什么是分布式锁?
Posted 苍山有雪,剑有霜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是分布式锁?相关的知识,希望对你有一定的参考价值。
什么是分布式锁?
在一些分布事场景下,为了保证数据的一致性,而分布式锁就是用来解决这个问题的。例如,当多台机器需要对同一个用户属性进行修改时,就会出现属性值跟预想的不一样的结果,如下图所示:
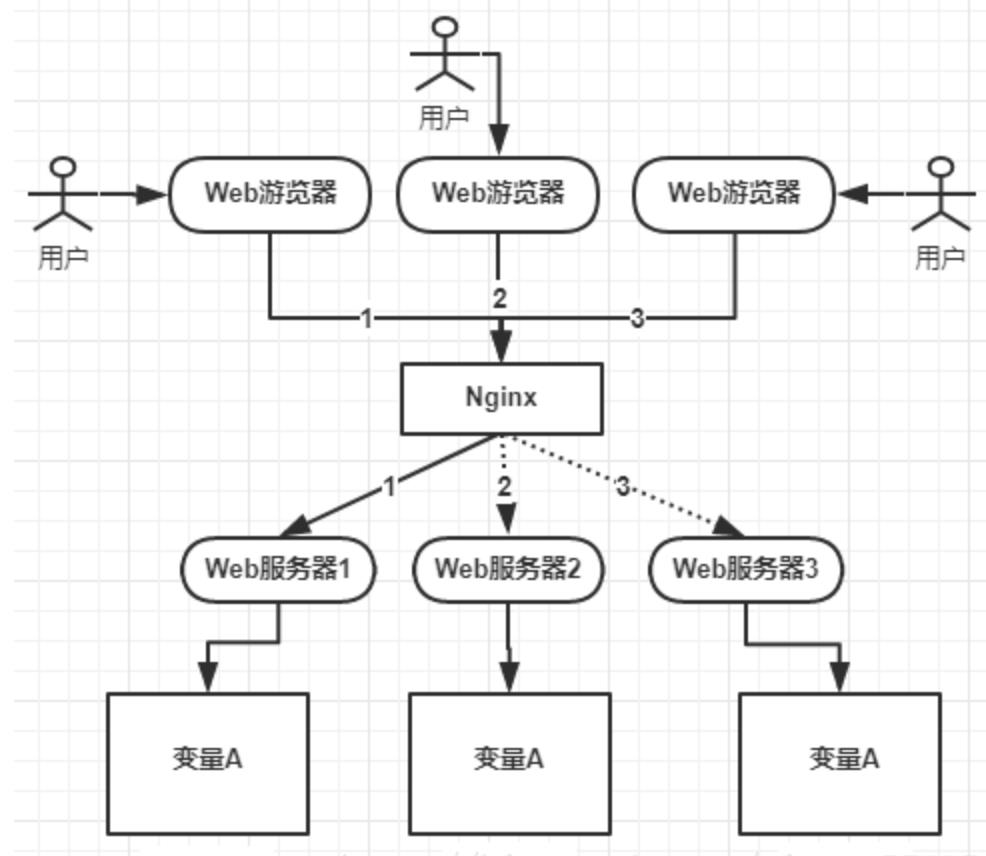
PS:其实跟多线程锁需要解决的问题很像——都是为了达到数据的一致性。只不过多线程锁是为了解决单机问题,而分布式锁是为了解决多台机器(分布式集群)的问题。
分布式锁应该具备的条件:
- 一个方法同一时间只能被一台机器执行;
- 高可用的获取锁和释放锁;
- 高性能的获取锁和释放锁;
- 具备可重入性;
- 具备相应的机制,防止死锁;
三种分布式锁的实现
有三种实现分布式的方式,分别是:
- 基于数据库;
- 基于缓存(Redis);
- 基于Zookeeper;
基于数据库
这种方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
PS:唯一索引是啥?这应该不用解释了。
这种方式的问题:
- 数据库的可用性和性能直接影响分布式锁,因此数据库需要双机部署、数据同步等;
- 不具备可重入,因为同一行数据只能存在一个;
- 没有锁失效的机制;
- 为了阻塞锁等方式,实现方式比较复杂;
基于缓存(Redis)
Redis实现分布式锁的方式的核心就是:Redis性能较好,而且内置分布式锁命令。
具体步骤:
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
这种方式也有缺点:
Redis的性能很好,但是无论是单机还是主从备换模式都可能会造成锁丢失。
基于Zookeeper
Zookeeper**是一个专门为分布式应用提供一致性服务的开源组件,**内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名,步骤如下:
- 创建一个目录mylock;
- 线程A想获取锁就在mylock目录下创建临时顺序节点;
- 获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
- 线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
缺点就在于:
需要频繁的创建和删除节点,性能不如Redis。
总结
分布式的CAP理论表明——任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。因此没有一种方式可以使得分布式锁完美无缺,具体使用什么方式来实现分布式锁,都应根据不同的应用场景选择最适合的实现方式。
参考链接
以上是关于什么是分布式锁?的主要内容,如果未能解决你的问题,请参考以下文章