2021年大数据Hadoop(二十八):YARN的调度器Scheduler
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Hadoop(二十八):YARN的调度器Scheduler相关的知识,希望对你有一定的参考价值。
全网最详细的Hadoop文章系列,强烈建议收藏加关注!
后面更新文章都会列出历史文章目录,帮助大家回顾知识重点。
目录
本系列历史文章
2021年大数据Hadoop(二十六):YARN三大组件介绍
2021年大数据Hadoop(二十五):YARN通俗介绍和基本架构
2021年大数据Hadoop(二十四):MapReduce高阶训练
2021年大数据Hadoop(二十三):MapReduce的运行机制详解
2021年大数据Hadoop(二十二):MapReduce的自定义分组
2021年大数据Hadoop(二十一):MapReuce的Combineer
2021年大数据Hadoop(二十):MapReduce的排序和序列化
2021年大数据Hadoop(十九):MapReduce分区
2021年大数据Hadoop(十八):MapReduce程序运行模式和深入解析
2021年大数据Hadoop(十七):MapReduce编程规范及示例编写
2021年大数据Hadoop(十六):MapReduce计算模型介绍
2021年大数据Hadoop(十五):Hadoop的联邦机制 Federation
2021年大数据Hadoop(十三):HDFS意想不到的其他功能
2021年大数据Hadoop(十一):HDFS的元数据辅助管理
2021年大数据Hadoop(八):HDFS的Shell命令行使用
2021年大数据Hadoop(七):HDFS分布式文件系统简介
2021年大数据Hadoop(六):全网最详细的Hadoop集群搭建
2021年大数据Hadoop(二):Hadoop发展简史和特性优点
前言
2021年全网最详细的大数据笔记,轻松带你从入门到精通,该栏目每天更新,汇总知识分享

Yarn的调度器Scheduler
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
在Yarn中有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,Fair Scheduler。
FIFO Scheduler
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
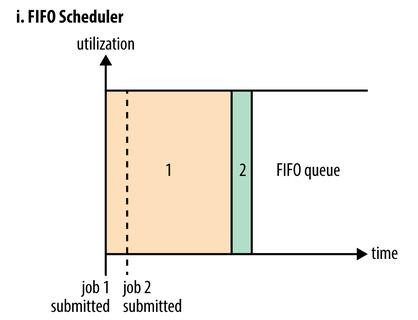
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
Capacity Scheduler
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。

容量调度器 Capacity Scheduler 最初是由 Yahoo 最初开发设计使得 Hadoop 应用能够被多用户使用,且最大化整个集群资源的吞吐量,现被 IBM BigInsights 和 Hortonworks HDP 所采用。
Capacity Scheduler 被设计为允许应用程序在一个可预见的和简单的方式共享集群资源,即"作业队列"。Capacity Scheduler 是根据租户的需要和要求把现有的资源分配给运行的应用程序。Capacity Scheduler 同时允许应用程序访问还没有被使用的资源,以确保队列之间共享其它队列被允许的使用资源。管理员可以控制每个队列的容量,Capacity Scheduler 负责把作业提交到队列中。
Fair Scheduler
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。

公平调度器 Fair Scheduler 最初是由 Facebook 开发设计使得 Hadoop 应用能够被多用户公平地共享整个集群资源,现被 Cloudera CDH 所采用。
Fair Scheduler 不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源。
示例:Capacity调度器配置使用
调度器的使用是通过yarn-site.xml配置文件中的
yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器。
假设我们有如下层次的队列:
root
├── prod
└── dev
├── mapreduce
└── spark
下面是一个简单的Capacity调度器的配置文件,文件名为capacity-scheduler.xml。在这个配置中,在root队列下面定义了两个子队列prod和dev,分别占40%和60%的容量。需要注意,一个队列的配置是通过属性yarn.sheduler.capacity.<queue-path>.<sub-property>指定的,<queue-path>代表的是队列的继承树,如root.prod队列,<sub-property>一般指capacity和maximum-capacity。
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>mapreduce,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.mapreduce.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>我们可以看到,dev队列又被分成了mapreduce和spark两个相同容量的子队列。dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急。我们注意到,mapreduce和spark两个队列没有设置maximum-capacity属性,也就是说mapreduce或spark队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%)。而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
关于队列的设置,这取决于我们具体的应用。比如,在MapReduce中,我们可以通过mapreduce.job.queuename属性指定要用的队列。如果队列不存在,我们在提交任务时就会收到错误。如果我们没有定义任何队列,所有的应用将会放在一个default队列中。
注意:对于Capacity调度器,我们的队列名必须是队列树中的最后一部分,如果我们使用队列树则不会被识别。比如,在上面配置中,我们使用prod和mapreduce作为队列名是可以的,但是如果我们用root.dev.mapreduce或者dev. mapreduce是无效的。
本博客大数据系列文章会一直每天更新,记得收藏加关注喔~
以上是关于2021年大数据Hadoop(二十八):YARN的调度器Scheduler的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Hadoop(二十五):YARN通俗介绍和基本架构
2021年大数据Hadoop(二十六):Yarn三大组件介绍
2021年大数据Hadoop(二十九):关于YARN常用参数设置