干货!机器学习中,如何优化数据性能
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货!机器学习中,如何优化数据性能相关的知识,希望对你有一定的参考价值。

作者 | 中国农业银行研发中心 张梓聪
出品 | AI 科技大本营(ID:rgznai100)
头图 | 下载于视觉中国
得益于覆盖各种需求的第三方库,Python在今天已经成为了研究机器学习的主流工具。不过由于其解释型语言的特性,在运行速度上往往和传统编译型语言有较大差距。特别是当训练数据集非常庞大时,很多时候处理数据本身就会占用大量的时间。
Python中自身提供了非常强大的数据存储结构:numpy库下的ndarry和pandas库下的DataFrame。前者提供了很多list没有实现的便利功能,而后者是最方便的column-row型数据的存储方式,同样提供了大量方便的随机访问函数。
然而不正确的使用很多时候反而会适得其反,给人一种如此高级的三方库性能还不如list手动造轮子的错觉。
本文主要通过优化数据结构以及一些使用中的注意点来提高在大数据量下数据的处理速度。

避免使用append来逐行添加结果
很多人在逐行处理数据的时候,喜欢使用append来逐行将结果写入DataFrame或ndarry。类似下面的写法:

这是非常不好的习惯,numpy或pandas在实现append的时候,实际上对内存块进行了拷贝——当数据块逐渐变大的时候,这一操作的开销会非常大。
下面是官方文档对此的描述:
Numpy: 
Pandas.DataFrame: 
实际上,受list的append操作的影响,开发者会不假思索的认为numpy和pandas中的append也是简单的数组尾部拼接。这实际上是一个很严重的误解,会产生很多不必要的拷贝开销。笔者没有深入研究它们这么设计原因,猜测可能是为了保证拼接后的数组在内存中依然是连续区块——这对于高性能的随机查找和随机访问是很有必要的。
解决办法:
除非必须,在使用DataFrame的部分函数时,考虑将inplace=True。出于保证原始数据的一致性,DataFrame的大部分方法都会返回一个原始数据的拷贝,如果要将返回结果写回,用这种方式效率更高。
除非必须,避免使用逐行处理。Numpy和pandas都提供了很多非常方便的区块选取及区块处理的办法。这些功能非常强大,支持按条件的选取,能满足大部分的需求。同时因为ndarry和DataFrame都具有良好的随机访问的性能,使用条件选取执行的效率往往是高于条件判断再执行的。
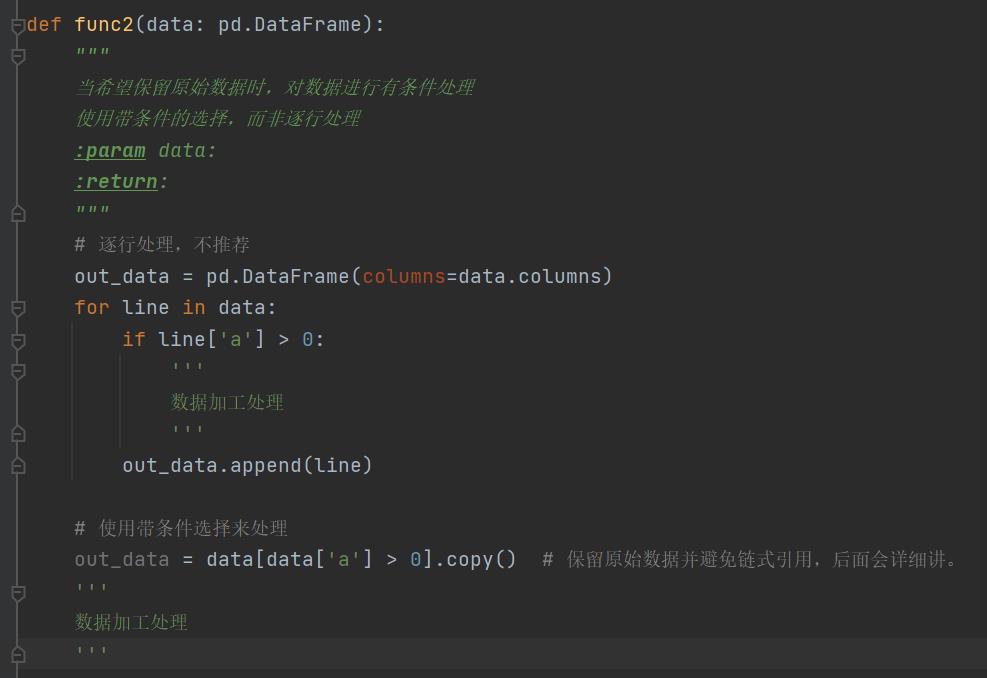
特殊情况下,使用预先声明的数据块而避免append。如果在某些特殊需求下(例如当前行的处理逻辑依赖于上一行的处理结果)并且需要构造新的数组,不能直接写入源数据时。这种情况下,建议提前声明一个足够大的数据块,将自增的逐行添加改为逐行赋值。
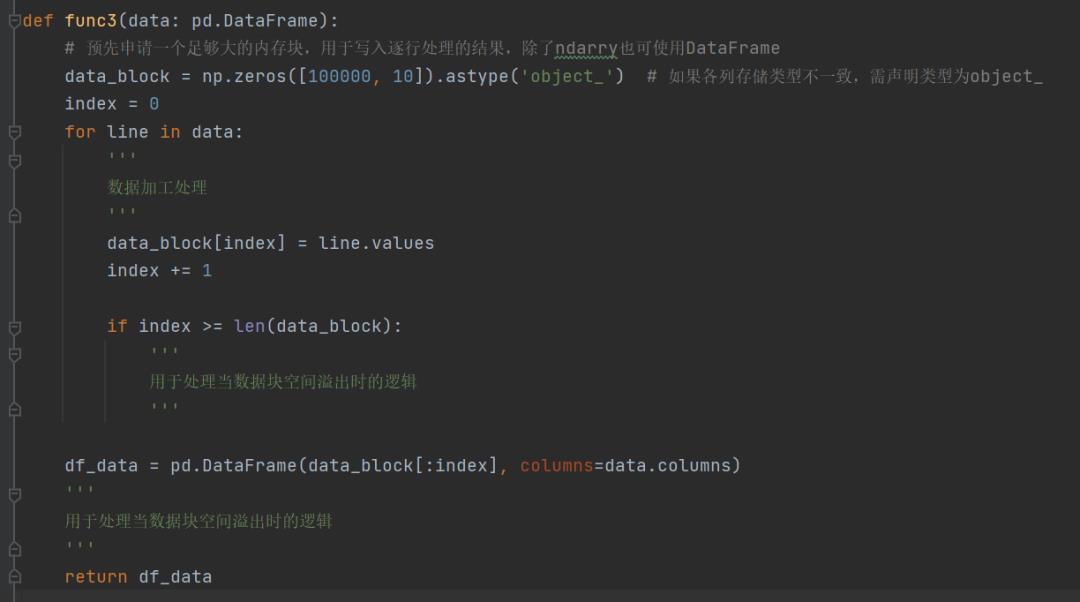
这种写法本质上是通过空间换取时间,即便数据量非常巨大,无法一次性写入内存,也可以通过数据块的方式,减少不必要的拼接操作。需要注意的是,数据块的边界处理条件,以避免漏行。
 避免链式赋值
避免链式赋值
链式赋值是几乎所有pandas的新人都会在不知不觉中犯的错误,并且产生恼人而又意义不明的SettingWithCopyWarning警告。实际上这个警告是在提醒开发者,你的代码可能没按你的预期运行,需要检查——很多时候可能产生难以调试发现的错误。当使用DataFrame作为输入的第三方库时,非常容易产生这类错误,且难以判断问题到底出现在哪儿。
在继续讲解链式复制前,需要先了解pandas的方法有一部分是返回的是输入数据的视图(view)一部分返回的是输入数据的拷贝(copy),还有少部分是直接修改源数据。
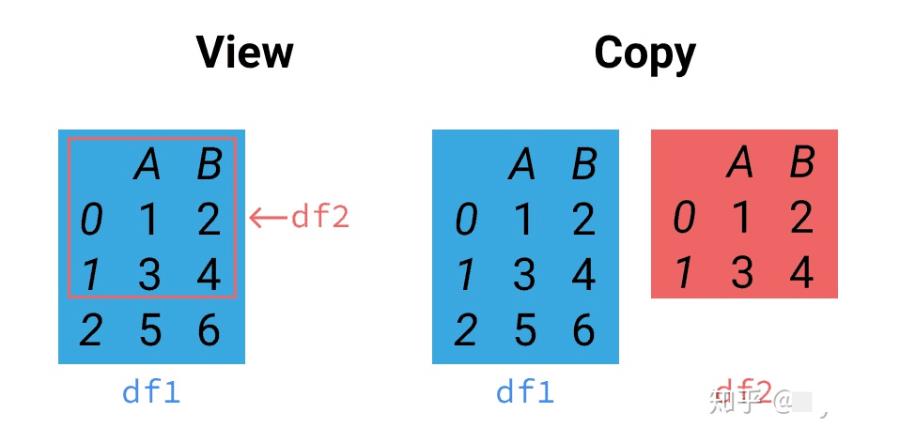
上图很好的解释了视图与拷贝的关系。当需要对df2进行修改时,有时候我们希望df1也能被修改,有时候则不希望。而当使用链式赋值时,则有可能产生歧义。这里的歧义指的是面向开发人员的,代码执行是不会有歧义的。
链式索引,就是对同一个数据连续的使用索引,形如data[1:5][2:3]这样。而链式赋值,就是使用链式索引进行赋值操作。下图是一个链式赋值的例子,解释器给出了SettingWithCopyWarning警告,同时对data的赋值操作也没有成功。
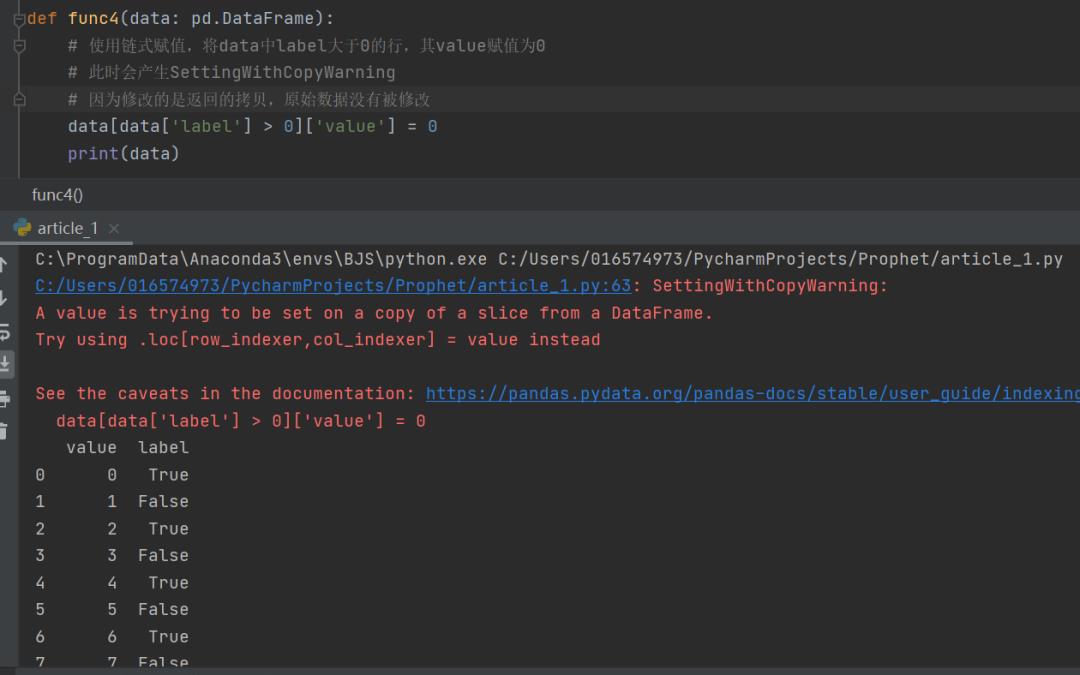
解决办法:上图中的警告建议,当你想修改原始数据时,使用loc来确保赋值操作被在原始数据上执行,这种写法对开发人员是无歧义的(开发人员往往会误认为链式赋值修改的依然是源数据)。
反过来的情况并不会发生这种歧义。如果开发人员想选取源数据的一部分,修改其中某列的值并赋给新的变量而不修改源数据,那么正常的写法就是无歧义的。

然而有些隐蔽的链式索引往往并不是简单的像上述情况那样,有可能跨越多行代码,甚至函数。下图的例子中,data_part是对data的选取,而赋值操作又对data_part进行了选取,此时构成了链式索引。
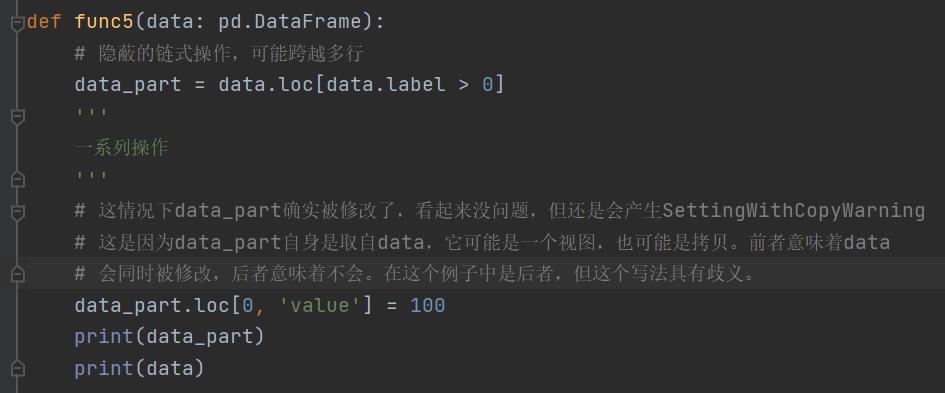
解决办法:当你确定是要构造拷贝时,明确指明构造拷贝。避免对有可能是视图的中间变量进行修改。

需要注意的是:DataFrame的索引操作到底是返回视图还是返回拷贝,取决于数据本身。对于单类型数据(全是某一类型的DataFrame)出于效率的考虑,索引操作总是返回视图,而对于多类型数据(列与列的数据类型不一样)则总是返回拷贝。但也请不要依赖这一特性,因为根据内存布局,其行为未必总是一致。最好的方法还是明确指定——如果想要写入副本数据,就在索引时明确拷贝;如果想要修改源数据,就使用loc严格赋值。

总结
1.可以直接修改源数据就修改源数据,避免不必要的拷贝
2.使用条件索引替代逐行遍历
3.构造数据块替代逐行添加
4.想修改源数据时使用data.loc[row_index, col_index]替代链式赋值
5.想构造副本时严格使用copy消除隐形链式赋值
参考资料:
https://numpy.org/doc/stable/reference/generated/numpy.append.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.append.html
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#indexing-label
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#indexing-view-versus-copy
https://zhuanlan.zhihu.com/p/41202576

扫描下方二维码,添加小助手
即刻加入 AI 科技大本营「读者群」
群内将不定期放送福利
快快加入吧!
以上是关于干货!机器学习中,如何优化数据性能的主要内容,如果未能解决你的问题,请参考以下文章