用Spark实现word Count实例——入门大数据实例
Posted 影月风格厂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Spark实现word Count实例——入门大数据实例相关的知识,希望对你有一定的参考价值。
参考资料:
- https://blog.csdn.net/weixin_43893397/article/details/105289992
- https://zhuanlan.zhihu.com/p/75779188
- https://blog.csdn.net/u010675669/article/details/81744386
- https://blog.csdn.net/weixin_43924642/article/details/89388432
首先将需要的input文件本地传至HDFS上(本次程序输入为words.txt)
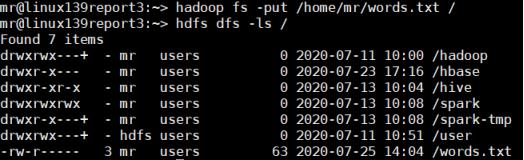
- 用spark-shell直接执行
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
即可看到结果。(PS:注意路径都是HDFS路径)
以下这些是别人的写法,我这运行不了,卡死。
sc.textFile("hdfs://linux139report3:7077/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
另外sc.textFile的路径默认是HDFS路径,也可以用本地路径(测试通过,但有warning)
sc.textFile("file://home/mr/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
也可以指定HDFS路径,测试通过
sc.textFile("hdfs:///words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
可以将结果输出到HDFS中
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out")
运行之后在HDFS中的/out看到计算结果
2、在本地IDEA上编写程序,打包到集群上运行
准备好版本
IDEA 2019.3
Scala插件scala-intellij-bin-2019.3.23.zip(不太清楚有没有用,但我装了)
ScalaSDK 2.11.8(https://www.scala-lang.org/download/2.11.8.html)
安装过程可参考
https://blog.csdn.net/u013973379/article/details/82826034
(以下是我的安装过程)
下载Scala插件并安装(我无法在线自动安装,官网上下载下来手动安装了,结果如下)
建立项目文件
修改pom.xml
一般来说,这两项我们是必须加上的
<properties>
<spark.version>2.2.1</spark.version>
<scala.version>2.11.8</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</dependency><properties>
<spark.version>2.2.1</spark.version>
<scala.version>2.11.8</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</depen
编(fu)写(zhi)Scala程序
打包找到共两种方法:
第一种(经过第一二步之后就有左边的jar包)
第二种(我选这种):
file->Project Structure->Artifacts
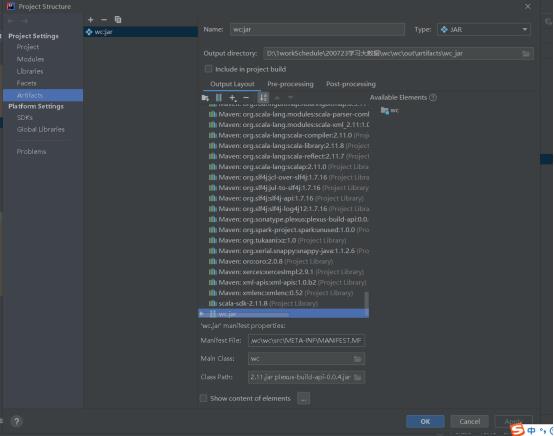
一定要注意wc.jar的包中,Manifest File路径和Main Class要正确。
之后build即可,Build->Build Artifacts->wc.jar->build
打包时候一定要注意,这个问题坑爹啊!
https://www.cnblogs.com/chenjfblog/p/10166331.html
打包时候出现Error: Error compiling the sbt component
https://blog.csdn.net/weixin_45793819/article/details/107243819
打包好之后,我们在路径中找到jar包,打开jar取出其中的wc.jar(我们只需要这个即可,其余是依赖包)
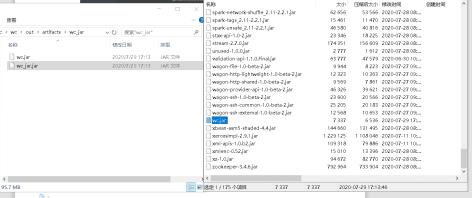
在装有spark的node上执行:
(PS:每个换行是一个空格,拉成一行执行)
spark-submit
--class wordcount
--master spark://linux139report3:7077
--executor-memory 1G
--total-executor-cores 2
/home/mr/wc.jar
/words.txt
/out10000
spark-submit
--class [classname]
--master spark://[nodename]:7077
--executor-memory [source size]
--total-executor-cores [core number]
/home/mr/wc.jar [local path:jar name]
/words.txt [HDFS path+file name]
/out10000 [HDFS path/output path]
最后,执行成功之后,查看结果文件/out10000,里面就已经是计算结果了,可能存在多个文件里面。
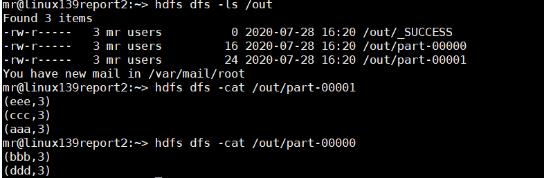
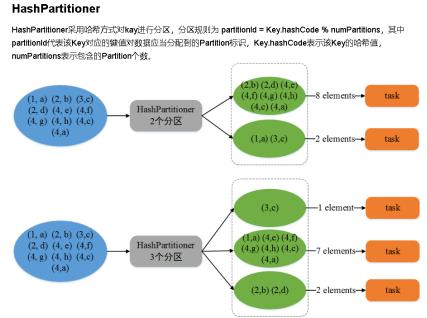
那究竟为何输出是两个文件呢??我这给出我的想法
如果采用的是HashPartitioner分区方法则会根据Key值进行分区,Key一样的可能分到一个分区了。(PS:真的不太确定)
以上是关于用Spark实现word Count实例——入门大数据实例的主要内容,如果未能解决你的问题,请参考以下文章