分布式追踪系统总结
Posted 归田
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式追踪系统总结相关的知识,希望对你有一定的参考价值。
一、背景
随着互联网架构的扩张,分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、消息收发、分布式数据库、分布式缓存、分布式对象存储、跨域调用,这些组件共同构成了繁杂的分布式网络,那现在的问题是一个请求经过了这些服务后其中出现了一个调用失败的问题,只知道有异常,但具体的异常在哪个服务引起的就需要进入每一个服务里面看日志,这样的处理效率是非常低的。
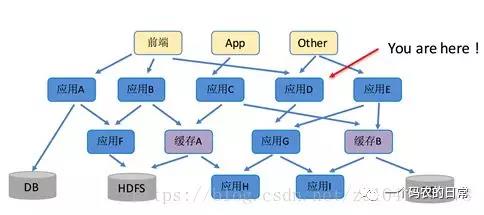
分布式调用链其实就是将一次分布式请求还原成调用链路。显式的在后端查看一次分布式请求的调用情况,比如各个节点上的耗时、请求具体打到了哪台机器上、每个服务节点的请求状态等等。
二、常见分布式调用链系统
- Google Drapper
- 阿里巴巴 鹰眼
- 美团 CAT
- 京东 Pfinder
- Twitter Zipkin
- PinPoint
- Sky Walking
三、可以解决的问题
1、故障快速定位
通过调用链跟踪,一次请求的逻辑轨迹可以用完整清晰的展示出来。开发中可以在业务日志中添加调用链ID,可以通过调用链结合业务日志快速定位错误信息。
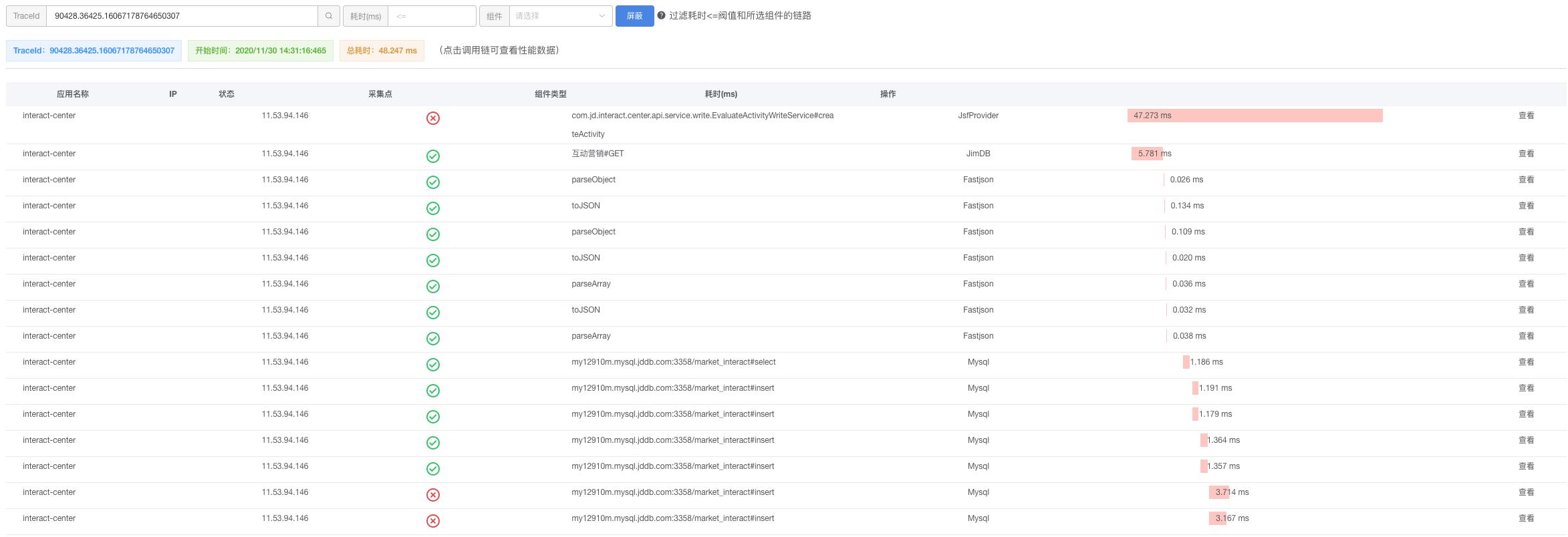
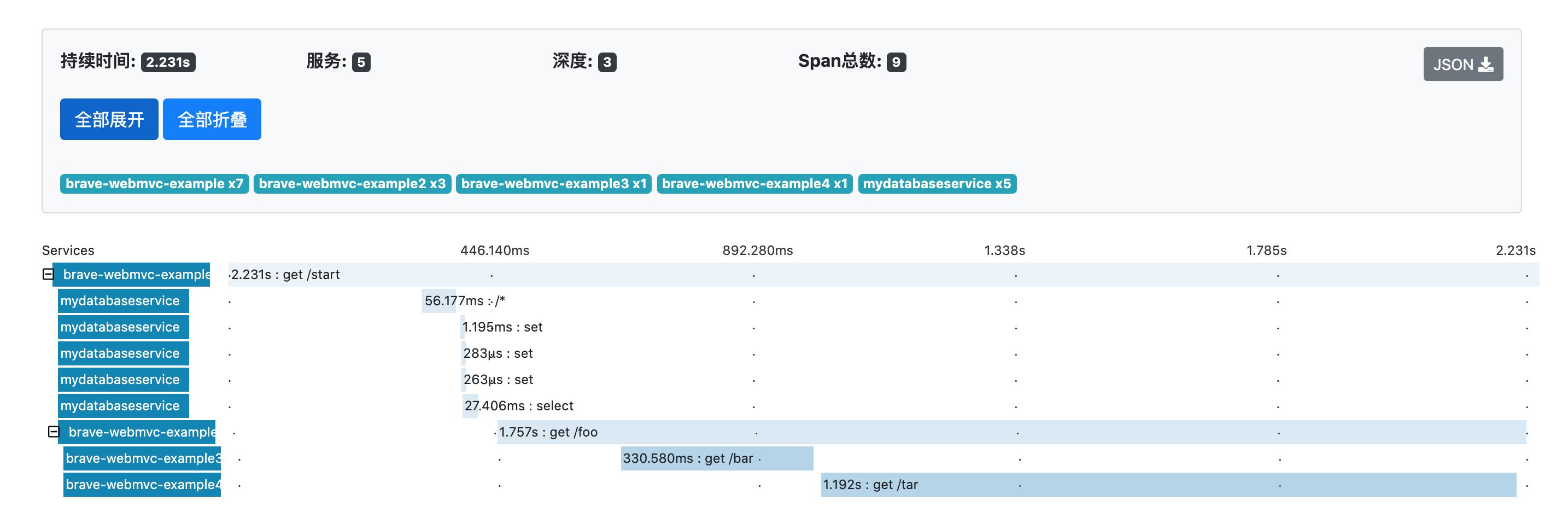
2、各个调用环节的性能分析
在调用链的各个环节分别添加调用时延,可以分析系统的性能瓶颈,进行针对性的优化。通过分析各个环节的平均时延,QPS等信息,可以找到系统的薄弱环节,对一些模块做调整,如数据冗余等。
3、数据分析等
调用链绑定业务后查看具体每条业务数据对应的链路问题,可以得到用户的行为路径,经过了哪些服务器上的哪个服务,汇总分析应用在很多业务场景。
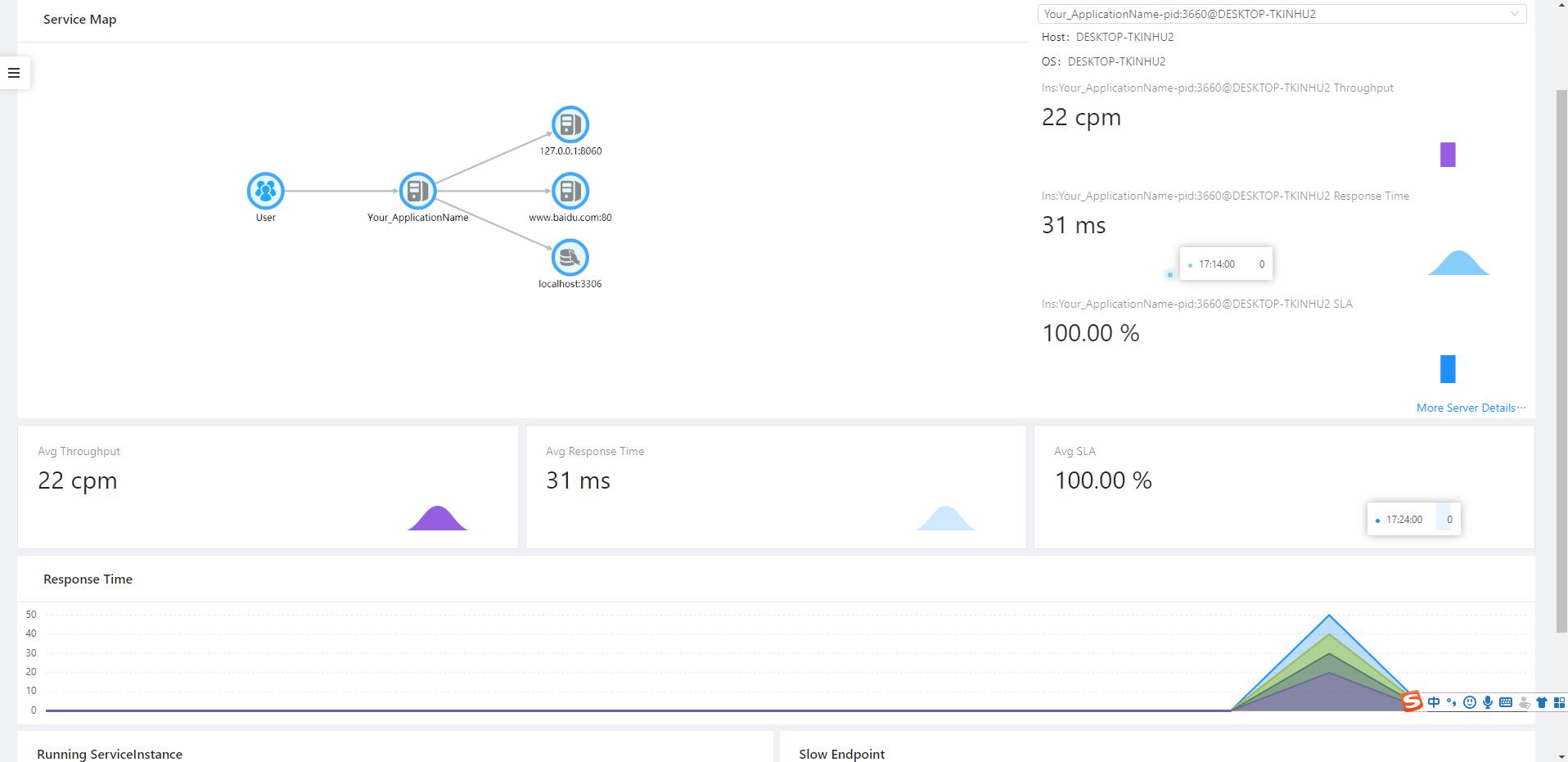
4、生成服务调用拓扑图
通过可视化分布式系统的模块和他们之间的相互联系来理解系统拓扑。点击某个节点会展示这个模块的详情,比如它当前的状态和请求数量。
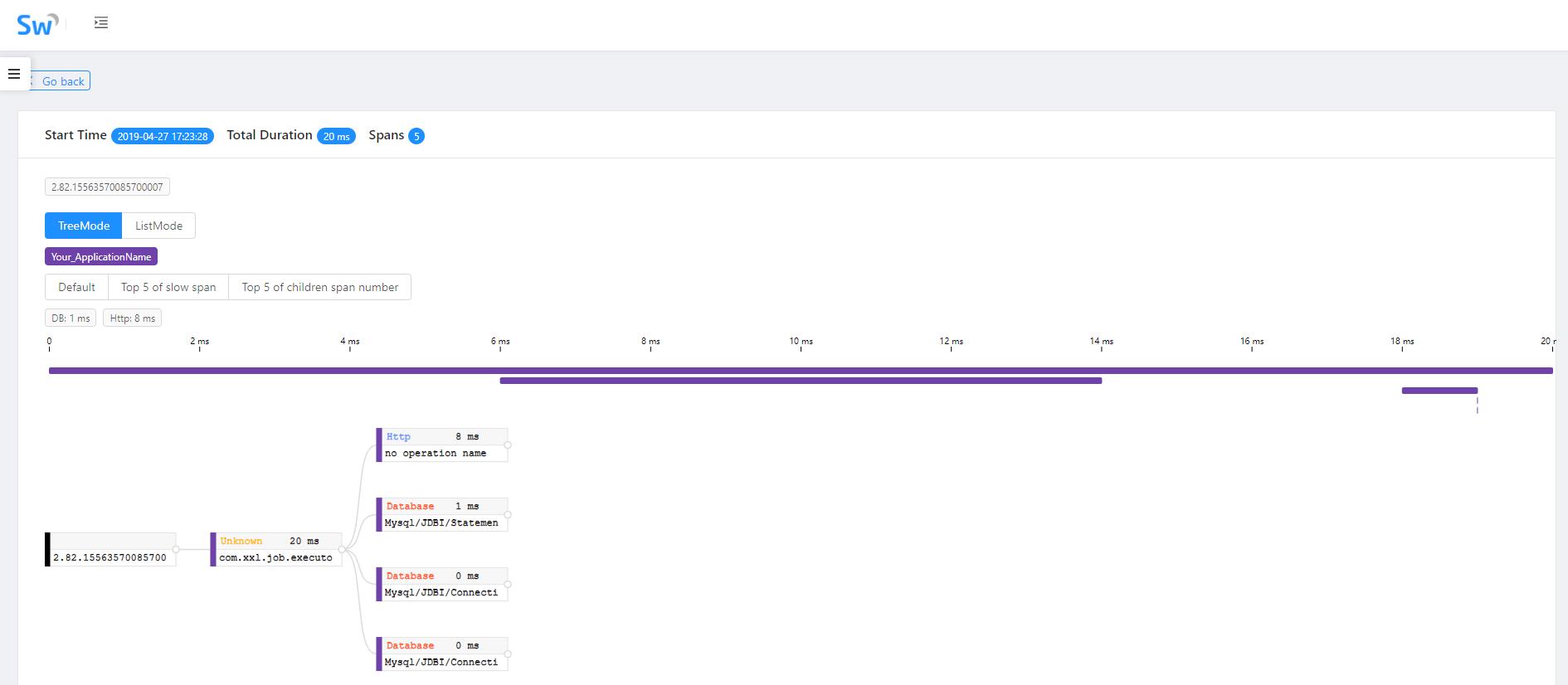
四、分布式调用跟踪系统的设计
(1)分布式调用跟踪系统的设计目标
低侵入性,应用透明:作为非业务组件,应当尽可能少侵入或者无侵入其他业务系统,对于使用方透明,减少开发人员的负担
低损耗:服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径
大范围部署,扩展性:作为分布式系统的组件之一,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性
(2)埋点和生成日志
埋点即系统在当前节点的上下文信息,可以分为客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。埋点日志通常要包含以下内容:
TraceId、RPCId、调用的开始时间,调用类型,协议类型,调用方ip和端口,请求的服务名等信息;
调用耗时,调用结果,异常信息,消息报文等;
预留可扩展字段,为下一步扩展做准备;
(3)抓取和存储日志
日志的采集和存储有许多开源的工具可以选择,一般来说,会使用离线+实时的方式去存储日志,主要是分布式日志采集的方式。典型的解决方案如Flume结合Kafka等MQ。
(4)分析和统计调用链数据
一条调用链的日志散落在调用经过的各个服务器上,首先需要按 TraceId 汇总日志,然后按照RpcId 对调用链进行顺序整理。用链数据不要求百分之百准确,可以允许中间的部分日志丢失。
(5)计算和展示
汇总得到各个应用节点的调用链日志后,可以针对性的对各个业务线进行分析。需要对具体日志进行整理,进一步储存在HBase或者关系型数据库中,可以进行可视化的查询。
五、链路跟踪Trace模型
一次典型的分布式调用过程,如下图所示:
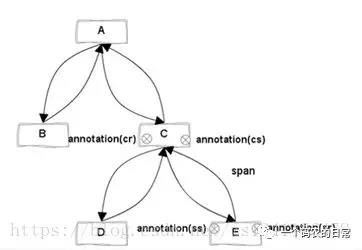
Trace调用模型,主要有以下概念:
Trace:一次完整的分布式调用跟踪链路。
Span: 追踪服务调基本结构,表示跨服务的一次调用; 多span形成树形结构,组合成一次Trace追踪记录。
Annotation:在span中的标注点,记录整个span时间段内发生的事件。
BinaryAnnotation:可以认为是特殊的Annotation,用户自定义事件。
Annotation类型:保留类型
Cs CLIENT_SEND,客户端发起请求
Cr CLIENT_RECIEVE,客户端收到响应
Sr SERVER_RECIEVE,服务端收到请求
Ss SERVER_SEND,服务端发送结果
六、 分布式调用链系统对比
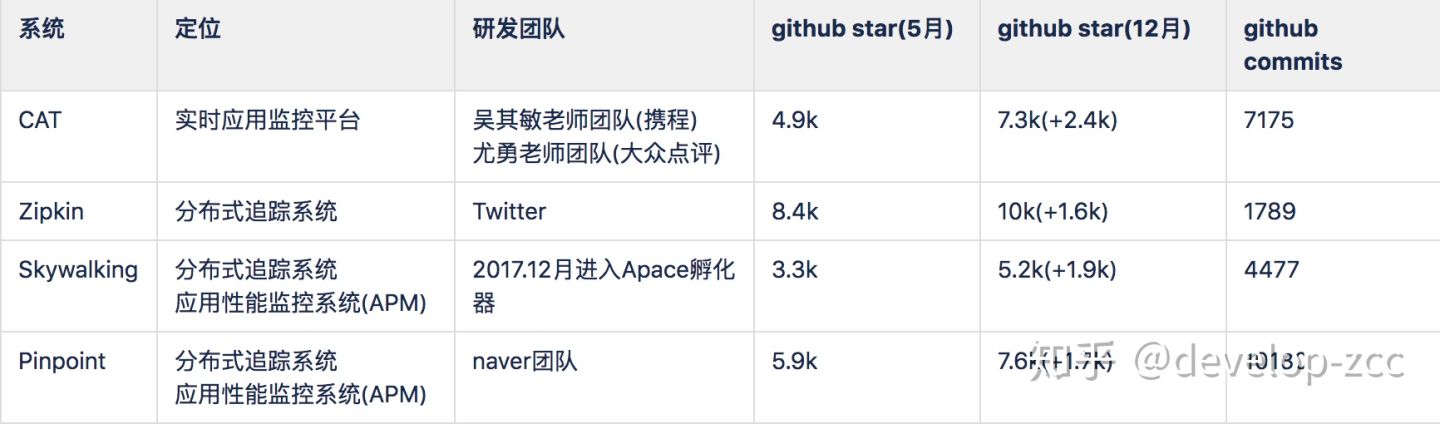
1、基本信息
-
CAT是一个更综合性的平台,提供的监控功能最全面,国内几个大厂生产也都在使用。但研发进度及版本更新相对较慢。
-
Zipkin由Twitter开源,调用链分析工具,基于spring-cloud-sleuth得到广泛使用,非常轻量,使用部署简单。
-
Skywalking专注于链路和性能监控,国产开源,埋点无侵入,UI功能较强。能够加入Apache孵化器,设计思想及代码得到一定认可,后期应该也会有更多的发展空间及研发人员投入。目前使用厂商最多。版本更新较快。
-
Pinpoint专注于链路和性能监控,韩国研发团队开源,埋点无侵入,UI功能较强,但毕竟是小团队,不知道会不会一直维护着,目前版本仍在更新中
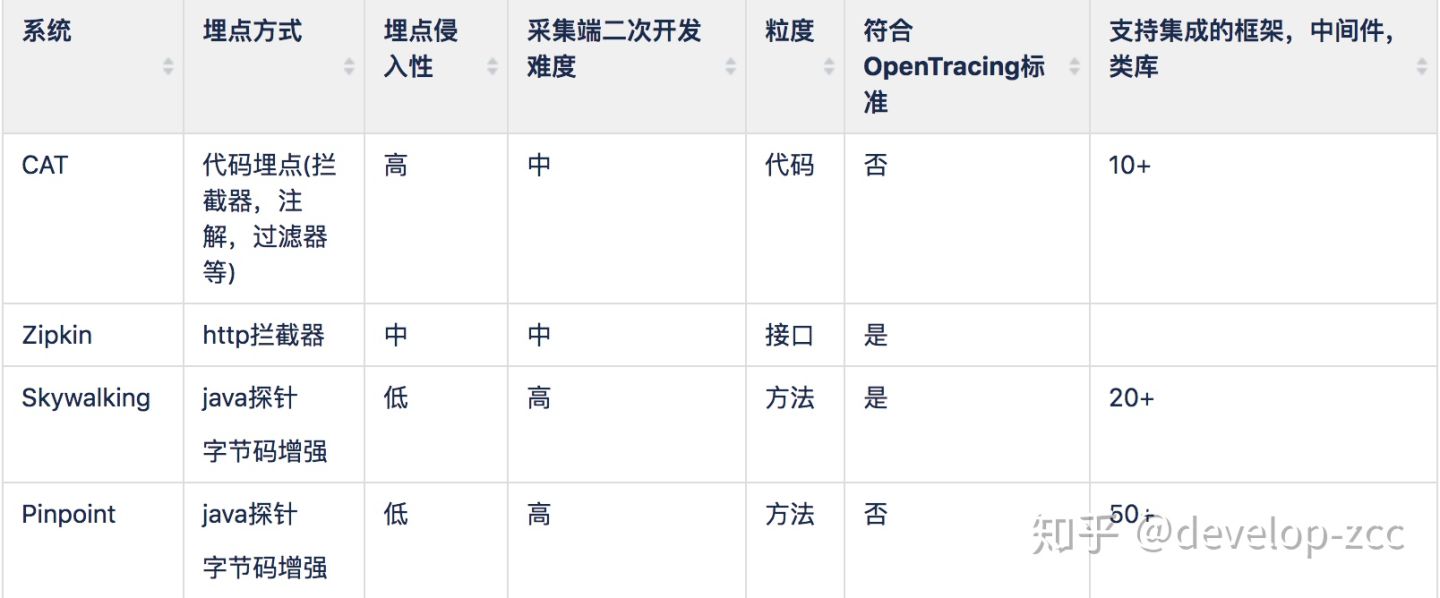
2、埋点方式
-
无侵入方式的埋点对于业务方更透明,接入更便捷,但技术要求高,客户端的二次开发有一定门槛。
-
这几种方式对于各框架,中间件都要由相应的支持,以及同一组件不同版本的支持,由此带来的业务方更新成本无侵入方式肯定更低。
-
CAT虽然能做到代码级粒度,但需要侵入业务代码,增加了业务开发复杂度。
-
OpenTracing标准来自CNCF,对于后面CNCF旗下的产品数据兼容性更强。值得注意的是,Skywalking已经支持istio探针。
-
使用字节码增强技术对于技术升级切换成本较小,只需启动命令修改下。
3、埋点数据传输及性能
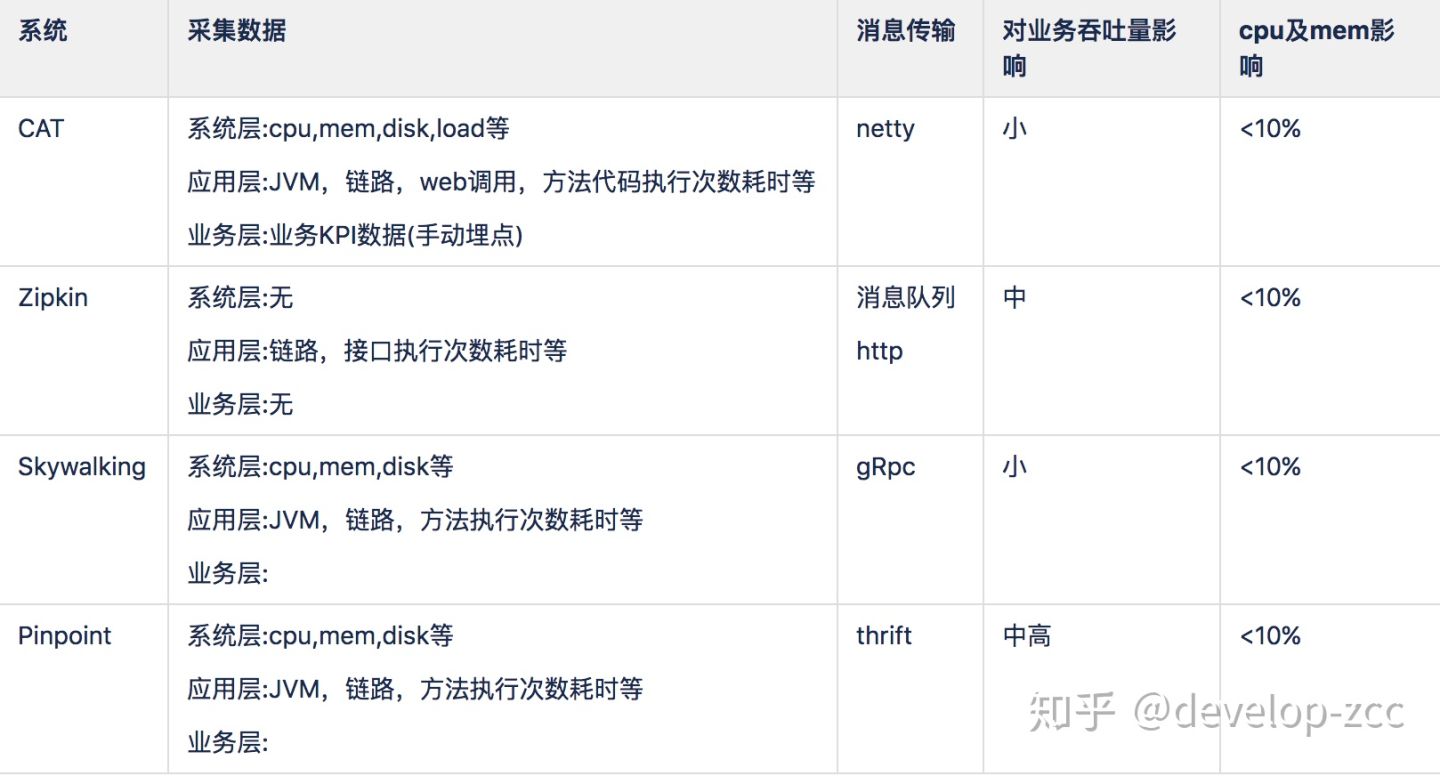
-
除了zipkin采集数据较单一,其他组件采集数据差不多
-
网络传输上消息队列应该优于其他,因为在大数据量场景下,消息中间件能够缓冲客户端与服务端吞吐量不平衡的情况,同时实时数据的分流处理,共享更灵活。其他方式要么将数据持久化到本地,要么占用大量内存,要么直接丢弃。
-
性能影响上Pinpoint相对于其他相对更大
-
cpu和mem影响都在10%的可接受范围内
4、数据存储
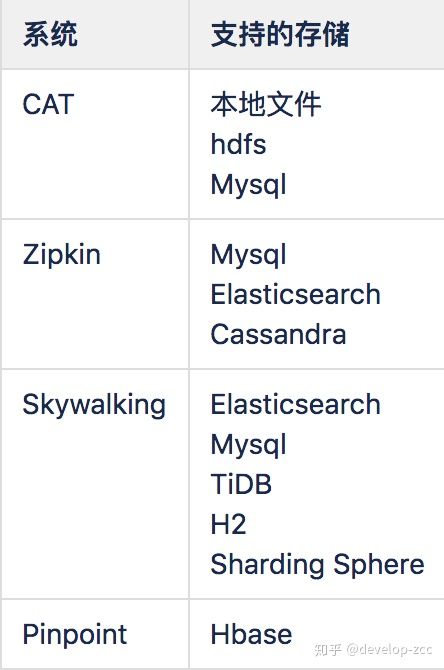
-
CAT的数据存储选型较落后,无法适应目前大数据量的查询,特别是一些精确查询
-
Pinpoint选择Hbase存储,局限于Hbase基于rowkey查询的限制,对于非rowkey字段的查询不支持
-
目前看来Elasticsearch是作为实时查询,时序查询比较好的一个选择,时间较长的重要历史数据可考虑同步到hive中。同时支持Elasticsearch作为数据源的开源报表工具也很多,如kibana,grafana等
5、支持中间件
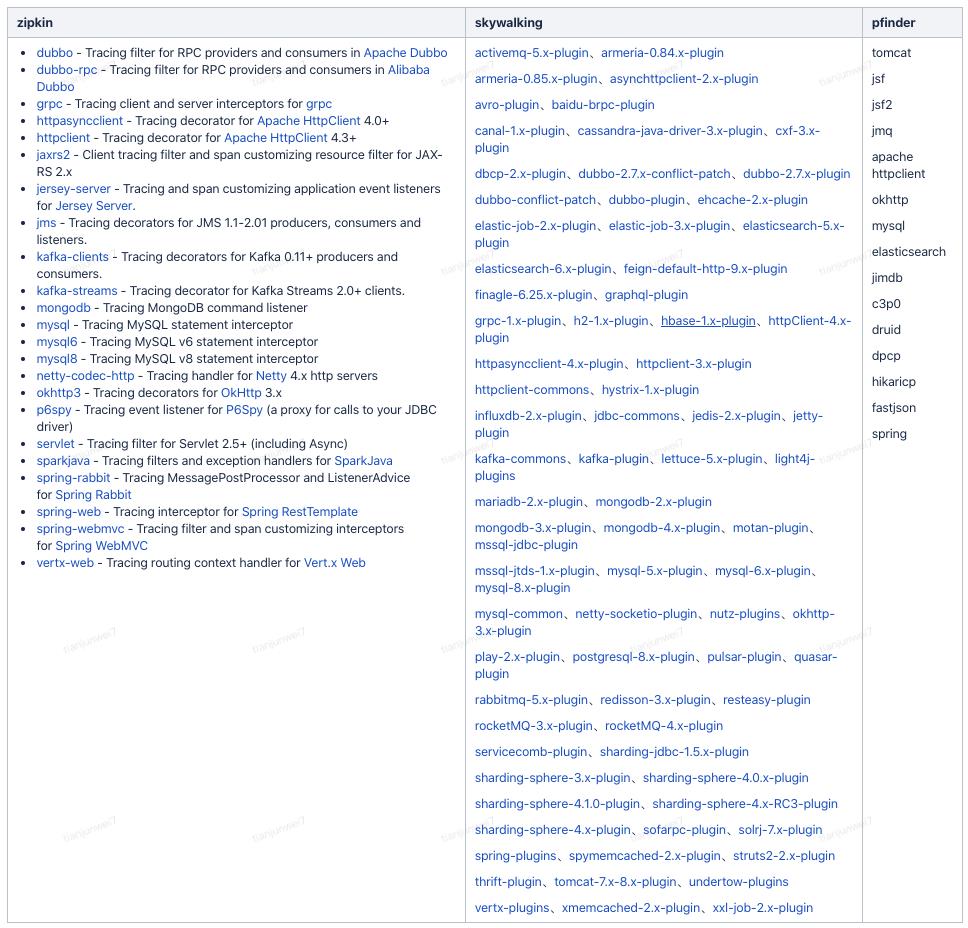
6、插件实现示例
(1)zipkin 针对 spring MVC 追踪,通过 SpringMVC 的拦截器实现
public final class SpanCustomizingAsyncHandlerInterceptor extends HandlerInterceptorAdapter {
@Autowired(
required = false
)
HandlerParser handlerParser = new HandlerParser();
SpanCustomizingAsyncHandlerInterceptor() {
}
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object o) {
SpanCustomizer span = (SpanCustomizer)request.getAttribute(SpanCustomizer.class.getName());
if (span != null) {
this.handlerParser.preHandle(request, o, span);
}
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
SpanCustomizer span = (SpanCustomizer)request.getAttribute(SpanCustomizer.class.getName());
if (span != null) {
SpanCustomizingHandlerInterceptor.setHttpRouteAttribute(request);
}
}
}
(2)skywalking 实现示例,针对 Controller 的实现类中 RequestMapping 注解进行拦截处理
public class ControllerInstrumentation extends AbstractSpring3Instrumentation {
public static final String CONTROLLER_ENHANCE_ANNOTATION = "org.springframework.stereotype.Controller";
public static final String CONSTRUCTOR_INTERCEPTOR = "org.apache.skywalking.apm.plugin.spring.mvc.v3.ControllerConstructorInterceptor";
public static final String REQUEST_MAPPING_ENHANCE_ANNOTATION = "org.springframework.web.bind.annotation.RequestMapping";
@Override
public ConstructorInterceptPoint[] getConstructorsInterceptPoints() {
return new ConstructorInterceptPoint[] {
new ConstructorInterceptPoint() {
@Override
public ElementMatcher<MethodDescription> getConstructorMatcher() {
return any();
}
@Override
public String getConstructorInterceptor() {
return CONSTRUCTOR_INTERCEPTOR;
}
}
};
}
@Override
public InstanceMethodsInterceptPoint[] getInstanceMethodsInterceptPoints() {
return new InstanceMethodsInterceptPoint[] {
new DeclaredInstanceMethodsInterceptPoint() {
@Override
public ElementMatcher<MethodDescription> getMethodsMatcher() {
return byMethodInheritanceAnnotationMatcher(named(REQUEST_MAPPING_ENHANCE_ANNOTATION));
}
@Override
public String getMethodsInterceptor() {
return REQUEST_MAPPING_METHOD_INTERCEPTOR;
}
@Override
public boolean isOverrideArgs() {
return false;
}
}
};
}
@Override
protected ClassMatch enhanceClass() {
return ClassAnnotationMatch.byClassAnnotationMatch(new String[] {CONTROLLER_ENHANCE_ANNOTATION});
}
}
以上是关于分布式追踪系统总结的主要内容,如果未能解决你的问题,请参考以下文章