阿里十年-大数据系列讲解之YARN
Posted 程序员OfHome
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里十年-大数据系列讲解之YARN相关的知识,希望对你有一定的参考价值。
YARN是资源管理系统,理论上支持多种资源,目前支持CPU和内存两种资源
YARN产生背景
直接源于MRv1在几个方面的缺陷
扩展性受限
单点故障
难以支持MR之外的计算
多计算框架各自为战,数据共享困难
MR:离线计算框架
Storm:实时计算框架
Spark:内存计算框架
YARN设计目标
通用的统一资源管理系统
同时运行长应用程序和短应用程序
长应用程序
通常情况下,永不停止运行的程序
Service、HTTP Server等
短应用程序
短时间(秒级、分钟级、小时级)内会运行结束的程序
MR job、Spark Job等
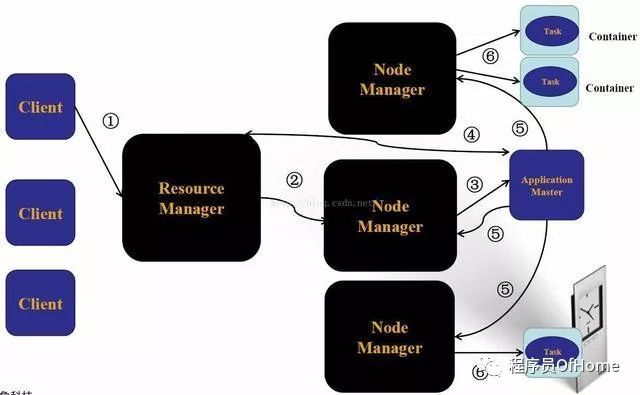
YARN基本架构
ResourceManager
整个集群只有一个,负责集群资源的统一管理和调度
详细功能
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配与调度
NodeManager
整个集群有多个,负责单节点资源管理和使用
详细功能
单个节点上的资源管理和任务管理
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
ApplicationMaster
每个应用有一个,负责应用程序的管理
详细功能
数据切分
为应用程序申请资源,并进一步分配给内部任务
任务监控与容错
Container
对任务运行环境的抽象
描述一系列信息
任务运行资源(节点、内存、CPU)
任务启动命令
任务运行环境
YARN运行过程
YARN容错性
ResourceManager
存在单点故障;
正在基于ZooKeeper实现HA。
NodeManager
失败后,RM将失败任务告诉对应的AM;
AM决定如何处理失败的任务。
ApplicationMaster
失败后,由RM负责重启;
AM需处理内部任务的容错问题;
RMAppMaster会保存已经运行完成的Task,重启后无需重新运行。
YARN调度框架
双层调度框架
RM将资源分配给AM
AM将资源进一步分配给各个Task
基于资源预留的调度策略
资源不够时,会为Task预留,直到资源充足
与“all or nothing”策略不同(Apache Mesos)
YARN资源调度器
多类型资源调度
采用DRF算法(论文:“Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”)
目前支持CPU和内存两种资源
提供多种资源调度器
FIFO
Fair Scheduler
Capacity Scheduler
多租户资源调度器
支持资源按比例分配
支持层级队列划分方式
支持资源抢占
YARN资源隔离方案
支持内存和CPU两种资源隔离
内存是一种“决定生死”的资源
CPU是一种“影响快慢”的资源
内存隔离
基于线程监控的方案
基于Cgroups的方案
CPU隔离
默认不对CPU资源进行隔离
基于Cgroups的方案
YARN支持的调度语义
支持的语义
请求某个特定节点/机架上的特定资源量
将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源
请求归还某些资源
不支持的语义
请求任意节点/机架上的特定资源量
请求一组或几组符合某种特质的资源
超细粒度资源
动态调整Container资源
运行在YARN上的计算框架 (还有别的)
离线计算框架:MapReduce
DAG计算框架:Tez
流式计算框架:Storm
内存计算框架:Spark
离线计算框架:MapReduce
仅适合离线批处理
具有很好的容错性和扩展性
适合简单的批处理任务
缺点明显
启动开销大、过多使用磁盘导致效率低下等
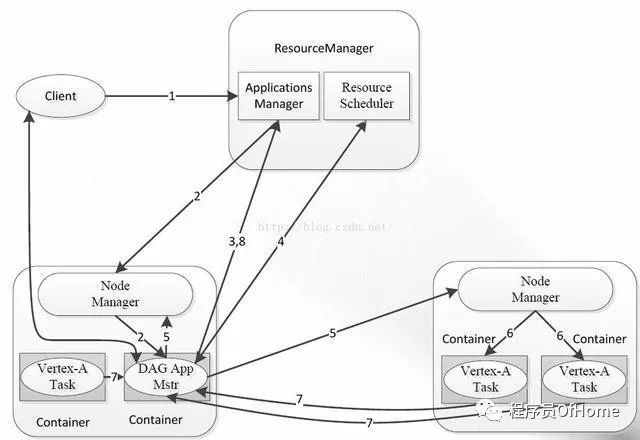
DAG计算框架:Apache Tez
DAG计算:多个作业之间存在数据依赖关系,并形成一个依赖关系有向图( Directed Acyclic Graph ),该图的计算称为“DAG计算”
和Mapreduce相比
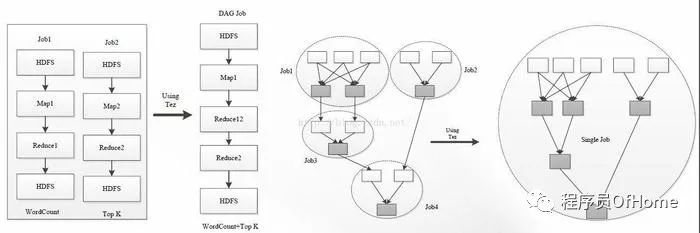
Tez应用场景
直接编写应用程序
Tez提供了一套通用编程接口
适合编写有依赖关系的作业
优化Pig、Hive等引擎
下一代Hive:Stinger
好处1:避免查询语句转换成过多的MapReduce作业后产生大量不必要的网络和磁盘IO
好处2:更加智能的任务处理引擎
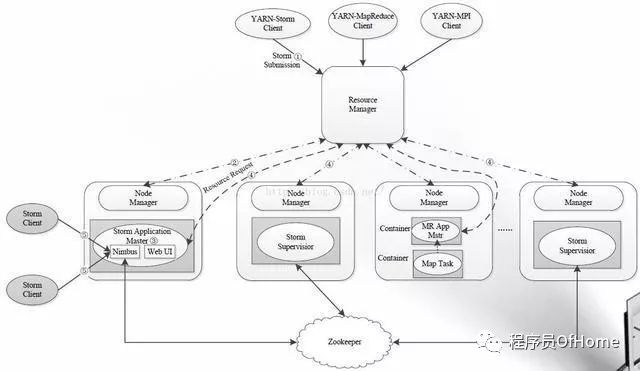
流式计算框架:Storm

Storm on YARN(和其他如mapreduce、tez、spartk等都不同,其他计算框架的client)
内存计算框架:Spark
已经形成了自己的生态系统
文末福利
将来自己,一定会感谢现在自己的,现在不努力,将来只会后悔。我们不做后悔的哪个,只做最好的自己。
想从事以上工作或者往大数据方向发展的朋友,可以点击联系我们,获取大数据相关资料和高清学习线路图,希望在你发展的道路上有所帮助。
程序员OfHome交流群:610535338
以上是关于阿里十年-大数据系列讲解之YARN的主要内容,如果未能解决你的问题,请参考以下文章
YARN分析系列之二 -- Hadoop YARN各个自模块说明
大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)