Apache DolphinScheduler 征稿 —开源大数据调度器Apache DolphinScheduler安装维护与实践
Posted ╭⌒若隐_RowYet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache DolphinScheduler 征稿 —开源大数据调度器Apache DolphinScheduler安装维护与实践相关的知识,希望对你有一定的参考价值。
目 录
- 1. 简 介
- 2. 集群模式安装详解(比官网还细,个人手把手实践避坑)
- 3. 实战教学
- 3.1 用户退出&语言选择等杂项
- 3.2 监控中心
- 3.3 安全中心
- 3.4 数据源中心
- 3.5 资源中心
- 3.6 项目管理
- 3.6.1 创建、编辑、删除项目
- 3.6.2 工作流定义
- 3.6.3 工作流手动运行
- 3.6.4 工作流定时调度
- 3.6.5 工作流实例重跑(大特色)
- 3.6.6 查看任务日志及历史运行
- 3.6.7 各大ETL控件介绍
- 3.6.7.1 `SHELL(SHELL脚本)`
- 3.6.7.2 `SUB_PROCESS(引用同项目下的其它工作流)`
- 3.6.7.3 `PROCEDURE(执行存储过程)`
- 3.6.7.4 `SQL(执行查询或非查询的SQL语句)`
- 3.6.7.5 `Spark、Flink、MR(MapReduce)大数据控件`
- 3.6.7.6 `Python`
- 3.6.7.7 `DEPENDENT(与本项目或者其他项目的某些工作流有依赖)`
- 3.6.7.8 `HTTP(刷网页请求)`
- 3.6.7.9 `DataX和Sqoop(ETL工具)`
- 3.6.7.10 `CONDITION(条件判断,上一个任务成功或者失败的后续)`
- 3.6.7 参数设置
- 3.7 首页
- 4. API调用
- 5. 元数据表选讲
- 6. 扩容/缩容与升级
- 7. 其它
1. 简 介
Apache DolphinScheduler(海豚调度),国人之光,是许多国人雷锋开源在Apache的顶级项目,主要功能就是负责任务的调度处理;
写这篇博文有两个目的,其一:博主安装和实践结合官网做一个详细分享;其二:赶一波Apache DolphinScheduler 征稿的活动;
1.1 概 念
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用,架构如图1.1,大概看一下,看不懂没关系,后续细讲;
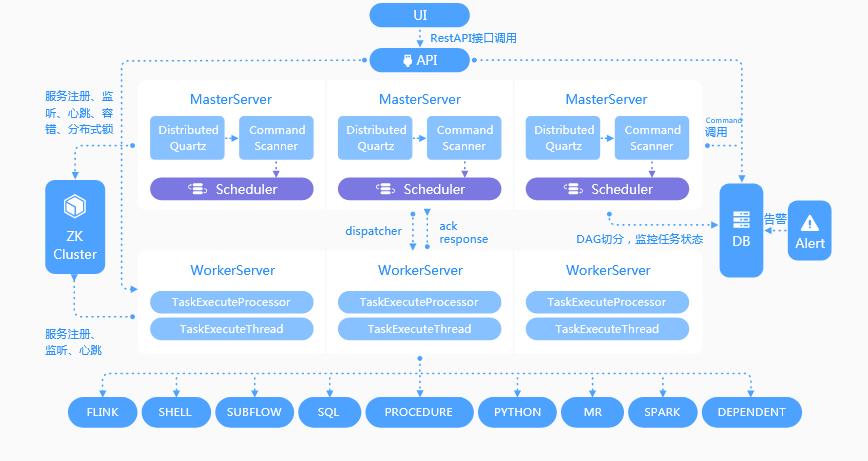
分布式:就是可以这个组件不同的部分可以分布在不同的机器上,整体的协调工作完成任务调度;(为啥要分布式而不装在一台,因为一头牛拉一大堆物资可能会累死,除了培养更加强壮的牛以外,还可以让多头牛去拉);去中心化:DolphinScheduler有多台master(负责发号施令,布置任务,接受成果),假设有m1,m2,m3……,也有多台worker(负责真正干活的小弟),假设有w1,w2,w3……,而这些机器都注册在zookeeper,每次任务A来的时候,都同时需要m和w,但是根据你配置的不同任务A将分到不同的m和w上,而不是单纯在一个单点上运行,提高容错性,当然如果你玩单机模式,则不存在这个概念;易扩展:既然master,worker可以有多个,那可不可有更多,所以DolphinScheduler是支持扩容的,反之,实践中发现太败家了,需要回收一些机器,也是可以支持缩容的;可视化DAG工作流任务调度:就是除了提供查看日志来查看任务和工作流的运行情况,还有个有序无环图可查看任务和工作流的运行情况;处理流程中错综复杂的依赖关系:现在有要跑的项目A,B;项目A有工作流a1(内有任务一s1,任务二s2),a2(内有任务一s3,任务二s4),a3(内有任务一s5,任务二s6);项目B里面有工作流b1(内有任务一s7,任务二s8),b2(内有任务一s9,任务二s10);一般的任务调度器,都能保证一个工作流内的任务如s1,s2是有序往下运行的,当然也可并行;但是有些调度器就实现不了工作流a1和a2以及a3之间有依赖关系了,比如某些场景下必须工作流b1先跑完,才可以跑a1,a2;那更甚至的必须先跑完整个项目B才能跑 项目A就更不支持了,即项目之间有壁垒,这些都是比价差劲的,需要用户自己想办法去实现,但是DolphinScheduler这些缺陷都填了,即以上的这些复杂依赖关系,不论是工作流之间,项目之间都支持;
1.2 优缺点
官网提出她有四大优点,如图1.2,个人觉得高可用和DAG监控界面算是比较优秀的,其他的是一个调度器必备的,不能作为特色吧,另外赞扬一句,DolphinScheduler的WebUI做的是真的绚丽,令人看了很舒服;

缺点:相对而言目前(20210605)比较年轻,还在持续更新中,还需要与大家共同成长,个别功能不完善,如虽然支持多个Master节点,但是不自带Master之间的自动故障转移,即你在用API访问时,需要自己配置反向代理;支持的数据源比较单一,如Presto,ElasticSearch等暂不支持;任务类型的控件还较少,邮件、中止等控件还没有。
1.3 哪些人适合DolphinScheduler(纯属个人观点)
如果第一公司不想花大价钱购买商业ETL工具及调度器,第二公司也没规划人力自研调度器,那么DolphinScheduler将是不错的选择;
因为确实也存在很优秀的商业调度器,唯一的缺点就是贵嘛;而DolphinScheduler在目前的开源调度器中,如Azkaban,XXL-Job,Ozzie,AirFlow等对比,确实略胜一筹,如果自研开源调度器,人力成本也是需要估量的,因为DolphinScheduler完全开源,也可以借鉴DolphinScheduler。
1.4 社区
-
微信公众号:海豚调度 -
微信号:easyworkflow,让她拉你进群,共同探讨dolphinscheduler; -
其 他:……
欢迎大家加入社区工程促进Apache DolphinScheduler越来越好。
2. 集群模式安装详解(比官网还细,个人手把手实践避坑)
目前(20210606)支持的部署模式如下;
- 单机部署
集群部署- Docker部署
- Kubernetes部署
- SkyWalking-Agent部署
Why集群模式?现在DolphinScheduler支持的部署模式越来越丰富了 ,博主翻了下日志,新的版本对后续的部署模式Docker,Kubernetes,SkyWalking-Agent做了很大的优化和调整,这些模式如果有兴趣,建议用最新的版本,但是生产环境本着最新版本倒退2个版本的原则,博主还是选用了较为稳定的1.3.5版本,而且博主的大数据集群都是集群部署模式,多少有点个人爱好因素,就选择了集群部署模式,因为博主喜欢这种任何配置都安排在清清楚楚的文件夹的感觉;
2.1 架构图详解
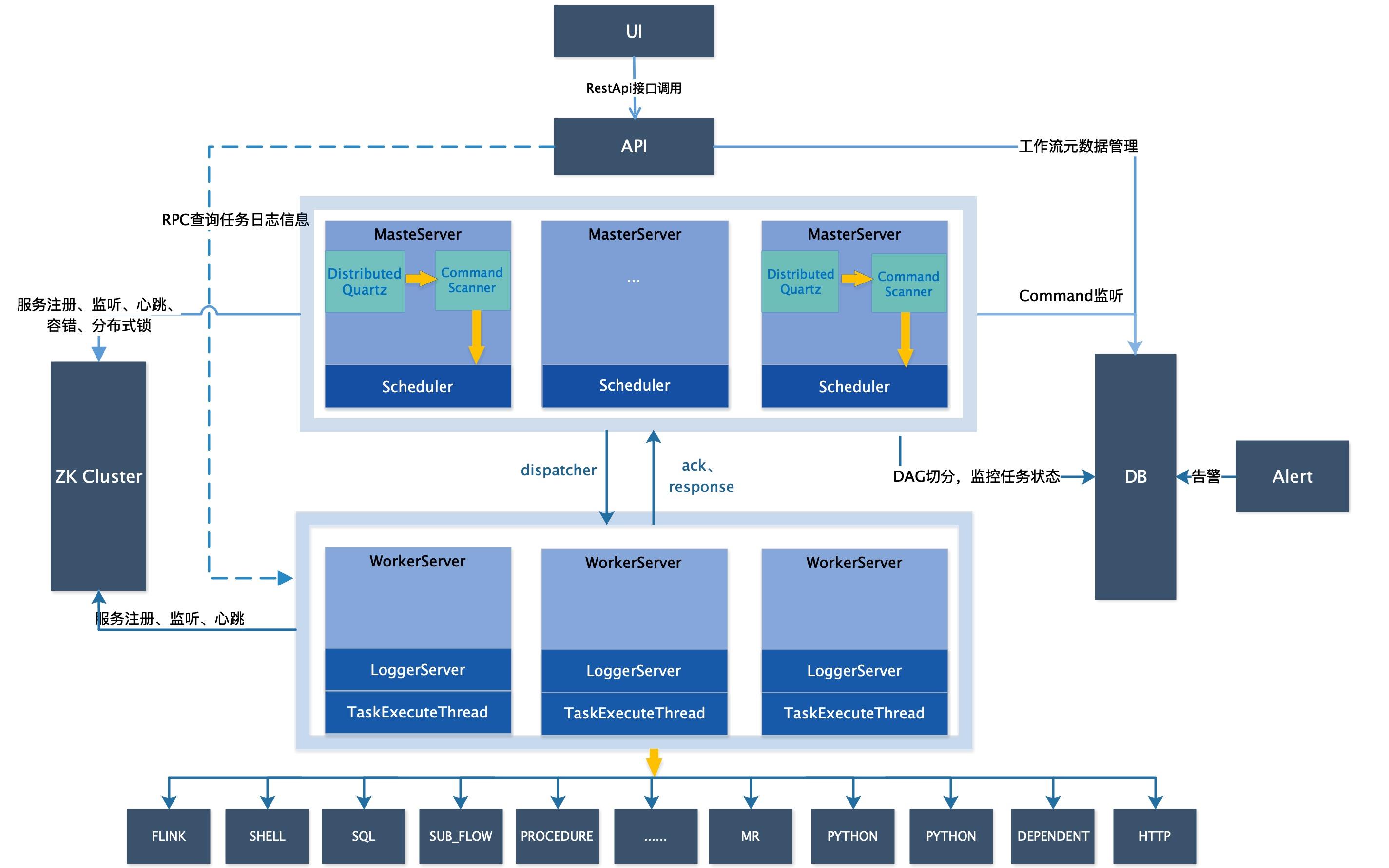
-
MasterServer:MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务,该服务内主要包含:- Distributed Quartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
- MasterSchedulerThread是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作;
- MasterExecThread主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理;
- MasterTaskExecThread主要负责任务的持久化。
-
WorkerServer:WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 Server基于netty提供监听服务,该服务包含:FetchTaskThread主要负责不断从Task Queue中领取任务,并根据不同任务类型调用TaskScheduleThread对应执行器。 -
LoggerServer:是一个RPC服务,提供日志分片查看、刷新和下载等功能; -
ZooKeeper:ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。 -
Task Queue: 提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,实际上我们压测过百万级数据存队列,对系统稳定性和性能没影响。 -
Alert:提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能又有邮件通知和**SNMP(暂未实现)**两种。 -
API:API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。 -
UI:系统的前端页面,提供系统的各种可视化操作界面,详见实战教学。
2.2 机器安排
根据上面的架构,可以集群模式机器分配可以如下;
MasterServer:最好能有2+台MasterServer,可以实现高可用;
2.WorkerServer:最好能有3+台WorkerServer分别接收任务调度运行;如果条件允许,最好能MasterServer、WorkerServer分布在不同的机器上,避免WorkerServer导致机器性能瓶颈影响到MasterServer,实在条件不允许,就搞两台和MasterServer共用也行,这样你只要3台机器即可;否则是5台;LoggerServer:是跟着WorkerServer的,不用特别准备机器;ZooKeeper:如果你有ZooKeeper集群,用已有的就行,如果没有就用这5台安装一个ZooKeeper集群;Task Queue:不用刻意准备机器;Alert:5台机器任选一台;API:可以多台,也不建议刻意准备,博主是跟着MasterServer的两台;UI:可以多台,也不建议刻意准备,博主是跟着MasterServer的两台;
因此整个机器安排如表2.2;
| 机器\\服务 | MasterServer | WorkerServer | LoggerServer | Alert | API&UI | ZooKeeper(已有可忽略) |
|---|---|---|---|---|---|---|
| node1(10.192.168.20) | 1 | 1 | 1 | |||
| node2(10.192.168.21) | 1 | 1 | 1 | |||
| node3(10.192.168.22) | 1 | 1 | 1 | 1 | ||
| node4(10.192.168.23) | 1 | 1 | 1 | |||
| node5(10.192.168.24) | 1 | 1 | 1 |
2.3 安装前准备
博主选择安装的是Apache DolphinScheduler 1.3.5版本,接下来做一些安装前的准备;
2.3.1 安装要求
以下基础配置是需要每台机器都有的,选装的看你自己安排;
操作系统:那就开源到底,建议选用CentOS7,配置建议为CPU 4核+、内存8 GB+、SAS磁盘、千兆网卡……,总之只要不是太low的配置就行,如果实在不会操作Linux,可以关注下博主的Linux栏,有手把手教程安装Linux操作系统,配置网络,用户管理等;jdk:JDK (1.8+),必须装;python:最好能装,因为后续调度Python脚本也是很常见的,可以参考博客Linux通过anaconda来安装python;ZooKeeper:ZooKeeper (3.4.6+) ,必须要装;Hadoop集群:Hadoop (2.6+) or MinIO :选装,如果需要用到资源上传功能,可以选择上传到Hadoop or MinIO上;
注意:jdk、ZooKeeper、Hadoop、免密登录的安装,可以参考博客:Hadoop集群大数据解决方案之搭建Hadoop3.X+HA模式(二);
元数据库:PostgreSQL (8.2.15+) or mysql (5.7系列) : 两者任选其一即可, 如MySQL则需要JDBC Driver 5.1.47+,建议选用MySQL,如果不会安装,可以参考博客:Linux(CentOS-7)下安装MySQL-5.7.30,在其中一台安装好MySQL并开启服务,其他的WorkerServer最好能安装好MySQL客户端,因为后续的调度及其可用在Shell脚本上用到MySQL脚本,注意如果你有Hive元数据库,可以存在Hive元数据库同一实例下,不用再可以准备MySQL了;Spark:选装,如果有调度spark的任务,也是需要在WorkerServer安装Spark客户端;Hive:选装,如果有调度hive的任务,也是需要在WorkerServer安装hive客户端;其他:只要运行在linux的任务,都需要支持有客户端,否则,会出现xxx command not found;
注意:DolphinScheduler本身不依赖Hadoop、Hive、Spark,仅是会调用他们的Client,用于对应任务的提交,安装客户端博主一般的做法就是去相应的官网,找到该软件的tar包,然后上传到你的Linux机器的某个位置,以MySQL为例子,如/data/tools/mysql/目录下,然后解压,假设得到/data/tools/mysql/mysql-5.7,然后把mysql下的/data/tools/mysql/mysql-5.7/bin目录写入环境变量,另外记得在/usr/bin目录下也设置下软链接,指令
ln -sf /data/tools/mysql/mysql-5.7 /usr/bin/mysql,保证shell脚本/usr/bin/sh 能引用到,其他客户端的安装基本也是这样;
如果以上工具都已经ready的,恭喜你,你对大数据领域已经有很深的认识了;
2.3.2 选择/创建安装维护账号
如果你已经玩转大数据集群,那么必然是有一个账号在启动者集群的各项任务,如hadoop,hdfs,hive等等,博主的集群有个这样的账号,名字就叫hadoop,那么就继续用hadoop账号去做免密登录,下载安装DolphinScheduler,如果你没有这种账号,那么随意,官网是说建一个dolphinScheduler账号,这个看你,账号叫啥都行;
2.3.3 集群之间免密登录
集群之间免密登录虽然上面博客也又说到,这里再啰嗦几句,博主有一篇花式玩转Linux集群免密登录一文教你把免密登录整的明明白白,有兴趣的可以看看,切记免密登录是绑定账号的,这里的免密登录一般用到上面2.3.2选择/创建安装维护的账号,假设你用的hadoop创建了集群的免密登录,那么当你切换root账号时,root账号并没有免密登录的权限,需要重新配置。
2.3.4 下载
博主在集群安装的软件一般是/data/tools下,注意,Dolphinscheduler不比hadoop,spark,hive等软件,这些软件的tar包安装都是解压,然后配置,然后启动就能用,Dolphinscheduler下载的tar包apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz,解压后的文件重命名apache-dolphinschedule-1.3.5是一个类似于windows的exe文件,是需要在conf/config/install_config.conf 下指定真实的installPath(一定要安装的用户有可读可写的权限),一切配置好以后,运行install.sh就能把DS装到你选定的目录,后续的启动、关闭都是在installPath上进行的,以下操作需要在每一台机器上都进行;
我们就先在20上配置好;
# 进入/data/tools
cd /data/tools
# 创建总文件夹dolphinscheduler
mkdir dolphinscheduler
# 进入dolphinscheduler
cd dolphinscheduler
# 下载,如果网速不好,就去dolphinscheduler官网或者git下载这个tar包,然后上传到集群的这个目录
wget https://downloads.apache.org/dolphinscheduler/1.3.5/apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz
# 解压
tar -zxvf apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz
# 因为名字老长了,做一下重命名
mv apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin apache-dolphinscheduler-1.3.5
# 创建installPath,一定要安装的用户有可读可写的权限
mkdir install-ds-1.3.5
# 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可
# 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可
# 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软链接即可
ln -sf /data/tools/dolphinscheduler/install-ds-1.3.5 current
# 进入解压的apache-dolphinscheduler-1.3.5
cd apache-dolphinscheduler-1.3.5
# 查看下当前目录
ls -al
# 结果如下
drwxr-xr-x 9 hadoop supergroup 204 Jun 1 20:23 .
drwxr-xr-x 4 hadoop supergroup 178 Jun 2 00:15 ..
drwxr-xr-x 2 hadoop supergroup 95 Jun 1 20:23 bin
drwxr-xr-x 6 hadoop supergroup 4096 Jun 2 10:02 conf
-rw-r--r-- 1 hadoop supergroup 563 Feb 7 17:46 DISCLAIMER
-rwxr-xr-x 1 hadoop supergroup 4663 Feb 7 17:46 install.sh
drwxr-xr-x 2 hadoop supergroup 12288 Jun 1 20:26 lib
-rw-r--r-- 1 hadoop supergroup 38540 Feb 7 17:46 LICENSE
drwxr-xr-x 3 hadoop supergroup 12288 Feb 7 17:46 licenses
-rw-r--r-- 1 hadoop supergroup 70942 Feb 7 17:46 NOTICE
drwxr-xr-x 2 hadoop supergroup 254 Jun 1 20:23 script
drwxr-xr-x 4 hadoop supergroup 149 Jun 1 20:23 sql
drwxr-xr-x 8 hadoop supergroup 149 Jun 1 20:23 ui
以上文件做一个简单的介绍,具体如下;
├─bin DS命令存放目录
│ ├─dolphinscheduler-daemon.sh 启动/关闭DS服务脚本
│ ├─start-all.sh 根据配置文件启动所有DS服务
│ ├─stop-all.sh 根据配置文件关闭所有DS服务
├─conf 配置文件目录
│ ├─application-api.properties api服务配置文件
│ ├─datasource.properties 数据库配置文件
│ ├─zookeeper.properties zookeeper配置文件
│ ├─master.properties master服务配置文件
│ ├─worker.properties worker服务配置文件
│ ├─quartz.properties quartz服务配置文件
│ ├─common.properties 公共服务[存储]配置文件
│ ├─alert.properties alert服务配置文件
│ ├─config 环境变量配置文件夹
│ ├─install_config.conf DS环境变量配置脚本[用于DS安装/启动]
│ ├─env 运行脚本环境变量配置目录
│ ├─dolphinscheduler_env.sh 运行脚本加载环境变量配置文件[如: JAVA_HOME,HADOOP_HOME, HIVE_HOME ...]
│ ├─org mybatis mapper文件目录
│ ├─i18n i18n配置文件目录
│ ├─logback-api.xml api服务日志配置文件
│ ├─logback-master.xml master服务日志配置文件
│ ├─logback-worker.xml worker服务日志配置文件
│ ├─logback-alert.xml alert服务日志配置文件
├─sql DS的元数据创建升级sql文件
│ ├─create 创建SQL脚本目录
│ ├─upgrade 升级SQL脚本目录
│ ├─dolphinscheduler-postgre.sql postgre数据库初始化脚本
│ ├─dolphinscheduler_mysql.sql mysql数据库初始化脚本
│ ├─soft_version 当前DS版本标识文件
├─script DS服务部署,数据库创建/升级脚本目录
│ ├─create-dolphinscheduler.sh DS数据库初始化脚本
│ ├─upgrade-dolphinscheduler.sh DS数据库升级脚本
│ ├─monitor-server.sh DS服务监控启动脚本
│ ├─scp-hosts.sh 安装文件传输脚本
│ ├─remove-zk-node.sh 清理zookeeper缓存文件脚本
├─ui 前端WEB资源目录
├─lib DS依赖的jar存放目录
├─install.sh 自动安装DS服务脚本
在安装配置中用到的关键性文件为conf/datasource.properties、conf/config/install_config.conf、conf/env/dolphinscheduler_env.sh,简单吧,其他的文件,需要了解其功能即可,一般不用特意修改,除非你要个性化设置,下面进入安装配置;
2.4 安装步骤
2.4.1 创建元数据库
如果你装过Hive,这一步骤就不陌生了,没有也没关系,其实就是找一个数据库存放Dolphinscheduler的元数据(metadata,解释数据的数据,比如你有多少项目,多少工作流,MatserServer、WorkServer是哪些等等),这里一般选用MySQL,如果你有Hive,也可以放在Hive元数据库的那个实例下,新建一个dolphinscheduler库即可,如果没有,就在刚刚准备的MySQL实例内新建dolphinscheduler库;这种库一般都比较重要,强烈要求DBA进行备份和监控,以防不测;
在你的MySQL客户端,跑以下语句完成元数据库的创建,如果有DBA,恭喜你,可以交给DBA做,告诉他建一个dolphinscheduler ,需要某账号(没有则新建,博主选的是dw_user账号)该库的所有权限;
-- 创建数据库dolphinscheduler
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-- 给你的一个数据库账号赋权,一定要可读可写,最好是dolphinscheduler库权限全给账号dw_user且能远程连接
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dw_user'@'%' IDENTIFIED BY '123456qwer';
# 设置账号能连接权限全给账号dw_user且能本地连接
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dw_user'@'localhost' IDENTIFIED BY '123456qwer';
# 刷新权限
flush privileges;
特别提醒:既然用了MySQL,自然连接MySQL的jar包不能少,一样的,如果你安装了Hive,直接把Hive的lib下的mysql-connector-java-x.x.xx.jar复制到你解压的apache-dolphinscheduler-1.3.5/lib/下即可,如果没有,就去官网下载;
# 如果装过hive则copy
copy /data/tools/hive/current/lib/mysql-connector-java-8.0.13.jar /data/tools/dolphinscheduler/dolphinscheduler-1.3.5/lib
# 没有的话直接下载
# 下载到/data/source文件夹
# 进入
cd /data/source
# 下载
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.25.tar.gz
# copy到lib下,没网的话就在有网的机器下好再上传到这里
cp /data/source/mysql-connector-java-8.0.25/mysql-connector-java-8.0.25.jar /data/tools/dolphinscheduler/dolphinscheduler-1.3.5/lib
2.4.2 初始化元数据库表
这里假设元数据库就安装在10.192.168.20上(自己根据自己的机器来),初始化之前,先要修改下conf 目录下 datasource.properties 中的下列配置;
# 进入dolphinscheduler-1.3.5
cd /data/tools/dolphinscheduler/dolphinscheduler-1.3.5
# 编辑conf/datasource.properties
vim conf/datasource.properties
#具体改动如下,注释调postgre配置,新增mysql的
#postgre
#spring.datasource.driver-class-name=org.postgresql.Driver
#spring.datasource.url=jdbc:postgresql://localhost:5432/dolphinscheduler
# mysql
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://10.192.168.20:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=dw_user
spring.datasource.password=123456qwer
# 修改完记得保存退出
:wq!
# 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接
# 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接
# 确保已安装了java,且配置了java环境变量,且/usr/bin/下有java软链接
# 博主的jdk安装在/data/tools/java/current下,设置/usr/bin/java软链接
ln -sf /data/tools/java/current/bin/java /usr/bin/java
# 运行元数据库初始化脚本,如果没java或者没配置环境变量,会报错`/bin/java: No such file or directory`
sh script/create-dolphinscheduler.sh
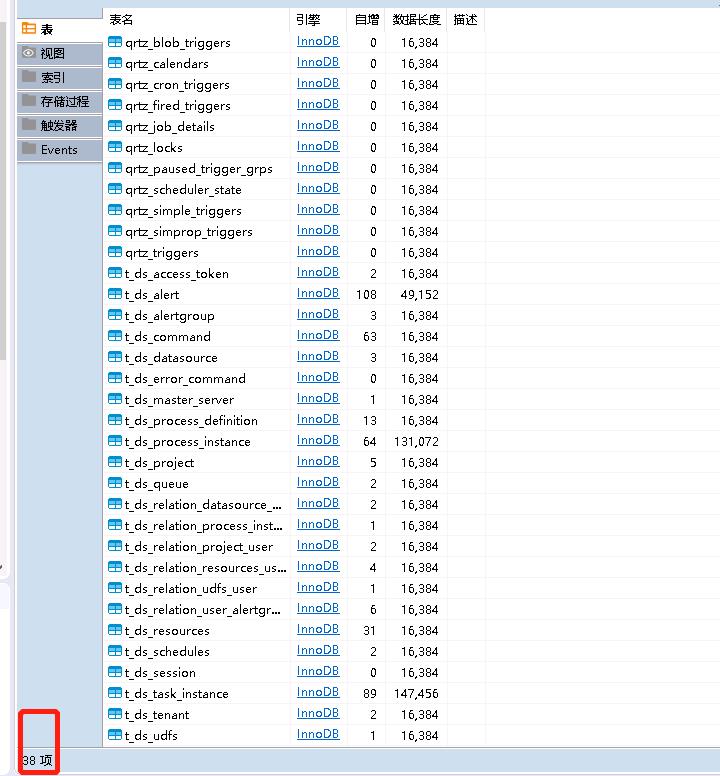
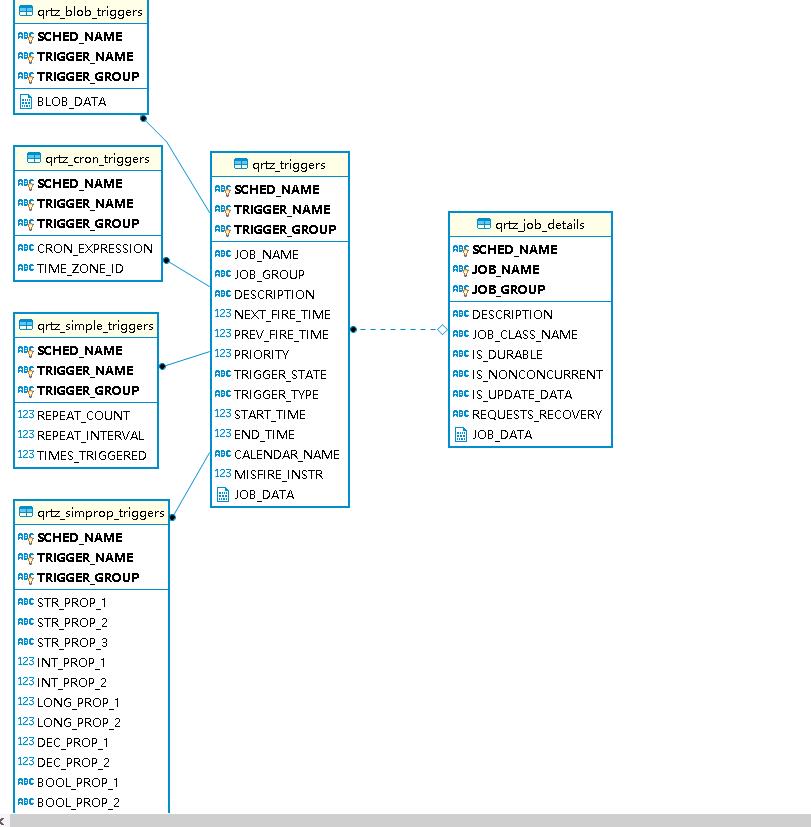
这是你在MySQL客户端刷线下数据库dolphinscheduler,你会发现新建了38张表(版本1.3.5其他版本可能有差距,总之没报错即可),局部表预览和E-R图如图2.4.1,2.4.2;
2.4.3 修改dolphinscheduler的环境变量conf/env/dolphinscheduler_env.sh
修改 conf/env 目录的dolphinscheduler_env.sh环境变量,博主的配置如下,你们可以按照自己的来;
# 进入 /data/tools/dolphinscheduler/dolphinscheduler-1.3.5
cd /data/tools/dolphinscheduler/dolphinscheduler-1.3.5
# 编辑conf/env/dolphinscheduler_env.sh
vim conf/env/dolphinscheduler_env.sh
# 具体操作如下
# 这一步非常重要,例如 JAVA_HOME 和 PATH 是必须要配置的,没有用到的可以忽略或者注释掉
export HADOOP_HOME=/data/tools/hadoop/current
export HADOOP_CONF_DIR=/data/tools/hadoop/current/etc/hadoop
export SPARK_HOME1=/data/tools/spark/current
# export SPARK_HOME2=/opt/soft/spark2
export PYTHON_HOME=/data/tools/anaconda/anaconda3/bin
export JAVA_HOME=/data/tools/java/current
export HIVE_HOME=/data/tools/hive/current
export FLINK_HOME=/data/tools/flink/current
# export DATAX_HOME=/opt/soft/datax/bin/datax.py
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$PATH
# 千万记得保存退出
:wq!
2.4.4 修改部署配置文件 conf/config/install_config.conf
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# NOTICE : If the following config has special characters in the variable `.*[]^${}\\+?|()@#&`, Please escape, for example, `[` escape to `\\[`
# postgresql or mysql 这里选择mysql为元数据库
dbtype="mysql"
# db config
# db address and port mysql数据库的实例
dbhost="10.192.168.20:3306"
# db username 用户名
username="dw_user"
# database name 数据库名
dbname="dolphinscheduler"
# db passwprd 登录密码
# NOTICE: if there are special characters, please use the \\ to escape, for example, `[` escape to `\\[`
password="123456qwer!"
# zk cluster ZooKeeper集群,配置你自己有ZooKeeper集群
zkQuorum="10.192.168.20:2181,10.192.168.21:2181,10.192.168.22:2181,10.192.168.23:2181,10.192.168.24:2181"
# Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd)
# 安装目录,这个很重要,就是一键部署后的目录,这里选择之前早已准备好的安装目录,切记一定要安装账号对该目录有可读,可写,可执行权限
installPath="/data/tools/dolphinscheduler/install-ds-1.3.5"
# deployment user
# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
# 操作系统的账号,这里选择你平时使用的大数据账号即可
deployUser="hadoop"
# alert config
# mail server host
# 这里是你公司的邮箱服务器,一般公司都有自己的邮箱服务器,可以找基础设施部邮件组询问下
mailServerHost="appmail.rowyet.cn"
# mail server port
# note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct.
# 邮箱服务器端口
mailServerPort="25"
# sender
# 后续的邮件如数据发送,告警发送使用的账户,可以让基础设施部创建个你们自己的邮箱
mailSender="dw_bi@rowyet.cn"
# user
# 同mailSender即可
mailUser="dw_bi@rowyet.cn"
# sender password
# note: The mail.passwd is email service authorization code, not the email login password.
# mailSender、mailUser邮箱的密码,安全还是要有的,不然岂不是谁都可以冒名顶替发送了嘛
mailPassword="r@123*qwe"
# TLS mail protocol support 默认值即可
starttlsEnable="true"
# SSL mail protocol support 默认值即可
# only one of TLS and SSL can be in the true state.
sslEnable="false"
#note: sslTrust is the same as mailServerHost 你的邮箱服务器
sslTrust="appmail.rowyet.cn"
# resource storage type:HDFS,S3,NONE 因为博主有hdfs,打算把上传的资源文件放到hdfs,所以这些写hdfs,这里也支持s3,没有则写NONE
resourceStorageType="HDFS"
# 因为博主的是hdfs,则把s3相关的配置注释了
# if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
# 配置hdfs的集群,因为博主的是ha的hdfs,则直接配置集群的名称和8020端口
defaultFS="hdfs://dw-rowyet:8020"
# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
# s3Endpoint="http://192.168.xx.xx:9010"
# s3AccessKey="xxxxxxxxxx"
# s3SecretKey="xxxxxxxxxx"
# if resourcemanager HA enable, please type the HA ips ; if resourcemanager is single, make this value empty 这里配置yarn,因为博主的yarn也是ha的,把两台全部写上
yarnHaIps="10.192.168.20,10.192.168.20"
# if resourcemanager HA enable or not use resourcemanager, please skip this value setting; If resourcemanager is single, you only need to replace yarnIp1 to actual resourcemanager hostname. 默认即可
singleYarnIp="yarnIp1"
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。/dolphinscheduler is recommended
# 这个地方是你资源库上传的存放路径,因为配置在hdfs,所以下面的路劲是hdfs的
resourceUploadPath="/dolphinscheduler/data-1.3.5"
# who have permissions to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="hadoop"
# 因为博主没用到k8s,所以k8s的配置保持默认即可
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username
keytabUserName="hdfs-mycluster@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# api server port 这里是你web ui和api的端口,默认是12345,生产环境建议改改,也是一种安全嘛,不改问题也不大,博主设置9090
apiServerPort="9090"
# install hosts
# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
# 这里是你的整个dolphinscheduler集群的机器,一台都别少
ips="10.192.168.20,10.192.168.21,10.192.168.22,10.192.168.23,10.192.168.24"
# ssh port, default 22
# Note: if ssh port is not default, modify here 默认即可
sshPort="22"
# run master machine
# Note: list of hosts hostname for deploying master 这里是你的两台master
masters="10.192.168.20,10.192.168.21"
# run worker machine
# note: need to write the worker group name of each worker, the default value is "default"
# 这里是你的workerserver,新版本里面work的分组必须配置在这里,如默认的defaul
workers="10.192.168.22:defaul,10.192.168.23:defaul,10.192.168.24:defaul"
# 如果多个分组,这样三台机器属于默认default组,22还属于etl组,23、24还属于realtime组;
# 在运行任务和工作流时你是可以指定worker组的,但是博主觉得这个有点鸡肋,没必要分组,就采用默认的分组吧;
# 因为测试下来调度的瓶颈往往是运行机器本身的资源,如一下子开多了,内存不够,所以worker分组只是利于管理,实际用处不大;
#workers="10.192.168.22:defaul,10.192.168.23:defaul,10.192.168.24:defaul,10.192.168.22:etl,0.192.168.23:realtime,10.192.168.24:realtime"
# run alert machine
# note: list of machine hostnames for deploying alert server
# 邮件告警服务器,一台即可
alertServer="10.192.168.22"
# run api machine
# note: list of machine hostnames for deploying api server
# web ui和api调用的服务器,可以设置多台,且多台之间是相互独立的,可以高可用,挂一台另一台能正常工作
# 缺点也有,目前的版本不支持配置这个组的一个组名,即访问时只能单独写死ip,除非自己配置反向代理,本身不自带两台机器自动故障转移
apiServers="10.192.168.20,10.192.168.21"
特别提醒:
- 如果需要用资源上传到Hadoop集群功能, 并且Hadoop集群的NameNode 配置了 HA的话 ,需要开启 HDFS类型的资源上传,同时需要将Hadoop集群下的core-site.xml和hdfs-site.xml复制到/opt/dolphinscheduler/conf,非NameNode HA跳过次步骤;
- conf文件夹下的其他配置信息
master.properties、master.properties等如果你没有个性化的配置,就不用再修改了,如果想要个性化配置,可参考官网的配置文件; - 到此配置就全部结束了,接下来一键部署;
2.4.5 一键部署
20这台机器已经配置好了,为了方便,就把20这台机器的dolphinscheduler复制到21,22,23,24这些机器上,然后再一键部署启动;
# 以下步骤在21,22,23,24上都需要完成
# 以下步骤在21,22,23,24上都需要完成
# 以下步骤在21,22,23,24上都需要完成
# 以21为例
# 进入/data/tools
cd /data/tools
# 创建总文件夹dolphinscheduler
mkdir dolphinscheduler
# 进入dolphinscheduler
cd dolphinscheduler
# 将20上的tar复制到21
scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz /data/tools/dolphinscheduler/
# 解压
tar -zxvf apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz
# 因为名字老长了,做一下重命名
mv apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin apache-dolphinscheduler-1.3.5
# 将20配置好的datasource.properties复制到21
scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /datasource.properties /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/
# 将20配置好的install_config.conf复制到21
scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /config/install_config.conf /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/config
# 将20配置好的install_config.conf复制到21
scp 10.192.168.20:/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/ /env/dolphinscheduler_env.sh /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/conf/env
# 创建installPath,一定要安装的用户有可读可写的权限
mkdir install-ds-1.3.5
# 创建个当前版本的软链接,后续若有升级、降级操作,只需要改变当前版本软连即可,博主的独到秘籍
ln -sf /data/tools/dolphinscheduler/install-ds-1.3.5 current
# 以上步骤在21,22,23,24上都需要完成
# 以上步骤在21,22,23,24上都需要完成
# 以上步骤在21,22,23,24上都需要完成
# 然后任意选一台机器,这里就选20吧,进入/data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/
cd /data/tools/dolphinscheduler/apache-dolphinscheduler-1.3.5/
# 一键部署启动
sh install.sh
#注意:
# 第一次部署的话,在运行中第3步`3,stop server`出现5次以下信息,此信息可以忽略
# sh: bin/dolphinscheduler-daemon.sh: No such file or directory
# 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的
# 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的
# 正确部署后,这个命令是可以将整个dolphinscheduler集群启动起来的
2.4.6 守护进程与日志
还记得表2.2 集群模式机器部署安排吗,对着自己的机器安排,在不同的机器上执行jps,查看守护进程,以表格2.2为例,各守护进程分布如下;
MasterServer ----- master服务 (20,21机器)
WorkerServer ----- worker服务 (22,23,24机器)
LoggerServer ----- logger服务 (22,23,24机器) 这个不是启动日志,而是你的工作流运行的历史记录
ApiApplicationServer ----- api服务 (20,21机器)
AlertServer ----- alert服务 (22机器)
# 同理各自的启动日志也是跟着各个守护进程的机器的,这个才是集群启动的真正日志
logs/
├── dolphinscheduler-alert-server.log (22机器)
├── dolphinscheduler-master-server.log (20,21机器)
|—— dolphinscheduler-worker-server.log (22,23,24机器)
|—— dolphinscheduler-api-server.log (20,21机器)
|—— dolphinscheduler-logger-server.log (22,23,24机器)
# 还记得配置的web ui端口吗?这个非常重要,可以在(20,21机器)查看下端口是否存在
ss -tnlp | grep 9090
# 一切都正常的可以访问web ui了,正常则查看对应守护进程的日志,看看有啥问题;
2.4.7 访问Web UI
访问Web UI的网址是:http://10.192.168.20:9090/dolphinscheduler或者http://10.192.168.21:9090/dolphinscheduler,http://10.192.168.20:9090/dolphinscheduler,注意看仔细,后面还有一个dolphinscheduler,别漏了,跳转如图2.4.7;
默认账号:admin;默认密码:dolphinscheduler123;登录进去记得改一下 密码,生产环境还是安全点好,不要让你的密码别人一猜就中;

2.4.8 启动与关闭守护进程
和日常的java守护进程一样,放在文件件install-ds-1.3.5/bin/下,注意这里最好就使用你的install-ds-1.3.5目录下去开启了,最好能测试下是否能正常 启动与关闭守护进程;
特别提醒:java程序有时候会出现stop不掉的情况,实在stop不掉,就直接kill,但是优先stop,因为stop其实会做一下守护进程的安全退出工作,kill则是异常退出;当然也会有start不成功的,那就需要你去查看下install-ds-1.3.5/logs/相应服务的日志,查看下为啥start失败了,这个原因有很多,自己网上百度下对症下药吧;
# 一键停止集群所有服务
sh ./bin/stop-all.sh
# 一键开启集群所有服务
sh ./bin/start-all.sh
# 启停Master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停Worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停Api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
到此整个安装部署就完成了,官网还绑定一块企业微信告警,个人觉得,并不是大多数的公司都适合企业微信告警,支持企业微信的可以按照官网配置,比如博主就喜欢钉钉告警,这
以上是关于Apache DolphinScheduler 征稿 —开源大数据调度器Apache DolphinScheduler安装维护与实践的主要内容,如果未能解决你的问题,请参考以下文章
Apache DolphinScheduler 征稿 — 极速入门Apache DolphinScheduler分布式调度系统
Apache DolphinScheduler 征稿 —开源大数据调度器Apache DolphinScheduler安装维护与实践
Apache DolphinScheduler征稿-DolphinScheduler的入门级教程及案例