文献阅读20期:Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Posted RaZLeon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读20期:Transformer Transforms Salient Object Detection and Camouflaged Object Detection相关的知识,希望对你有一定的参考价值。
[ 文献阅读 ] Transformer Transforms Salient Object Detection and Camouflaged Object Detection [1]
表现SOTA!性能优于SCWS、JLDCF等网络,源自机器翻译的Transformer网络特别擅长在长序列中对远程依存关系进行建模。大量实验结果表明,Transformer网络可以转换显著性目标检测和伪装对象检测,从而为每个相关任务提供了新的基准。
1.Transformer Network
1.1.Transformer Network 总览
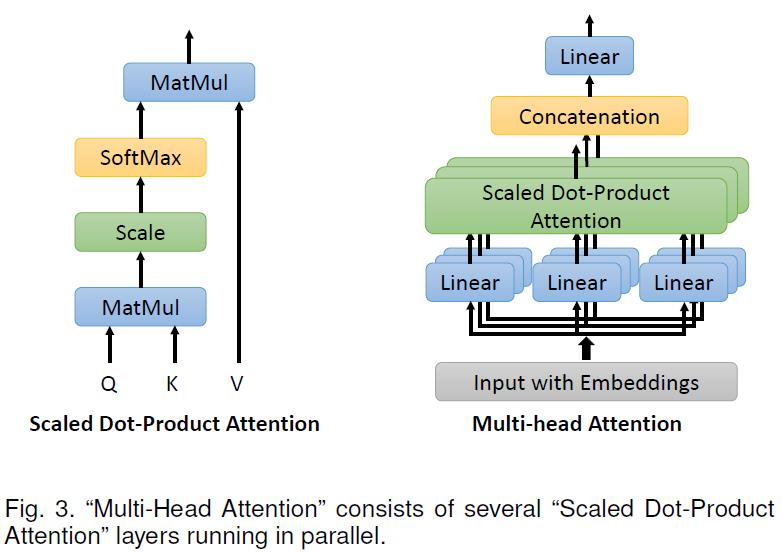
- 多头注意力机制:典型思想是自我注意,它捕捉输入序列中元素之间的长期依赖关系。自我注意机制旨在估计一个目标与给定序列中其他物体的相关性,并对序列中所有物体之间的相互作用进行建模。
- 假定有序列 X ∈ R n × d \\mathbf{X} \\in \\mathbb{R}^{n \\times d} X∈Rn×d,n为序列长度,d为embedding维度。则输入的向量首先会被转换为3个不同的向量:Query vector Q \\mathbf{Q} Q,Key vector K \\mathbf{K} K,Value vector V \\mathbf{V} V,这三个向量都有相同的维度d,并且相对应有三种可学习权重矩阵: W Q ∈ R n × d q , W K ∈ R n × d k \\mathbf{W}^{Q} \\in \\mathbb{R}^{n \\times d_{q}}, \\mathbf{W}^{K} \\in \\mathbb{R}^{n \\times d_{k}} WQ∈Rn×dq,WK∈Rn×dk and W V ∈ R n × d v \\mathbf{W}^{V} \\in \\mathbb{R}^{n \\times d_{v}} WV∈Rn×dv
- 基于以上,一个输入序列X可以转化为以下三个矩阵:
Q = X W Q , K = X W K , V = X W V (1) \\mathbf{Q}=\\mathbf{X} \\mathbf{W}^{Q}, \\mathbf{K}=\\mathbf{X} \\mathbf{W}^{K}, \\mathbf{V}=\\mathbf{X} \\mathbf{W}^{V}\\tag{1} Q=XWQ,K=XWK,V=XWV(1) - 基于上述三个权值矩阵,计算所有队列的点积。然后使用softmax算子将结果归一化为注意分数。最后,将每个值向量乘以注意力得分之和。这样,具有较大注意分数的向量从以下层接收额外的关注。标度点积自我注意的定义是:
Z = softmax ( Q K T d ) V (2) \\mathbf{Z}=\\operatorname{softmax}\\left(\\frac{\\mathbf{Q K}^{T}}{\\sqrt{d}}\\right) \\mathbf{V}\\tag{2} Z=softmax(dQKT)V(2) - 自我注意层的输出与输入顺序无关。为了解决输入向量位置信息缺失的问题,在输入向量上增加了一个附加的位置编码。有两种可选的编码形式,包括可学习参数和正弦/余弦函数编码。形式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d ) P E ( pos , 2 i + 1 ) = cos ( p o s 1000 0 2 i d ) (3) \\begin{aligned} \\mathbf{P E}(p o s, 2 i) &=\\sin \\left(\\frac{p o s}{10000^{\\frac{2 i}{d}}}\\right) \\\\ \\mathbf{P E}(\\operatorname{pos}, 2 i+1) &=\\cos \\left(\\frac{p o s}{10000^{\\frac{2 i}{d}}}\\right) \\end{aligned}\\tag{3} PE(pos,2i)PE(pos,2i+1)=sin(10000d2ipos)=cos(10000d2ipos)(3) - 多头注意力机制后来是对自注意力机制的一个扩充,如下图:
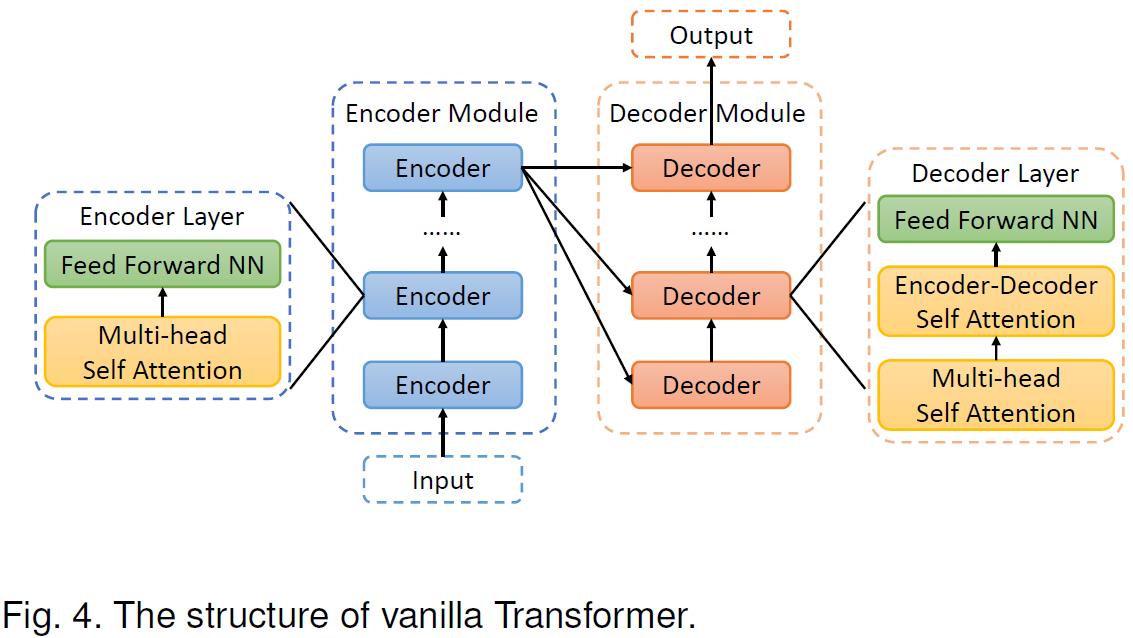
- Transformer 网络一般是用来做NLP自然语言处理的,但本文把它用来做目标检测。一般来说Transformer Network长下图这样:
- 如果将 H × W × 3 H \\times W \\times 3 H×W×3的图片打平成一维向量,这个向量的大小即 3 H W 3HW 3HW,这就会导致很大的计算复杂度,为了让计算复杂度维持在一个可以接受的水平,本文首先用ResNet-50将样本下采样为一个大小为 H 16 × W 16 × 3 \\frac{H}{16} \\times \\frac{W}{16} \\times 3 16H×16W×3的高级别特征映射,这样之后向量大小就变为 H W 256 \\frac{H W}{256} 256HW,让计算复杂度维持在一个可以接受的水平。
1.2.显著目标检测
- 视觉图像上的显著目标检测实际上是一种需要根据上下文进行推断的任务。而且被检测的目标应当和其背景很好地区分开来。如下图所示:

- 本文将训练集定义为: D = { x , y } i = 1 N D=\\{x, y\\}_{i=1}^{N} D={x,y}i=1N,其中x是RGB图片,y是ground truth或是基于弱监督的弱map或scribble
1.2.1.全监督模型
- 对于全监督模型,采用了加权结构感知损失,即加权01交叉熵损失和加权IOU损失之和,如下所示:
L full ( c , y ) = ω ∗ L c e ( c , y ) + L i o u ( c , y ) (4) \\mathcal{L}_{\\text {full }}(c, y)=\\omega * \\mathcal{L}_{c e}(c, y)+\\mathcal{L}_{i o u}(c, y)\\tag{4} Lfull (c,y)=ω∗Lce(c,y)+Liou(c,y)(4)
其中 ω \\omega ω是边缘感知权重: ω = 1 + 5 ∗ ∣ ( avg − pool ( y ) − y ) ∣ , L c e \\omega=1+5 *\\left|\\left(\\operatorname{avg}_{-} \\operatorname{pool}(y)-y\\right)\\right|, \\mathcal{L}_{c e} ω=1+5∗∣(avg−pool(y)−y)∣,Lce, L c e \\mathcal{L}_{c e} Lce是01交叉熵损失, L i o u \\mathcal{L}_{i o u} Liou定义如下:
L i o u = 1 − ω ∗ inter + 1 ω ∗ union − ω ∗ inter + 1 (5) \\mathcal{L}_{i o u}=1-\\frac{\\omega * \\text { inter }+1}{\\omega * \\text { union }-\\omega * \\text { inter }+1}\\tag{5} Liou=1−ω∗ union −ω∗ inter +1ω∗ inter +1(5)
其中inter = c ∗ y =c * y 以上是关于文献阅读20期:Transformer Transforms Salient Object Detection and Camouflaged Object Detection的主要内容,如果未能解决你的问题,请参考以下文章文献阅读20期:Transformer Transforms Salient Object Detection and Camouflaged Object Detection
文献阅读20期:Transformer Transforms Salient Object Detection and Camouflaged Object Detection
文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models
文献阅读:RoFormer: Enhanced Transformer with Rotary Position Embedding