大家沉迷短视频无法自拔?Python爬虫进阶,带你玩转短视频
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大家沉迷短视频无法自拔?Python爬虫进阶,带你玩转短视频相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
现在短视频可谓是一骑绝尘,吃饭的时候、休息的时候、躺在床上都在刷短视频,今天给大家带来python爬虫进阶 :美拍视频地址加密解析。
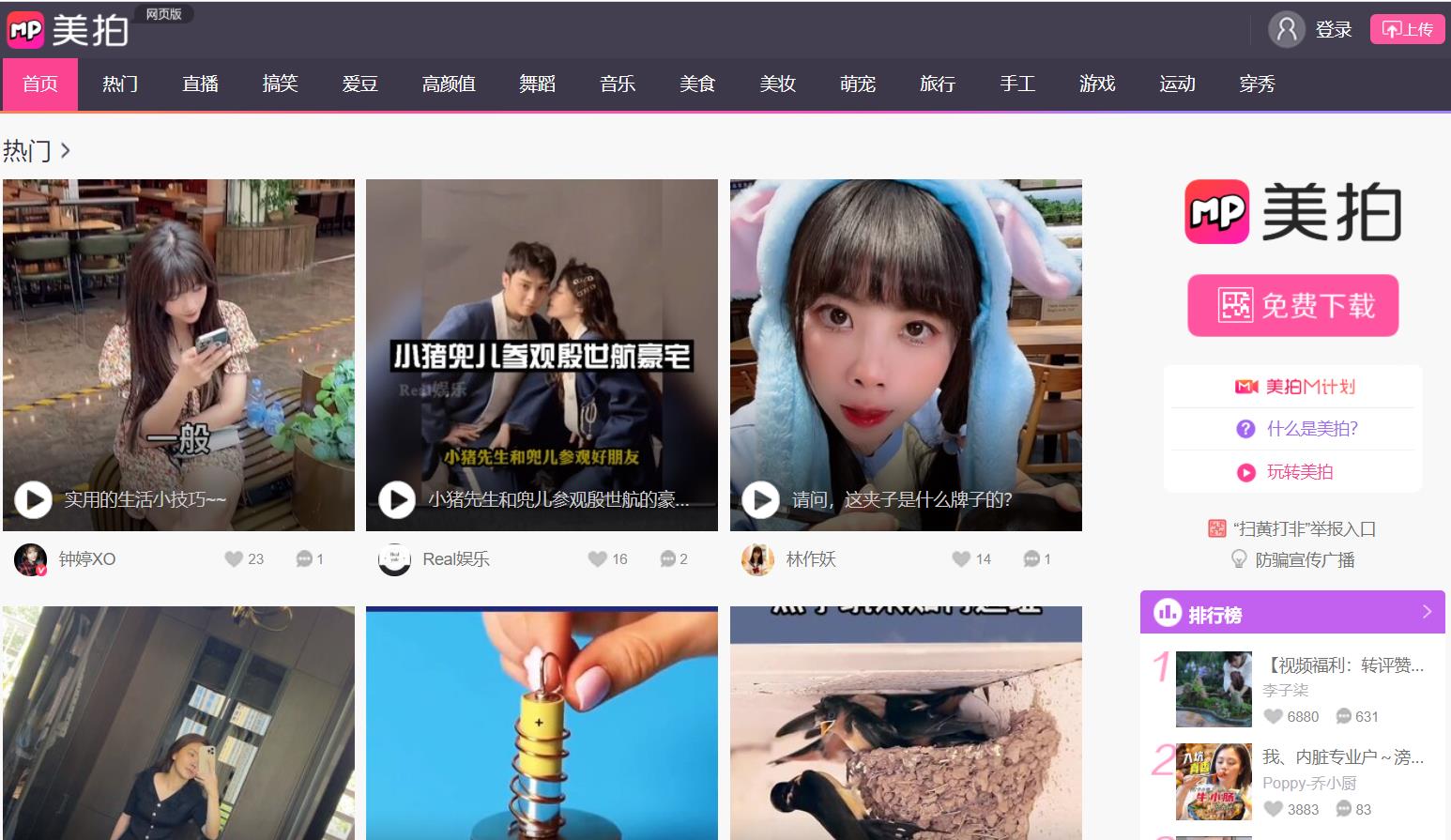
抓取目标
目标网址:美拍视频
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:requests、xpath、base64
重点学习内容
爬虫采集数据的解析过程
js代码调试技巧
js逆向解析代码
Python代码的转换
项目思路解析
进入到网站的首页
挑选你感兴趣的分类
根据首页地址获取到进入详情页面的超链接的跳转地址
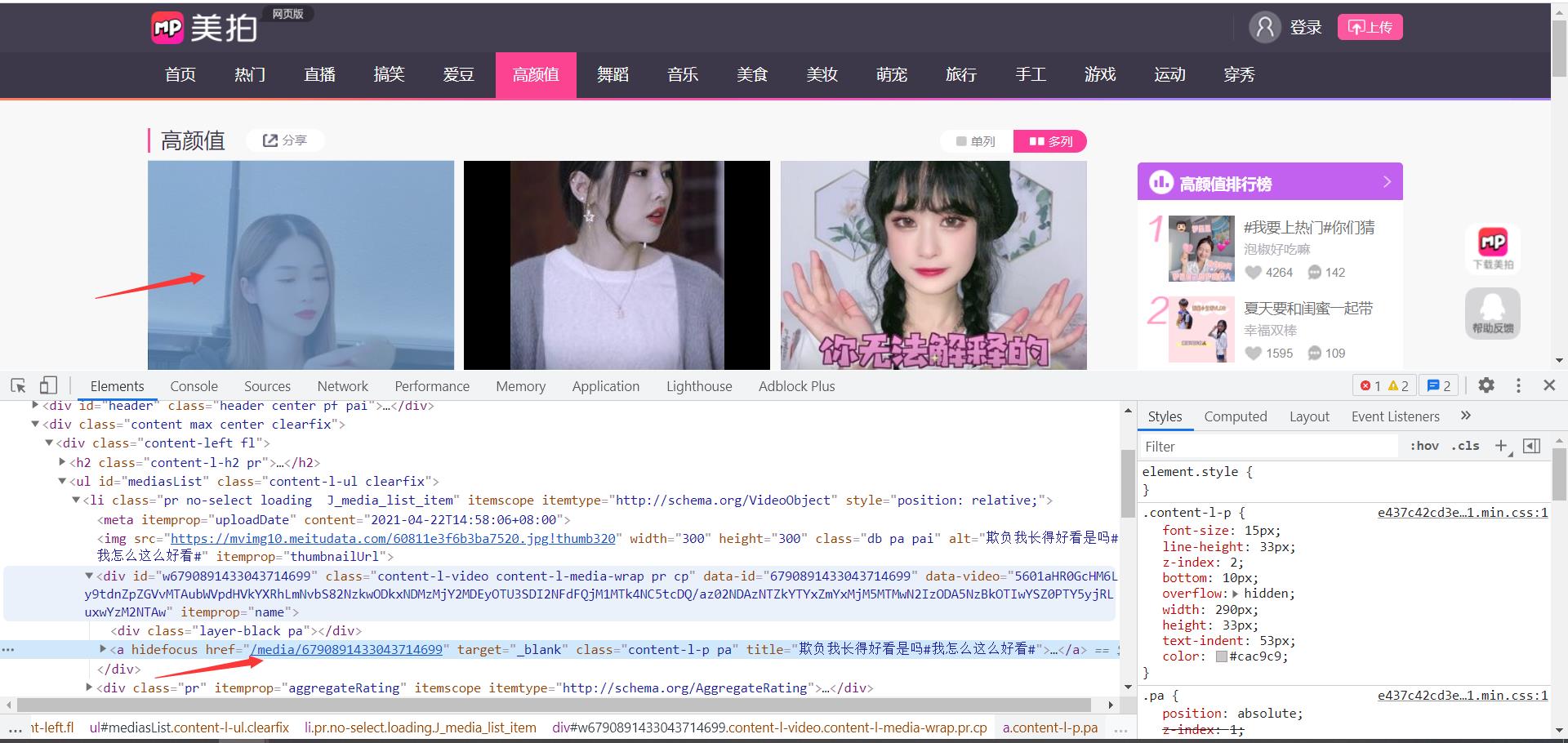
找到对应加密的视频播放地址数据
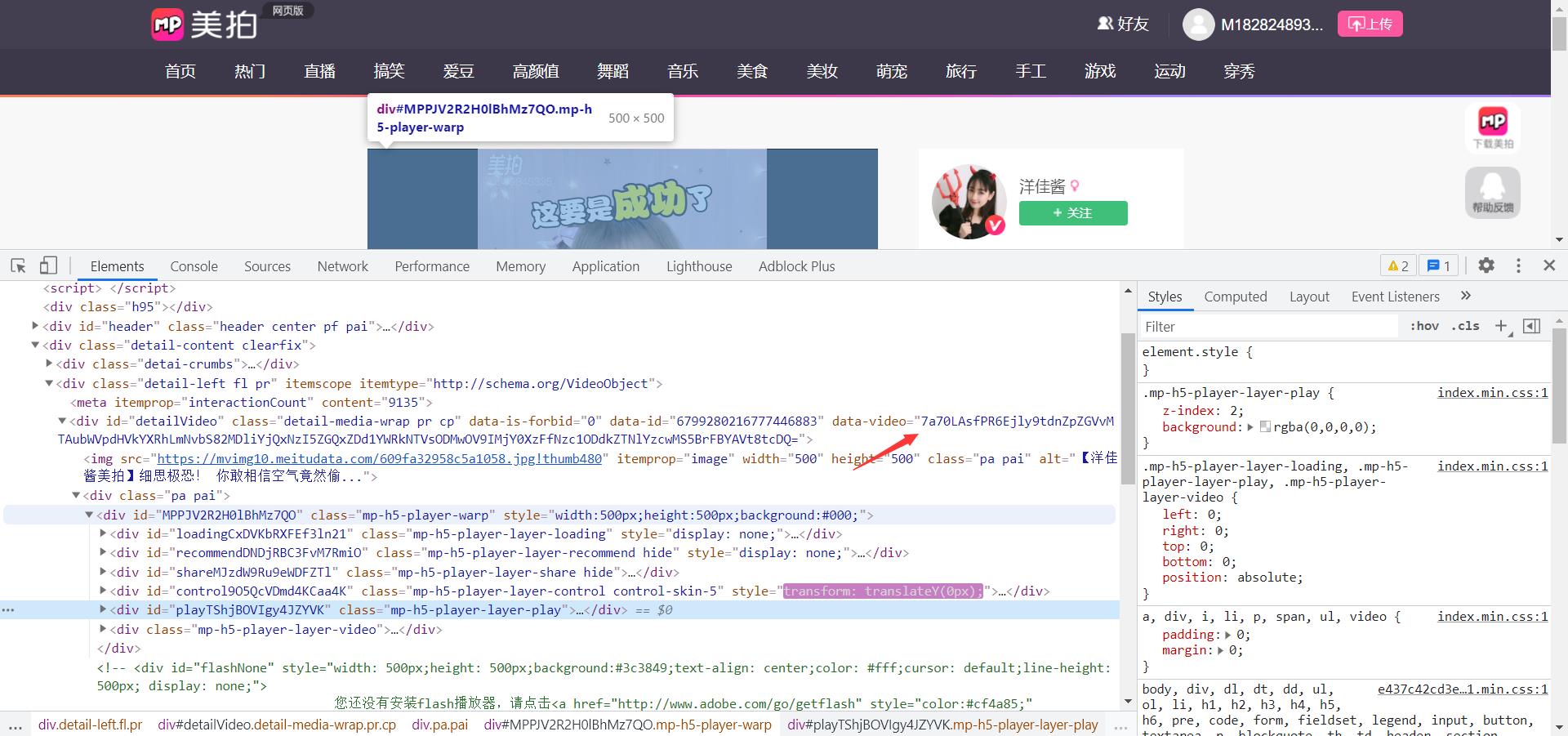
这个数据是静态的网页数据,通过js代码进行解码的
找到对应的解析代码
先找到视频的播放地址
找到解析视频地址的加密js文件
点击播放的时候会触发文件
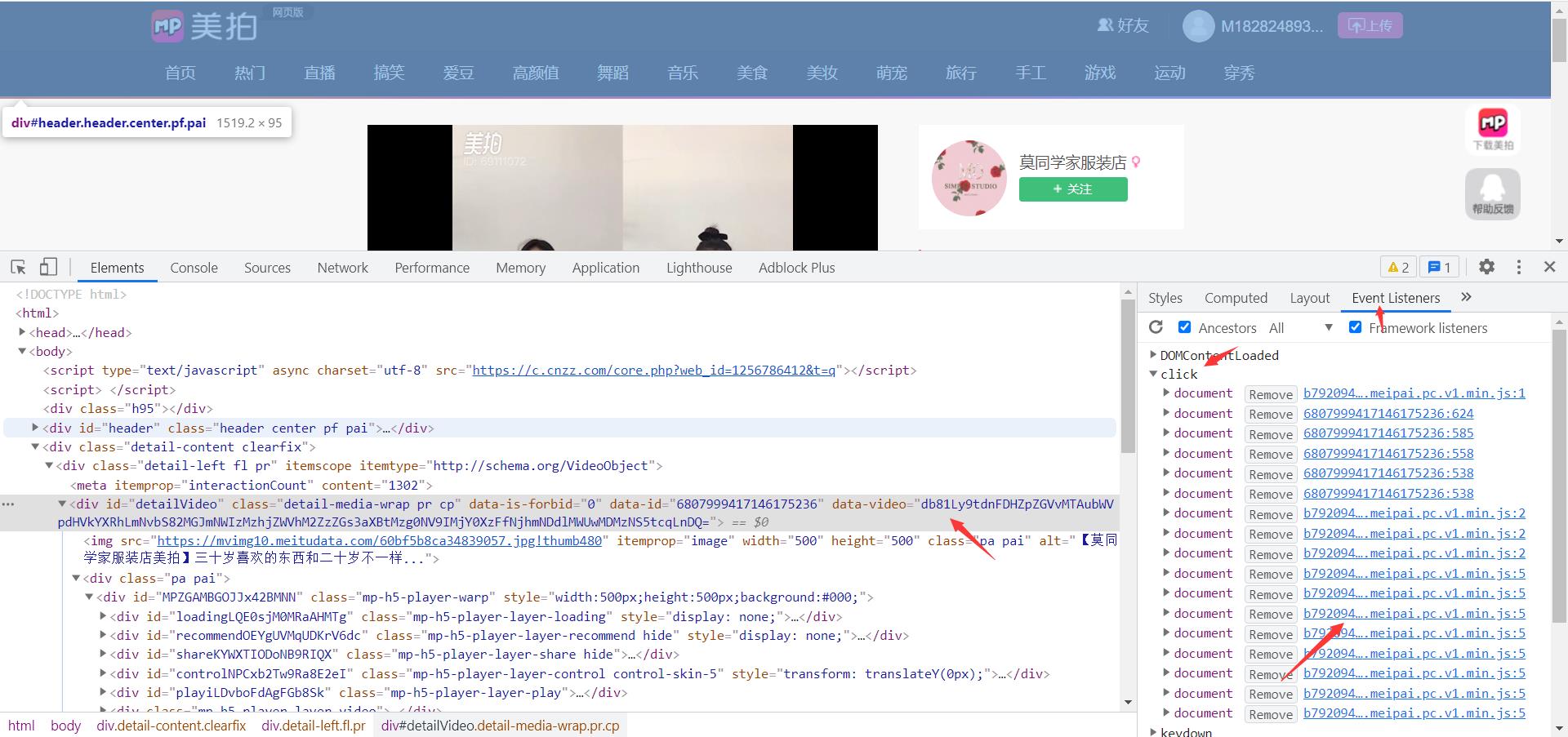
大致能看出来这个是base64加密之后的数据
在对应的js文件里搜索关键字
找到js的加密方式
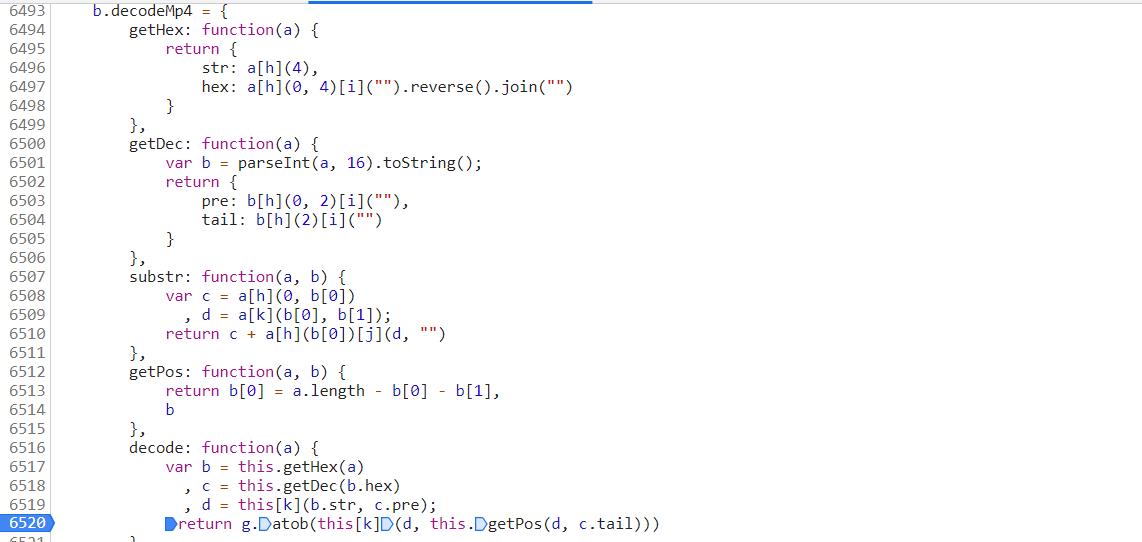
js函数的一些函数的用法
# eplace()方法用于在字符串中用一些字符替换另一些字符
# parseInt 数据转换成对应的整型
# base64.atob 对base64编码过的字符串进行解码
# substring 方法可在字符串中抽取从 start 下标开始的指定数目的字符
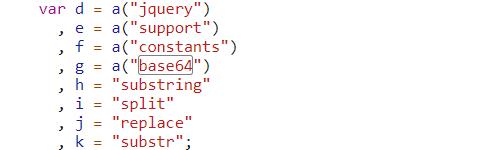
将js代码转换成Python代码
import base64
def decode(data):
def getHex(a):
return {
'str': a[4:],
'hex': ''.join(list(a[:4])[::-1]),
}
def getDec(a):
b = str(int(a, 16))
return {
'pre': list(b[:2]),
'tail': list(b[2:]),
}
def substr(a, b):
c = a[0: int(b[0])]
d = a[int(b[0]): int(b[0]) + int(b[1])]
return c + a[int(b[0]):].replace(d, "")
def getPos(a, b):
b[0] = len(a) - int(b[0]) - int(b[1])
return b
b = getHex(data)
c = getDec(b['hex'])
d = substr(b['str'], c['pre'])
return base64.b64decode(substr(d, getPos(d, c['tail'])))
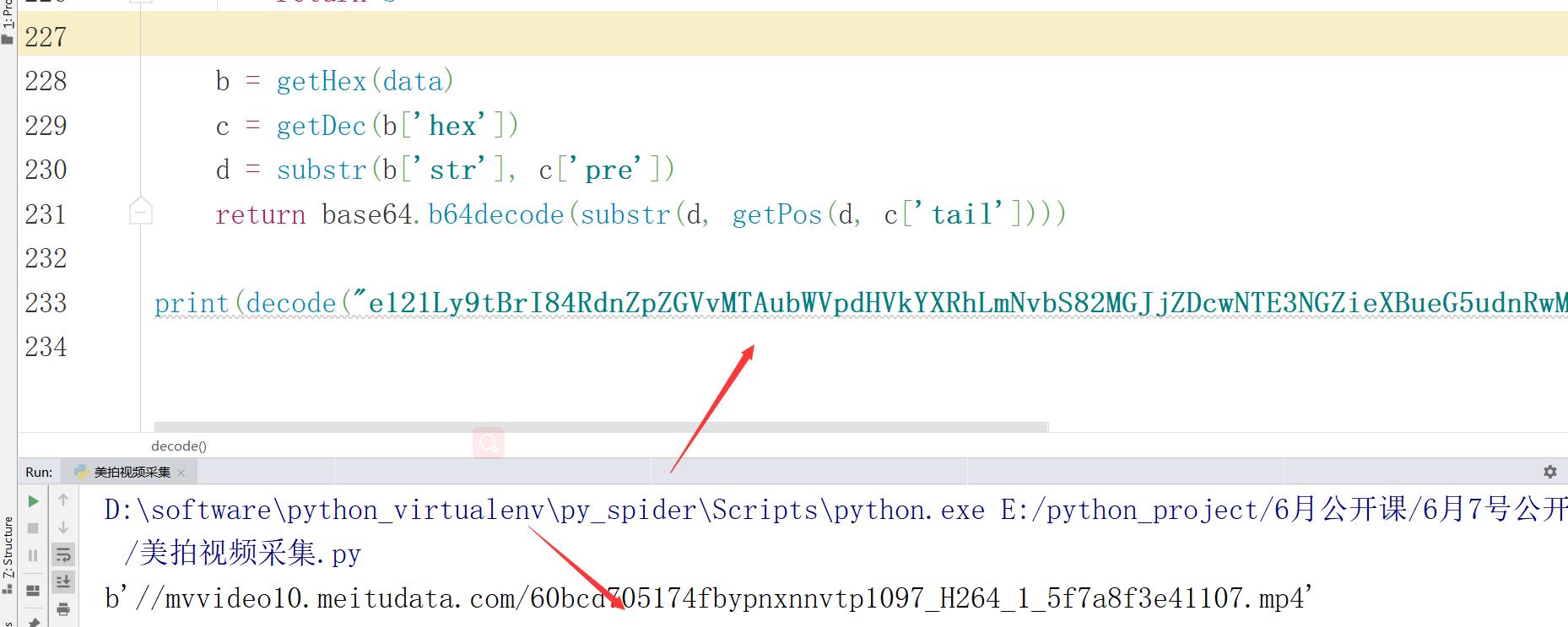
print(decode("e121Ly9tBrI84RdnZpZGVvMTAubWVpdHVkYXRhLmNvbS82MGJjZDcwNTE3NGZieXBueG5udnRwMTA5N19IMjY0XzFfNWY3YThmM2U0MTEwNy5tc2JVjAu3EDQ="))
得出最终视频播放地址

简易源码分享
import requests
from lxml import etree
import base64
def decode_mp4(data):
def getHex(a):
return {
'str': a[4:],
'hex': ''.join(list(a[:4])[::-1]),
}
def getDec(a):
b = str(int(a, 16))
return {
'pre': list(b[:2]),
'tail': list(b[2:]),
}
def substr(a, b):
c = a[0: int(b[0])]
d = a[int(b[0]): int(b[0]) + int(b[1])]
return c + a[int(b[0]):].replace(d, "")
def getPos(a, b):
b[0] = len(a) - int(b[0]) - int(b[1])
return b
b = getHex(data)
c = getDec(b['hex'])
d = substr(b['str'], c['pre'])
return base64.b64decode(substr(d, getPos(d, c['tail'])))
# 运行主函数
def main():
url = 'https://www.meipai.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = etree.HTML(response.text)
href_list = html_data.xpath('//div/a/@href')
# print(href_list)
for href in href_list:
res = requests.get('https://www.meipai.com' + href, headers=headers)
html = etree.HTML(res.text)
name = html.xpath('//div[@id="detailVideo"]/img/@alt')[0]
mp4_data = html.xpath('//div[@id="detailVideo"]/@data-video')[0]
# print(name, mp4_data)
mp4_url = decode_mp4(mp4_data).decode('utf-8')
print(mp4_url)
result = requests.get("http:" + mp4_url)
with open(name + ".mp4", 'wb') as f:
f.write(result.content)
f.close()
if __name__ == '__main__':
main()
欢迎大家在评论中交流技术,记得一键三连哦,祝大家顺顺利利开开心心!
以上是关于大家沉迷短视频无法自拔?Python爬虫进阶,带你玩转短视频的主要内容,如果未能解决你的问题,请参考以下文章
最近沉迷Redis网络模型,无法自拔!终于知道Redis为啥这么快了
沉迷Link-Cut tree无法自拔之:[BZOJ3669][Noi2014] 魔法森林
沉迷Link-Cut tree无法自拔之:[BZOJ2049]洞穴勘探(蒟蒻的LCT板子)
沉迷Link-Cut tree无法自拔之:[BZOJ2594][Wc2006]水管局长数据加强版
沉迷Link-Cut tree无法自拔之:[BZOJ3514] Codechef MARCH14 GERALD07 加强版