深入YARN系列1:窥全貌之YARN架构,设计,通信原理等
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入YARN系列1:窥全貌之YARN架构,设计,通信原理等相关的知识,希望对你有一定的参考价值。
深入YARN系列主要分为:
- 深入YARN系列1:窥全貌之YARN架构,设计,通信原理等
- 深入YARN系列2:剖析ResourceManaer的架构与核心源码分析
- 深入YARN系列3:剖析NodeManager架构,组件机制,生产应用
- 深入YARN系列4:剖析ApplicationMaster的任务管理机制与生产调优
- 深入YARN系列5:YARN三大组件配合使用与YARN生产性能优化
1.YARN的架构与设计
YARN的总体架构模式是Master/Slave主从模式。一个全局的ResourceManager ( RM,主 ,可以多个HA),多个NodeManager共同构成计算框架。 NodeManager (NM)是每台机器的框架代理,管理单个节点的资源和任务,比如负责容器container、监控其资源使用情况(cpu、内存、磁盘、网络)等。既然YARN是为了给计算框架做资源调度分配与管理的,那么少不了应用程序管理相关的框架:ApplicationMaster (AM) 实际上是一个特定框架的库,其作用是负责管理整个系统中所有的应用程序(从任务提交到结束),协商来自 ResourceManager 的资源,同时与 NodeManager 一起执行和监视任务。
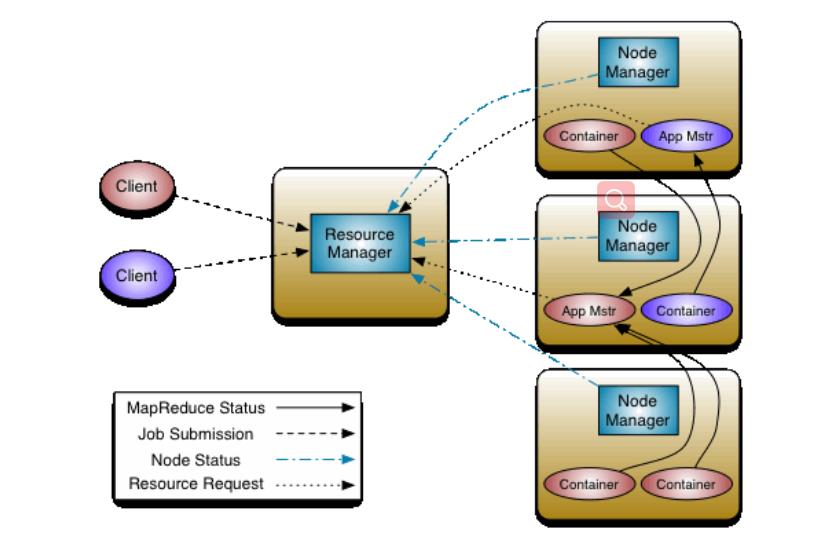
从上面这张Hadoop官网的照片我们可以清晰的看出,YARN主要有以下三个组件构成.ResourceManager,NodeManager,ApplicationMaster构成。
2.透视YARN三大组件全貌
YARN 可以看出一个大的云操作系统,它负责为应用程序启动 ApplicationMaster(相当于主线程),然后再由 ApplicationMaster 负责数据切分、任务分配、 启动和监控等工作,而由 ApplicationMaster 启动的各个 Task(相当于子线程)仅负责自己的计算任务。当所有任务计算完成后,ApplicationMaster 认为应用程序运行完成,然后退出。
2.1.ResourceManager全局资源管理器
RM负责整个系统的资源分配与管理;它主要有调度器ResourceScheduler和应用程序管理器(APPlications Manager)构成;
2.1.1ResourceScheduler
Resource Scheduler调度器只负责资源的细分调度,比如按照队列,容量等指标,给每个请求的应用程序分配的指定数量的资源。 Hadoop 提供了三种不同的资源调度器供选用,用户可以在配置文件中加以选择。这三种调度器是FIFO Scheduler, FAIR Scheduler,CAPACITY Scheduler,详细使用可以参考官网或我的其他博客。yarn配置文件 yarn-sire.xml 中<yarn. resourcemanager. scheduler. class >来指定调度器,Apache Hadoop集群默认的调度器 是 CapacityScheduler ,而CDH默认的则是FAIR Scheduler.
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>2.1.2APPlications Manager
APPlications Manager 应用程序管理器负责整个系统中所有应用程序的管理,包括管理启动的所有ApplicationMaster (AM)实例,比如启动AM,和AM通信并监控所有AM实例的运行状态,某个AM失败时,在失败次数范围内时对其进行重启等(默认一个应用的AM可以启动2次)。区别APPlications Manager和APPlications Master,两者不同,前者管理后者的实例。
2.2 NodeManger,节点资源管理器
NM是单个节点的资源管理器,管理者单个节点的资源分配与任务。所以如果hadoop集群特殊情况时想做存储与计算分离,则某些节点可以只启动Datanode,或只启动Nodemanger即可,这样可以只做存储节点或者计算节点,当然也可以通过参数限制存储的使用和计算的使用比例。所以NM是YARN的实际计算节点。
- NM和RM保持心跳机制,定时汇报自己节点的资源使用情况和Container的运行状态
- Container,全称是Resouce Container是YARN中的资源抽象(主要包含了CPU,内存,网络等),应用程序向RM请求资源的个体就是Container,由NodeManager分配。YARN会为每个任务分配一个container,且任务能使用的资源值就是container中分配的资源(新Capacity调度支持container资源的动态扩容)
- NM接受来自AM的Container分配,启动与停止
- YARN使用了轻量级资源隔离机制CGroups,CGroups 是 Linux 内核功能。从 YARN 的角度来看,这允许限制容器的资源使用。没有 CGroups,就很难限制容器 CPU 使用率。
- NM只负责AM管理的应用程序的部分工作,不管整个程序的失败与否,只负责执行Container。
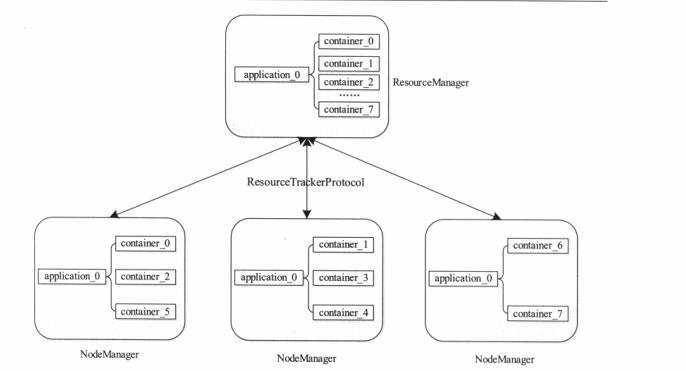
尖叫总结:RM内部有个 ResourceTrackerService 类的对象 resourceTracker ,它跟踪管理着 NodeManager 节点所知道的资源变动。同时 NodesListManager 类的对象nodesListManager 则维持着一个节点清单,记录着哪些节点当前是可用的,哪些则是不可用的。而 ResourceTrackerService 和 NodesListManager 掌握的则是来自所有 NodeManager 节点的心跳报告,通过心跳进行交互的信息如节点当前状态,资源使用情况等。这些信息最终都要汇集到ResourceScheduler,通过调度器将资源分配出去给用户使用。
2.3 Application Master应用程序主管理器
客户端每使用YARN启动执行一个应用程序之前,先启动一个AM(其实本质就是一个运行的Container,一个程序最早启动的container实例)
- 每个提交到YARN的任务都会启动一个唯一的AM实例,如果AM失败了,默认可以重试启动一次。
- AM与RM通信提交需要的资源,AM与RM调度器Scheduler通信协商以获取资源Container,得到Container后分配给自己的任务执行执行。比如map任务的执行。分配的多少个Container就有多少个map并行执行。
- AM从RM得到的资源只是资源列表,hosts,container数量,资源大小等,这时候AM需要与NM通信,启动任务,启动container。
- AM监管者该任务所有任务实例的运行状态,比如一个MapReduce任务,该任务AM监管所有的MapTask,ReduceTask的运行状态。如果AM监管到任务失败了后,可以进行重新申请资源重启。包括可以主动杀死任务,停止任务等。
尖叫总结:从上面可以看出,YARN三大组件的RM,NM都只与资源分配有关,只有AM跟应用程序有关。所以如果想将一个新的计算框架(比如自定义的)/应用程序使用YARN进行资源调度和任务管理,只需要从重新实现两个组件即可,前者是提交任务使用的客户端Client,后者就是Application Master。比如MapReduce计算引擎能直接配置使用YARN进行调度,就是YARN默认给他实现了可以提交任务通信的客户端JobClient和任务管理器MapReduce Application Master(简称MRAppMaster)。
3.YARN组件之间的通信RPC/IPC
开发人员经常会在任务中看到RPC通信异常,也有IPC通信异常,报错等?或者查到监控指标RPC请求延迟等?大家应该都不陌生,那么这些报错意味着什么呢?如何解决呢?
3.1RPC通信与IPC通信
RPC通信是指远程过程调用(Remote Procedure Call)通信协议,主要用来让远程的两台服务器之间A主机的程序可以调用B主机的子程序,是一种远程分布式网络调用通信协议,我们不用太关注底层网络通信细节(不用关注TCP,UDP等),是一种封装好了的通信协议,直接拿来用即可,真香。
IPC通信是指进程间通信(Inter-Process Communication ,IPC)协议,这个是分布式系统通信的基石。
尽管Java自带了一套RPC通信组件(RMI,remote method Invocation),但是Hadoop并没有使用该框架,因为相比Java的RMI,后者更加轻量级,高性能和可控性。Hadoop的RPC框架也是C/S模式,分成了四个模块,分别是序列化层,函数调用层,网络传输层以及server端处理层。当前开源的RPC框架很多,比如Apache的AVRO,Google的Protocol Buffer等。
YARN的RPC通信为了更好的兼容默认使用Google的Protocol Buffer作为默认的序列化机制,而不是Hadoop自带的Writtable。在 YARN 中,任何两个需相互通信的组件之间仅有一个 RPC 协 议,而对于任何一个 RPC 协议,通信双方有一端是 Client,另一端为 Server,且 Client 总 是主动连接 Server 的,因此,YARN 实际上采用的是拉式(pull-based)通信模型。
比如NM和RM之前的远程通信就是基于RPC,通过ResouceTracker实现,其中RM是服务端,NM是客户端。NM主要通过调用ResouceTracker中两个RPC函数与之交互,前者是NM刚启动时通过registerNodeManager函数向RM进行注册,然后再通过nodeHeartBeat像RM发送周期性心跳,维护两者之间的交互。如下图所示,因为RPC分成了四层次序列化层,函数调用层,网络传输层以及server端处理层,所有不同组件之间实现通信的“协议”是不同的。
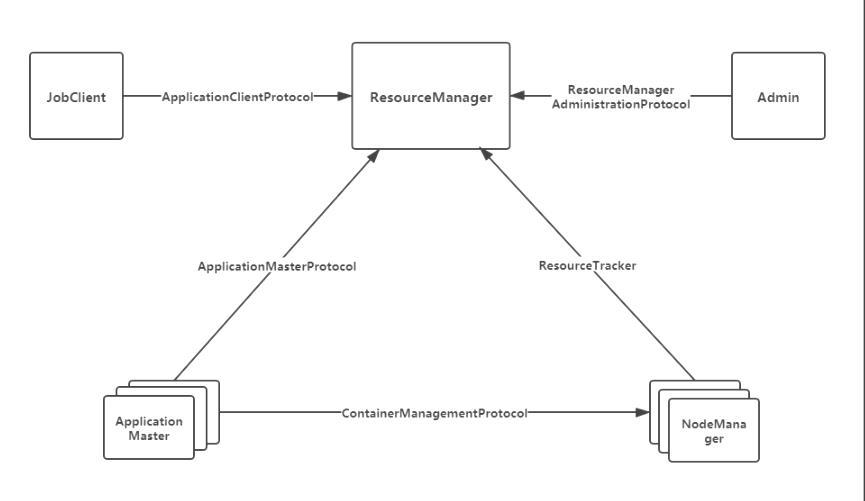
- 1.JobClient(作业提交客户端)与 RM 之间JobClient 通过该 RPC 协议提交应用程序、查询应用程序状态,使用的协议 是ApplicationClientProtocol 。
- 2.AM 与 RM 之间的协议是ApplicationMasterProtocol ,AM 通过该 RPC 协议向 RM 注册并为各个任务申请资源,或者使用完以后进行销毁自己。
- 3. AM 与 NM 之 间 的 协 议 是ContainerManagementProtocol ,AM 通 过 该 RPC 协议要 求 NM 启动/停止 Container,同时获取各个 Container 的状态信息等。
- 4.NM 与 RM 之间的协议是ResourceTracker ,NM 通过该 RPC 协议向 RM 注册,并且周期性发送心跳信息汇报当前节点的资源使用情况和 Container 运行情况。
- 5.Admin与 RM 之间的通信协议是ResourceManagerAdministrationProtocol,超级用户通过该 RPC 协议更新系统配置文件,比如节点上下线名单、用户队列权限等。
尖叫总结:RM,NM,AM三大组件互相通信,通过不同RPC框架协议进行通信,进而保持整个YARN资源的调度和任务监控实施。
以上是关于深入YARN系列1:窥全貌之YARN架构,设计,通信原理等的主要内容,如果未能解决你的问题,请参考以下文章
深入YARN系列3:剖析NodeManager架构,组件与生产应用
深入YARN系列3:剖析NodeManager架构,组件与生产应用
深入YARN系列2:剖析ResourceManager的架构与组件使用
深入YARN系列2:剖析ResourceManager的架构与组件使用