超详细版企业离线部署CDH6.10集群与配置使用
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细版企业离线部署CDH6.10集群与配置使用相关的知识,希望对你有一定的参考价值。
进入大数据行业数载,也从一个开发小白走到了今天,期间也历经过一摸番着石头过河的探索,到如今的胸有点墨;玩过demo,使用过负责过上千节点的大数据集群开发与使用;被人面虐过,也面跪过一些人。如今,趁着自己心中有火,眼里有光的年纪,把自己的一点心得与经验分享大数据行业的爱好者。也希望有助于后面的童鞋少走弯路,欢迎大家私信交流。持续每周更新。

死磕大数据系列
- 1.死磕大数据系列将从企业上千节点集群的搭建(包括cdh集群,以及升级后apache hadoop3集群),性能优化,牵扯到的组件包括HDFS,MapReduce,YARN,Hive,Spark,Zookeeper,Hbase,Kafka,Flink,Flume等搭配使用与优化,这次不搞demo,只展示大规模集群的生产应用与实施方案;
- 2.深入组件内部死磕HDFS内部原理,NameNode性能优化,datanode数据存储设计,深入HDFS的存储架构,知其然又知其所以然,实时分享大规模集群存储相关设计,优化以及实战运维经验;
- 3.死磕MR/Hive,Spark等计算引擎,实时案例展示企业开发中遇到的性能瓶颈,异常分析与性能优化,解决方案;我一直觉得只有碰到过性能瓶颈才能谈优化,脱离此都是纸上谈兵。
- 4.死磕YARN三大组件,RM,NM,APPmaster,展示上千节点集群资源调度设计,优化改造的方案与实施;让你明白集群优化前后的巨大差别,合理优化的重要性;
- 5.死磕Kafka/Flume,SparkStreaming等流式组件,展示日均500Tb流式数据组件设计与使用,分享遇到的性能瓶颈与组件优化;
- 6.死磕大数据架构,案例分析让你见识企业中数仓建模的来龙去脉,上百PB数据的处理,你会发现实战其实与书本相差甚远。大规模集群组件的选型与设计;大厂实际中大数据开发与管理的规范,如何提高效率;
1.生产CDH集群搭建前准备
对于大数据初学者,强烈建议使用cdh版本,使用cm搭建管理集群进行测试,学习。因为更加好用,方便,直观,见识下啥叫成熟的架构。学习要先见森林,再见树木,最后再见森林。不要一头扎进去linux黑窗口,那不是酷,那是傻。可以说80%的大数据开发者在大厂里是不允许直接操作linux跳板机的,而是成型的,成熟的,稳定的大数据web开发环境。
中小型的公司,使用CDH集群的还是很多,因为实在很方便,免费的且强大的功能。一般中小型公司节点个数从几十台到几百台不等,可以考虑使用CDH。但是现在CDH和HDP合并了,从今年2月以后CDH不支持在线下载安装了(收费),且免费的版本不超过100台节点了,很多功能还用不了。像我们公司上千节点,现在都在迁移开源的 Apache Hadoop3了,组件的二次开发,监控平台开发等成本很高。
但是学会CDH的生产部署,在小公司还是有市场的。安装部署集群前,最重要的是先把集群的主要服务架构部署清楚,一般生产上稍微规模大点的集群,核心服务都会使用单独的服务器,不会在上面开启计算和存储节点的。考虑成本的话,也会在不影响集群核心服务的同时存储计算等混合使用。
下面以十几台服务器为例,全流程展示生产CDH集群的安装与使用,展示使用的系统centos6.9,linux命令比较简单,centos7的话对应命令直接百度。关于CDH集群组件与介绍等可以百度,也可以参考CDH官网手册,可以这里下载
链接:https://pan.baidu.com/s/1MRbwWSgyvo9vQMuI5Xq8OQ
提取码:abcD
1.1 安装前服务器核心配置与检查
1.1.1.关闭防火墙
参考命令:service iptables status/ stop
1.1.2.关闭 Selinux
参考命令:vim /etc/selinux/config --> SELINUX=disable
1.1.3.所有主机hosts-ip映射到每个hosts
参考命令:vi/cat /etc/hosts
实际上大规模集群,规范化集群都不用这种hosts方式,低效,一般都用dns解析。
1.1.4.配置主机账号密码一致
参考命令: passwd
配置所有主机的root或者具有root权限账号的密码一致,方便后面操作。
1.1.5 JDK配置
所有主机的jdk环境可以不部署,下面安装的时候使用自带的通过自定义yum源安装
1.1.6 磁盘格式化,挂载等
一般一台服务器至少8T*12盘,磁盘需要格式化成某种特定格式,然后挂载到服务器上。可以使用脚本一键格式化,一键命名挂载所有磁盘。如果是虚拟机搭建可以不考虑。网上搜下很多成熟的脚本。
1.1.7 NTP时间同步服务器搭建
各个服务器之间时间要同步 ,一般所有服务器的时间以某台节点为准。
1.所有节点安装ntp服务
参考命令:yum install -y ntp ntpdate
chkconfig ntpd on 设置开机自启动
2 修改配置文件:
修改主服务器 vim /etc/ntp.conf 一下是主服务的配置,安装时可以粘贴替换使用
driftfile /var/lib/ntp/drift
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict -6 ::1
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
restrict 10.0.0.0 mask 255.0.0.0 nomodify
修改其他从服务器的配置文件,可以使用一键分发脚本,ansible等工具
修改所有从服务器 vim /etc/ntp.conf
注释掉所有server打头的配置项,添加如下配置项:
server 10-90-50-52-jhdxyjd.mob.local 这个是主服务器的主机名3.先重启主服务器,再重启从服务器,命令一样
参考命令:service ntpd start
查看同步状态ntpq -p,其他从服务器是否从主服务器同步时间

这些基础配置,如果是大厂的话,一般会有专门的基础运维处理;
2. CDH 6.1.0的CM安装
注意CDH集群的安装与开源的Apache Hadoop不同,非常方便。只需要单节点安装一个cm server 管理即可,后面所有服务的安装部署,参数优化等都可以通过部署的cm节点的web界面去操作了。
2.1为啥需要配置yum源?
现在cdh也不支持在线安装了,除非你有cm的账号,否则免费版只支持离线安装。 CDH集群的安装简单就简单在他只需要配置yum源。不需要每个节点都分发cm的安装包,只需要配置一个web的网络yum即可,其他节点安装使用时,直接从这个节点下载分发使用即可。所有配置yum源就是配置网络yum源。
cdh6.1生产需要的所有离线包,直接下载即可。
链接:https://pan.baidu.com/s/1MRbwWSgyvo9vQMuI5Xq8OQ
提取码:abcD
2.2 配置主节点yum源
选一个装cm的主节点,后面的操作都基于这个节点即可。比如我这里选择的是10.90.50.52这台服务器,在这台节点配置yum源和安装cm管理。
2.2.1 安装httpd 服务&启动httpd
参考命令:yum -y install httpd
chkconfig httpd on 添加开机自启动
service httpd start 启动httpd服务
这个安装好了可以10.90.50.52:80 web打开界面
2.22 配置yum 仓库
下载所有CDH6.1.0离线安装需要的包与依赖。
链接:https://pan.baidu.com/s/1MRbwWSgyvo9vQMuI5Xq8OQ
提取码:abcD
1.上传 cm6.1.0.tar.gz 到/var/www/html目录下(目录没有话,直接创建,注意这个目录不要改,是cm默认安装目录,可以改,但是你要熟悉)并解压
参考命令:cd /var/www/html/;tar -zxvf cm6.1.0.tar.gz

2.配置yum 源文件:
参考命令:cd /etc/yum.repos.d/
vim cloudera-manager.repo 添加如下内容:
#当前ip就是你配置cm主节点与网络yum源的节点
[cloudera-manager]
name = Cloudera Manager, Version
baseurl = http://10.90.50.52/cm6.1.0/
gpgcheck = 13.检查配置是否成功
参考命令:yum list | grep cloudera 有如下输出即可

或者直接在浏览器中访问 http://10.90.50.52/cm6.1.0/
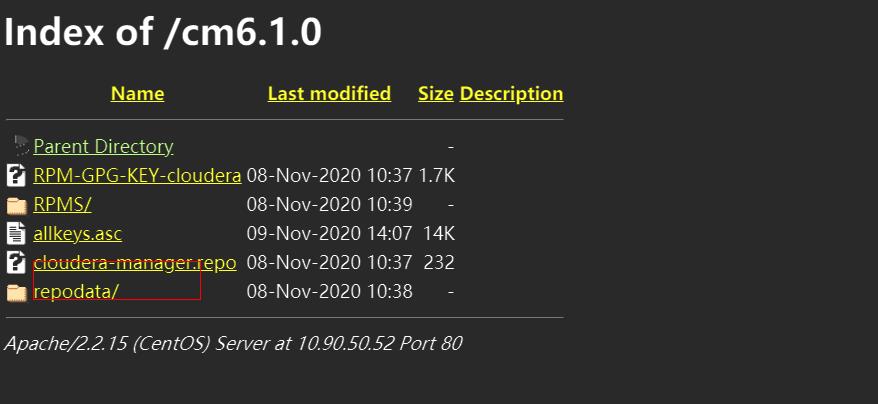
2.3 安装mysql
mysql主要作用是存储cm,各个组件等相关元数据信息,比如hive的元数据,可以共用一个mysql数据,也可以分开mysql,比如我们之前生产hive元数据的存储用的就是pg,高可用。小集群一般不分开没啥事,但为了元数据的安全要配置mysql的高可用,或者定时同步mysql元数据进行备份。
1.上传上面下载的mysql安装包到服务器,将其解压到指定路径,随便都可以。这里使用的是 /data/centos6为例
参考命令: tar -xvf mysql-5.7.33-1.el6.x86_64.rpm-bundle.tar -C /data/centos6
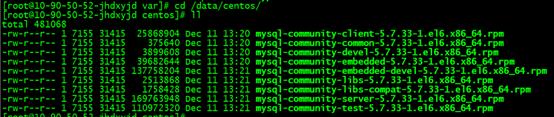
2.进入解压目录,执行yum 安装
cd /data/centos6;
yum install -y mysql-community-{server,client,common,libs}-*;
可以参考mysql配置你文件,修改mysql数据存储路径等,大规模生产有必要。
more /etc/my.cnf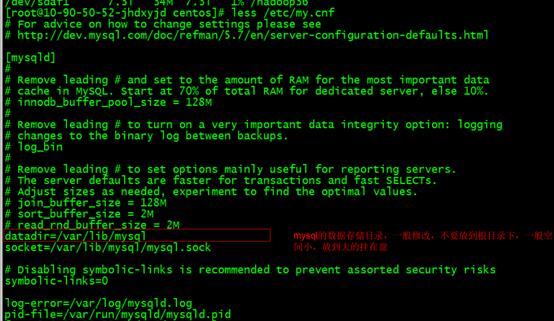
3.等待安装完成,初始化数据目录
mysqld --defaults-file=/etc/my.cnf --initialize-insecure --user=mysql4.初始化完成,启动mysql服务
service mysqld start;
chkconfig mysqld on 设置开机自动5.执行mysql客户端命令mysql,进入mysql,修改root密码;
这里密码以123456为例
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
mysql> grant all privileges on *.* to 'root' @'%' identified by '123456'; ##修改远程可访问注意后面还需要创建一些数据库,等使用时在创建吧,这样你知道为啥创建
2.5 主节点安装CM-server
2.5.1 jdk的安装
yum -y install oracle-j2sdk1.8.x86_64
yum -y install oracle-j2sdk1.8-1.8.0+update141-1.x86_64.rpm2.5.2 安装依赖(如果上面报依赖的错误)
yum -y install cyrus-sasl-gssapi fuse-libs MySQL-python openssl-devel fuse lsb portmap mod_ssl python-psycopg2 libxslt2.5.3 安装主服务
yum install -y cloudera-manager-server.x86_64 cloudera-manager-daemons.x86_64 cloudera-manager-agent.x86_641.安装后修改 cm_server 的配置文件
vim /etc/cloudera-scm-server/db.properties
注释掉此行 #com.cloudera.cmf.db.setupType=INIT
添加如下内如:
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=localhost
com.cloudera.cmf.db.name=scm
com.cloudera.cmf.db.user=scm
com.cloudera.cmf.db.setupType=EXTERNAL
com.cloudera.cmf.db.password=scm
2.登入mysql 创建上面配置的用户和数据库

mysql> create database scm DEFAULT CHARACTER SET utf8;
mysql> grant all on scm.* TO 'scm'@'%' IDENTIFIED BY 'scm';
3.上传添加安装包里的mysql-connector-java.jar包到指定位置
cd /opt/cloudera/cm/lib; 添加进到这个目录
上传完以后检查一下ll /opt/cloudera/cm/lib/mysql-connector-java.jar

2.5.4 配置本地的parcel 文件
cd /opt/cloudera/parcel-repo ,需要将上面百度网盘下载parces文件copy到这个目录下。此目录下有以下三个文件(注意此目录的权限,应该是用户cloudera-scm所属权限),总共三个文件,如下图所示。
![]()

2.5.5 启动cm server
1.启动 cm_server
service cloudera-scm-server start 如果显示【ok】
2.也进入日志目录,查看日志详情
cd /var/log/cloudera-scm-server/; tail -f cloudera-scm-server.log
出现一下内容表示启动成功:

3.端口检验,cm 默认使用7180端口(也可以改),所以要在本地能通服务器10.90.50.52:7180。否则打不开cm界面,无法进行下一步。
netstat -anptl | grep 7180


2.5.6 登录wed页面进行相关服务组件添加
初始用户名密码:admin/admin
cdh集群的默认的超级用户是hdfs
到此结束,cm server已经安装好了,后面所有的zookeeper,hdfs,yarn,hbase,hive,spark,flume,kafka等组件的安装配置,配置优化,节点添加,退役等等都可以通过这个界面进行操作了。
3. 基于CM安装配置大数据组件与应用
3.1 cm的监控与配置等安装
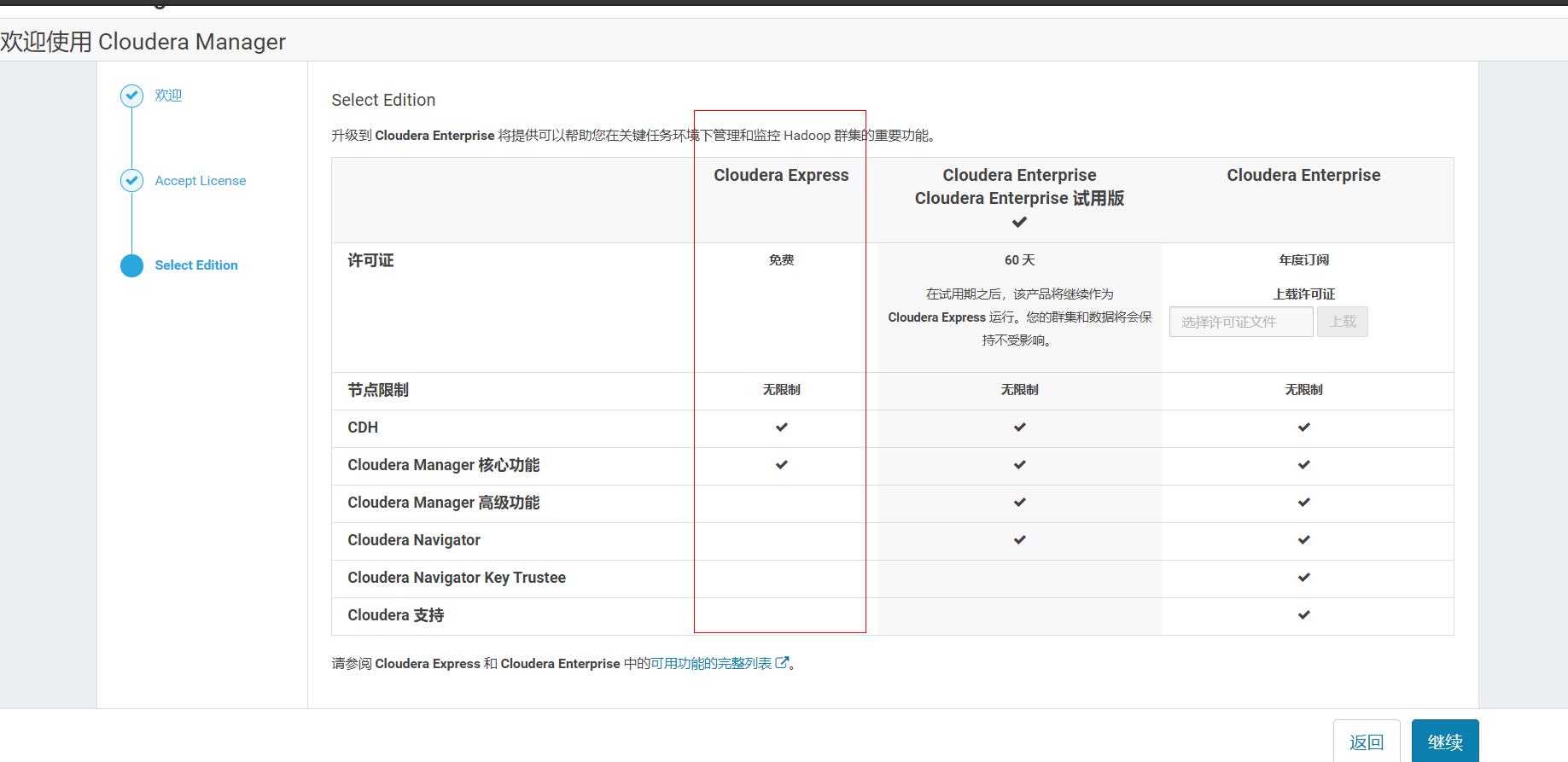
上面安装好10.90.50.52的cm后,admin/admin登录进去,如下界面,配置cm的基础信息,


注意,这里要选择免费版本
下面直接继续,默认完成即可。然后选择集群安装
注意,默认端口22不用更改,我这里更改是因为公司修改了默认端口。
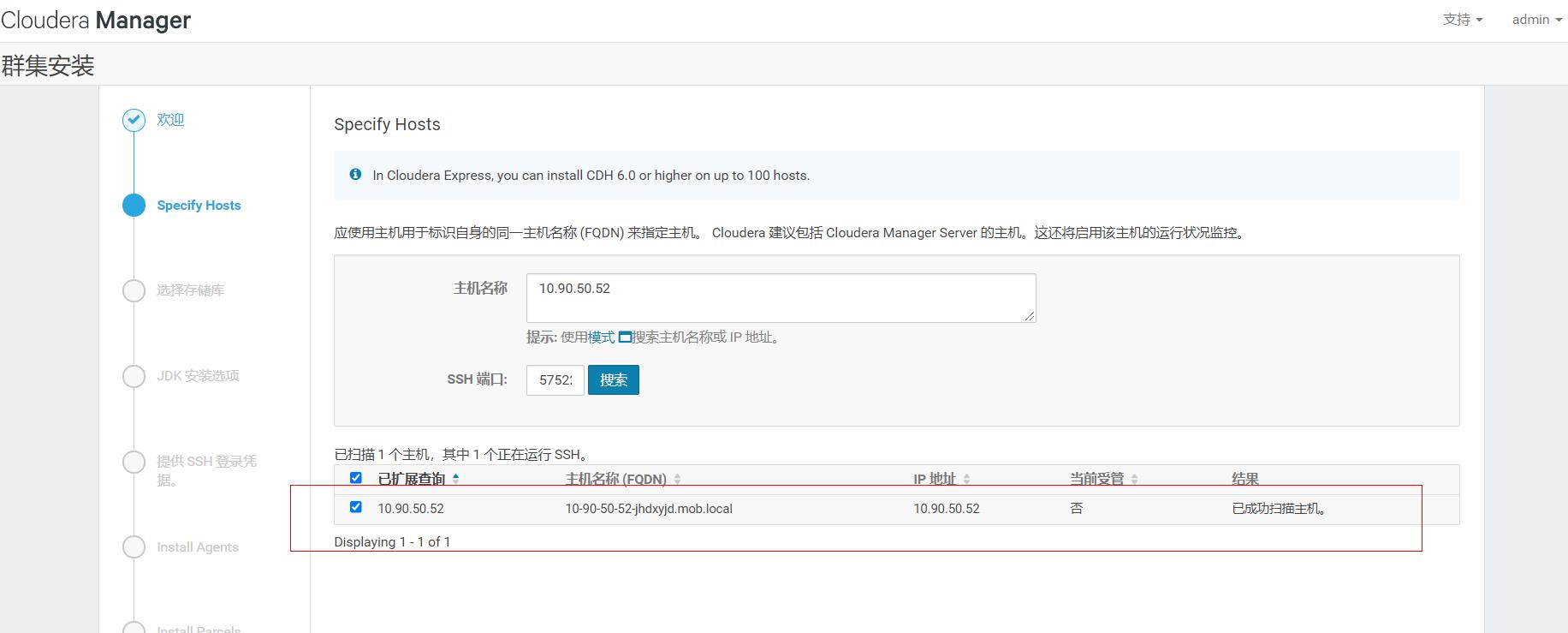
这一步要注意:yum源地址就是上面配置的,注意版本,是否跟提供的安装包一致,一般一样的。

jdK使用cdh自带的即可,cdh要求orace-jdk.

下面直接输入主机密码,建议所有主机刚开始统一设置密码,方便后面操作。


安装过程也可以后端查看进度

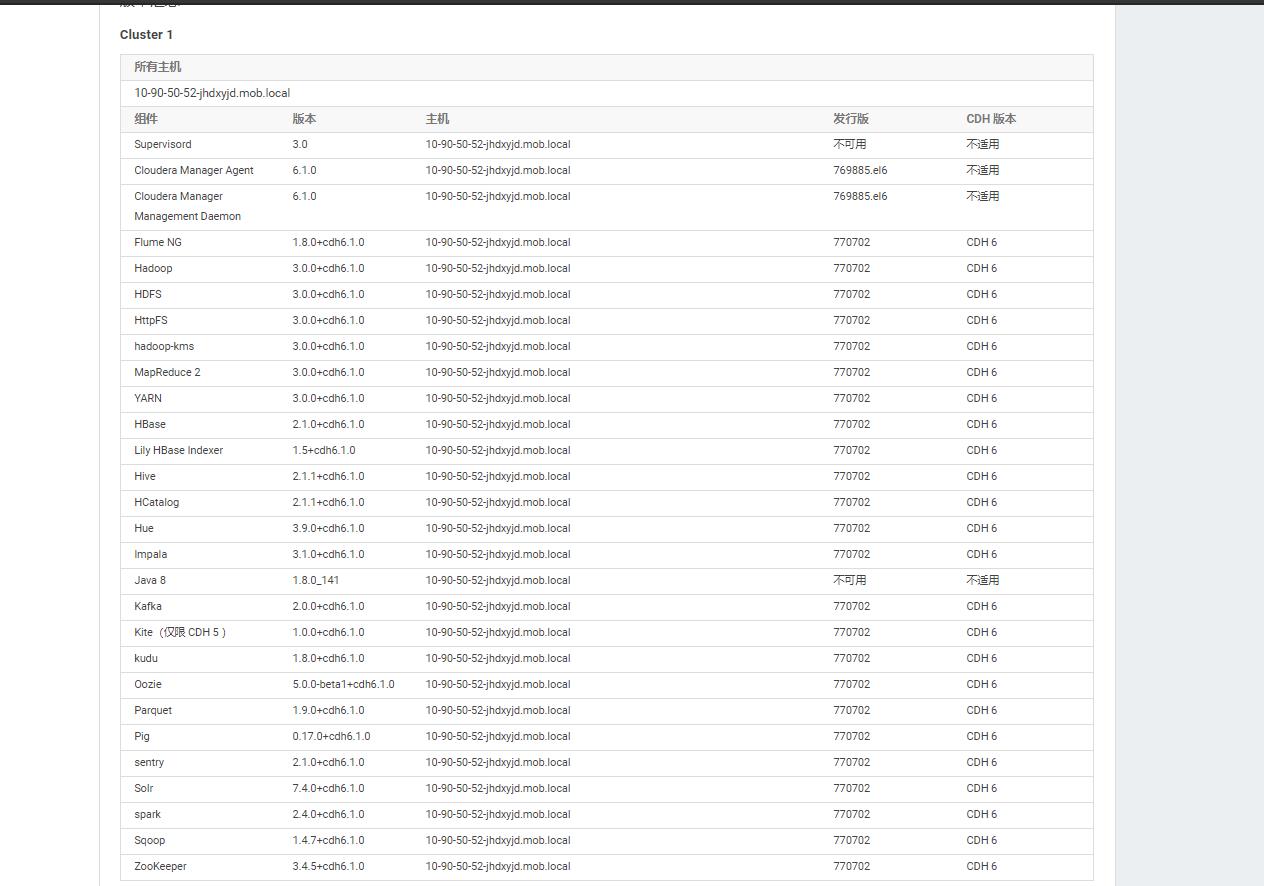
等待继续,直到安装完成,可以看到cm6自带了哪些版本的大数据组件,非常丰富。
cm安装好了,添加cm的监控服务.
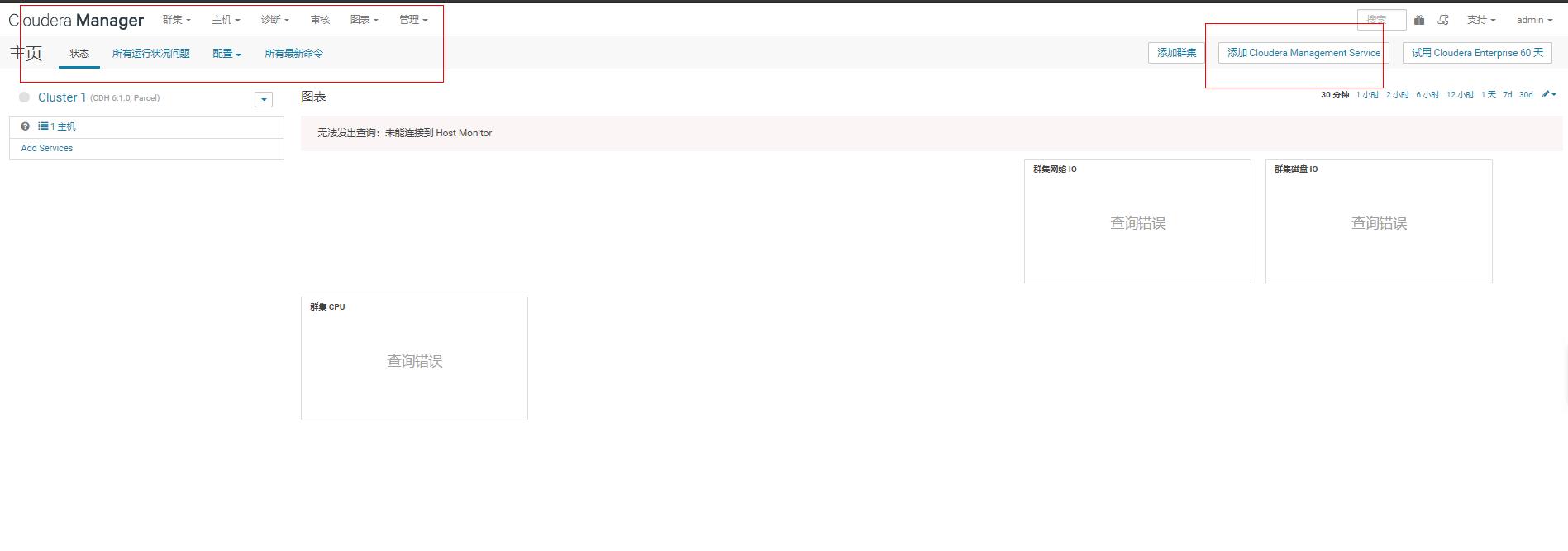
cm自带很多服务,比如分发,监控等,可以将这些服务分开安装不同机器,也可以放到一台机器。这里是放到一台机器,规模不大,这些服务也不怎么消耗性能。下面的安装直到下一步即可,安装完成可以在cm界面查看。
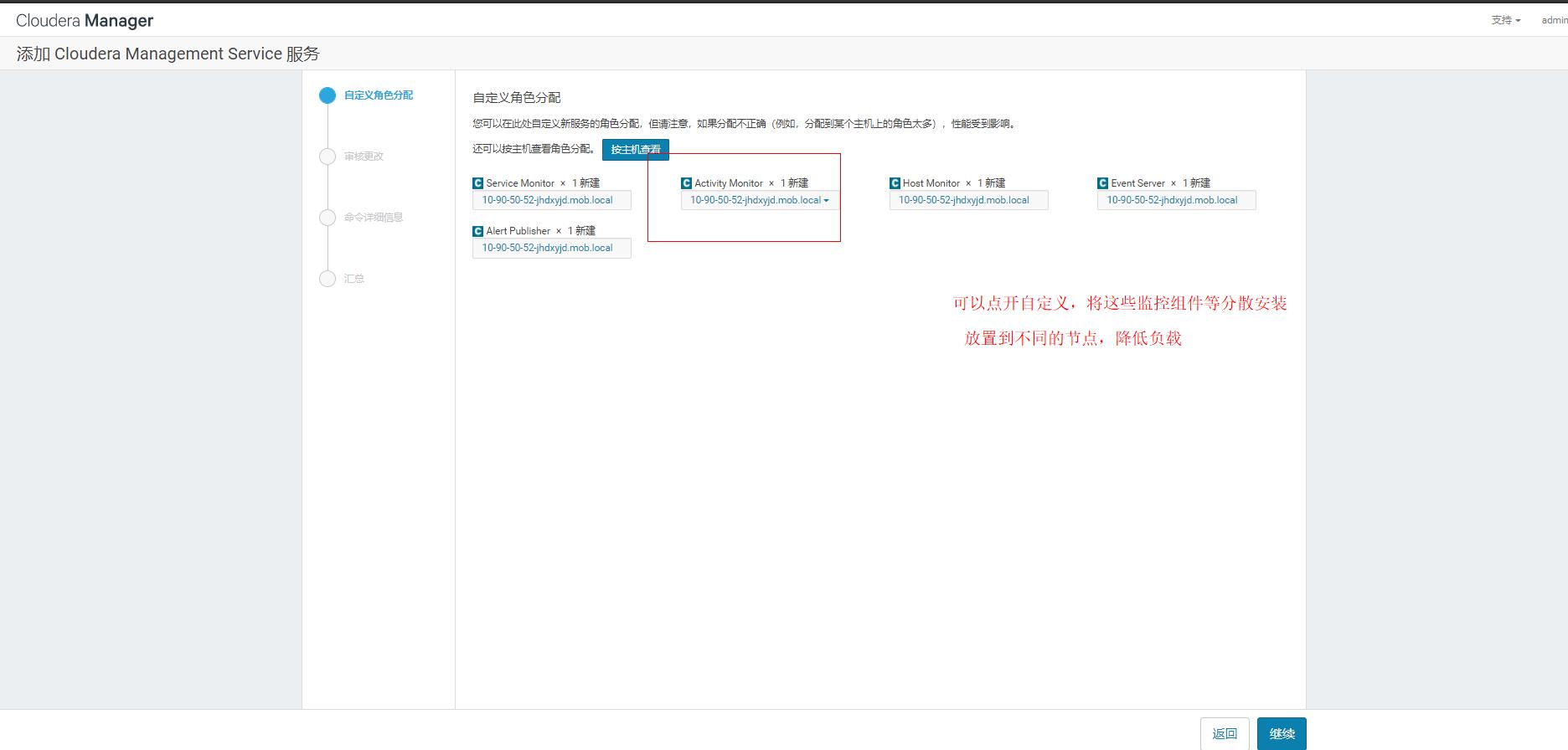
注意这里需要在10.90.50.52的mysql中创建一个元数据库给active_monitor存放元数据
mysql> create database Active_Monitor DEFAULT CHARACTER SET utf8;
mysql> grant all on Active_Monitor.* TO 'Active_Monitor'@'%' IDENTIFIED BY 'Active_Monitor';
点击完成后:各图标开始有监控指标


3.2 添加主机,进行大数据组件安装
上面讲cm的所有服务都安装10.90.50.52上,生产上也可以分开,小规模集群也无所谓。这个节点只装服务即可。然后安装集群,需要先添加主机,添加一定数量的主机,完成大数据主服务的安装,其他就是扩容DN,NM节点而已,很简单。比如,一般大数据集群,至少有6台用来安装主服务,且配置相对要好,尤其namenode节点,都是ssd固态硬盘等,内存条也贼好。集群的安装,要先设计好组件架构

3.2.1添加主机
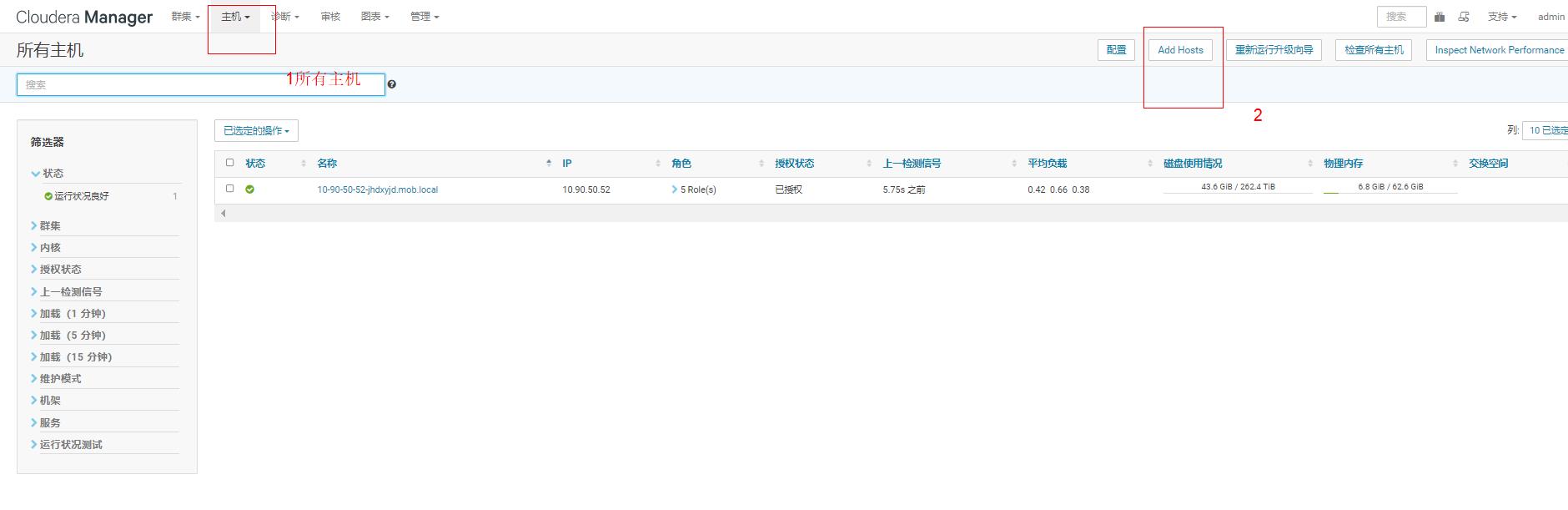
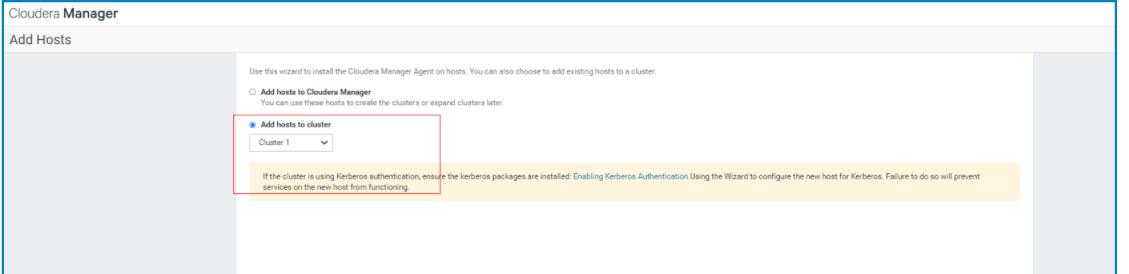
直接将需要添加的主机,全部粘贴到这个文本框里然后检索

注意这里是给添加到集群的主机,配置yun源的,然后继续
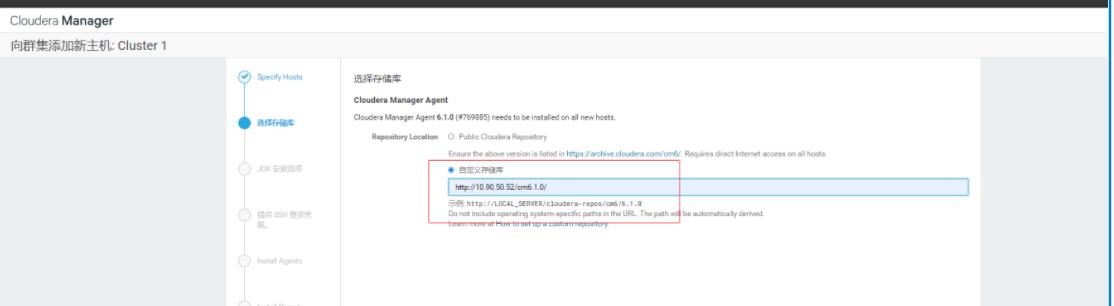

配置密码,cdh的安装不需要ssh,直接配置密码即可

下一步直到安装完成,主机检查可以跳过,直接点回主页即可,查看添加成功的主机

3.3 大数据组件Zookeeper的安装
cdh组件的安装是分开的,不想apache,一个hadoop包,可以安装好yarn,hdfs等,cdh把不同组件拆分安装,方便单独配置。集群安装的第一步zookeeper.
1.首页,添加服务,选中zookeeper.
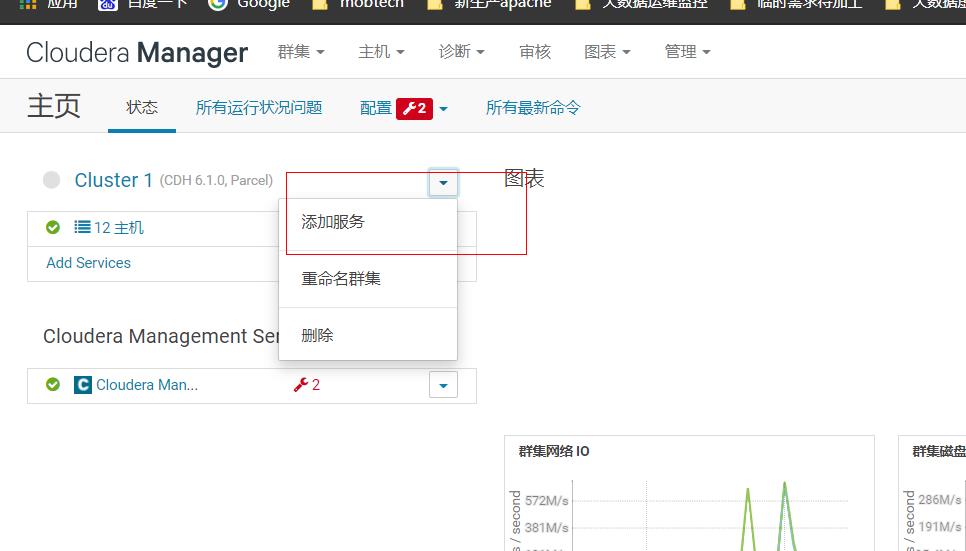
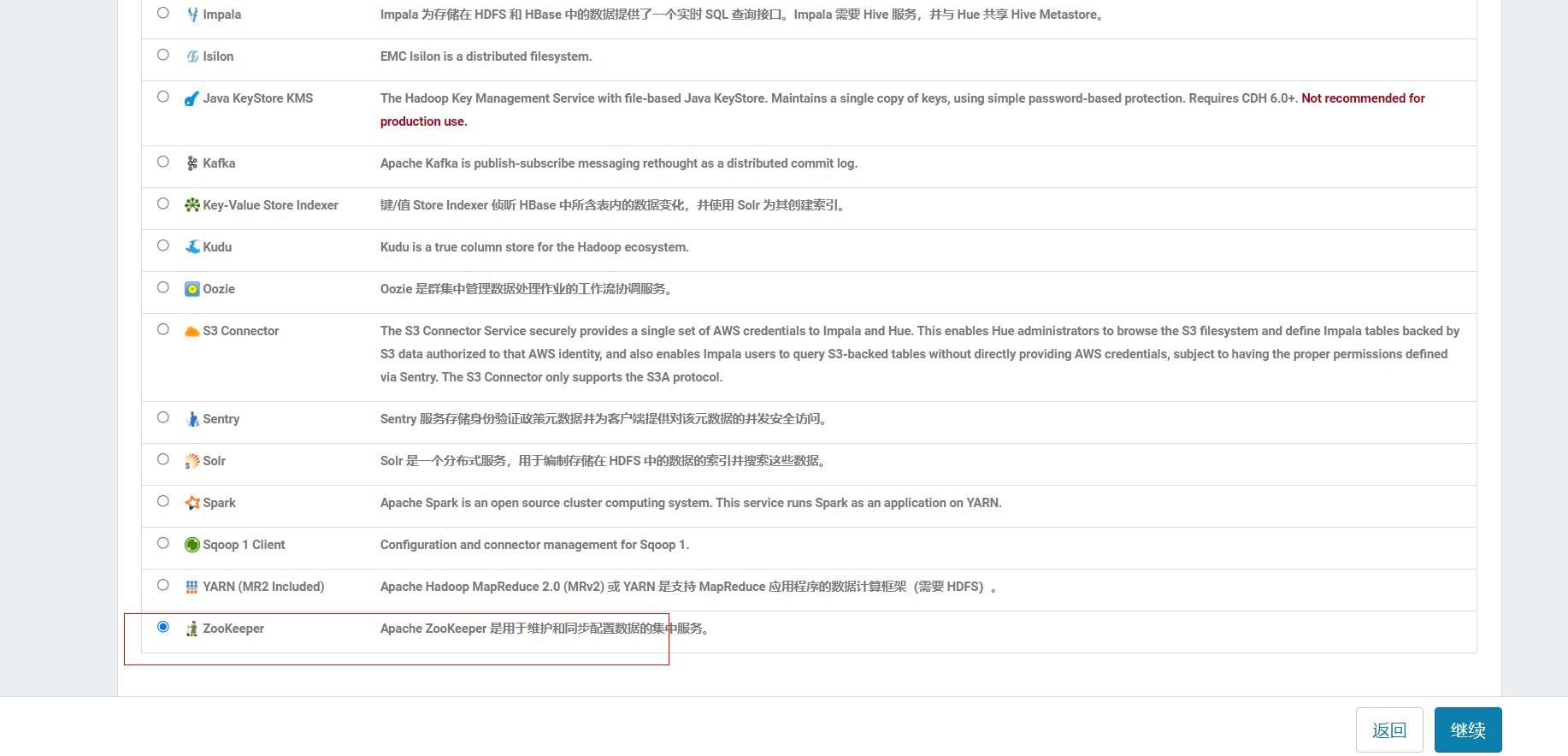
这里zookeeper装3台,选择三个节点,装5台就选5个节点即可

后面全部可以默认安装完成即可,当然也可以修改部分安装存储目录。新手不建议修改。
3.4 安装HDFS组件,配置HA,JN
1.首页,添加服务,选中hdfs
注意这里配置的secondarynaenode节点后面是为了ha的,备namenode。
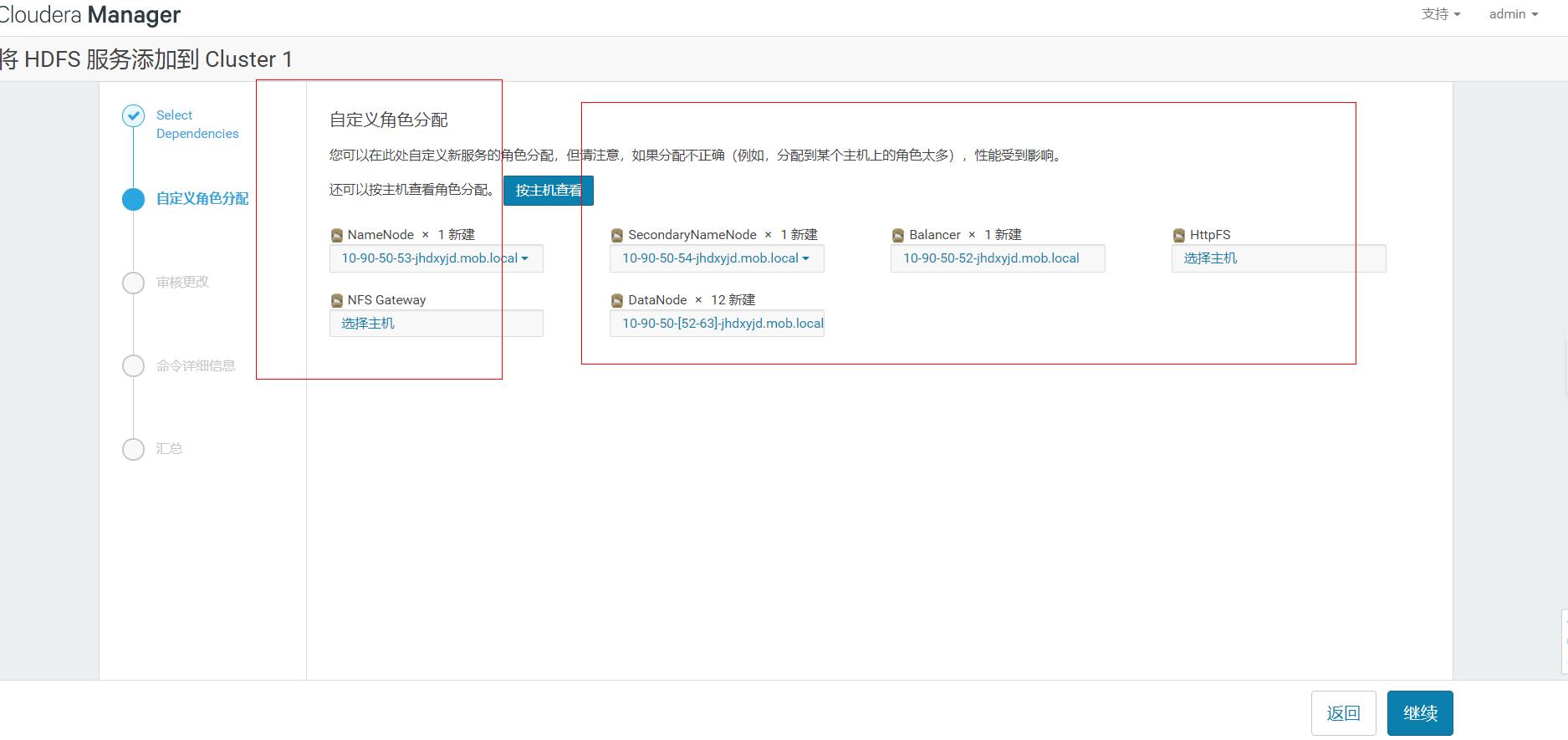
这里需要注意,一般cdh6很智能了,会自动检索你主机挂载的盘符,根据盘符的数量进行自动分组。你也可以修改一些参数,当然也可以安装后在统一修改。后面直接默认,下一步安装完成即可。

然后点击启动namenode ha,配置JN,完成即可

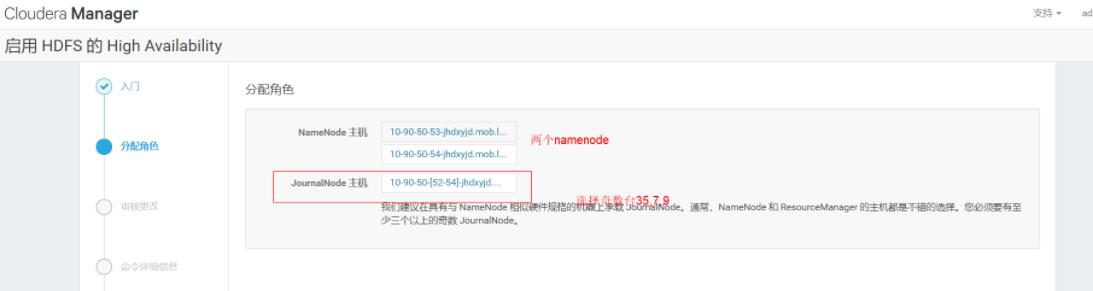
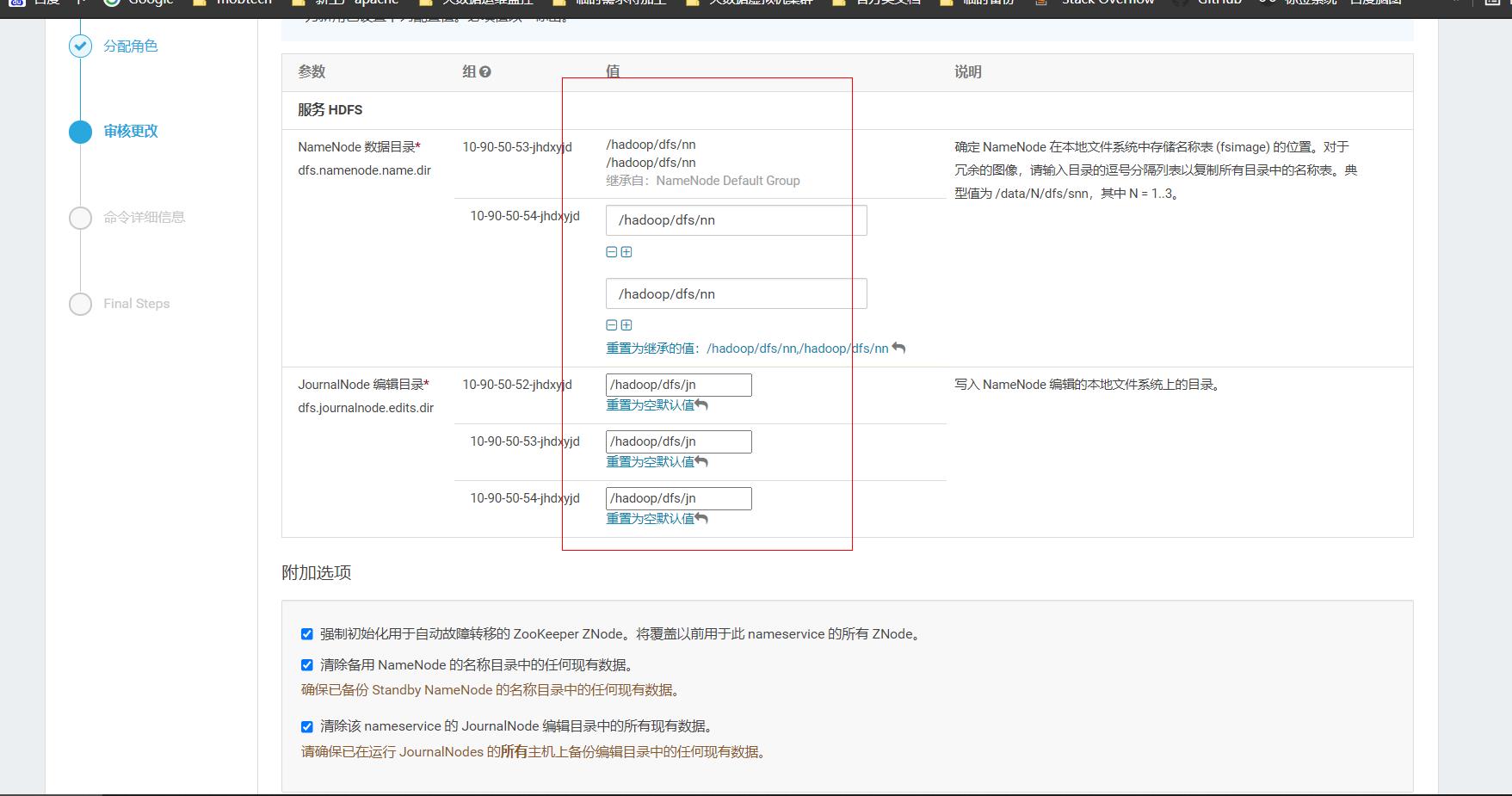
这里配置对应namenode本地存储目录,然后继续下一步,后面的主机检查可以忽略跳过。然后hdfs就安装完成了。
3.5安装YARN组件,配置HA
1.首页,添加服务,选中YARN


然后直接下一步安装跟上面hdfs安装一样,最后完成即可,启动 ResourceManager HA,添加ha两台主机,下一步即可,装好以后这些服务会自动重启。这里NM,RM安装在同一个节点,实际生产可以分开,配置不同主机即可。
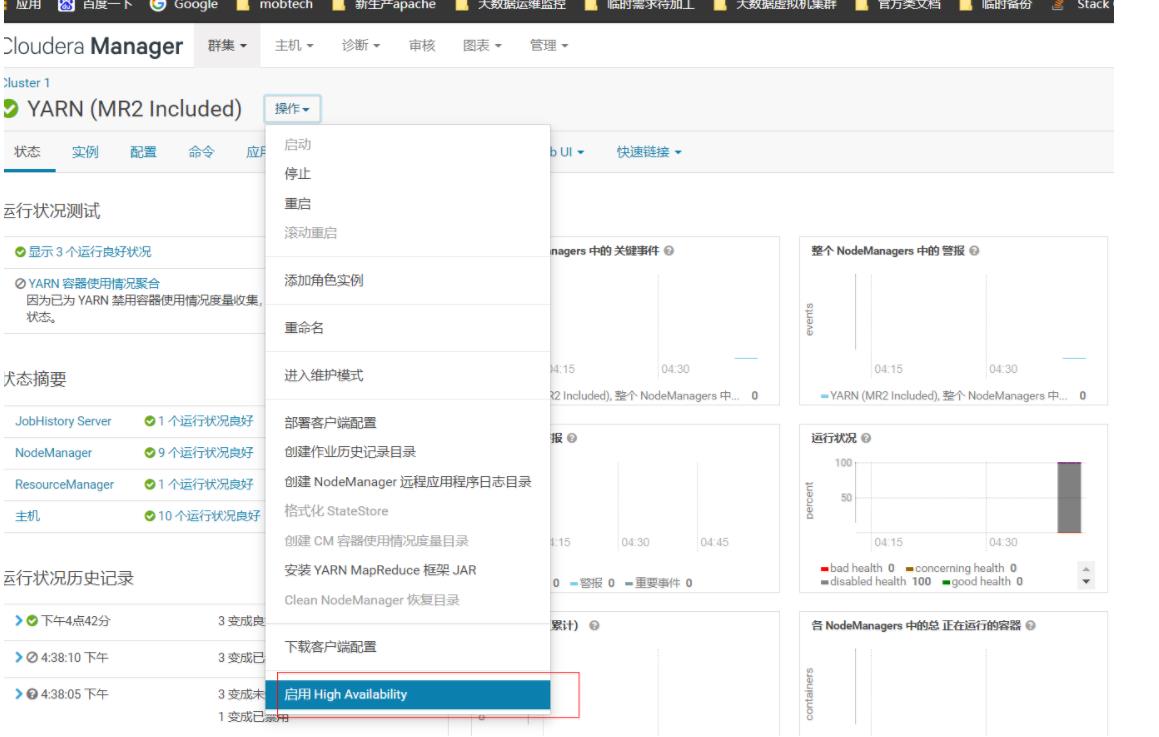
3.6安装Hive组件
1.首页,添加服务,选中Hive
注意 hive gateway其实就是hive客户端,根据需求配置,我这里都分发了,也可以后面配置。

注意,这里需要在10.90.50.52上创建mysql里数据库,库名这里以hive_metastore为例,存储hive元数据。
mysql> create database hive_metastore DEFAULT CHARACTER SET utf8;
mysql> grant all on hive_metastore.* TO 'hive_metastore'@'%' IDENTIFIED BY 'hive_metastore';
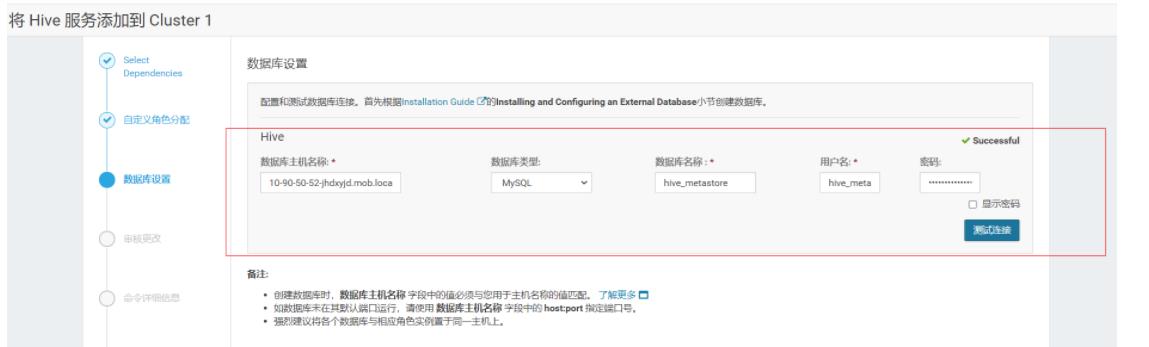
注意,这里直接安装会报错,需要把mysql的jdbc连接放到hive/lib目录下,这个跟apache一致
cp /opt/cloudera/cm/lib/mysql-connector-java.jar /opt/cloudera/parcels/CDH/lib/hive/lib/

安装完后,可以创建hive数据库,要用hdfs超级管理员操作
export HADOOP_USER_NAME=hdfs ,hive
3.7 Spark的安装与配置
1.首页,添加服务,选中Spark
2.注意安装完后,spark history需要手动重启

4. 生成集群监控指标
上面所有的图标支持拖拉,生成指标,如下,命令可以去cdh官网查询,或者可以打开图标查看命令格式。

5.集群优化,参数配置
可以进去不同组件,配置里,修改默认的参数。比如NodeManager的资源分配等,这些是不能使用默认值的。


以上是关于超详细版企业离线部署CDH6.10集群与配置使用的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术栈-Hadoop3.3.4-完全分布式集群搭建部署-centos7(完全超详细-小白注释版)虚拟机安装+平台部署