Pytorch Note4 Variable(变量)
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch Note4 Variable(变量)相关的知识,希望对你有一定的参考价值。
Pytorch Note4 Variable(变量)
全部笔记的汇总贴:Pytorch Note 快乐星球
Variable(变量)
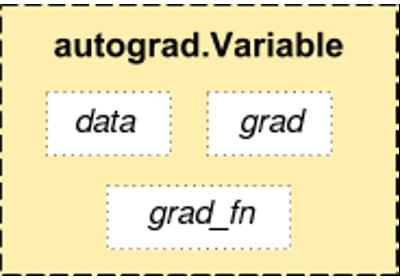
tensor 是 PyTorch 中的完美组件,但是构建神经网络还远远不够,我们需要能够构建计算图的 tensor,这就是 Variable。Variable 是对 tensor 的封装,操作和 tensor 是一样的,但是每个 Variabel都有三个属性,Variable 中的 tensor本身.data,对应 tensor 的梯度.grad以及这个 Variable 是通过什么方式得到的.grad_fn
Variable和Tensor本质上没有区别,不过Variable会被放入一个计算图中,然后进行前向传播,反向传播,自动求导。首先Variable是在torch.autograd.Variable中,要将一个tensor变成Variable也非常简单,比如想让一个tensor a变成Variable,只需要 Variable(a)就可以了。
Variable包含三个属性:
- data:存储了Tensor,是本体数据-
- grad:保存了data的梯度,是个Variable而非Tensor,与data形状一致
- grad_fn:指向Function对象,用于反向传播的梯度计算之用
# 通过下面这种方式导入 Variable
from torch.autograd import Variable
x_tensor = torch.randn(10, 5)
y_tensor = torch.randn(10, 5)
# 将 tensor 变成 Variable
x = Variable(x_tensor, requires_grad=True) # 默认 Variable 是不需要求梯度的,所以我们用这个方式申明需要对其进行求梯度
y = Variable(y_tensor, requires_grad=True)
z = torch.sum(x + y)
print(z.data)
print(z.grad_fn)
tensor(-18.1752)
<SumBackward0 object at 0x000001DD2D2E2448>
上面我们打出了 z 中的 tensor 数值,同时通过grad_fn知道了其是通过 Sum 这种方式得到的
# 求 x 和 y 的梯度
z.backward()
print(x.grad)
print(y.grad)
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
通过.grad我们得到了 x 和 y 的梯度,这里我们使用了 PyTorch 提供的自动求导机制,非常方便
例子(标量求导)
# Create Variable
x = Variable(torch.Tensor([1]), requires_grad=True)
w = Variable(torch.Tensor([2]), requires_grad=True)
b = Variable(torch.Tensor([3]), requires_grad=True)
# Build a computational graph
y = w * x + b # y = 2x + b
# Compute gradients
y.backward() # same as y.backward(torch.FloatTensor([1]))
# Print out the gradients.
print(x.grad) # x.grad = 2
print(w.grad) # w.grad = 1
print(b.grad) # b.grad = 1
tensor([2.])
tensor([1.])
tensor([1.])
矩阵求导
x = torch.randn(3)
x = Variable(x, requires_grad=True)
print(x)
y = x * 2
print(y)
y.backward(torch.FloatTensor([1, 0.1, 0.01]))
print(x.grad)
tensor([-2.0131, -1.9689, -0.7120], requires_grad=True)
tensor([-4.0262, -3.9377, -1.4241], grad_fn=)
tensor([2.0000, 0.2000, 0.0200])
相当于给出了一个三维向量去做运算,这时候得到的结果y就是一个向量,这里对这个向量求导就不能直接写成 y.backward(),这样程序是会报错的。这个时候需要传入参数声明,比如y.backward(torch.FloatTensor([1, 1, 1])),这样得到的结果就是它们每个分量的梯度,或者可以传入y.backward(torch.FloatTensor([1, 0.1, 0.01])),这样得到的梯度就是它们原本的梯度分别乘上1,0.1和0.01。
小练习
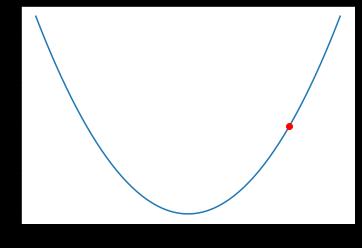
尝试构建一个函数 y = x 2 y = x^2 y=x2,然后求 x=2 的导数。
参考输出:4
提示:
y
=
x
2
y = x^2
y=x2的图像如下
import matplotlib.pyplot as plt
x = np.arange(-3, 3.01, 0.1)
y = x ** 2
plt.plot(x, y)
plt.plot(2, 4, 'ro')
plt.show()
# 答案
x = Variable(torch.FloatTensor([2]), requires_grad=True)
y = x ** 2
y.backward()
print(x.grad)
tensor([4.])
下一章传送门:Note5 动态图和静态图 dynamic-graph
以上是关于Pytorch Note4 Variable(变量)的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-19]:Pytorch基础 - Variable变量的使用方法与 Tensor变量的比较