文献阅读18期:Learning Convolutional Neural Networks for Graphs
Posted RaZLeon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读18期:Learning Convolutional Neural Networks for Graphs相关的知识,希望对你有一定的参考价值。
[ 文献阅读·图神经网络 ] Learning Convolutional Neural Networks for Graphs [1]
推荐理由:本文考虑两个问题,一是训练一个可以用于未知图的函数,让未知图可以有效进行分类和回归问题求解。二是用于对未知图的特性进行预测(如点或边的缺失)。
1.摘要&简介
- 本文的目的在于建立一种用于表达有向图或无向图的框架。
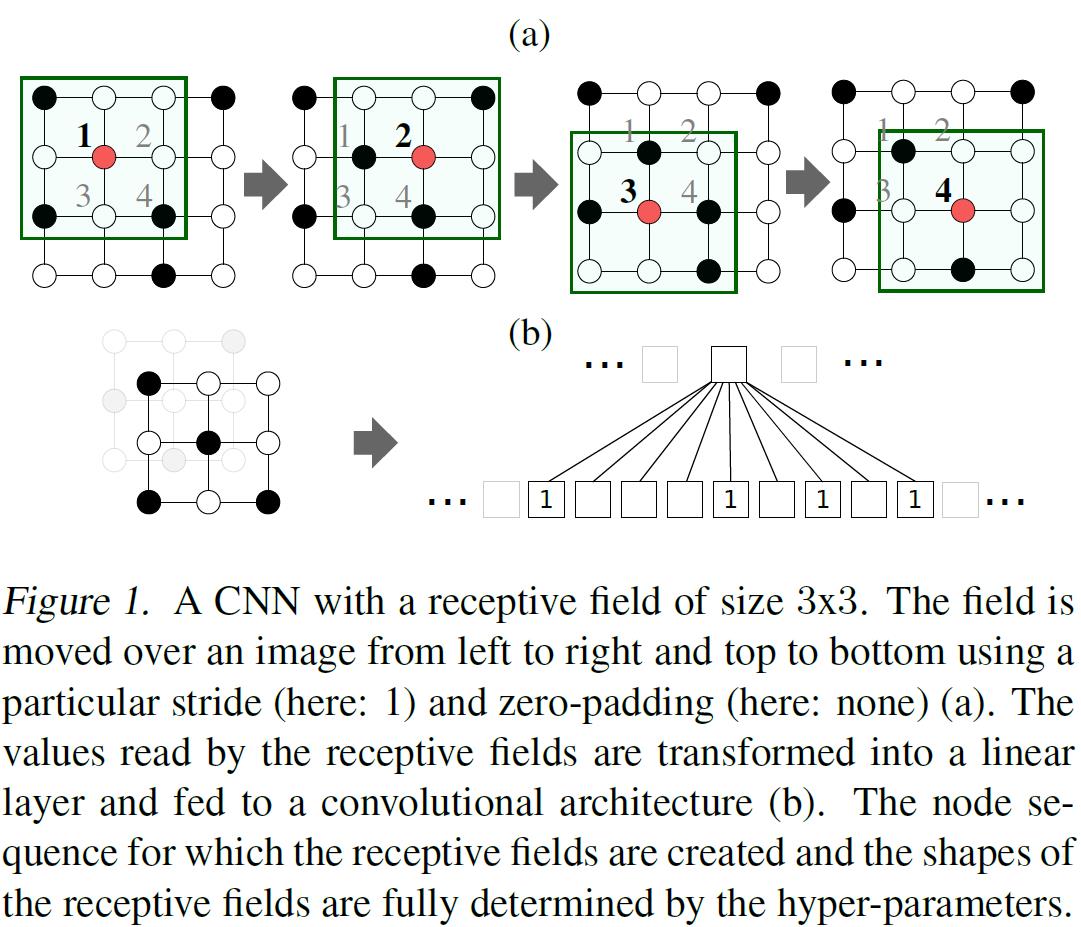
- 如果要理解图神经网络的卷积,那就得先理解传统的卷积神经网络CNN。如图1所示,从图卷积的角度去看,CNN就像是一个遍历所有节点,然后固定每个点近邻数量的图神经网络(每个像素节点固定有8个近邻,这效率高么?似乎不高。):
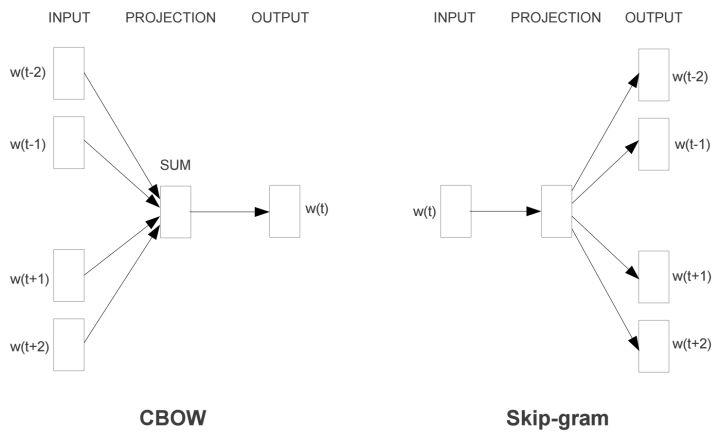
- 在NLP当中同样有类似的问题,比如Skip-Gram和Cbow的窗口一旦固定,预测的信息来源也只有前后两个近邻:
- 但有没有考虑过这样一个问题,在图像识别的过程中,人眼、鼻、口的位置关系基本是差不多的,但在像素点上,他们距离太远,在像素序列上距离更远,举个例子,眼睛的一个像素点,周围的像素可能只有眼睛和皮肤,除非一个人五官挤在一起,那几乎不可能在眼睛像素点的近邻中出现鼻子的像素点。
- 这种隐形关系的缺失,导致了图信息的缺失。
- 在NLP问题中,这样的Graph信息缺失同样也很严重,比如:“我今天忘记带猫咪去打疫苗了。”在这句话中“我”和“猫咪”是主人和宠物的关系,但如果窗口大小为前后各2,那“我”字能“看见”的前后信息,只有“今天”和“忘记”,则主人和宠物这种人类看似很直觉的联系,就被排除在语义之外。(这个例子其实很粗,博主自己想的,大家近似理解一下就好)
- 所以,图卷积这种“近邻数量自由”、“关系表达丰富”、“节点通信自由”的数据结构就能够从一定程度上解决隐形信息缺失的问题。
- 本文提出的方法名叫PATCHY-SAN,力求解决以下两个问题:
- 确定一种或多种节点序列,并用它们创建邻域图;
- 计算邻域图的归一化,即,从图表示到向量空间表示的唯一映射。
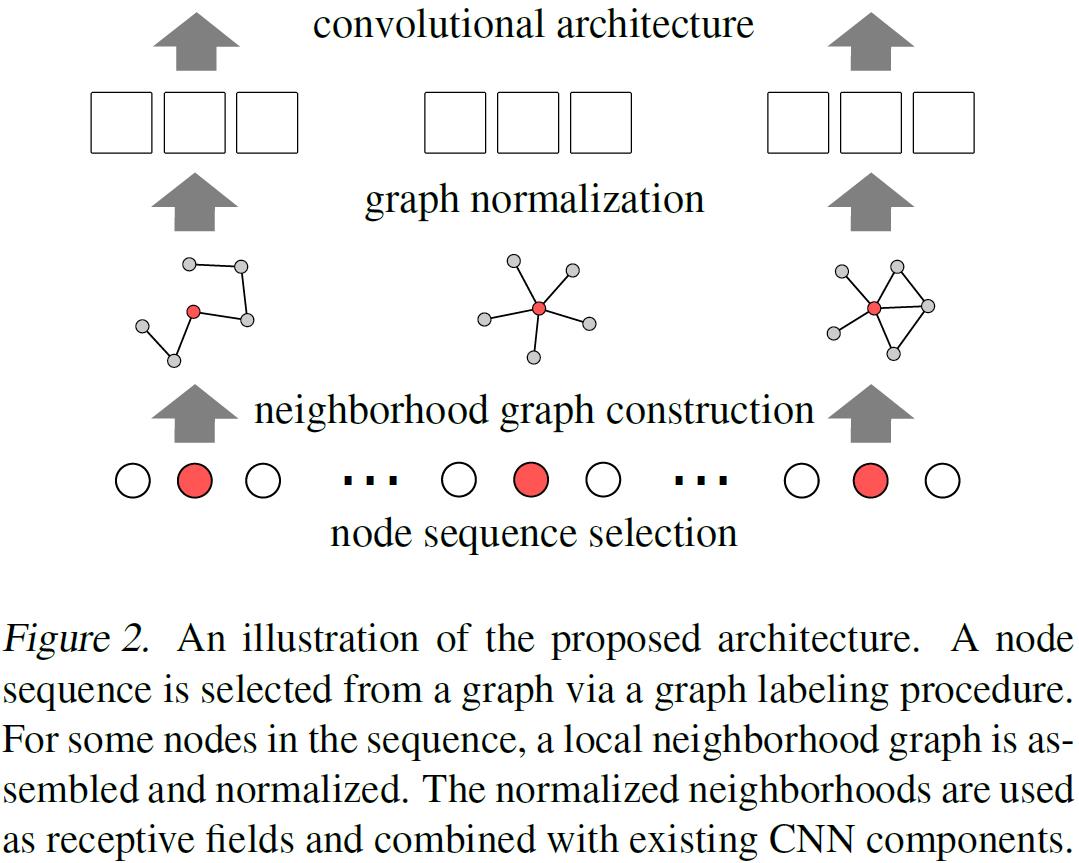
- 图2展示了PATCHY-SAN的结构:
2.PATCHY-SAN的相关概念
- 标记:本文定义了一个函数 ℓ \\ell ℓ用于节点的rank排序,也就是说将所有的节点映射为一个序列 V → S V \\rightarrow S V→S,当 ℓ ( u ) > ℓ ( v ) \\ell(u)>\\ell(v) ℓ(u)>ℓ(v)时rank有 r ( u ) < r ( v ) \\mathbf{r}(u)<\\mathbf{r}(v) r(u)<r(v)。
- 分区:由此,每个图G会得到一个新的邻接矩阵 A ℓ ( G ) \\mathbf{A}^{\\ell}(G) Aℓ(G),这其中每个节点的位置其实就是rank后的位置,近邻关系也是rank里的前后关系,而且每个同等级的节点还会被分到同一个区里去,这样就构成了多个节点的分区 { V 1 , … , V n } \\left\\{V_{1}, \\ldots, V_{n}\\right\\} {V1,…,Vn}。
- 同构和规范化:为了对比两个图,自然还要考虑同构和规范化的问题。
3.实施PATCHY-SAN
- 实施图卷积,首先需要解决CNN没有解决的两个问题:
- 确定一种节点序列,并用它们创建邻域图;
- 确定从图表示到向量表示的唯一映射,使得邻域图中具有相似结构角色的节点在向量表示中的位置相似。
- 为了解决这两个问题PATCHY-SAN进行了如下4个步骤的工作:
- 从图中选择固定长度的节点序列;
- 为所选序列中的每个节点确定一个定大小的邻域;
- 对提取的邻域图进行归一化处理;
- 从得到的序列中学习卷积神经网络的邻域表示
- 下面分四个部分对这四个步骤进行详细讨论。
3.1.节点序列的挑选
- 节点序列选择是为每个输入图形确定一个节点序列的过程,为该节点序列创建感受野。如算法1所示:


- 算法1列出了一个这样的过程:
- 输入图的顶点根据给定的图进行排序。
- 使用给定的步幅s遍历得到的节点序列,并且对于每个被访问的节点,执行算法3来构造感受野,直到创建了正好w个感受野。
- 步幅s确定了在为其创建感受野的大小。如果感受野的节点数小于w,则该算法将以0填充作为补充感受野。
(感受野可以直观理解为卷积核框定的9个像素,只不过在图卷积中被重新标定了顺序。)
3.2.设置序列近邻

- 算法3首先调用算法2为输入节点组装一个局部邻域。
- 邻域的节点是感受野的候选节点。
- 算法2列出了邻域集合的步骤:
- 给定一个节点v和感受野k的大小作为输入,该过程执行广度优先搜索,搜索距离v越来越远的顶点,并将这些顶点添加到集合N中。
- 如果收集的节点数小于k,则收集最近添加到N的顶点的距离为1的点,依此类推,直到至少k个顶点在N中,或者直到没有更多的邻居可添加。此时,N的大小可能与k不同。
3.3.图标准化
- 一个节点的感受野是通过对前一步集合的邻域进行归一化来构造的。
- 如图3所示,规范化对邻域图的节点施加一个顺序,以便从无序的图空间映射到线性顺序的向量空间:
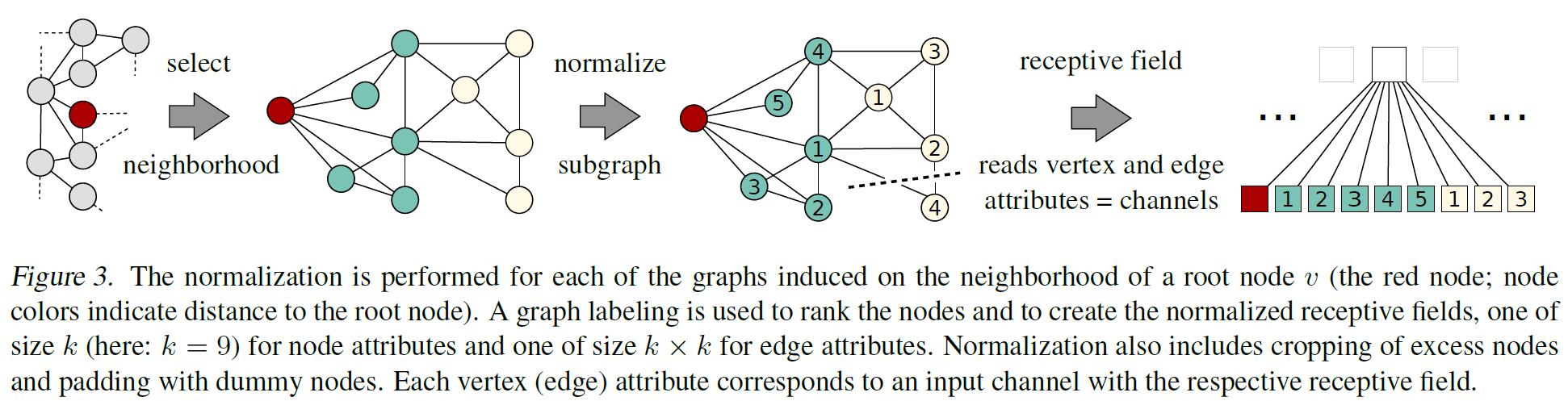
其基本思想是利用图标记过程,当且仅当两个不同图在图中的结构角色相似时,将两个不同图的节点分配到相应邻接矩阵中相似的相对位置。 - labeling,也就是给编号,看上去简单,实际上是一件相当复杂的事情。下面就深入到大家最关心的编号(标记)问题: ℓ \\ell ℓ函数的创建。
- 令
d
G
\\mathrm{d}_{\\mathrm{G}}
dG代表两个含有k个节点的图的距离,
d
A
\\mathbf{d}_{\\mathbf{A}}
dA代表两个k*k矩阵的距离,则
ℓ
^
\\hat{\\ell}
ℓ^可以表达为:
ℓ ^ = arg min ℓ E G [ ∣ d A ( A ℓ ( G ) , A ℓ ( G ′ ) ) − d G ( G , G ′ ) ∣ ] \\hat{\\ell}=\\underset{\\ell}{\\arg \\min } \\mathbb{E}_{\\mathcal{G}}\\left[\\left|\\mathbf{d}_{\\mathbf{A}}\\left(\\mathbf{A}^{\\ell}(G), \\mathbf{A}^{\\ell}\\left(G^{\\prime}\\right)\\right)-\\mathbf{d}_{\\mathbf{G}}\\left(G, G^{\\prime}\\right)\\right|\\right] ℓ^=ℓargminEG[∣∣dA(Aℓ(G),Aℓ(G′))−dG(G,G′)∣∣]
从式子里可以看出,要找到一系列编号,使得多个图之间的距离期望尽量的小,最后得到的编号就是图3当中的编号(妙啊!)。
3.4.卷积工作
- 最后的卷积工作其实就很简单啦,把捣鼓好的图图扔进网络,炼丹就大功告成啦!撒花!
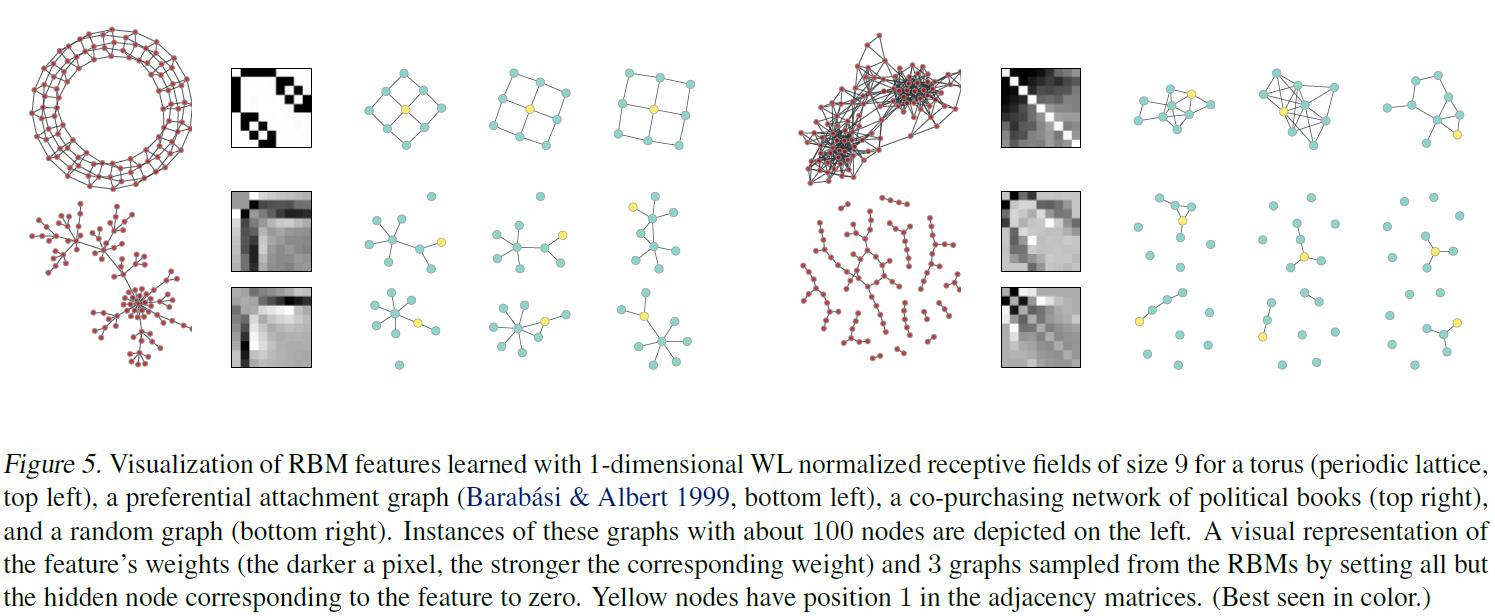
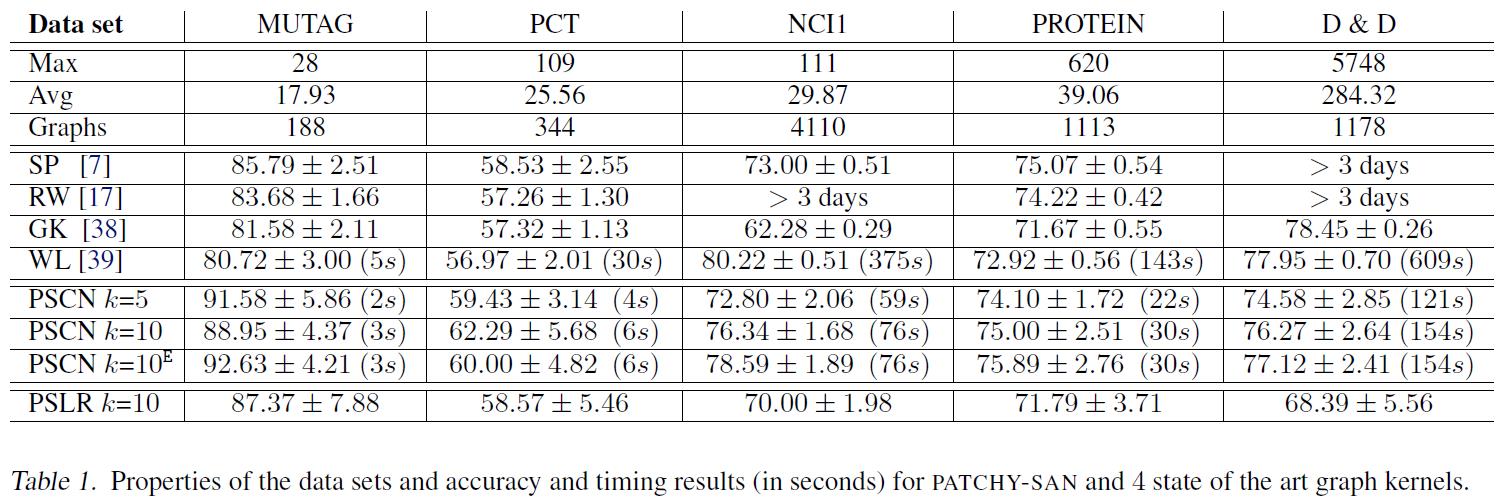
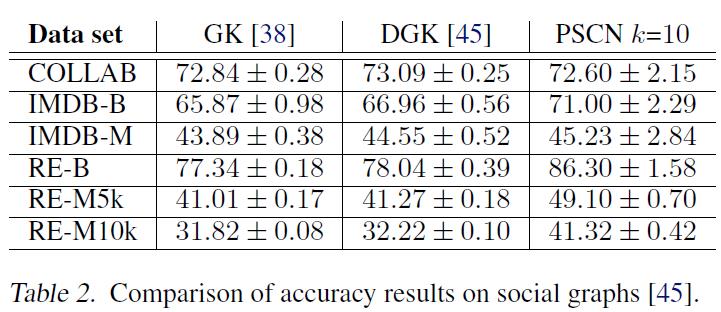
4.论文实验
参考文献
[1] Niepert M, Ahmed M, Kutzkov K. Learning convolutional neural networks for graphs[C]//International conference on machine learning. PMLR, 2016: 2014-2023.
以上是关于文献阅读18期:Learning Convolutional Neural Networks for Graphs的主要内容,如果未能解决你的问题,请参考以下文章
文献阅读18期:Learning Convolutional Neural Networks for Graphs
文献阅读17期:Deep Learning on Graphs: A Survey - 6
文献阅读16期:Deep Learning on Graphs: A Survey - 5
文献阅读12期:Deep Learning on Graphs: A Survey - 1