分布式锁的解决方案
Posted windpoplar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式锁的解决方案相关的知识,希望对你有一定的参考价值。
分布式锁的背景,基于数据库、redis、zookeeper实现分布式锁的原理与优缺点你都知道吗?
为什么要分布式锁、分布式锁的实现方式有哪几种、这几种分布式锁实现方式的优缺点有哪些?阅读完本文后你你应该掌握:
- 基于数据库实现分布式锁具体步骤是什么,优缺点是什么;
- 基于Redis实现分布式锁具体步骤是什么,优缺点是什么;
- 基于Zookeeper实现分布式锁具体步骤是什么,优缺点是什么;
分布式锁诞生的背景
我们在开发单机应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的Java多线程的18般武艺进行处理,并且可以完美的运行,毫无Bug!
我们现在的应用程序如果只部署一台服务器,那并发量是很差的,如果同时有上万的请求那么很有可能造成服务器压力过大,而瘫痪。
想想双十一 和 三十晚上十点分支付宝红包等业务场景,自然需要用到多台服务器去同时处理这些业务,那么这些服务可能会有上百台同时处理,
但是请我们大家想一想,如果有100台服务器 要处理分红包的业务,现在假设有1亿的红包,1千万个人分,金额随机,那么这个业务场景下是不是必须确保这1千万个人最后分的红包金额总和等于1亿。
如果处理不好每人分到100万,那马云爸爸估计大年初一,就得宣布破产了
分布式锁应该具备的条件
在分析分布式锁的三种实现方式之前,先了解一下分布式锁应该具备哪些条件:
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 具备可重入特性;
- 具备锁失效机制,防止死锁;
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
基于数据库实现的分布式锁
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名、类名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
创建一个表

向表中插入数据
此时因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证肯定只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,也就可以执行方法体内容。
成功插入则获取锁,执行完成后删除对应的行数据释放锁
使用基于数据库的这种实现方式很简单,但是对于分布式锁应该具备的条件来说,它有一些问题需要解决及优化,也就是他的优缺点:
- 因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换。
- 不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁。
- 没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据。
- 不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
- 在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂。
- 依赖数据库需要一定的资源开销,性能问题需要考虑。
基于Redis的实现方式
选用Redis实现分布式锁原因
- Redis有很高的性能;
- Redis命令对此支持较好,实现起来比较方便
实现思想
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- 释放锁的时候,若是该锁,则执行delete进行锁释放
配置Redisson
锁的获取和释放工具类编写
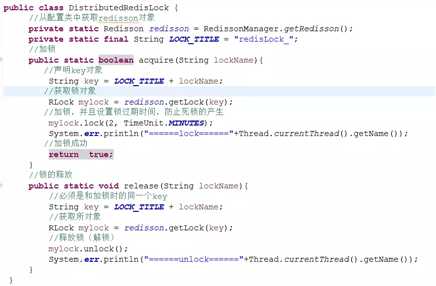
业务中使用分布式锁
基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
- 创建一个目录mylock;
- 线程A想获取锁就在mylock目录下创建临时顺序节点;
- 获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
- 线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
使用方式
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
优点
具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点
因为需要频繁的创建和删除节点,性能上不如Redis方式。
Redis 分布式锁和Zookeeper分布式锁的对比
Redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
Zookeeper分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小。
单点的redis能很好地实现分布式锁,如果redis集群,会出现master宕机的情况。如果master宕机,此时锁key还没有同步到slave节点上,会出现机器B从新的master上获取到了一个重复的锁;另外一点就是,如果是Redis获取锁的那个客户端出现 bug 挂了,那么只能等待超时时间之后才能释放锁。
而 Zookeeper的话,因为创建的是临时znode,只要客户端挂了,znode 就没了,此时就自动释放锁。但是zookeeper也会有弊端,那就是有可能会出现“羊群效应”,至于为什么,可以自己百度一下。
以上是关于分布式锁的解决方案的主要内容,如果未能解决你的问题,请参考以下文章