围绕HugeTLB的极致优化
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了围绕HugeTLB的极致优化相关的知识,希望对你有一定的参考价值。
宋牧春,字节跳动系统技术与工程团队,Linux内核工程师。
介绍以一种创新的方式优化HugeTLB对应的struct page内存占用。
目录
相信大家对HugeTLB在虚拟化及DPDK等场景应用并不陌生,在动不动就上百GB的服务器上,轻轻松松预留上百GB HugeTLB。相信不少云厂商也注意到HugeTLB的内存管理上存在一定的问题。既然有问题,为何upstream上迟迟看不到相关的优化patch呢?
答案很简单:问题棘手。
Linux在内存管理方面已经发展了十几年,即使某些机制不够优秀,想大改也不是简单的事情。内存管理贯彻整个Linux内核,与众多子系统交互。究竟Linux在HugeTLB的管理上存在什么问题呢?
如何管理物理内存
现在Linux Kernel主要以页为单位管理内存,而页的大小默认4 KB。为了方便管理物理内存,Linux为每个页分配一个metadata结构体,即struct page结构,其大小通常64 Bytes。struct page可以简单理解成一个数组,数组的index就是PFN(物理页帧号)。我称这段区域vmemmap。
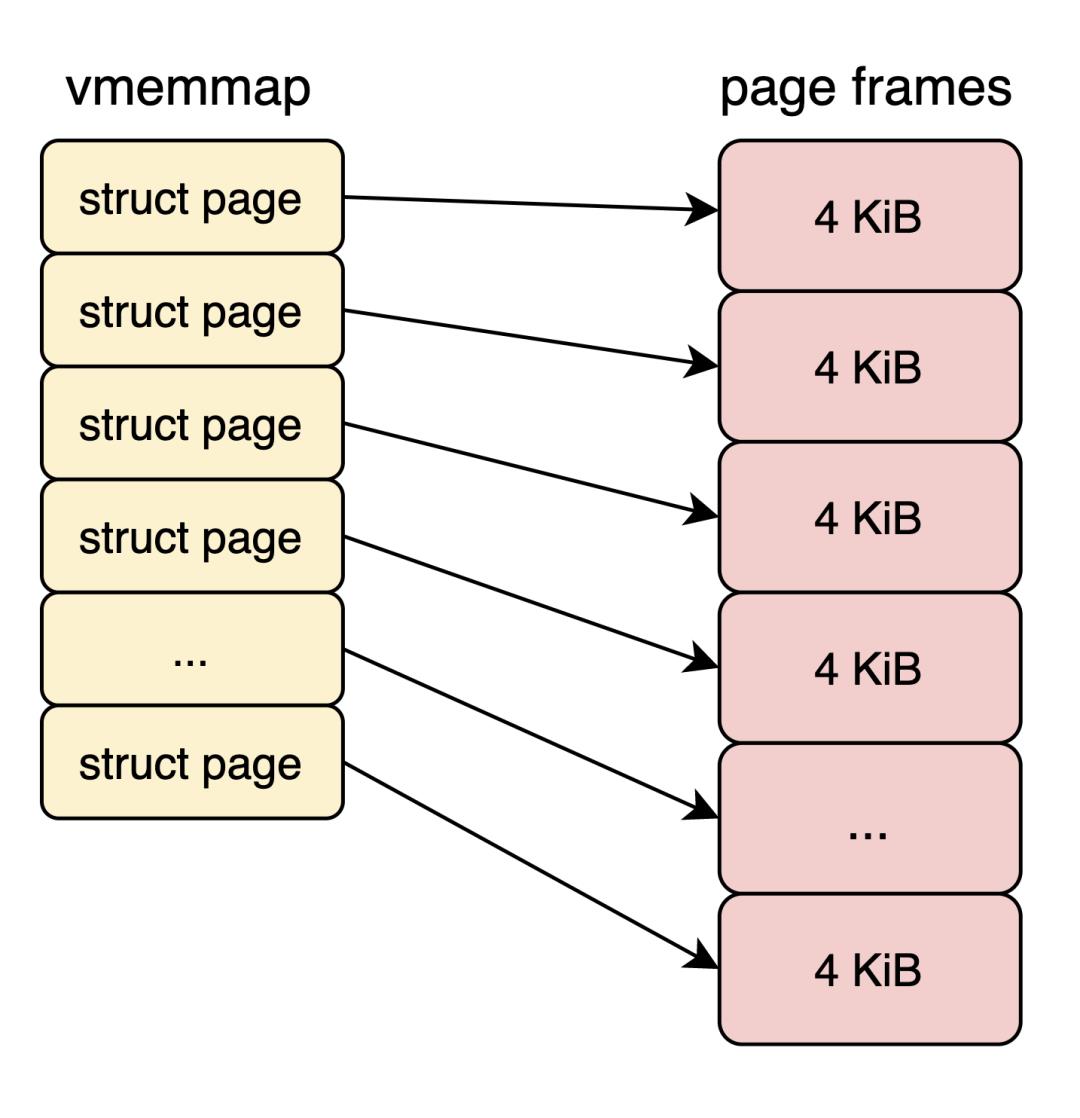
之为小页,与之相反的是大页。在x86-64平台,硬件支持2 MB和1 GB大页。Linux为了方便用户使用大页,提供2种不同的机制,分别是THP (Transparent Huge Page) 和 HugeTLB。HugeTLB经常出现在我们的工程实践中,HugeTLB为我们为我们带来不错的性能提升。
但是也有一朵乌云常伴其身。虽然2 MB的HugeTLB page理论上也只需要1个struct page结构,但是,在系统启动之初,所有的物理内存均以4 KB为单位分配struct page结构。因此每个 HugeTLB page对应 512个struct page结构,占用内存32 KB(折合8个4 KB小页)。
可能你会好奇这能有多少内存。针对嵌入式系统,确实不值一提。但是别忘了,我们有动不动就2 TB物理内存的服务器。
现在我们可以简单的算一笔账了。假设在一台1 TB的服务器上,我们分配1 TB的2 MB大页(理想情况下),那么struct page本身占用的内存是多少呢?没错,是16 GB。如果有上千台,上万台,甚至上十万台机器呢?如果我们能够优化掉16 GB的内存浪费或者尽可能的降低struct page的内存占用,我们将会降低服务器平台成本。我们的目标就是尽量驱散这朵乌云。
面临的挑战
我们试图找到一种最简单并且对其他模块影响最小的设计方案,在这过程中我们遇到不少挑战。
1. 不需要用户适配
理想情况下,我们的优化不应该涉及用户态的适配。如果引入一种全新的内存管理方式,所有的用户需要适配。我们的目标是开箱即用。
2. 不影响内核其他模块功能
在确定不需要用户适配的前提下,我们预期所有的代码修改只会集中于内核。我们知道内存管理的几乎全是围绕着struct page管理,各个不同子系统的模块几乎都和struct page息息相关。暴力的释放所有的HugeTLB相关的struct page结构体是不合适的,否则将会影响内核各个内存子系统。既要释放,但又不能释放。这恐怕是最棘手和矛盾的问题了。
3. 代码修改最小化
代码量间接的决定了bug的数量。内存管理子系统修改代码过多,势必影响内核的稳定性。我们既要实现功能,又要以最少的代码量实现。这不但可以降低bug出现的概率,同时也易于维护和理解。
初次探索
一种最简单直接的方法浮出水面。那就是动态分配和释放struct page。
HugeTLB的使用方法一般是先预留后使用。并且struct page只会被内核代码访问,我们倾向内核访问struct page的概率较低。因此我们第一次提出的方案是压缩解压缩的方法。
我们知道HugeTLB对应的512个struct page对应的信息可以压缩到 100 个字节左右,因此我们可以为每个HugeTLB准备一个全新的metadata结构体,然后将所有的信息压缩到新的metadata结构体。并且将struct page区域对应的页表的present清除,然后就可以将其对应的物理页释放。是不是和zram机制如出一辙?
内核在下次访问HugeTLB的struct page的时候触发page fault,在fault里面分配struct page需要的物理页,并解压缩(从新的metadata结构体恢复数据)。
当内核使用完成后,会执行put_page操作。我们在put_page里面做压缩操作,并释放vmemmap对应的物理页。思路很直接,但是这里面存在很多挑战。
- 1. page fault里面无法分配怎么办(例如:OOM)?
- 2. page fault可能发生在任何上下文,用GFP_NOWAIT分配内存?这只会加重第一个问题。
- 3. 如果某一持有A锁的路径触发page fault,page fault里面也尝试持有A锁怎么样?只会死锁。所以page fault的操作需要格外小心。
- 4. 压缩和解压缩操作如何做到原子?或者说压缩操作如何和解压缩操作互斥同步?
- 5. 每次put_page都需要压缩操作,性能影响如何?
- 6. 如果某些内核路径并没有get操作访问struct page(自然也不会put),压缩的时机会是什么时候?
我们列出了很多问题,但就第一个问题来说就很难解决。这不得不让我们放弃了这个想法。我们只能另寻他路。换个思路或许柳暗花明。
另辟蹊径
俗话说“知己知彼百战不殆”。我们先详细了解struct page是如何组织和管理的,清楚每一处细节,才可能运筹帷幄。
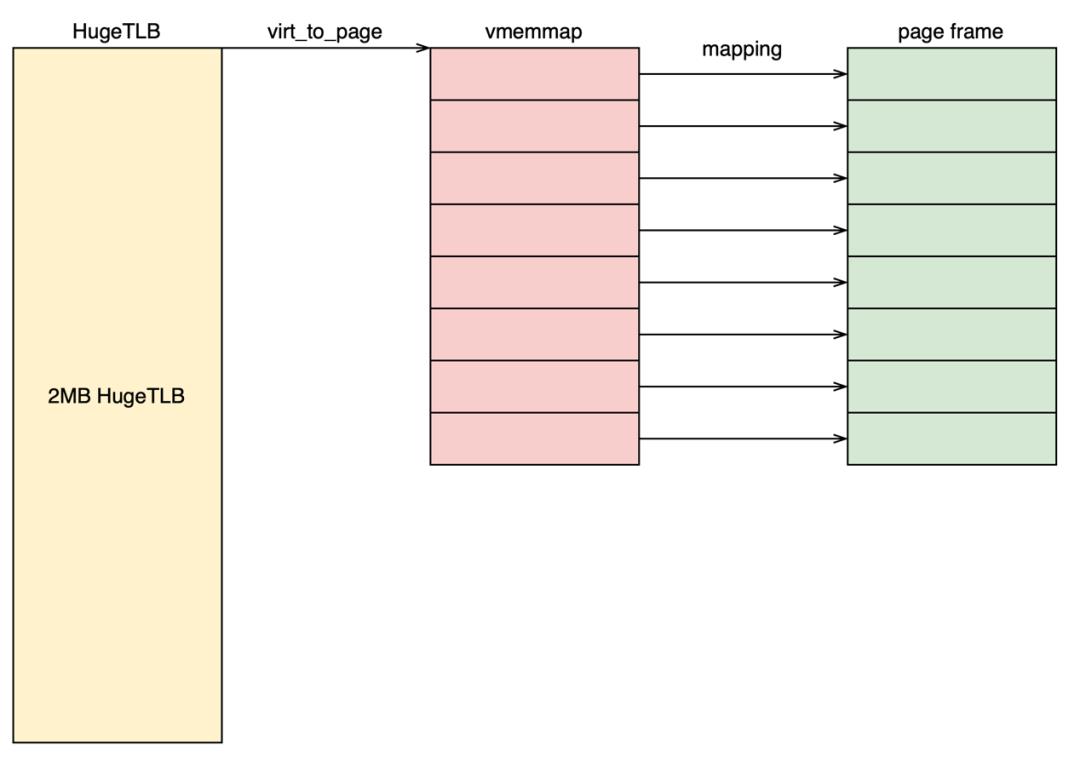
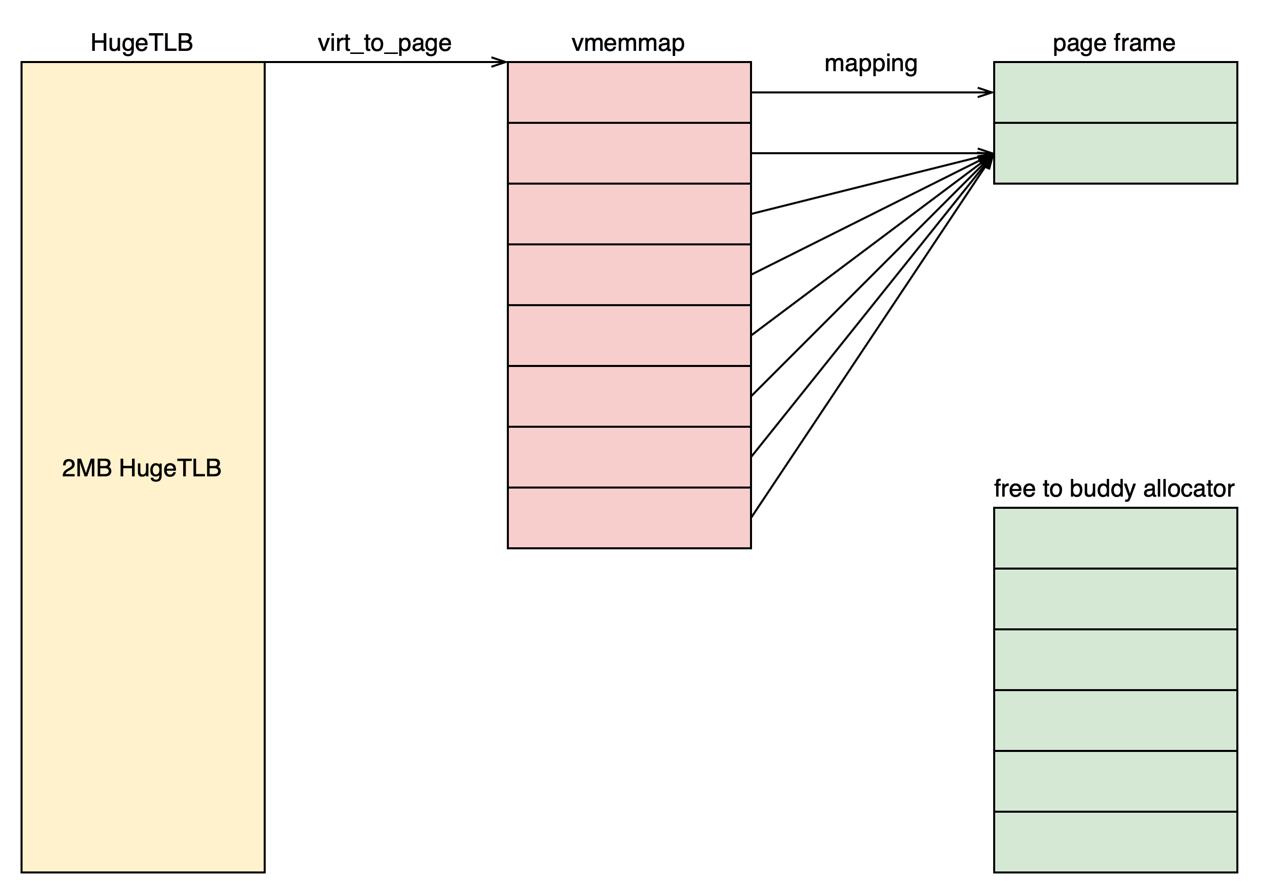
我们上面提到每个HugeTLB page对应512个struct page结构,而HugeTLB只使用前3个struct page结构存储大页相关的metadata。那么其余509个struct page是否完全没有意义呢?如果没有意义我们是不是就可以直接释放这些内存。
然而事情并没有那么简单。这些509个struct page会存储第一个struct page的地址(struct page中compound_head字段)。如果第一个struct page称之为head page的话,那么其余的struct page都是tail page。在Linux内核的内存管理的代码中充斥着大量的代码,这些代码都可能试图从tail page获取head page。所以我们并不能单纯的释放这些内存。
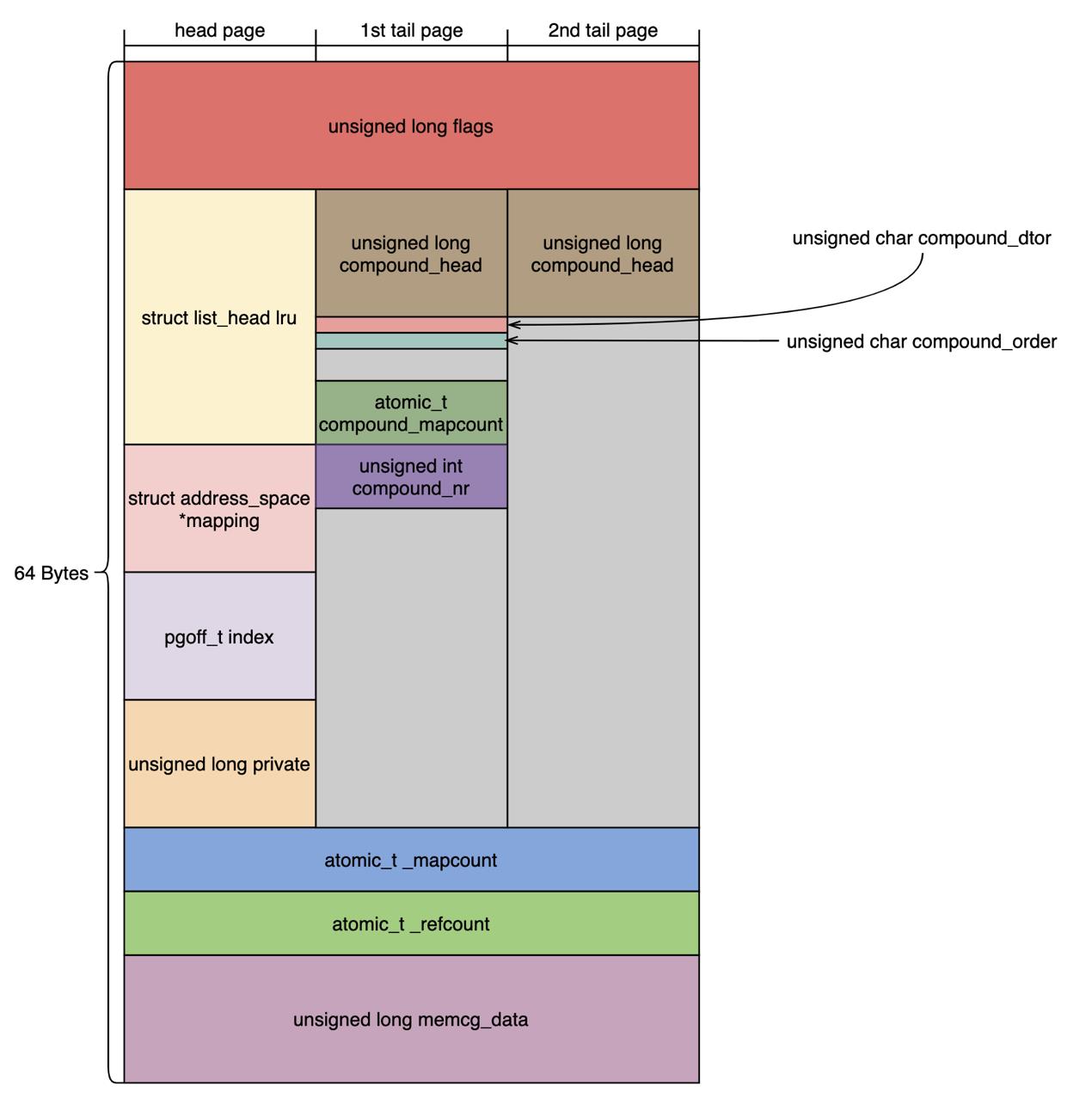
上图展示的3个struct page的结构体示意图(第3个tail page至第511个struct page结构体使用的位域同图中2nd tail page)。我们可以总结出以下特点:
- 1. struct page结构体的大小在大多数情况下是64字节,因此每个4 KB的物理页可以存储整数个数的struct page结构体。
- 2. 第2个tail page至第511个struct page结构体的内容完全一样。
- 3. 内存管理的代码中只会修改head page,1st tail page的2nd tail page的结构体,其余的tail page结构体内存不会修改。
- 4. 每个2MB HugeTLB page对应512个struct page,内存占用8个页(4KB * 8)。
- 5. struct page所在的vmemmap区域和内核的线性映射地址不重合。
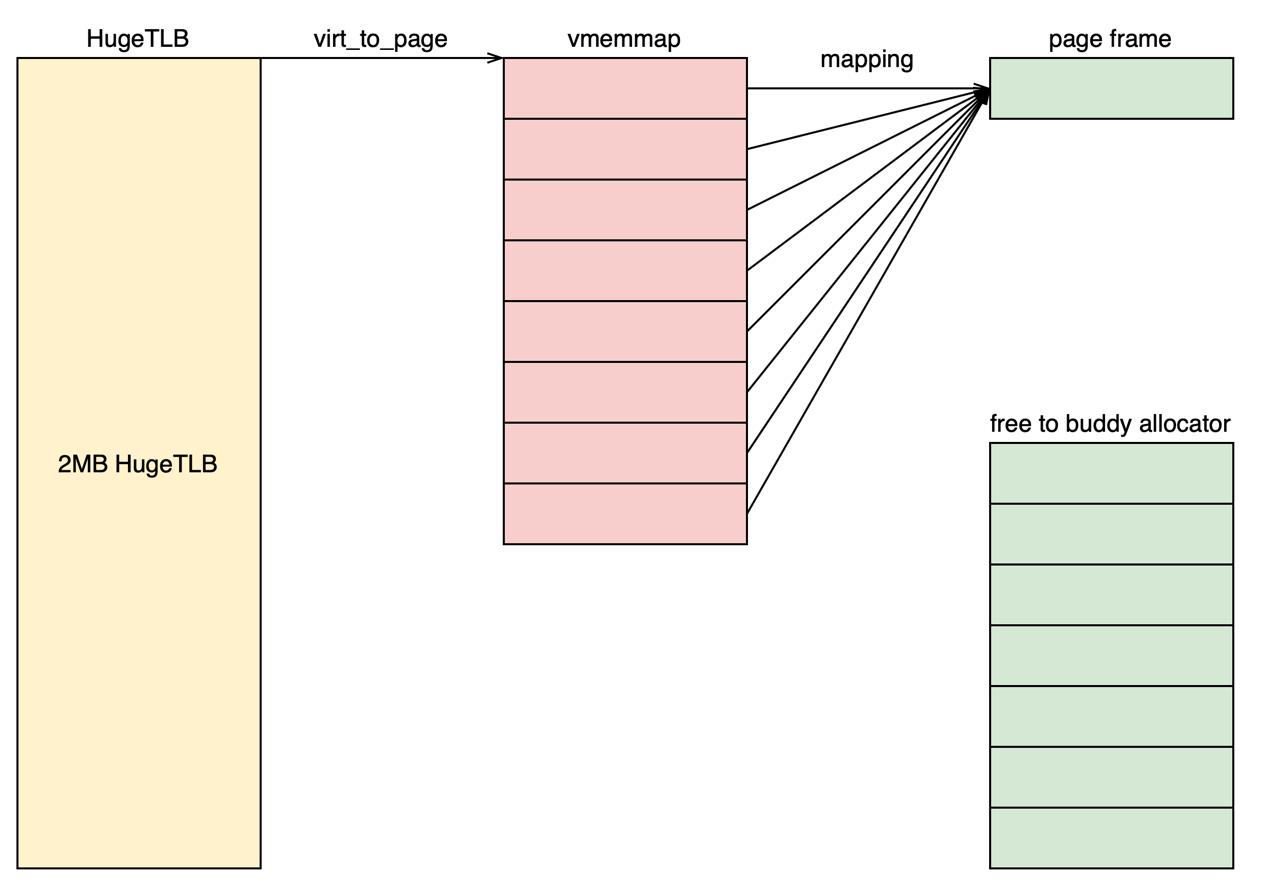
基于以上特点,我们可以提出全新的解决方案:共享映射,将HugeTLB对应的后7个页的vmemmap虚拟地址映射到第1个vmemmap页对应的物理页帧。第1-2点是共享映射方案的基础。基于第3点我们可以将这7个物理页释放,交给buddy系统管理。而第5点是buddy能够管理这块物理内存的基础。内核通过线性地址访问物理内存,所以这个地址不能和vmemmap共用。其原理如下图所示。基于第3点,我们将共享映射属性改成只读,防止出现异常情况。
内存收益
经过上面的优化,我们成功的降低了服务器平台成本,并且收益不错。针对1 GB和2 MB不同size的HugeTLB page,内存收益也同样不同。简单归纳表格如下:
| Total Size of HugeTLB Page | HugeTLB Type | Memory Gain |
| 512 GB | 1 GB | ~8 GB |
| 1024 GB | 1 GB | ~16 GB |
| 512 GB | 2 MB | ~7 GB |
| 1024 GB | 2 MB | ~14 GB |
如果使用1 GB HugeTLB,内存收益约为HugeTLB总量的1.6%。如果使用2 MB HugeTLB,内存收益约为HugeTLB总量的1.4%。
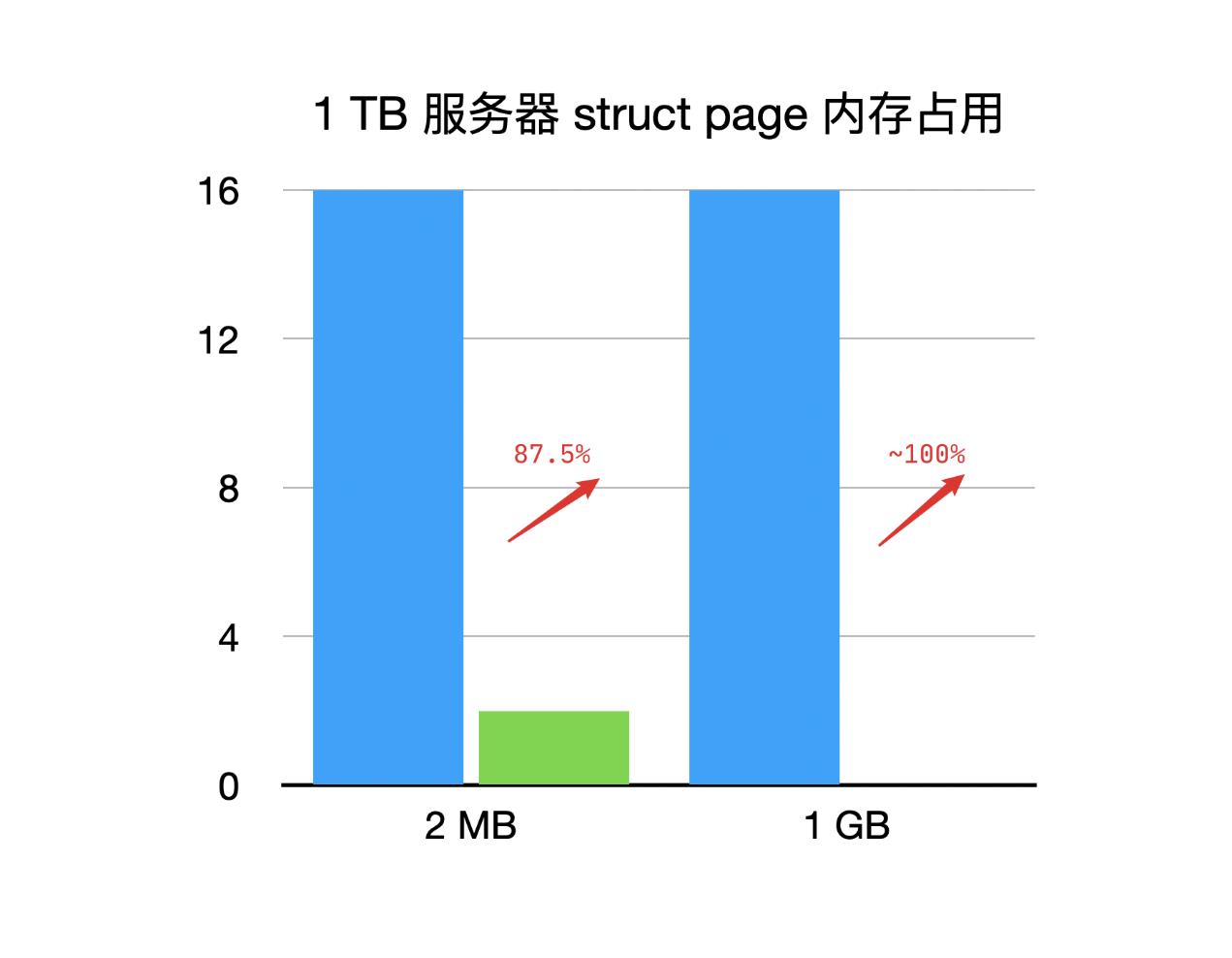
因此,在我们1台1 TB内存的服务器上,如果使用1 GB大页,struct page内存占用优化提升接近100%。如果使用2MB大页,struct page内存占用优化提升约87.5%。
性能分析
我们知道vmemmap区域映射的单位是2 MB。但是我们需要以4 KB页为单位修改页表,因此必须修改vmemmap区域为小页映射。这相当于在内核访问vmemmap区域时,MMU会多访问一级 PTE 页表。但是有TLB的存在,所以查找的性能损失并不大。
但是我们同样也有性能提升的地方,由于我们减少了vmemmap对应的物理页。理论上来说,我们更容易命中cache。实际上也确实这样,经过upstream的测试数据显示,对HugeTLB page进行get_user_page操作性能可以提升接近 4 倍。
开源计划
为了降低代码review的难度,我们决定将全部patch拆分成3笔patchset。目前第一步基础功能已经合入linux-next分支(代码参考: [v23,0/9] Free some vmemmap pages of HugeTLB page,点击文末左下角阅读原文可达),不出意外的话,预计Linux 5.14会和大家见面。

首先第一个功能是释放7个page。什么?这不是上面已经说的功能吗?是的,但是我们的第一个patchset只释放了6个page。所以在上面的patchset中,我们建立的映射关系其实如下图所示。这才是最简单的情况。因为我们head page和tail page的结构体内容其实是不一样的,如果要实现上面的图的映射关系,必然要有一些trick才行。另一组patchset是拆分vmemmap页表。第一组patchset的实现并不包含拆分vmemmap页表,而是系统启动时使vmemmap页表以PTE方式建立映射,而非PMD映射。
关于我们
这一些只是开始,我们对Linux内核内存管理的优化从未停止脚步。不只是HugeTLB,我们后续会开源更多内存方面优化的patchset,其中涉及memory cgroup,页表以及list_lru等等。感兴趣的同学可以继续关注我们后续的patchset。
字节跳动系统技术与工程团队一直致力于操作系统内核与虚拟化、系统基础软件与基础库的构建和性能优化、超大规模数据中心的稳定性和可靠性建设、新硬件与软件的协同设计等基础技术领域的研发与工程化落地,具备全面的基础软件工程能力,为字节上层业务保驾护航。
同时,团队积极关注社区技术动向,拥抱开源和标准。欢迎更多有志之士加入,如有意向可发送简历至sysrecruitment@bytedance.com。

此篇文章为转载,这个团队也是我心心相的团队。
以上是关于围绕HugeTLB的极致优化的主要内容,如果未能解决你的问题,请参考以下文章