20210616 日千万级流量架构优化策略
Posted 陈如水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20210616 日千万级流量架构优化策略相关的知识,希望对你有一定的参考价值。
千万级流量架构策略
了解现状:架构,业务特点;
应急方案:改造时间短,可以短期支撑住访问压力。
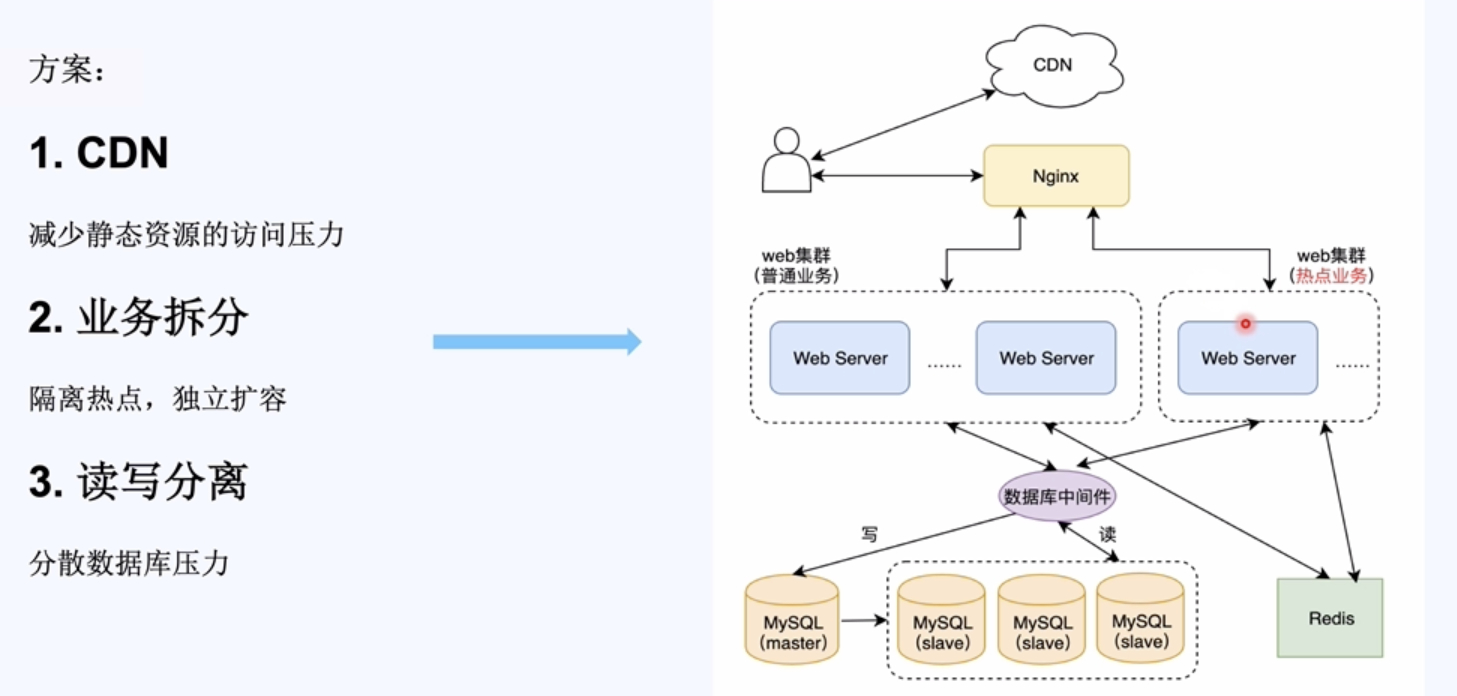
隔离热点,单独部署。就算热点挂了,也不影响其他功能。
峰值QPS=(日总PV数*80%)/(日总秒数*20%) 这只是理论值
pv*0.8/17280 pv/21600 每秒的峰值
每天千万级流量
1000万/21600=463QPS/s
如果每台机器100QPS
463/100 = 5台机器。
我的单机可以支撑日千万级流量访问,但是 当前服务100QPS/S
核心的架构策略:
拆分,队列,缓存,降级,限流。
使用队列来解决分布式事务的问题。
布隆过滤器,海量恶意攻击很有效。
无论是哪种限流策略,算法才是最重要的。
一,做架构的核心:拆分。
1,架构演进过程:
各自独立:各个服务独立出来,要不然会相互争抢资源;
集群化:单节点已经不能支持业务请求,需要加派人手。
分布式架构:集群力度太粗,改成分布式架构,分工越细效率越高。
多集群部署:一套系统很难支撑太高的并发量,所以进行多集群部署。
异地分布式集群架构(易地部署):为了照顾全国各地的用户,甚至国外的用户,需要异地部署。
集群和分布式的区别
每个节点负责的工作都一样;分布式,大家分工不同,每个人做自己的事。多个人协同干一个活。
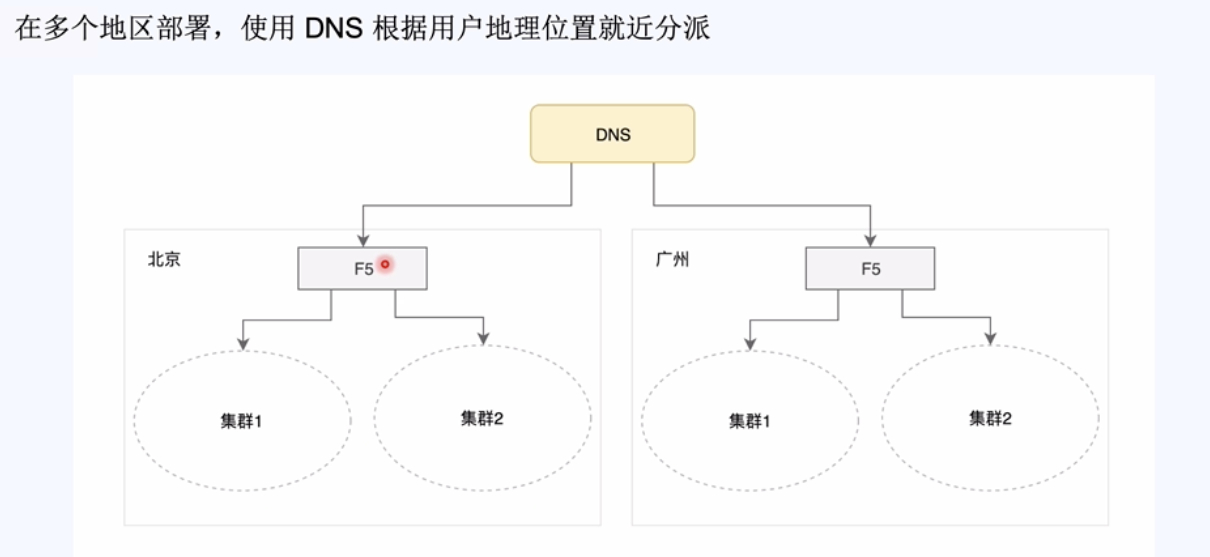
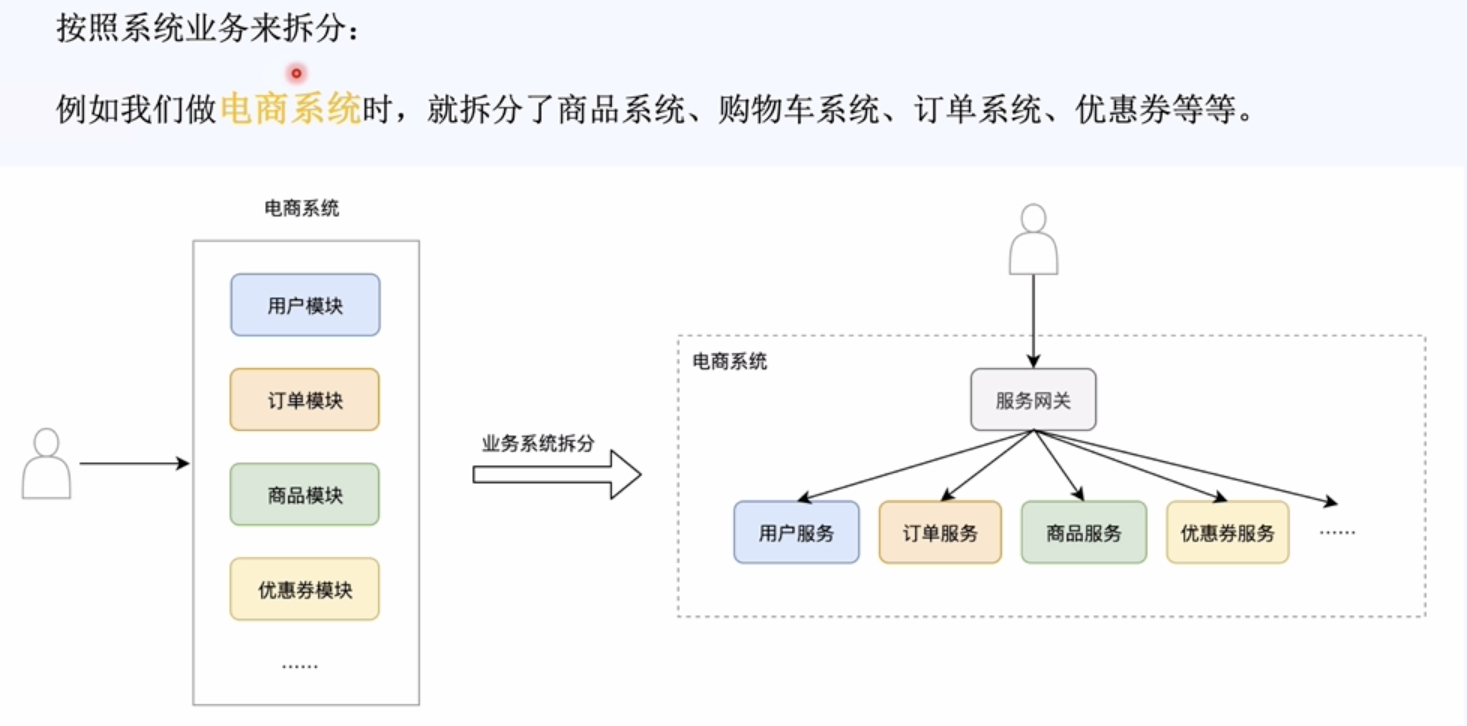
2,拆分的维度:系统维度,功能维度,读写维度这三个维度进行拆分。
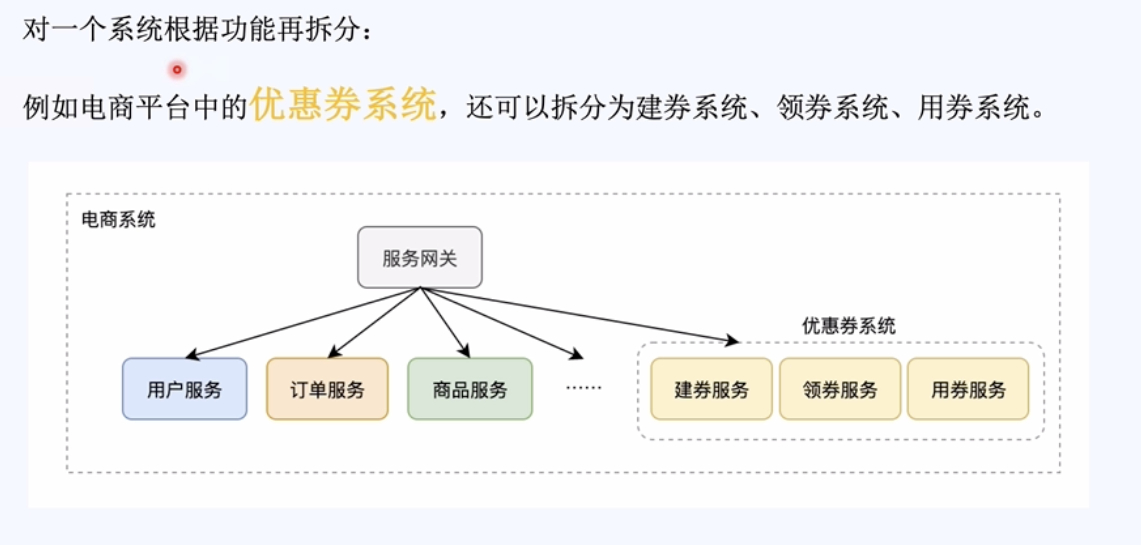
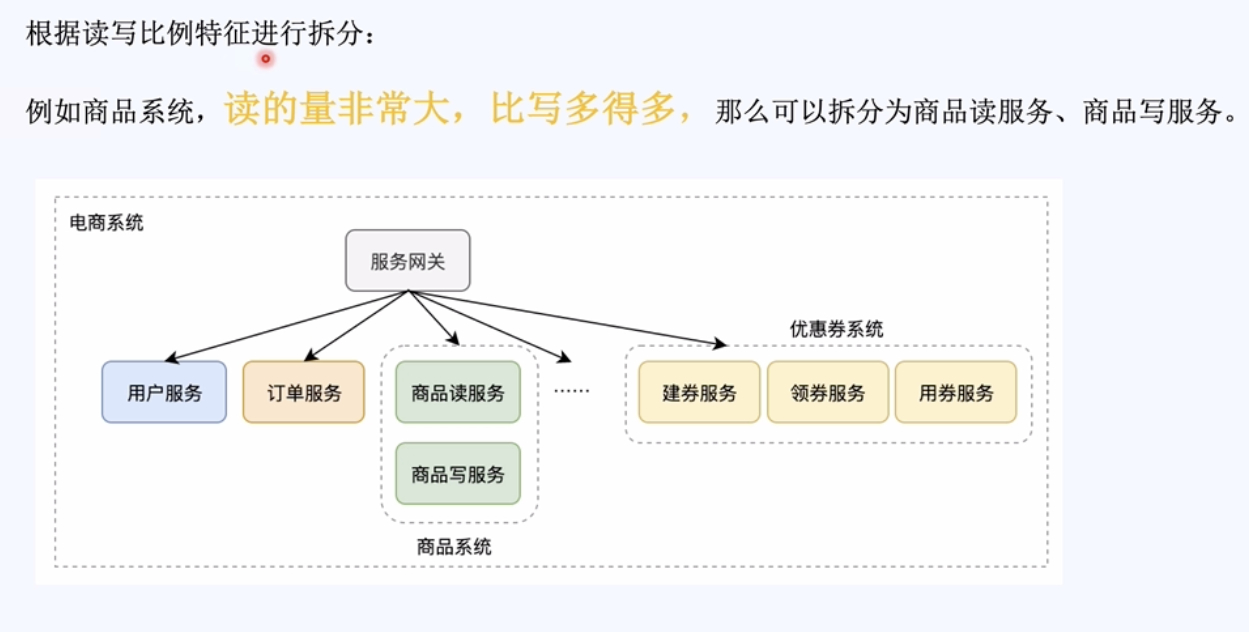
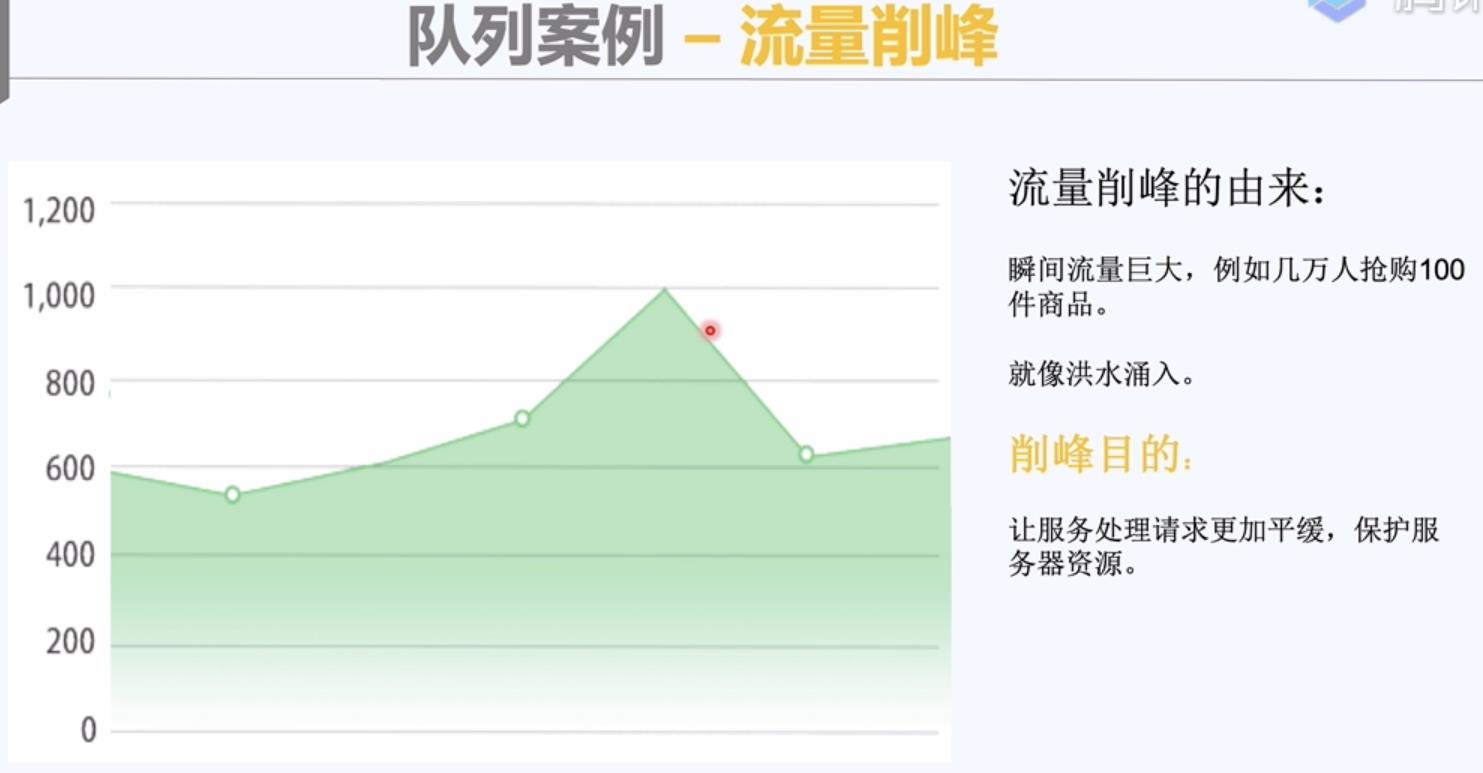
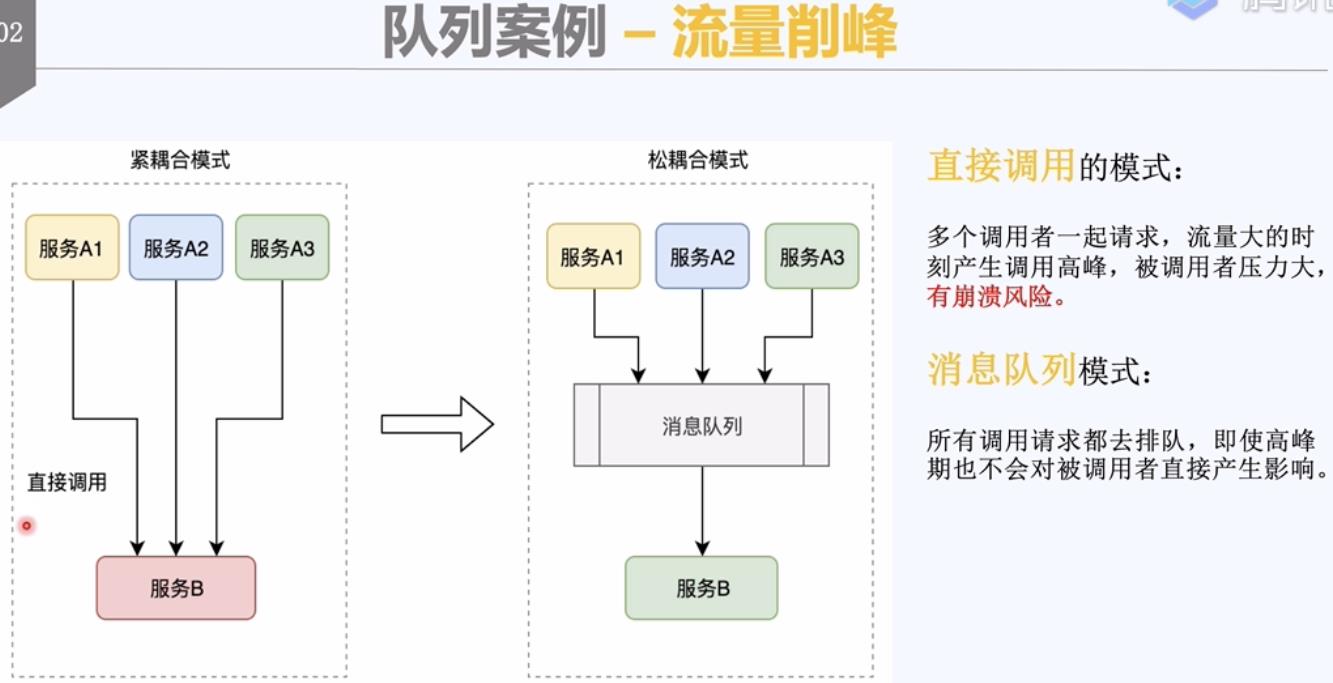
二, 队列的核心:异步 平缓的处理。
消息队列的使用案例:
1,流量削峰和解耦:让请求排队,一个一个去处理。
让同步请求变成异步请求
2,使用可靠消息模式解决分布式事务问题。
可靠消息模式:
1)发送方保证消息不丢失;
2)接收方保证消息不重复消费;
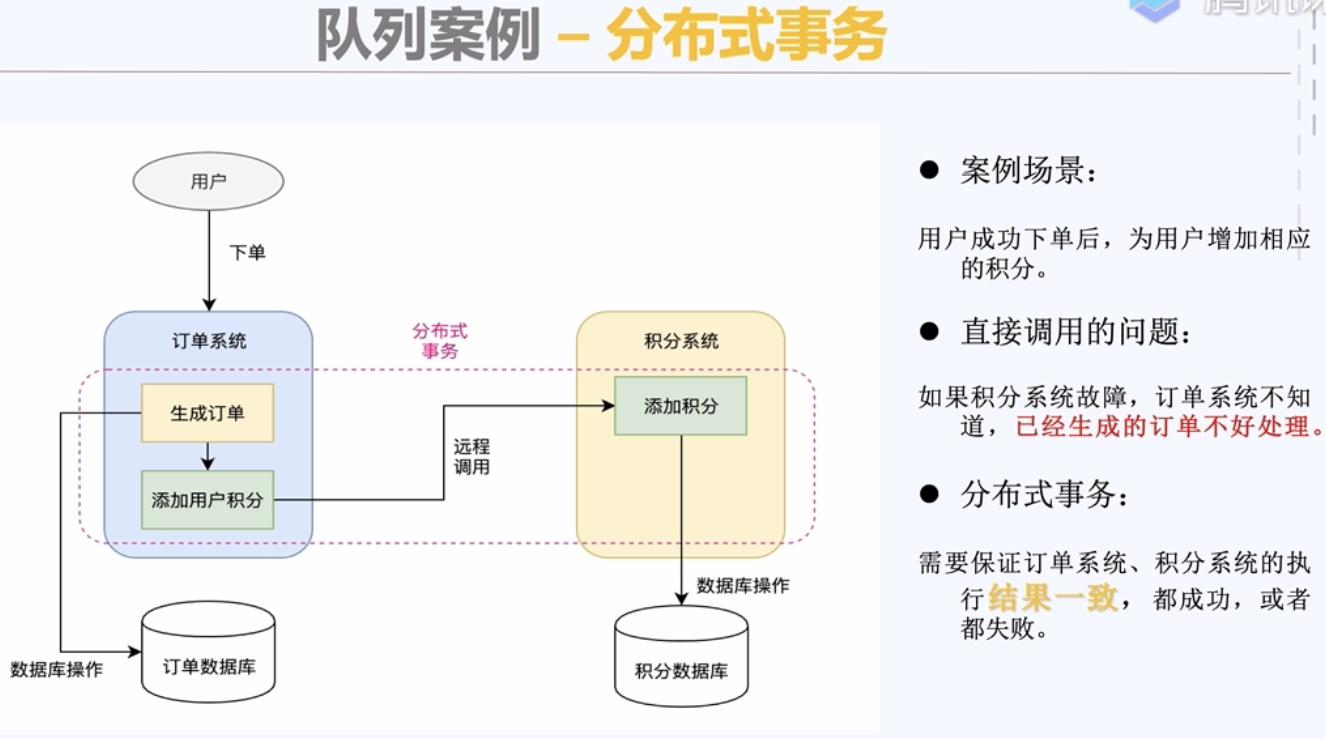
使用可靠消息模式保证最终一致性。因为是远程调用,所以就要考虑失败的可能性。
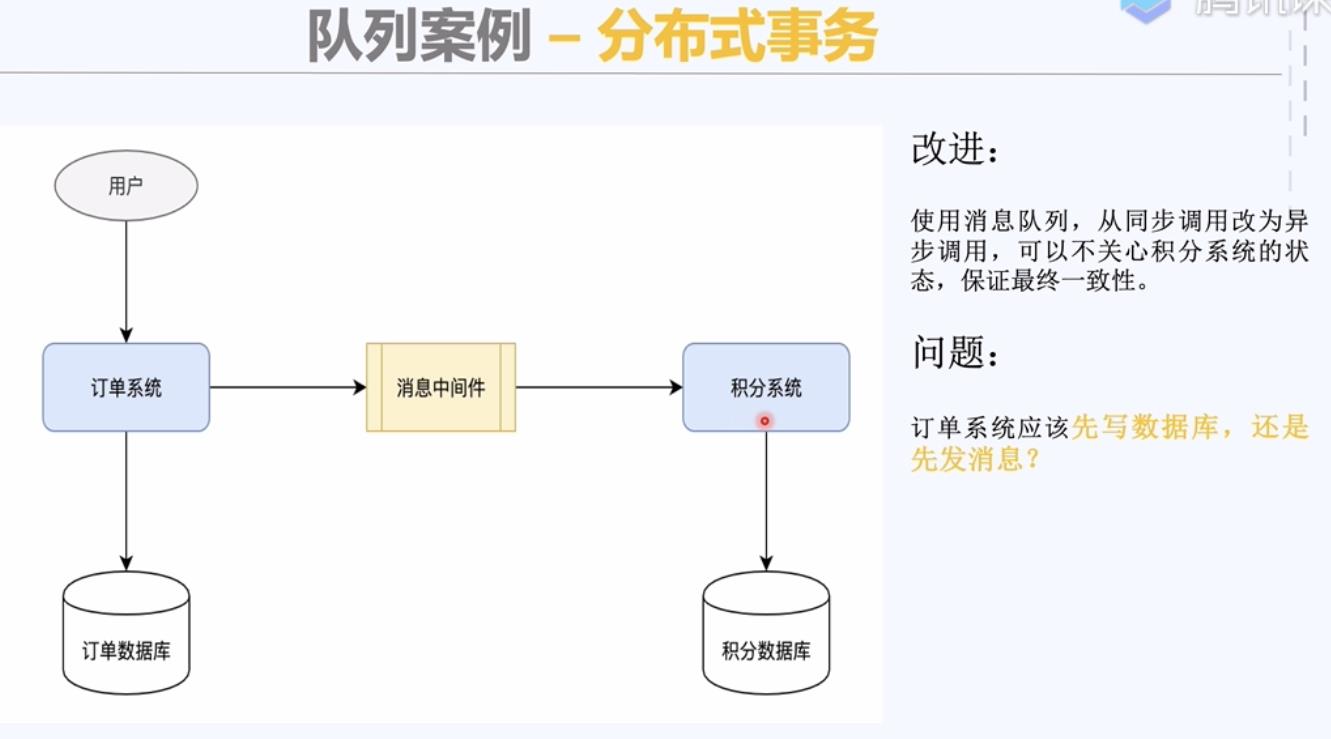
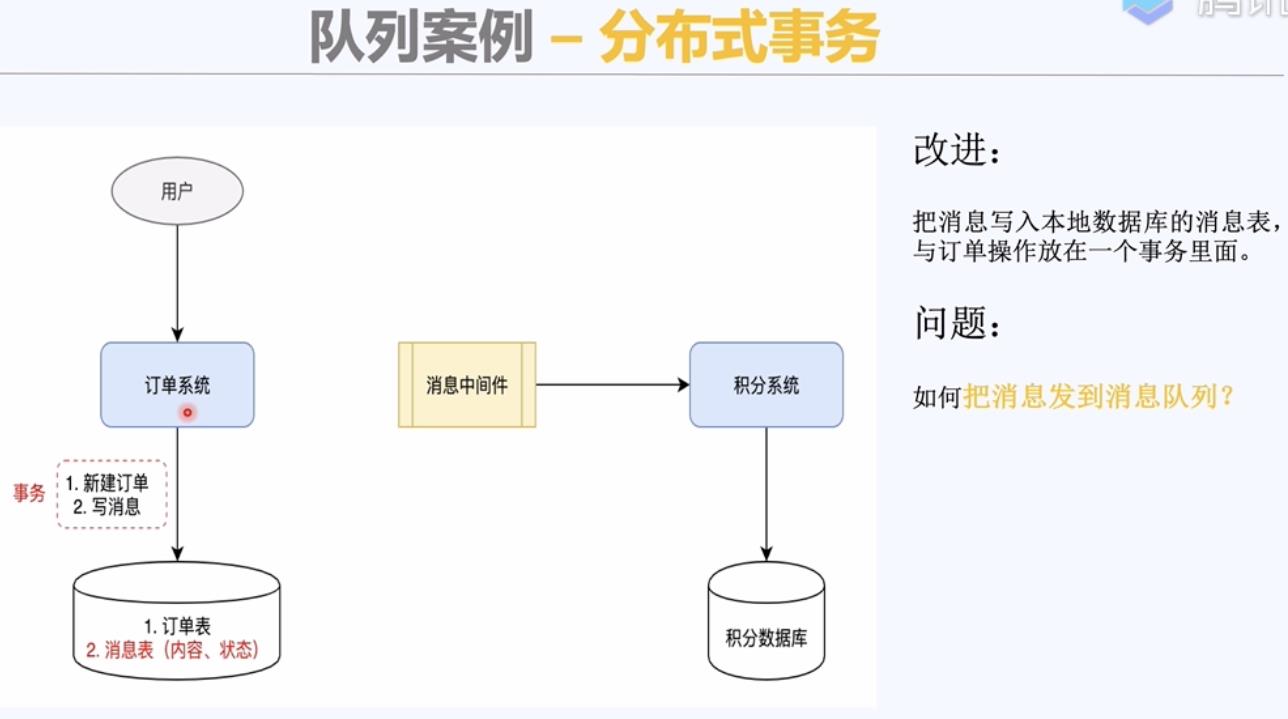
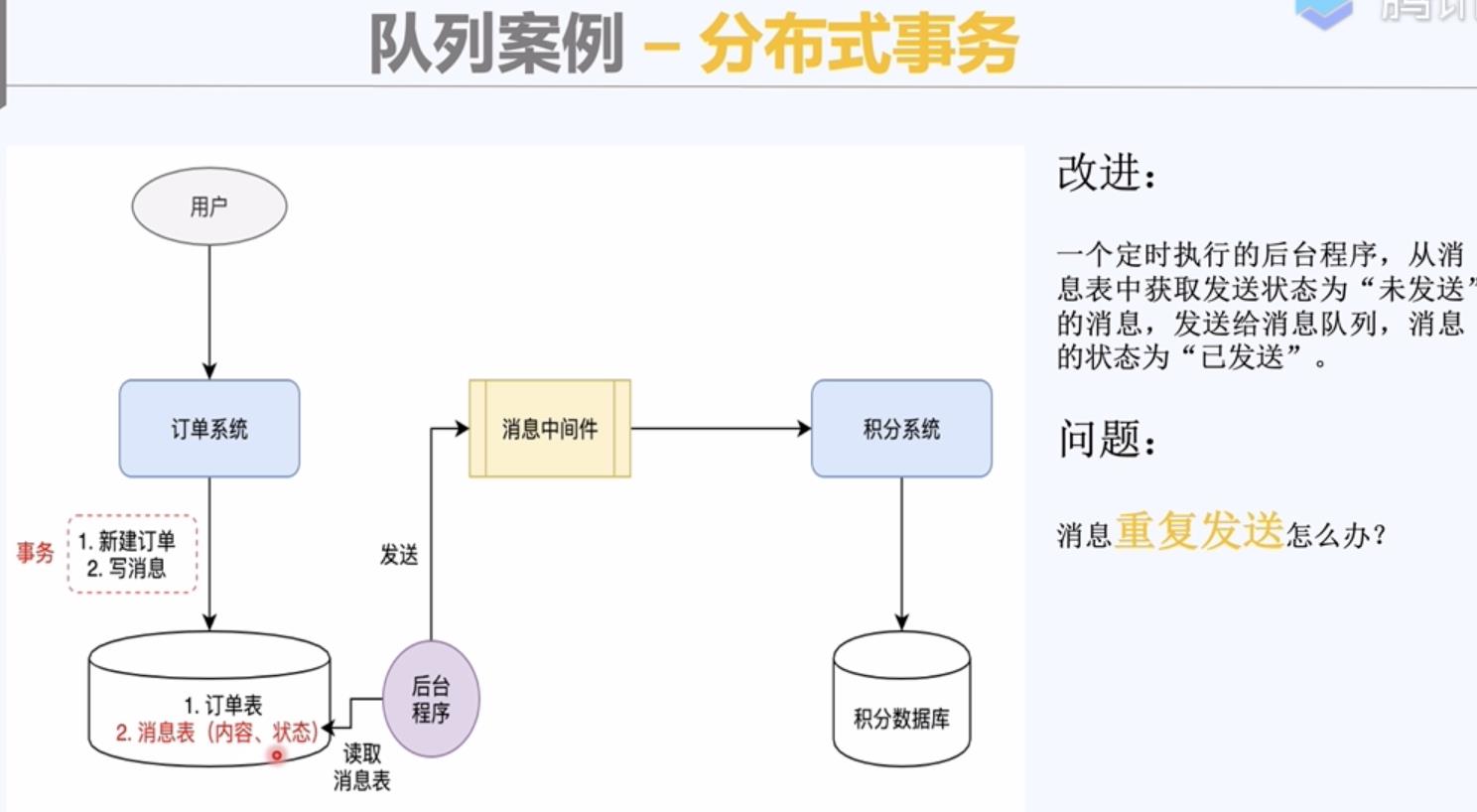
积分系统进行去重判断,保证幂等性。
添加一个判重表,进行业务逻辑处理之前先从判重表中查询一下。
积分表,判重表。
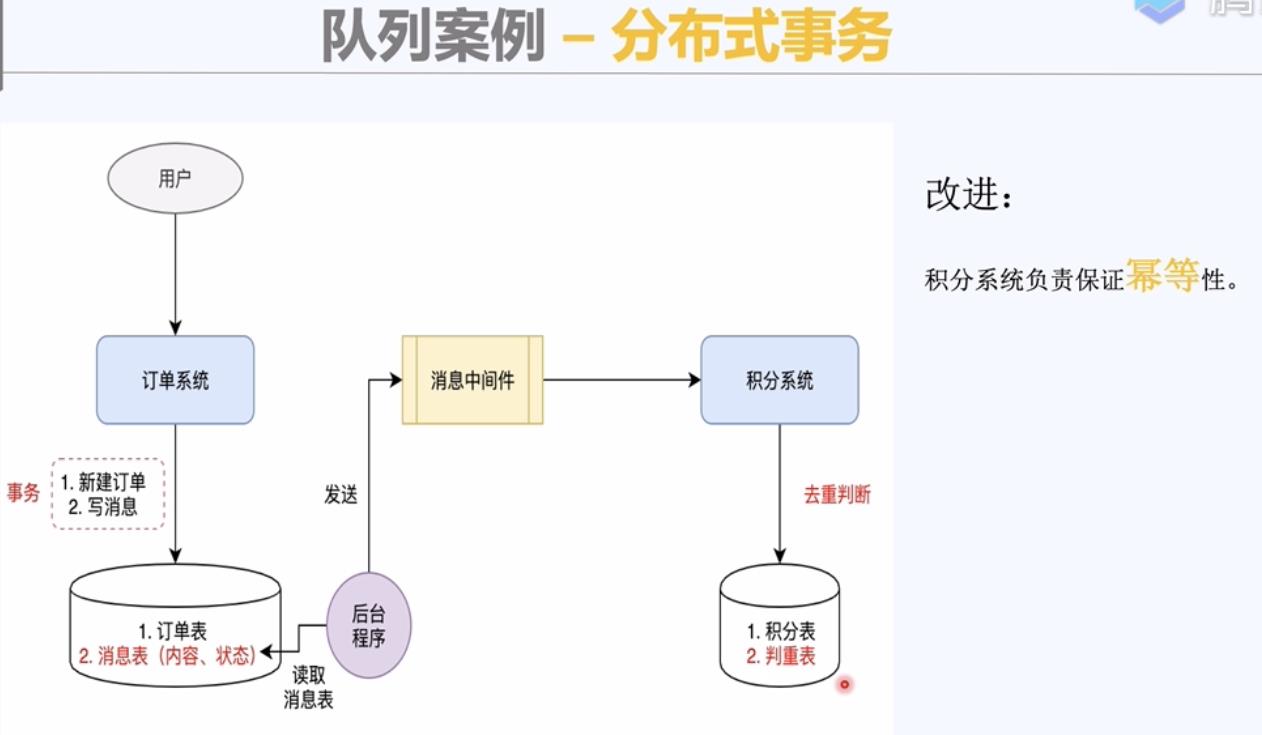
总结:
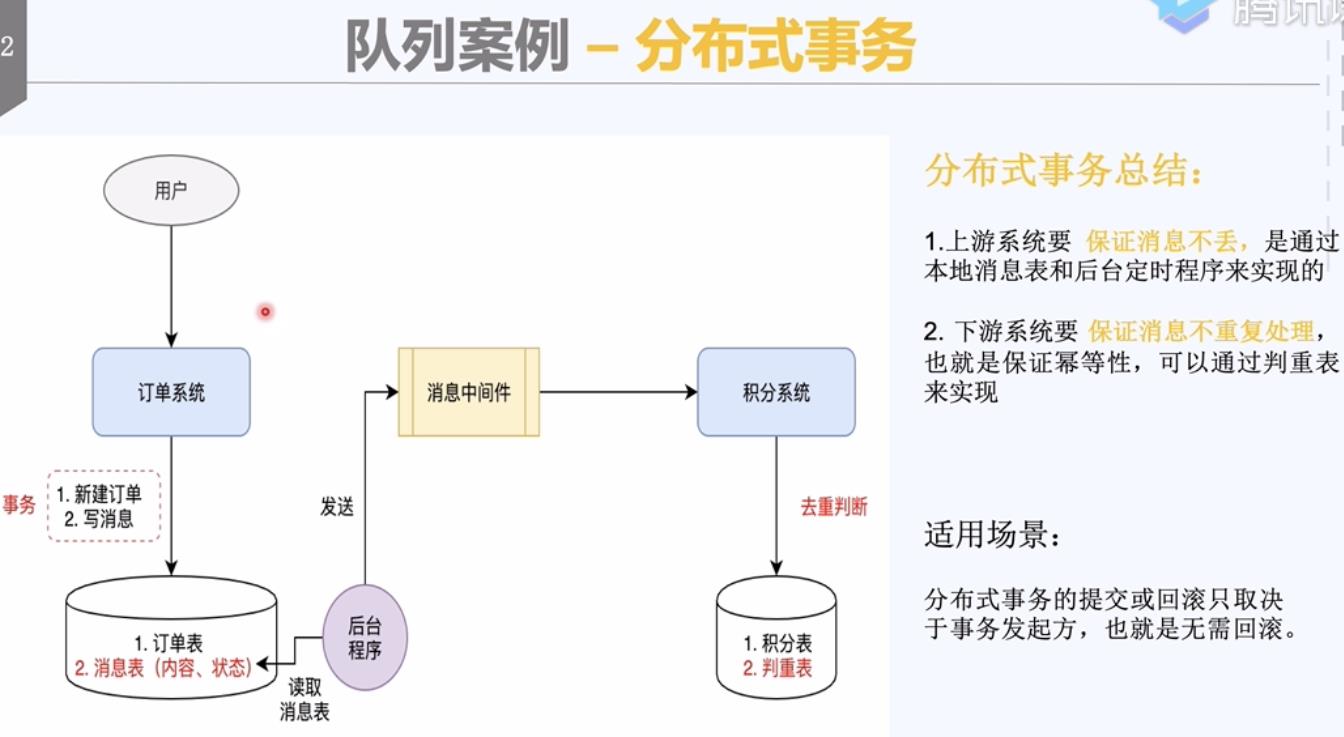
1)订单系统失败了,不会发消息,积分系统也不用执行。
2)即使下游服务失败了,也可以通过重试解决,不需要回滚。
3)可靠消息模式是处理分布式事务的常用模式。
三,缓存
缓存类型:
1)客户端缓存:浏览器,App 客户端;
2)网络:CND缓存(静态资源缓存,减轻网站访问压力,提升用户体验;CDN按照流量收费)
3)接入层:nginx代理缓存。
4)应用层:Redis缓存。
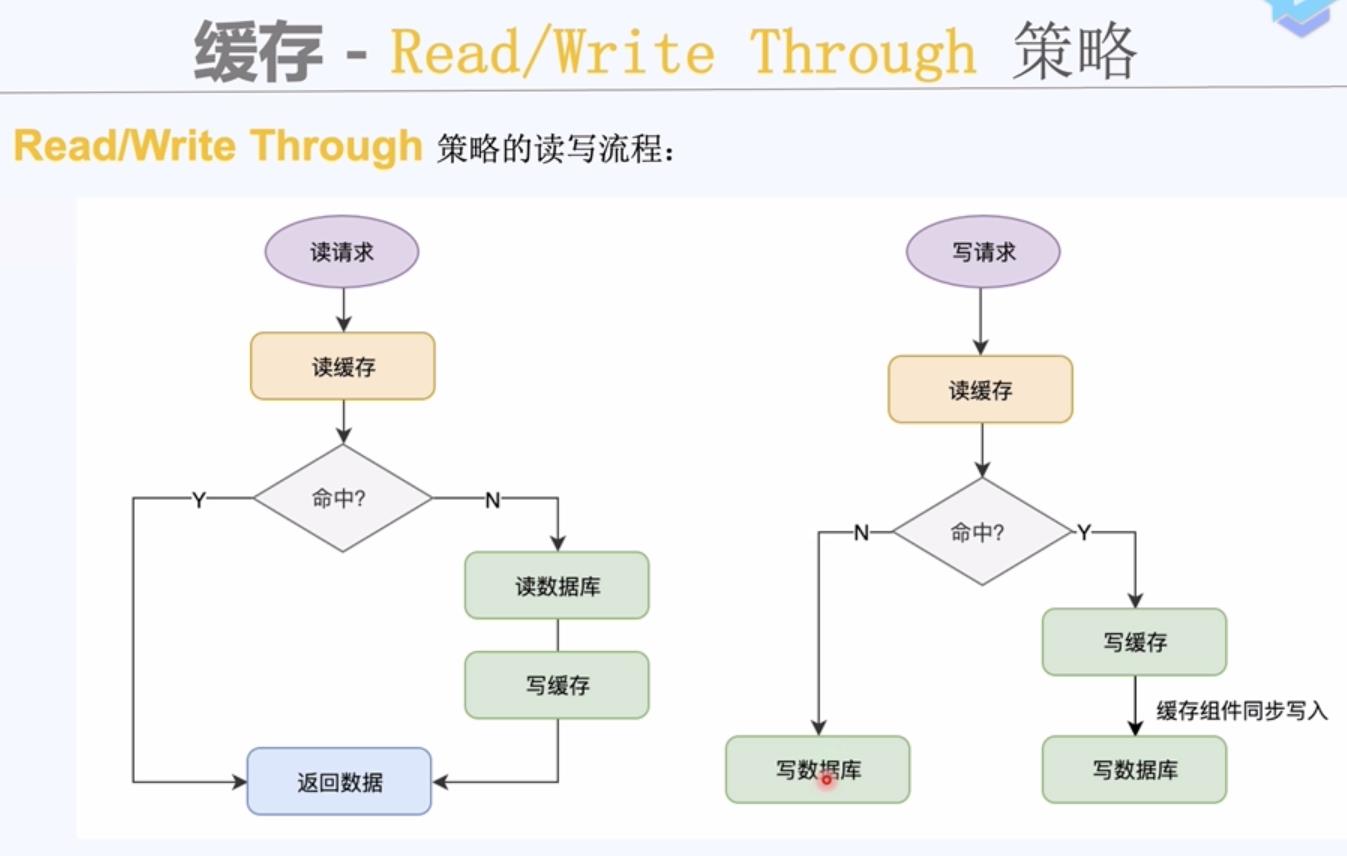
缓存读写策略
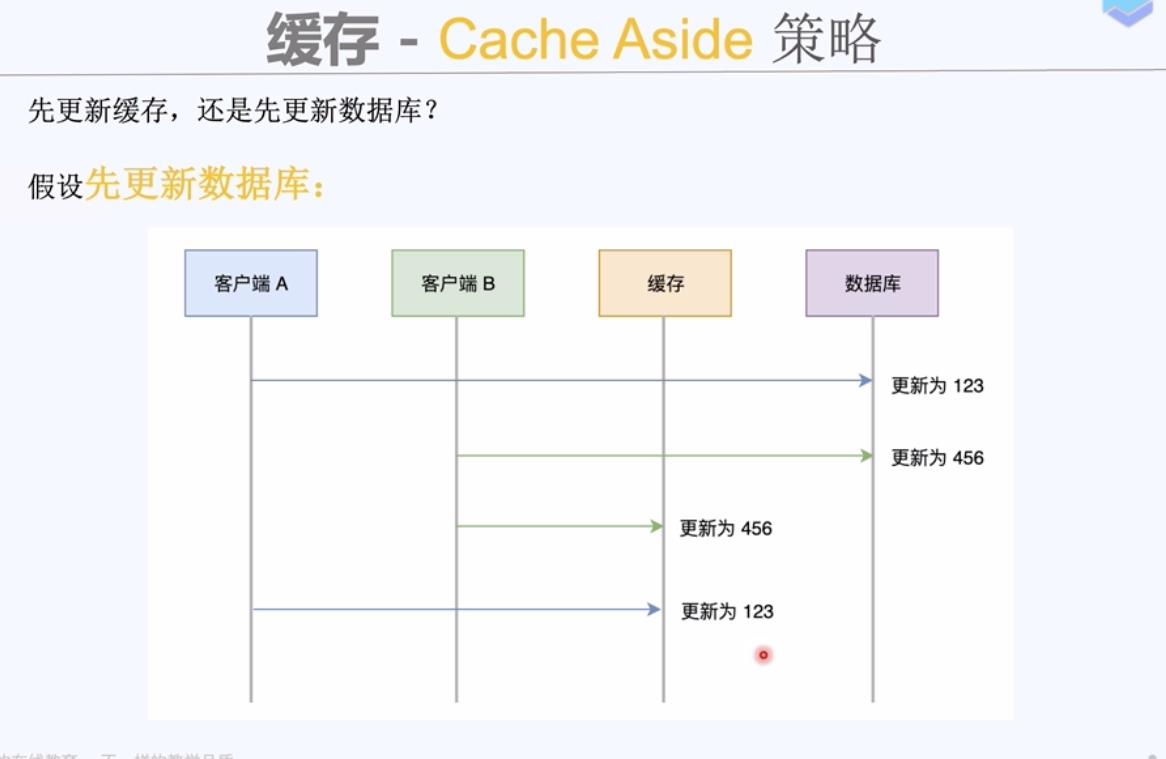
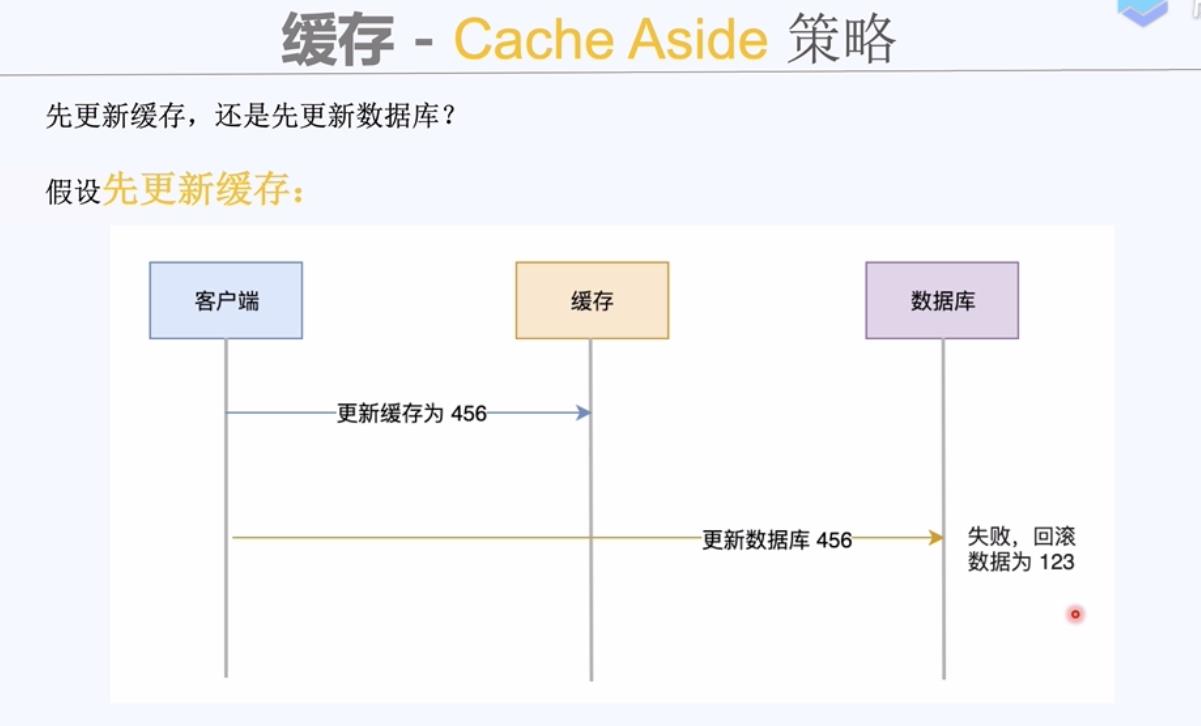
无论先更新缓存还是先更新数据库,数据库里的数据和缓存里的数据不一致了。不是原子操作,没有控制并发。
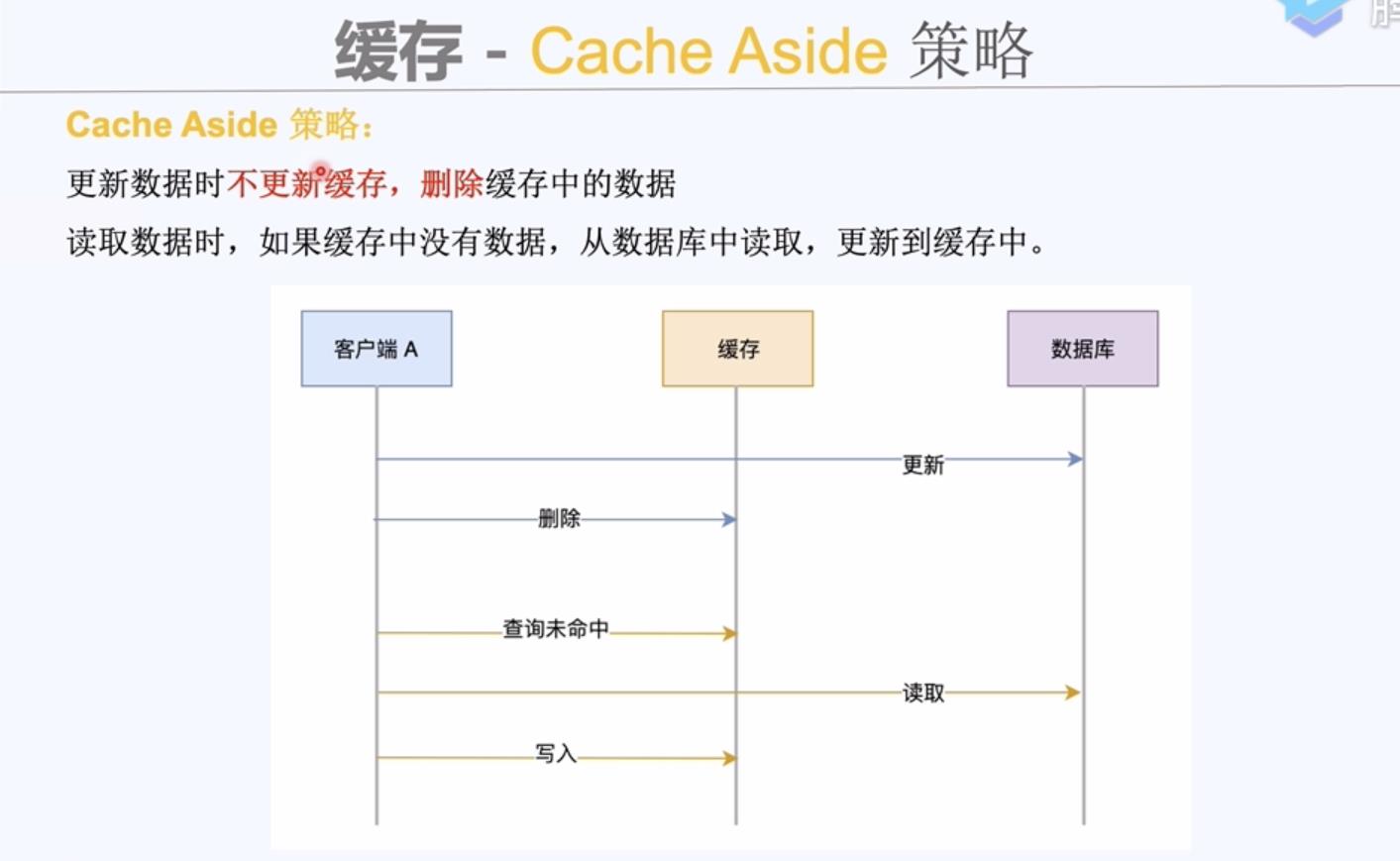
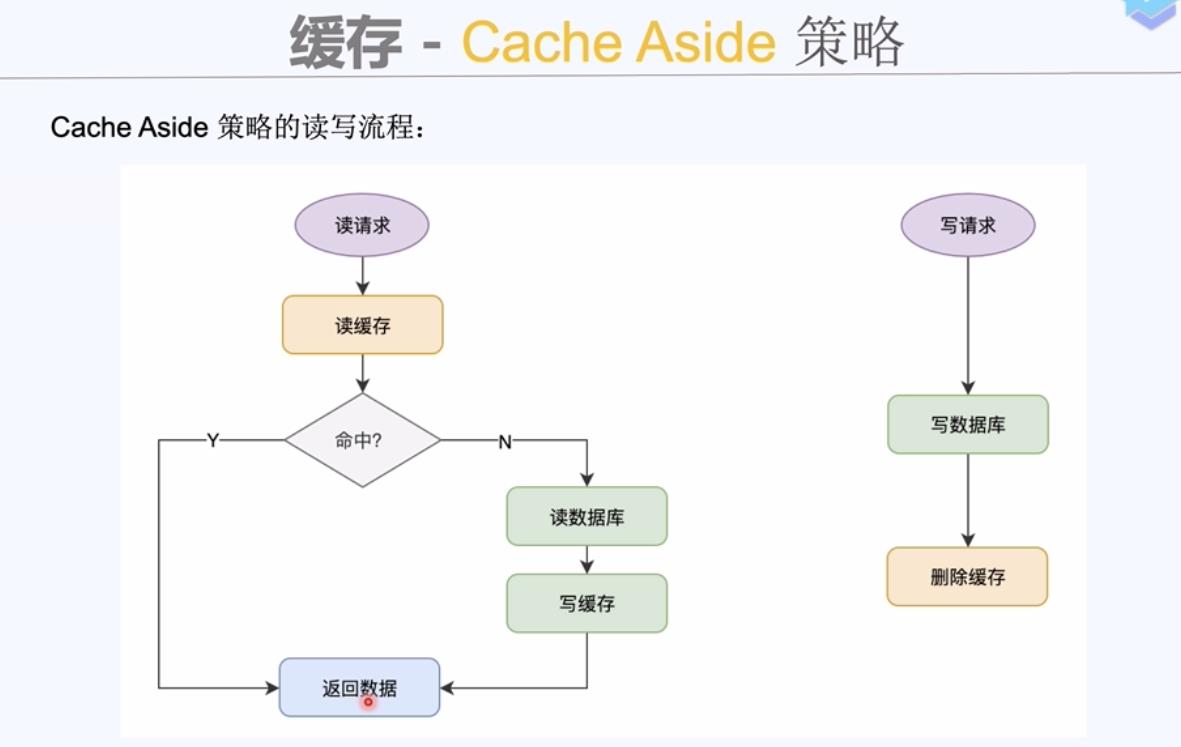
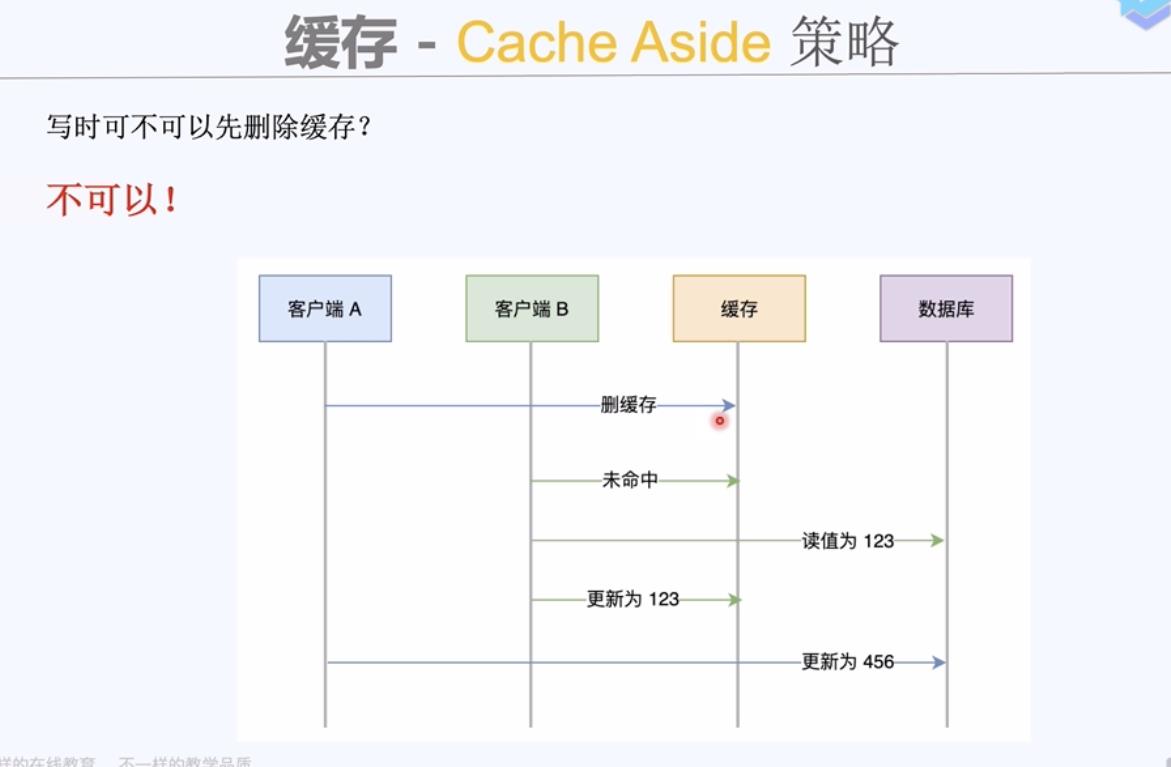

缓存组件同步写入
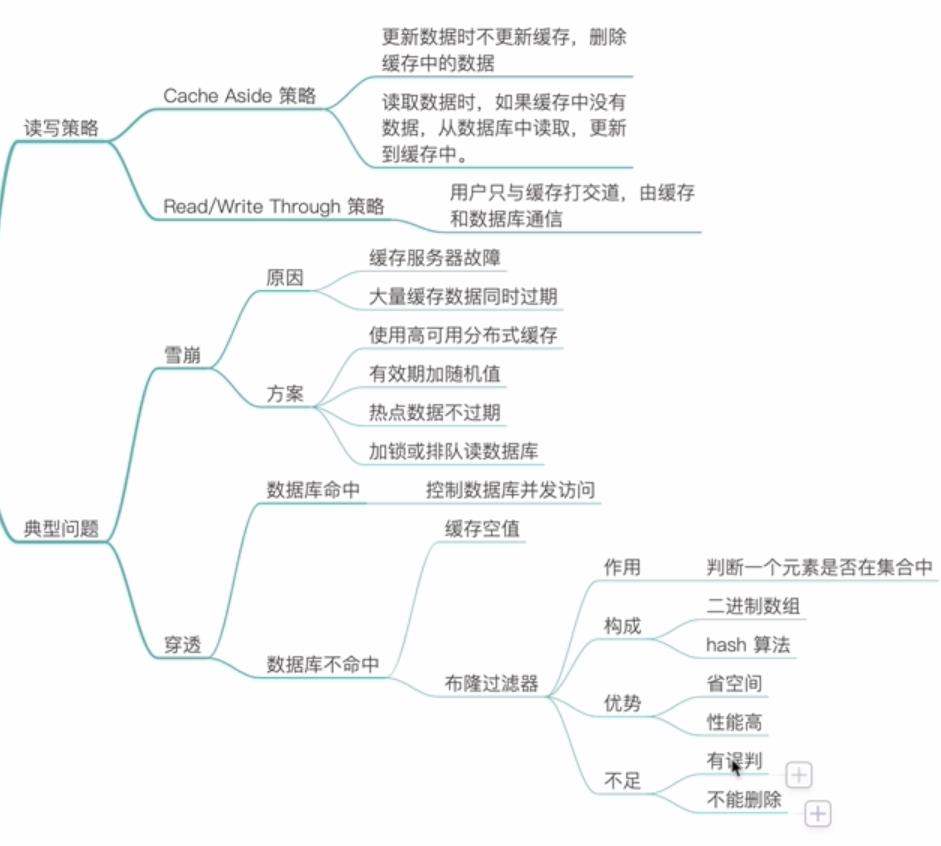
缓存服务器的典型问题(原因和解决方案)
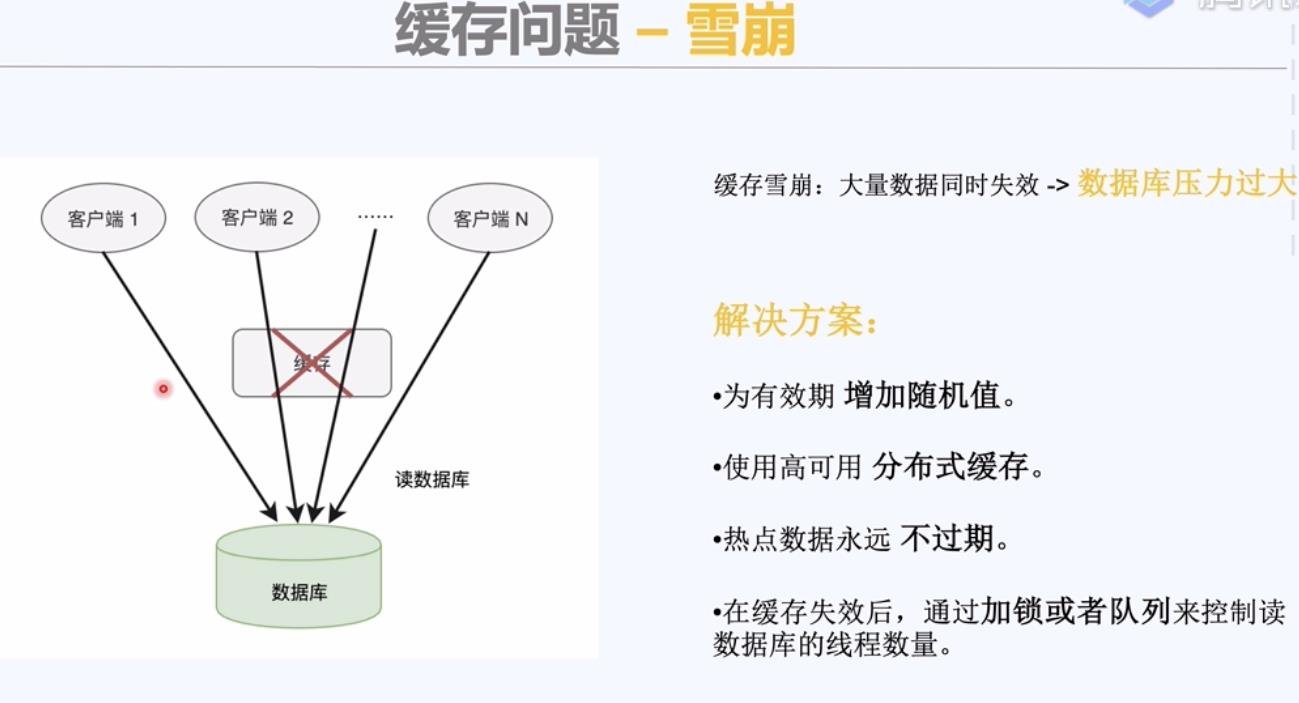
缓存雪崩原因:大量缓存同时过期;缓存服务器故障;
使用分布式缓存,它本身有高可用机制,并且数据是分片存储。
1)雪崩;使用高可用的分布式缓存,有效期加随机值,热点数据不过期,加锁或者排队读数据库。
2)穿透;缓存空值,布隆过滤器;
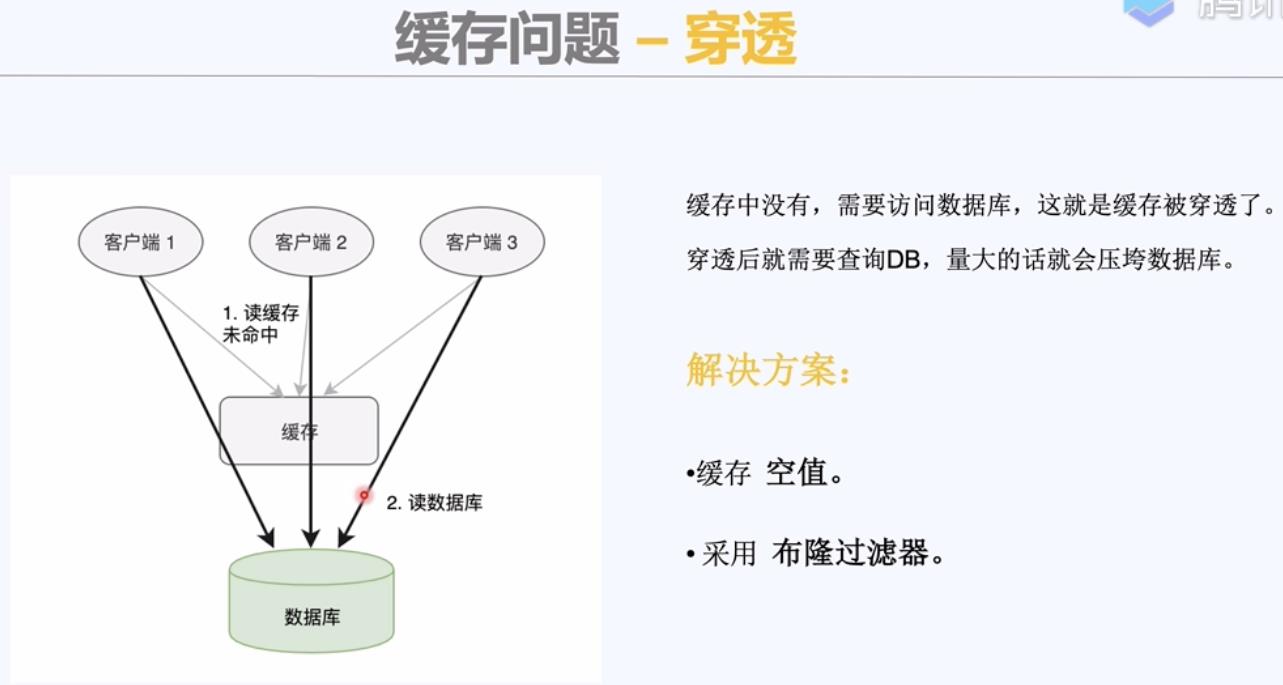
缓存空值,对数据库可以起到保护作用。 并发情况下。
但是缓存空置有局限。
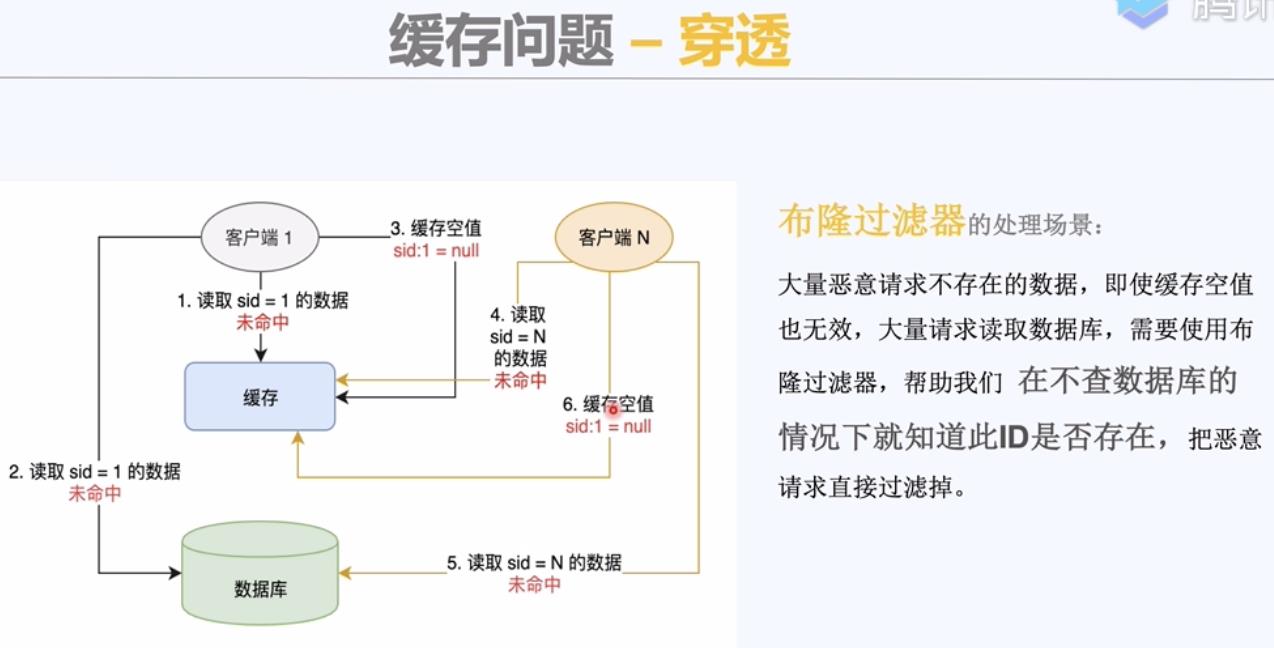
在不查询数据库的情况下就知道此id是否存在。
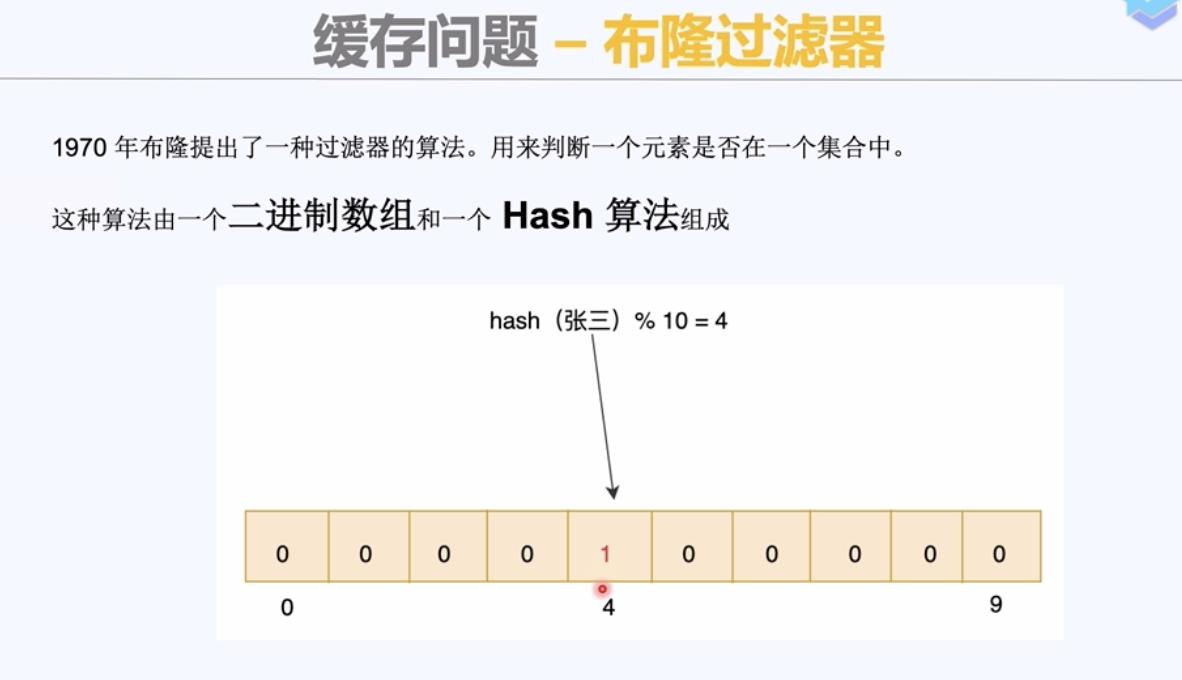
布隆过滤器:用来判断一个元素是否在一个集合中。
对数组长度进行取模。数组中的元素只有0和1.
如何使用布隆过滤器来解决缓存穿透问题呢?
1,写入数据时,更新布隆过滤器。如何更新布隆过滤器?
2,查询时先查询布隆过滤器。
布隆过滤器的问题:
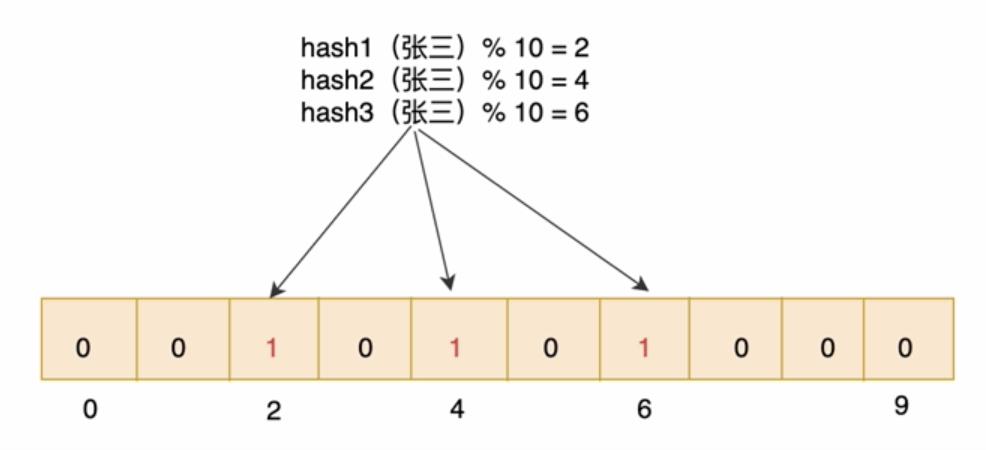
1,由于hash冲突,存在误判;例如hash(张三)=4,hash(赵四)=4
可以使用多个hash函数一起计算,提高精度。多个hash的值都设置为1.
2,不能删除。可以使用int数组进行计数。一般场景中不会存在删除。
四,降级
功能降级:电商平台很普遍的推荐功能,可以提升销量,但不是购物的核心流程。在系统压力大的时候,可以降级,改为默认内容。
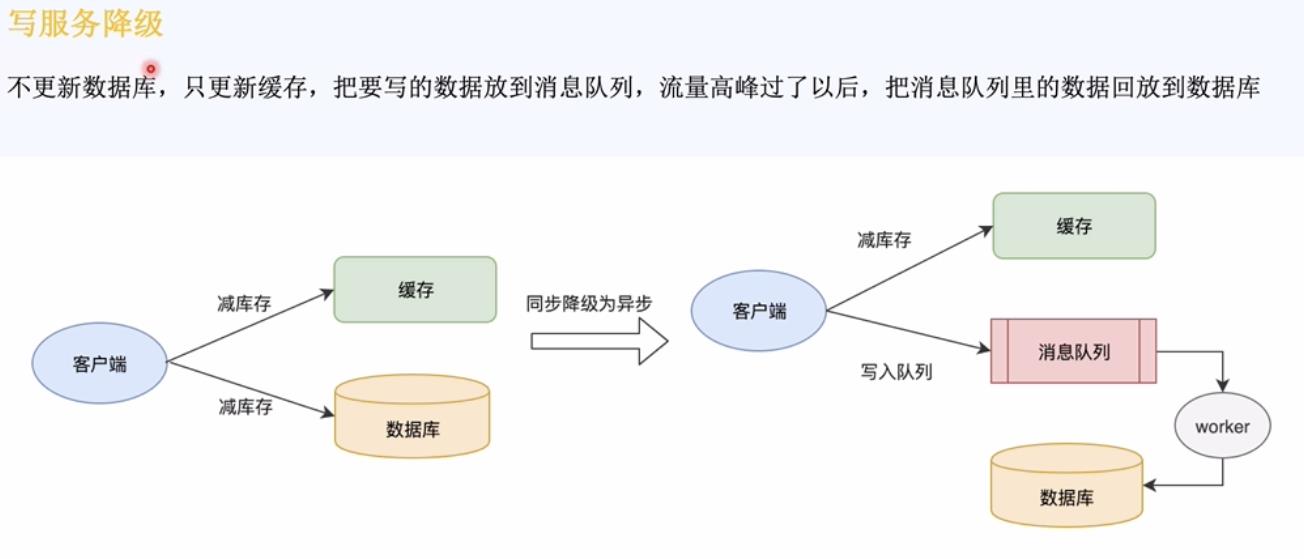
写服务降级

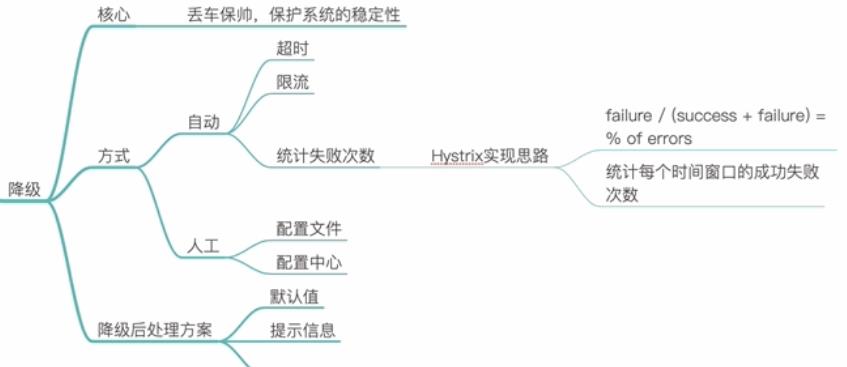
降级的方式分为:自动降级和手动降级
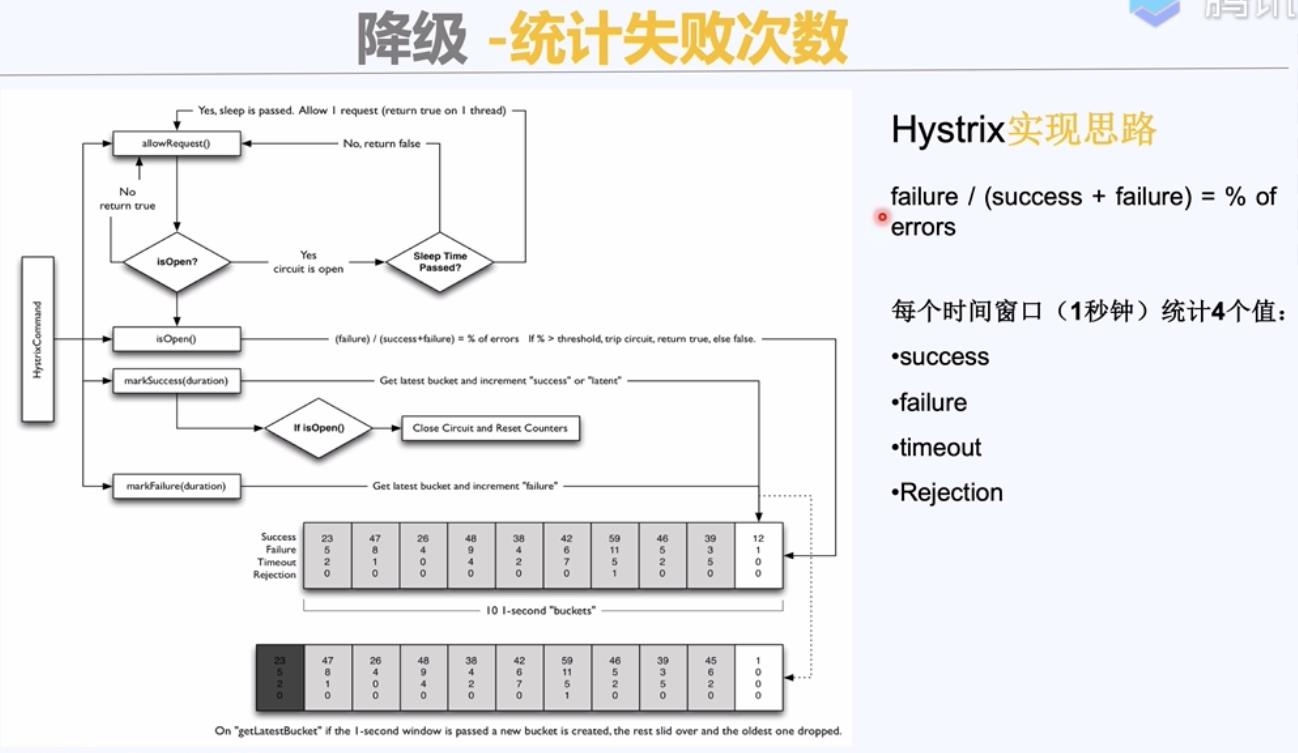
自动降级:超时降级,限流降级,统计失败次数降级。

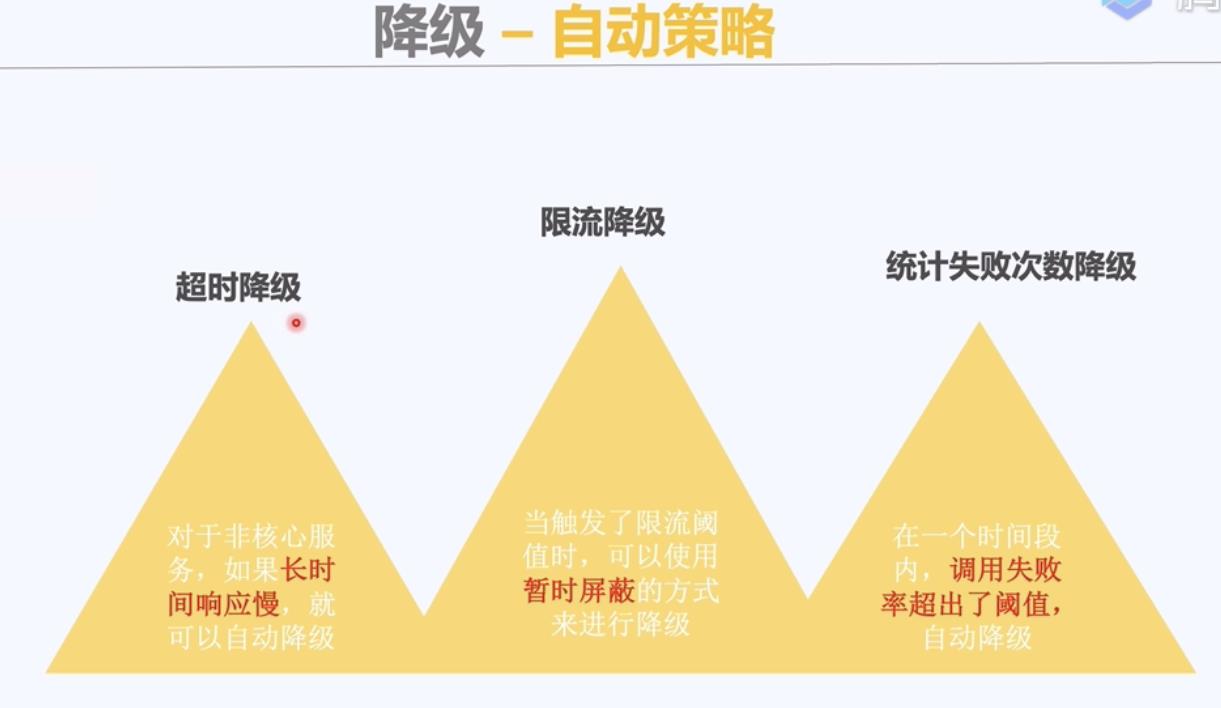
超时降级需要配置好超时时间和重试次数。
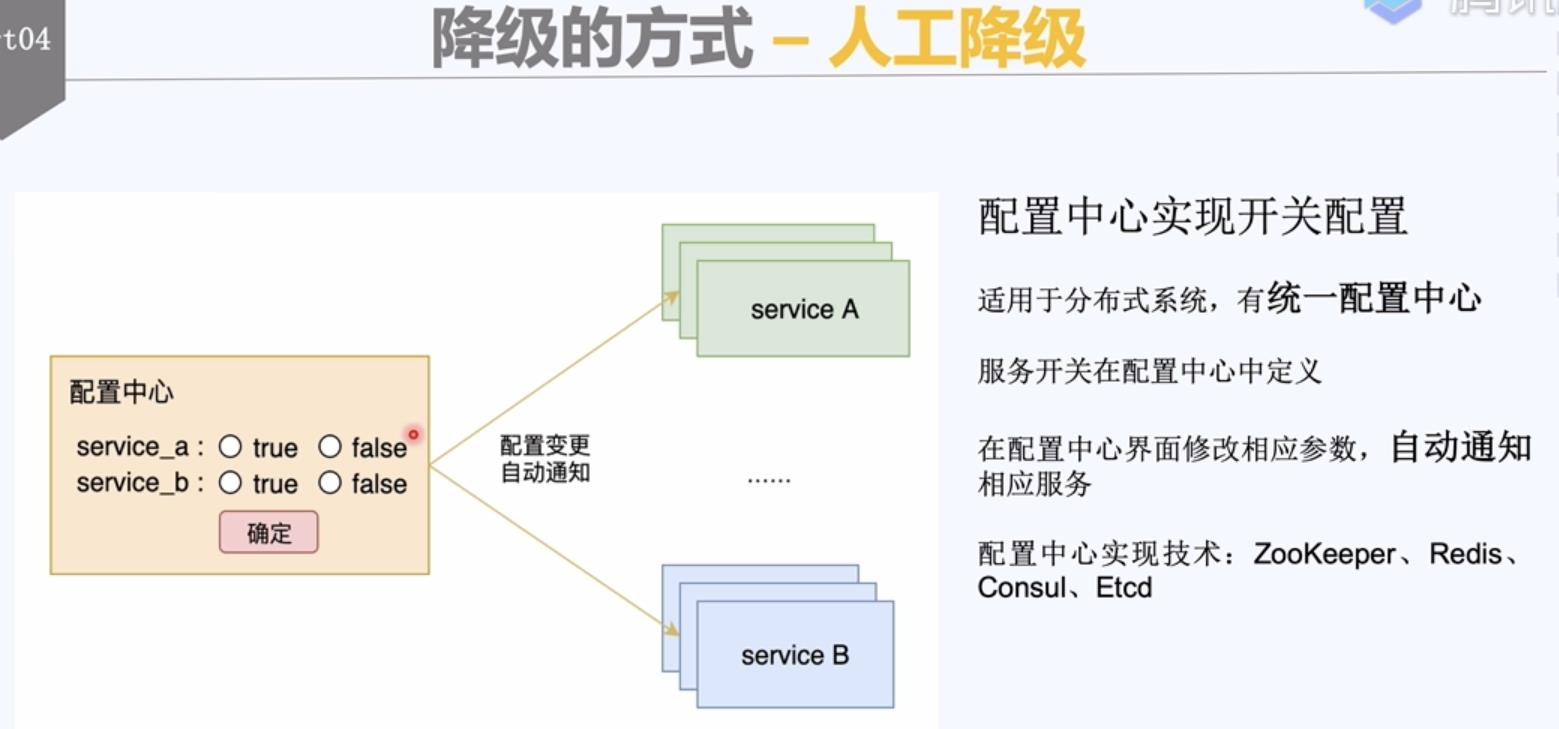
人工降级:
通过修改配置参数活配置文件,通知服务降级;就像一个总闸,可以预先把非核心的功能关闭;也可以在监控系统发现问题时人工介入。
配置文件实现开关配置:适用于系统部署结构简单的场景;系统自动监控配置文件的变化,配置文件变化后自动载入。
配置文件中定义了各个服务的开关。
降级后的处理方案:
使用默认值,兜底数据,缓存数据,排队页面,无货通知,错误页面等
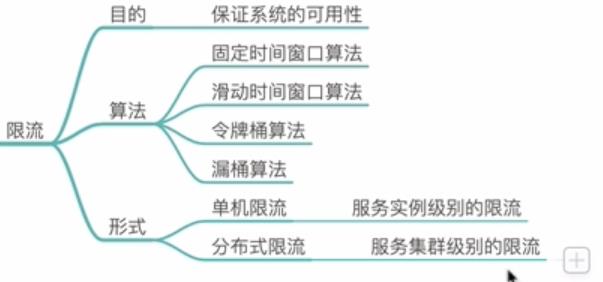
五,限流(系统架构核心技术,设计架构要考虑到限流,高可用)

限流:系统访问量达到一定的阈值,采取以下措施:拒绝处理,延迟处理,部分拒绝等。
为什么要进行限流?
1)系统不崩溃(A系统,1000次请求正常,2000次请求很慢很卡,5000次请求直接宕机)
2)确保系统的高效运行。高可用
高并发三大利器(保护系统的手段):缓存,限流,降级。
缓存:提高系统的访问速度,增大系统处理能力。
降级:暂时屏蔽,过后打开。
限流:对稀缺资源限制请求量,限速,拒绝服务。保证系统的可用性。
常用限流算法
1)固定时间窗口算法;计数器算法,实现简单;性能好
2)滑动时间窗口算法;
3)令牌桶算法;
4)楼痛算法;(会误杀请求)
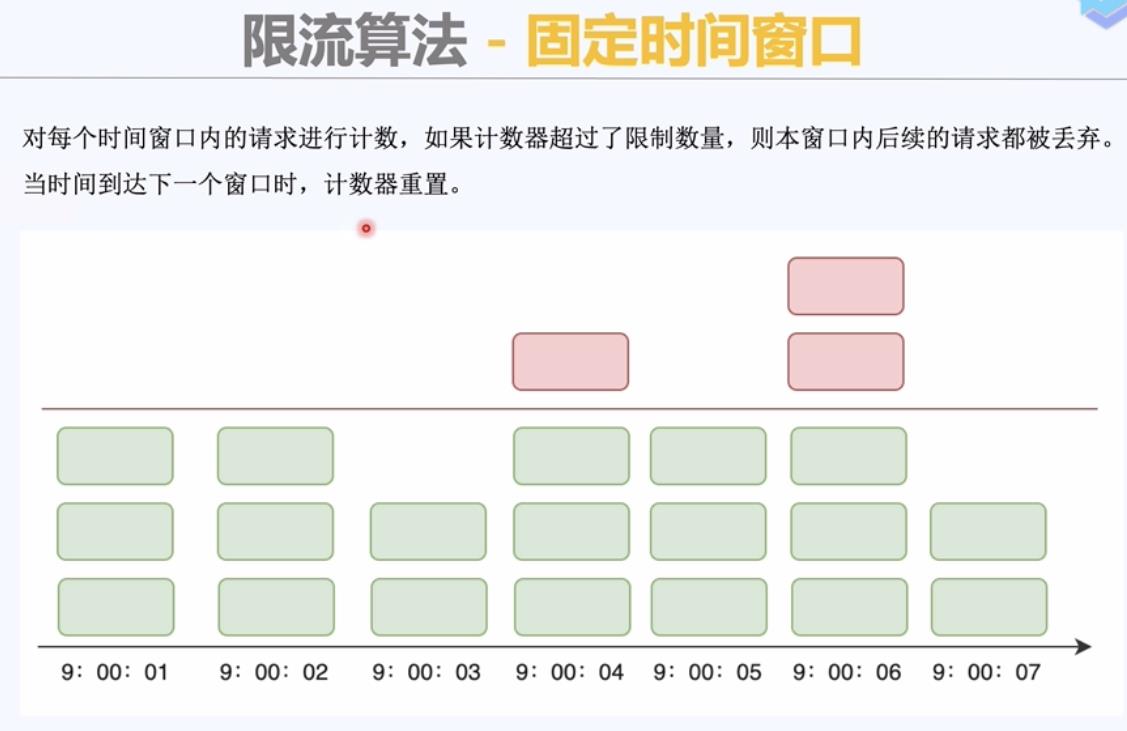
红先表示阈值,超过阈值就被丢弃。
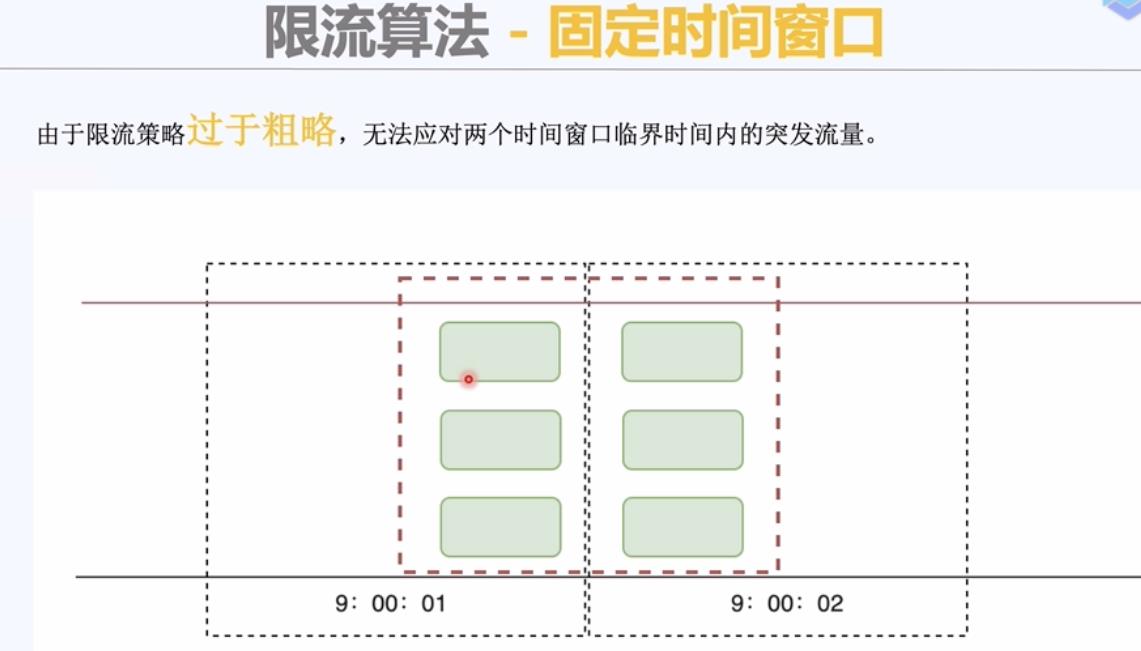
临界问题:1分钟访问100次,变成10秒钟访问两百次。 这两百次请求全部发生在临界时刻的前后五秒。
滑动时间窗口算法
不仅会对请求数进行记录还会记录每个请求的时间点。
比如每秒限制三个请求:
1)当前时间窗口内,是否超过三次请求
2)是否处于下一个时间窗口?时间窗口开始滚动。第二个请求的时间变成第一位。新的时间窗口从9:00:01.50开始。
时间窗口持续滑动,流量看起来比较平稳

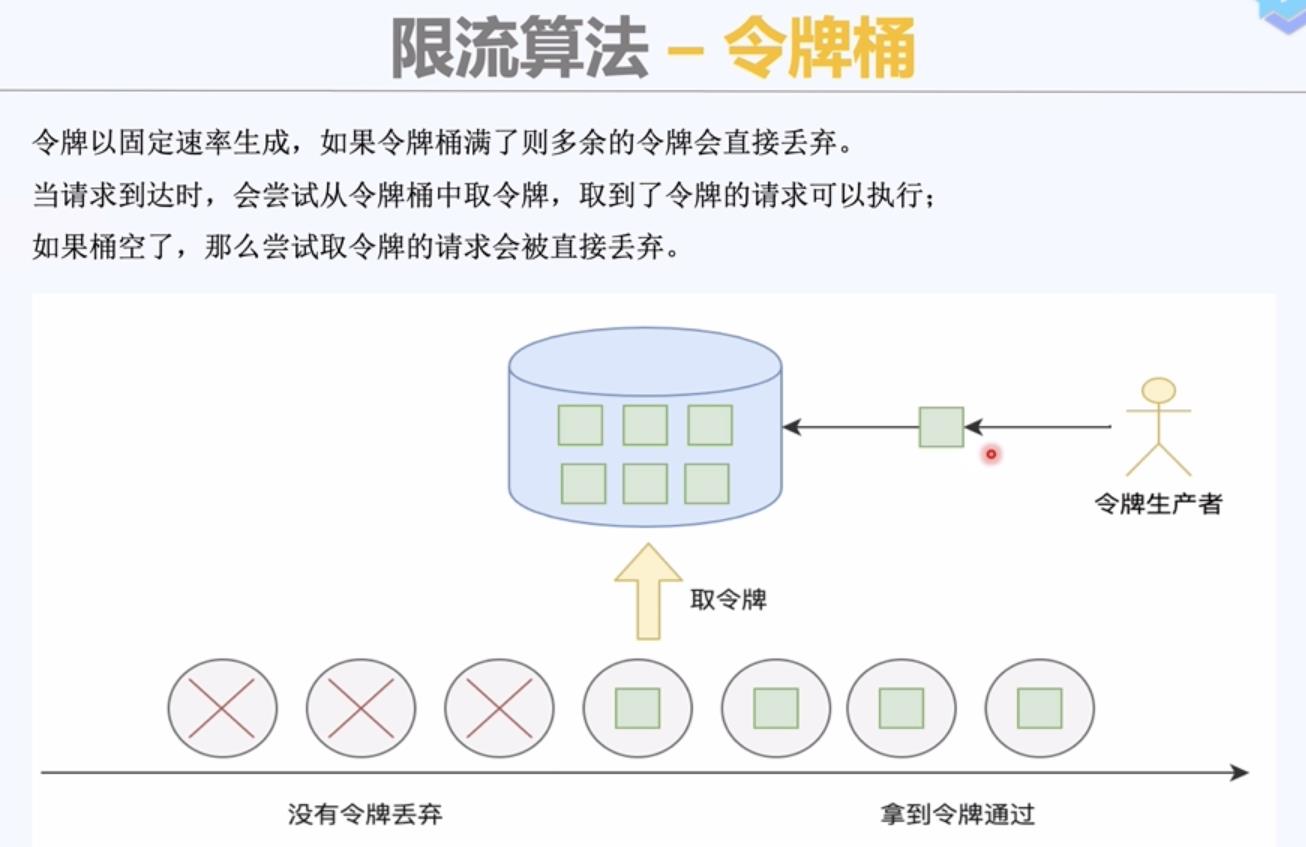
如果令牌桶空了,尝试获取令牌的请求会被丢弃(流量激增的时候)。
1)以固定速率放入令牌,直到桶满;令牌桶有容量限制
2)请求是否获取到令牌,如果获取到令牌继续执行;如果获取令牌失败,则限制请求。
不存在临界问题;比较灵活,每次可以获取一个令牌,也可以获取5个令牌。

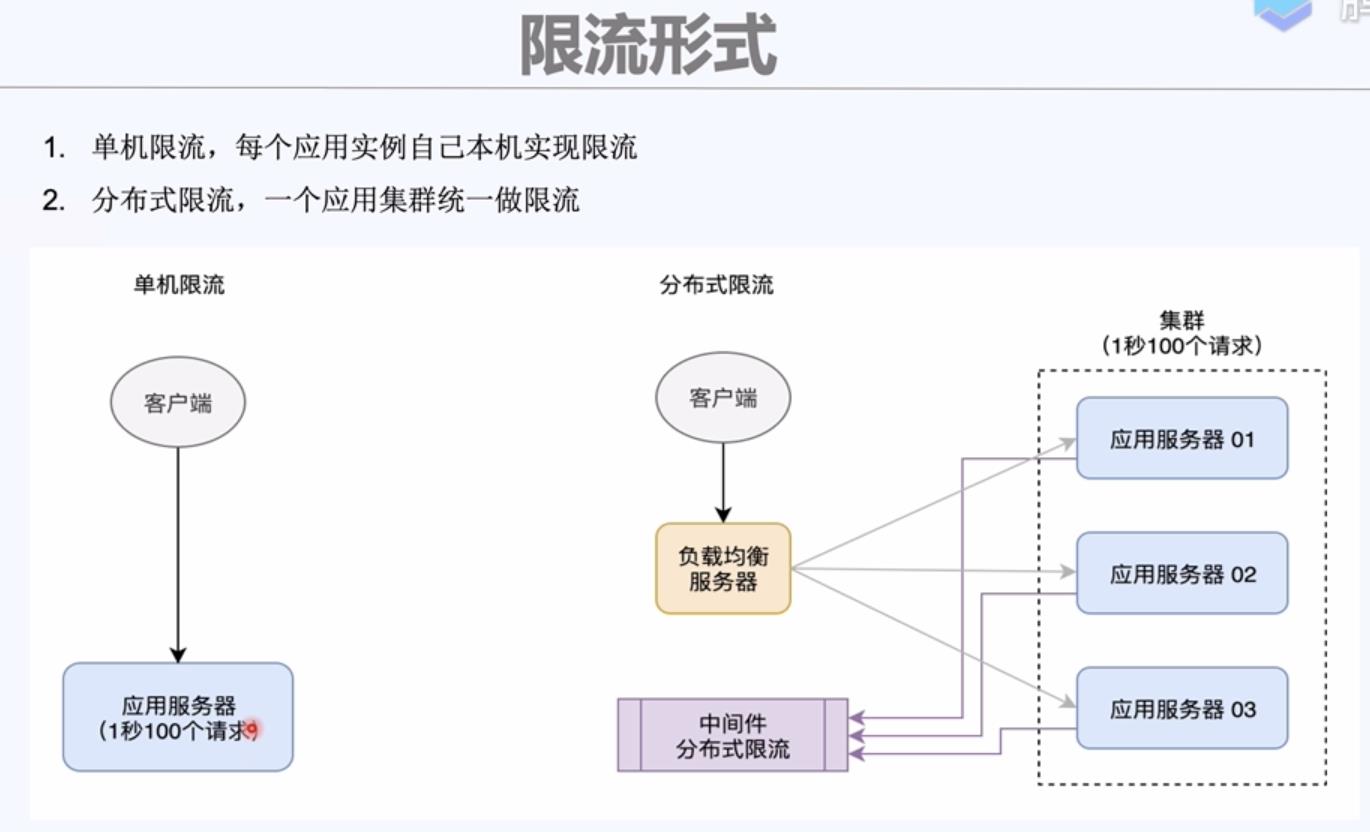
限流形式:单机限流(服务实例级别的限流),分布式限流(对集群统一限流;集群级别的限流)。
以上是关于20210616 日千万级流量架构优化策略的主要内容,如果未能解决你的问题,请参考以下文章