搭建Hadoop集群(超详细版)
Posted sparename
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建Hadoop集群(超详细版)相关的知识,希望对你有一定的参考价值。
硬件准备
集群配置
本次利用云服务器搭建Hadoop集群, 在开始之前,你需要3台云服务器,可以在同一家购买也可以在不同家购买。此次教程采用百度云产品,可以换不同账号新手免费试用几个月,具体配置如下:
| 服务器名称 | 配置 | 磁盘容量 |
|---|---|---|
| master | 2cpu 内存4GB | 40G |
| slave1 | 1cpu 内存2GB | 60G |
| slave2 | 1cpu 内存2GB | 60G |
集群规划
| 服务器IP | 180.76.231.240 | 180.76.53.4 | 106.12.160.115 |
|---|---|---|---|
| 主机名 | master | slave1 | slave2 |
| Namenode | 是 | 否 | 否 |
| secondaryManager | 是 | 否 | 否 |
| DateNode | 是 | 是 | 是 |
| RecourceManager | 是 | 否 | 否 |
| Nodemanager | 是 | 是 | 是 |
Hadoop、Zookeeper、Java、CentOS版本
| Hadoop | Zookeeper | Java | CentOS |
|---|---|---|---|
| 2.7.7 | 3.4.14 | 1.8.0_171 | 8.4 x86_64(64bit) |
基础环境配置
关闭防火墙
systemctl stop firewalld
systemctl status firewalld

修改主机名
hostnamectl set-hostname master
hostname
主机映射
3个虚拟机均需要修改hosts文件
vi /etc/hosts
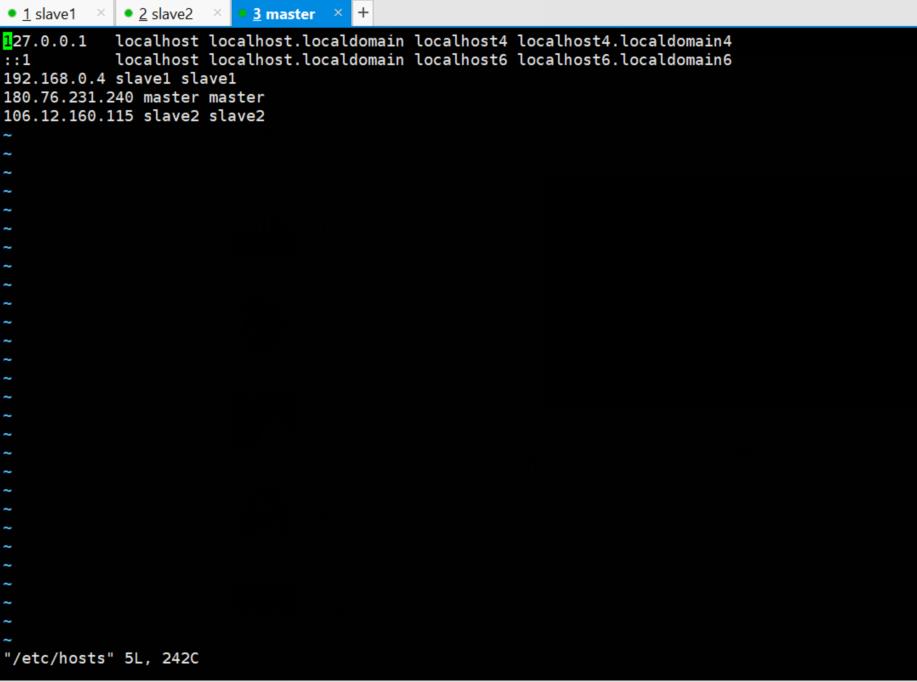
使其生效
source /etc/hosts
注意,因为是云服务器,会有两个ip,一个是内网IP,一个是外网IP,我们在设置hosts时,对于要设置的服务器,IP为内网,而对于其他服务器,要设置外网IP。
测试三台机器,是否ping通
ping master
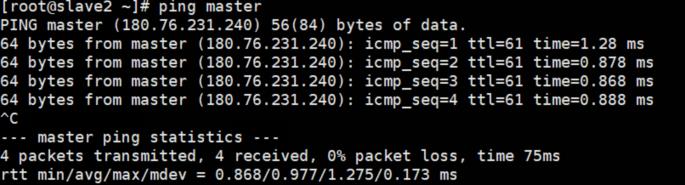
ping slave1
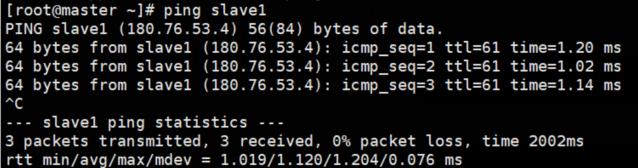
ping slave2

时间同步
查看主机时间
date
选择时区
tzselect
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
时间同步协议NTP
yum install -y ntp//三台机器安装ntp
master作为ntp服务器,修改ntp配置文件
vim /etc/ntp.conf//master执行
屏蔽掉默认的server,设置master作为时钟源,设置时间服务器的层级为10。
#注释掉server 0 ~ n,新增
server 127.127.1.0
fudge 127.127.1.0 stratum 10
重启ntp服务(master上执行)
/bin/systemctl restart ntpd.service
slave1,slave2操作
ntpdate master
定时任务crontab
crontab -e
输入i,添加定时任务
*/30 8-17 * * */usr/sbin/ntpdate master //早8晚五时间段每隔半个小时同步
*/10 * * * */usr/sbin/ntpdate master //每隔10分钟同步一次
*/30 10-17 * * */usr/sbin/ntpdate master //早十晚五时间段每隔半个小时同步
查看定时任务列表
crontab –l
配置ssh免密
生成公钥和私钥:
ssh-keygen -t rsa //三台都要
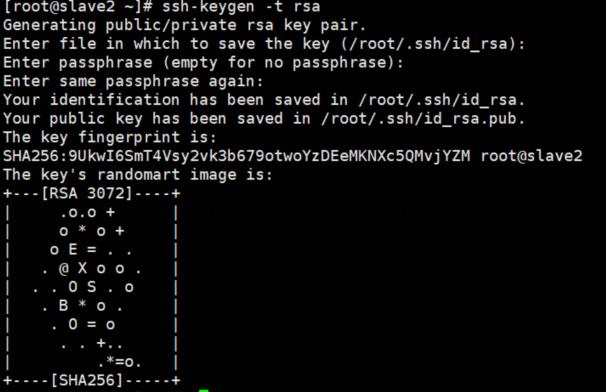
连续按3次Enter键,会在当前用户家目录下生成隐藏目录.ssh,里面包含私钥id_rsa和公钥id_rsa.pub
将公钥复制到要免密登录的服务器上:ssh-copy-id 服务器名
ssh-copy-id master
ssh-copy-id slave1
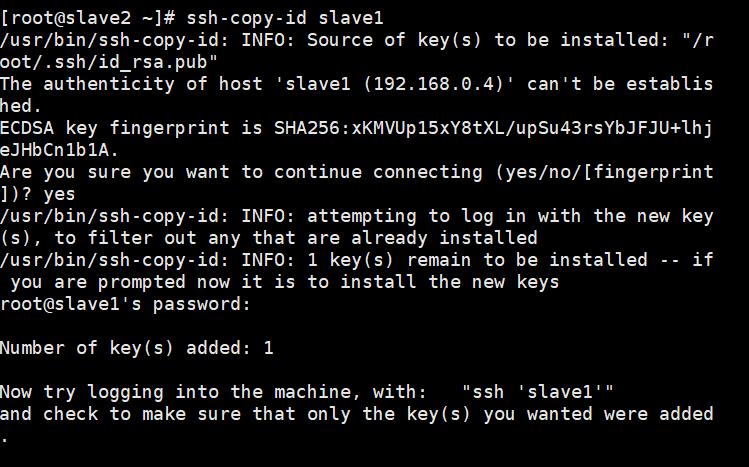
ssh-copy-id slave2
会让你确认是否要连接,输入yes
再输入对方主机的密码即可。在这里,我选择将各台服务器都相互免密登录,大家在实际过程中可按需求选择要免密的主机。
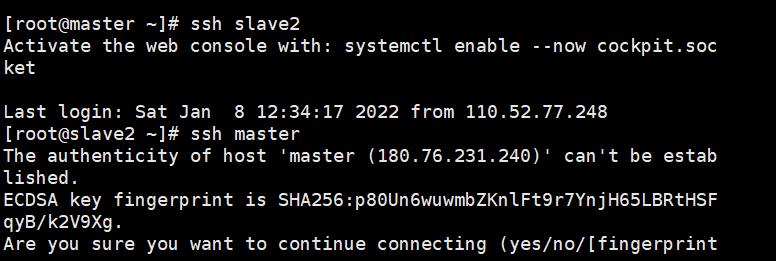
验证免密效果,分别测试免密效果:ssh 想要登录的主机名
ssh master
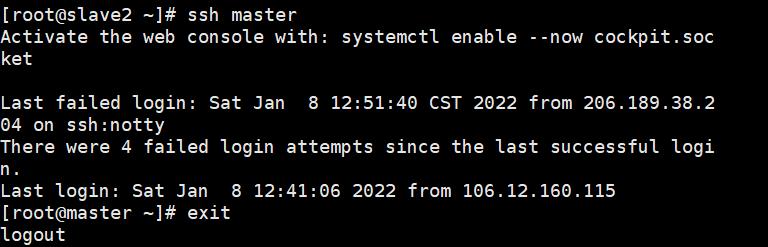
ssh slave1
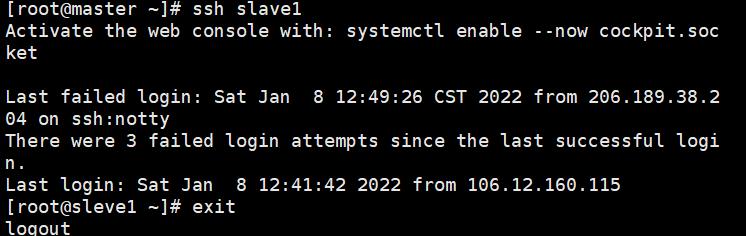
ssh slave2
退出:
exit
安装jdk
在官网下载好相关文件,利用xftp传入主机
创建安装目录和软件包存放目录
创建文件夹
在主机master先创建两个文件夹:/opt/module 和/opt/softs,我所有软件都安装在/opt/module下,软件安装包均放在/opt/softs下,命令为:
mkdir /opt/module/
mkdir /opt/softs/
利用xftp连接上传相关软件到/opt/softs
解压至/opt/module
tar -zxvf jdk-8u171-linux-x64.tar.gz
‐C /opt/modle/
将文件传入主机slave1和slave2
scp -r /opt/softs slave1:/opt/softs
scp -r /opt/softs slave2:/opt/softs
scp -r /opt/module slave1:/opt/module
scp -r /opt/module slave2:/opt/module
修改环境变量:
vi /etc/profile
添加内容如下:
export JAVA_HOME=/opt/module/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
使其生效:
source /etc/profile
删除slave1和slave2的/etc/profile文件:
rm -rf /etc/profile
将文件传入主机slave1和slave2
scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile
查看java版本,确认安装成功:
java -version

Zookeeper安装
安装Zookeeper:
tar -zxvf zookeeper-3.4.14.tar.gz -C /opt/module/
配置系统环境变量:
vi /etc/profile
添加如下信息
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.14
export PATH=$ZOOKEEPER_HOME/bin:$PATH
使得配置的环境变量生效:
source /etc/profile
修改配置文件
进入zookeeper的安装目录下的 conf目录 ,拷贝配置样本并进行修改:
cd /opt/module/zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改dataDir,增加dataLogDir如下:
dataDir=/opt/module/zookeeper-3.4.14/zookeeper-cluster/data
dataLogDir=/opt/module/zookeeper-3.4.14/zookeeper-cluster/log
#server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里
server.1=sleve1:2777:3888
server.2=sleve2:2777:3888
server.3=master:2777:3888
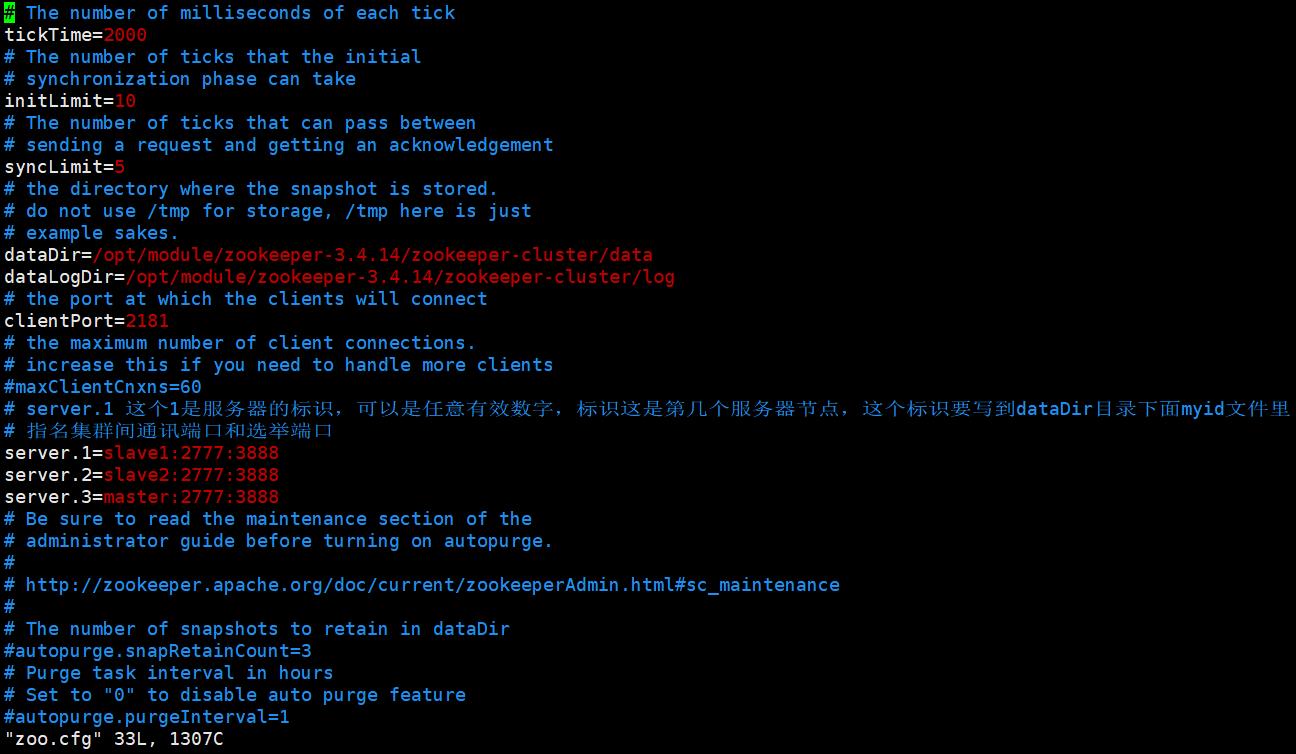
标识节点
分别在三台主机的 dataDir 目录下新建 myid 文件:
mkdir -vp /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/
写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
slave1上执行
echo "1" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
slave2上执行
echo "2" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
master上执行
echo "3" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
启动集群
进入各台服务器$ZOOKEEPER_HOME/bin,然后执行zkServer.sh start 启动集群,并用zkServer.sh status查看状态:(这里也可以不进入bin目录启动因为在/etc/profile设置了系统环境变量,但是如果每次在不同目录下启动每次启动会生成一个启动日记文件:zookeeper.out文件,zookeeper.out也可以用来查看启动时的错误)
cd $ZOOKEEPER_HOME/bin
查看当前目录:
pwd

zkServer.sh start
zkServer.sh status



常见问题解决措施:
1 检查是否创建data目录
2 检查conf/zoo.cfg文件中是否配置了正确的数据缓存路径(data文件夹位置)
3 检查data中是否创建了myid文件,其内容是否正确
如果myid文件中的数字不和zoo.cfg中的数字对应,也会造成错误!
4 检查conf/zoo.cfg文件中是否配置了服务/投票/选举端口,形式为:
server.x(x为myid中的id)=ip地址:端口号:端口号
举例:
server.1=192.168.70.143:2881:3881
5 是否关闭了防火墙(需要关闭,或者开放相关端口)
6 检查data目录下是否有*.pid文件,若有将其全部删除
7 端口占用:
netstat -nltp | grep 2181//查看指定端口
jps//查看java进程端口
kill -9 37884// 彻底杀死进程
8.主机映射问题,在配置zoo.cfg时最好是直接写ip地址,不写主机名称
9.启动顺序,需要按配置文件启动
具体错误查看zookeeper.out文件
Hadoop安装
进入/opt/softs/目录:
cd /opt/softs/
安装hadoop:
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module//表示将hadoop安装到/opt/module/
配置系统环境变量:
vim /etc/profile
添加如下信息
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
使得配置的环境变量生效:
source /etc/profile
进入 $HADOOP_HOME/etc/hadoop 目录下,修改几个配置文件:
cd $HADOOP_HOME/etc/hadoop

修改hadoop-env.sh
指定JDK的安装位置
export JAVA_HOME=/opt/module/jdk1.8.0_171
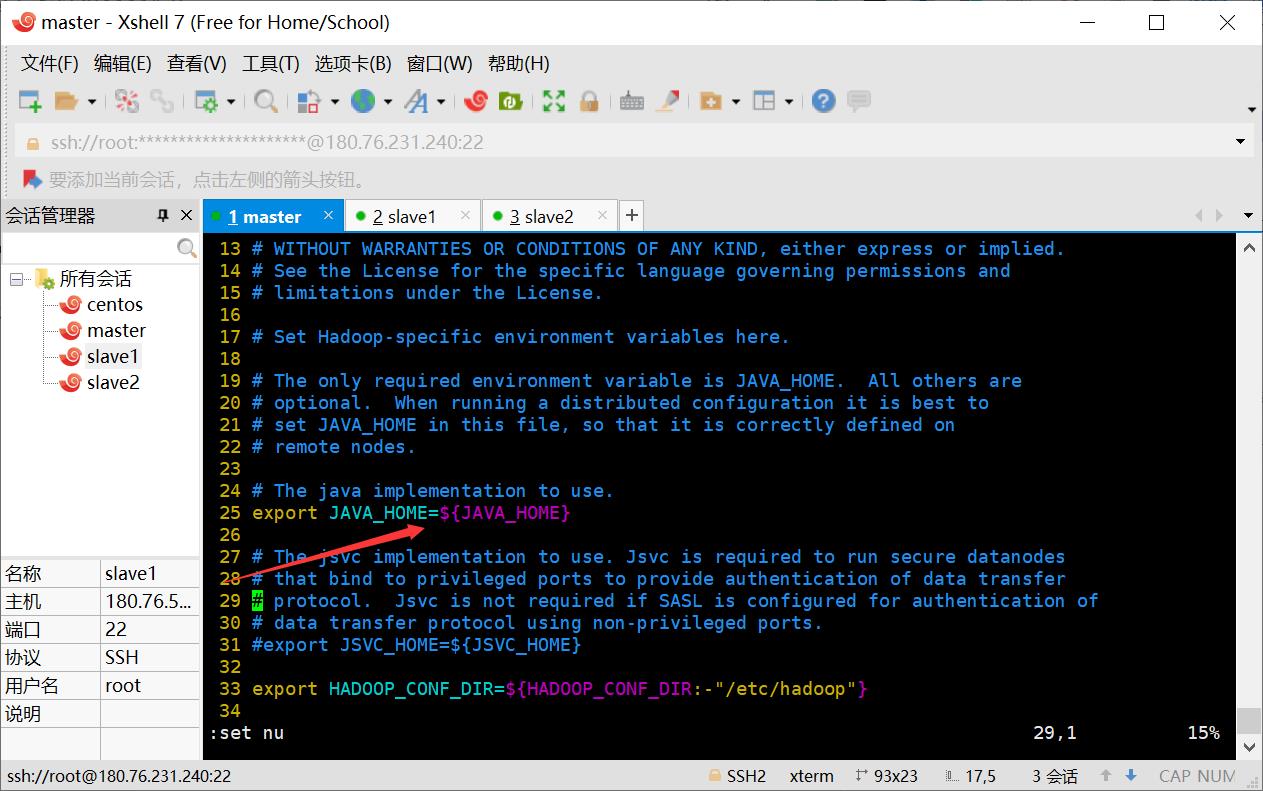
修改yarn-env.sh
进入$HADOOP_HOME/etc/hadoop下配置:
cd $HADOOP_HOME/etc/hadoop
vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_171
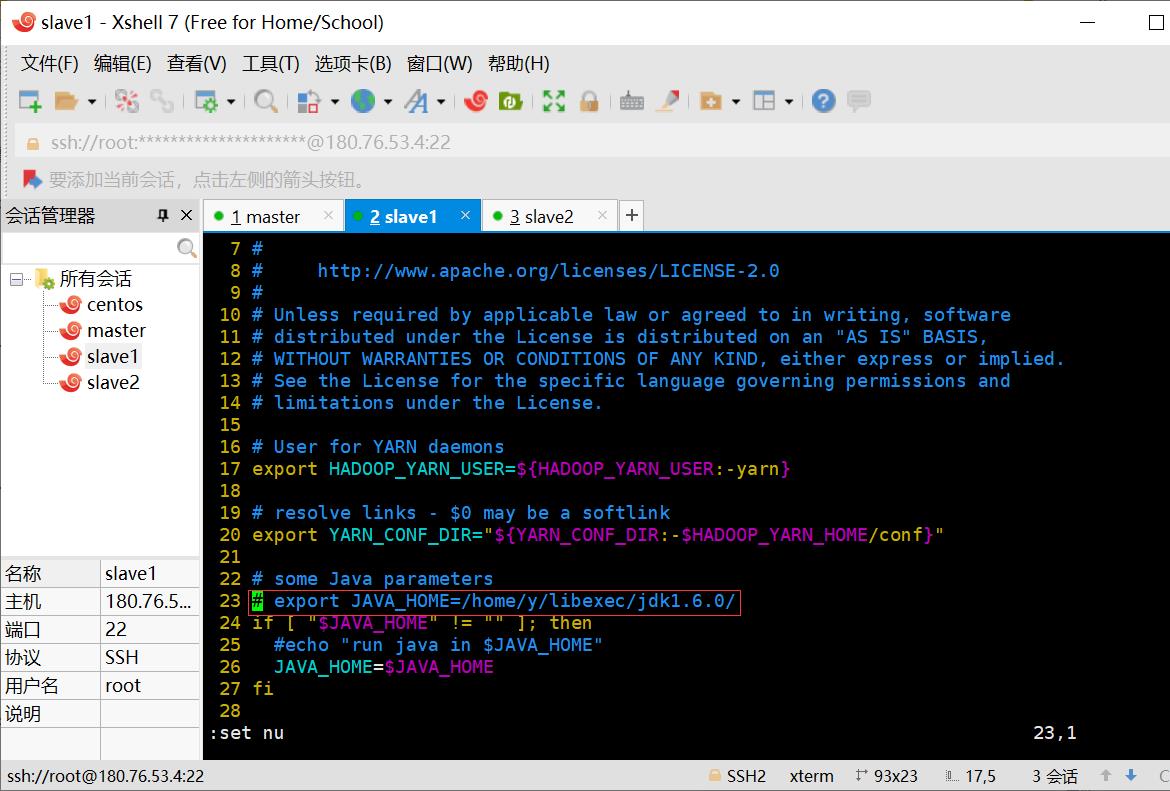
修改主要配置
由于其方便性,这里使用notepad++修改
除了直接在文档修改,我们还可以利用notepad++的插件通过FTP实现远程编辑项目的文档。采用这个方法虽然一次只能编辑一个文档。
notepad++是一款开源免费软件,到处都有得下载
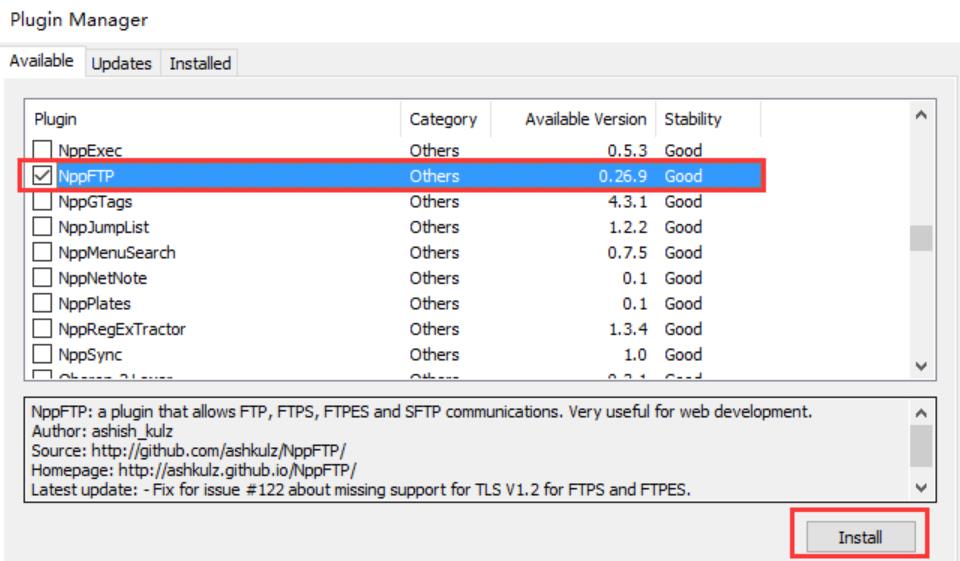
安装NppFTP插件
选择 「插件」 --> 「Plugin Manager」 --> 「Show Plugin Manager」,在弹出的窗口中找到 「NppFTP」 ,打上勾并点击 「Install」,之后一路「Yes」 就可以了。
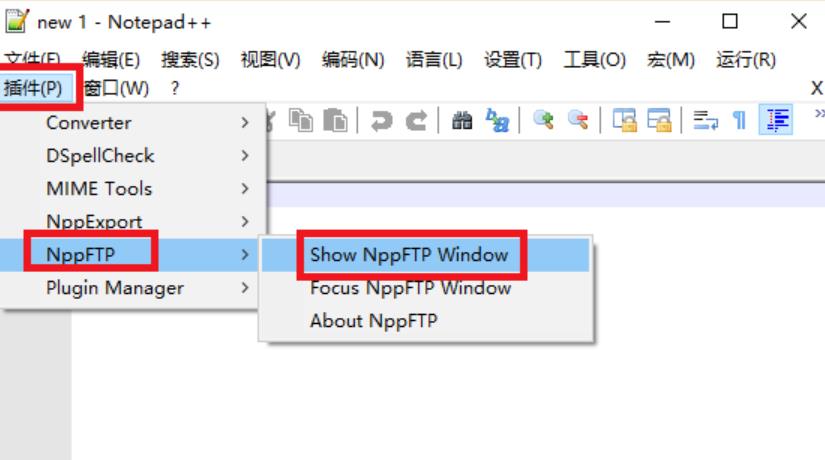
安装完毕之后,在 「插件」 菜单中即可看到 「NppFTP」 。我们也可以将这个插件以窗口的形式显示在主窗口侧边。
选择 「插件」 --> 「NppFTP」 --> 「Show NppFTP Window」
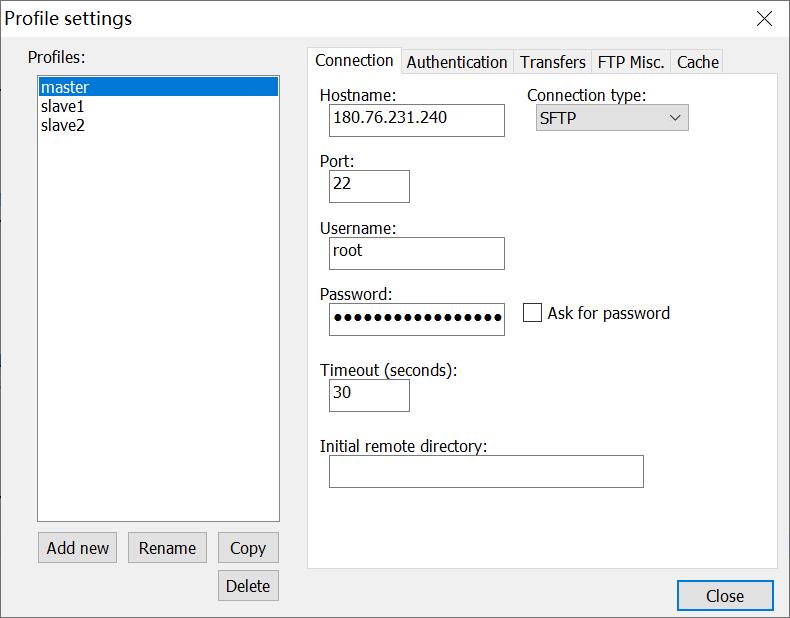
下面就可以通过Notepad++的NppFTP插件来连接虚拟机了。点击NppFTP插件栏的小齿轮选择 「profile settings」:

在「profile settings」 里,点击 「add new」 创建一个新的连接,然后右侧填入相应的信息,再点击 「close」 退出。
点击NppFTP插件栏左侧的闪电那个图标,选择刚刚创建的连接,即可连接到虚拟机。之后再打开需要编辑的文档就可以尽情的玩耍了。
进入/opt/module/hadoop-2.7.7/etc/hadoop目录
修改core-site.xml
<configuration>
<property>
<!-- 指定 namenode 的 hdfs 协议文件系统的通信地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<!-- 指定 hadoop 集群存储临时文件的目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<!-- ZooKeeper 集群的地址 -->
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<!-- ZKFC 连接到 ZooKeeper 超时时长 -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
</property>
</configuration>
若中文出现乱码现象,点击[编码],使用UTF-8编码

修改hdfs-site.xml
<configuration>
<property>
<!-- 指定 HDFS 副本的数量 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!-- namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔 -->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!-- datanode 节点数据(即数据块)的存放位置 -->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
<property>
<!-- 集群服务的逻辑名称 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 块的大小(128M),下面的单位是字节-->
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<!-- secondarynamenode守护进程的http通信地址:主机名和端口号。参考守护进程布局-->
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<!-- NameNode 元数据在 JournalNode 上的共享存储目录 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<!-- Journal Edit Files 的存储目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journalnode/data</value>
</property>
<property>
<!-- 配置隔离机制,确保在任何给定时间只有一个 NameNode 处于活动状态 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 使用 sshfence 机制时需要 ssh 免密登录 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<!-- SSH 超时时间 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!-- 访问代理类,用于确定当前处于 Active 状态的 NameNode -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 开启故障自动转移 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在Yarn 上运行 MapReduce 程序。-->
<!-- 指定yarn的shuffle技术-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 是否启用日志聚合 (可选) -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚合日志的保存时间 (可选) -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<!-- 启用 RM HA -->
<name>yarn