增加了限制:只有当前任期且复制超过半数的日志才可以提交。即只有LogIndex4提交后,LogIndex3才会被提交。
三、Paxos VS Raft
这个世界上只有一种一致性算法,那就是 Paxos。
Basic Paxos算法没有leader proposer角色,是一个纯粹的去中心化的分布式算法,但是它存在若干不足(只能单值共识 & 活锁 & 网络开销大)。所以才有了以leader proposer为核心的Multi Paxos算法(由一个去中心化的算法变为leader-based的算法)。Raft算法相当于Multi Paxos的进一步优化,主要通过增加两个限制:
(1)日志添加次序性:
Raft要求日志必须要串行连续添加的;
Multi Paxos可以并发添加日志,没有顺序性要求,所以日志可能存在空洞现象;
(2)选主限制:
Raft要求只有拥有最新日志的节点才有资格当选leader,因为日志是串行连续添加的,所以Raft能够根据日志确认最新节点;
在Multi Paxos算法中由于日志是并发添加的,所以无法确认最新日志的节点,所以Multi Paxos可以选择任意节点作为了leader proposer节点,成为leader节点后需要把其他日志补全;
下面是我个人的理解:
作为分布式算法,Raft的规则限制很多,但是每个规则都简单易懂,最重要的是leader-based的,整个程序是一个串行的流程,这使得更加容易理解和实现;
作为对比,Multi Paxos的限制就很少了,每个节点都可以成为leader,并发添加日志,这使得理解和落地就没那么简单;
不同业务场景下有着不同的述求,所以一致性算法选择Multi Paxos还是Raft看各自需求。
毕竟程序员更容易理解串行程序。
四、总结
Raft协议就是一种leader-based的共识算法,算法设计出发点就是可理解性以及工程的落地性,它在性能、可靠性、可用性方面是不输于Paxos的。
学习总结分布式一致性算法Paxos和Raft对我们理解、设计、实现、部署、测试分布式系统都大有益处,希望本文能与大家共同商榷。
作者简介
张辉,腾讯后台开发工程师,主要负责腾讯雾计算平台PCDN SDK相关的业务,毕业于南京大学计算机系。

以上是关于分布式一致性算法Raft的主要内容,如果未能解决你的问题,请参考以下文章