我要进大厂之大数据ZooKeeper知识点
Posted 努力的老刘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我要进大厂之大数据ZooKeeper知识点相关的知识,希望对你有一定的参考价值。
01
我们一起学大数据
02
第10点:说一说ZooKeeper集群架构
首先呢,ZooKeeper集群是一个主从架构,在ZooKeeper集群中有三个角色:leader,follower,observer。那知道了这三个东西,必须要了解它们的概念。
follower,跟随者,为客户端提供读写服务,向leader汇报自己的状态信息,同时也要参与“过半写成功”和leader选举。
observer,观察者,它是特殊的follower,为客户端提供读写服务,向leader汇报自己的状态信息,但不参与“过半写成功”和leader选举。
那客户端是如何和ZK集群进行写操作的呢?
有没有人觉得也会很简单,老刘当初就是这样想的,当看完之后就发现自己还是太肤浅了,ZK的写操作比ZK的读操作要复杂好多好多。
先分享出自己看到的一个特别好的例子,这个例子在老刘看来真的非常形象的表达出了ZK写操作的过程。
1、就是有一个富豪来到银行,对一个柜台小姐姐说我昨天在这里存钱,你们少给我存了1000万,现在需要你们给我加进去。
2、那这么大的金额,这个柜台小姐姐肯定是没有权限进行操作的,她就会汇报给经理,那经理也不能随便加,他为了让自己的操作服众,他就会征求自己所有下属的意见。
3、如果大多数人都同意加,经理就会做出决定,同意此事。并且会告知所有下属,让他们记下这件事。
4、那么最开始的柜台小姐姐就会通知富豪操作成功,加了1000万。
看完这个例子,大家接下里再看ZK写操作,就会发现几乎一模一样。
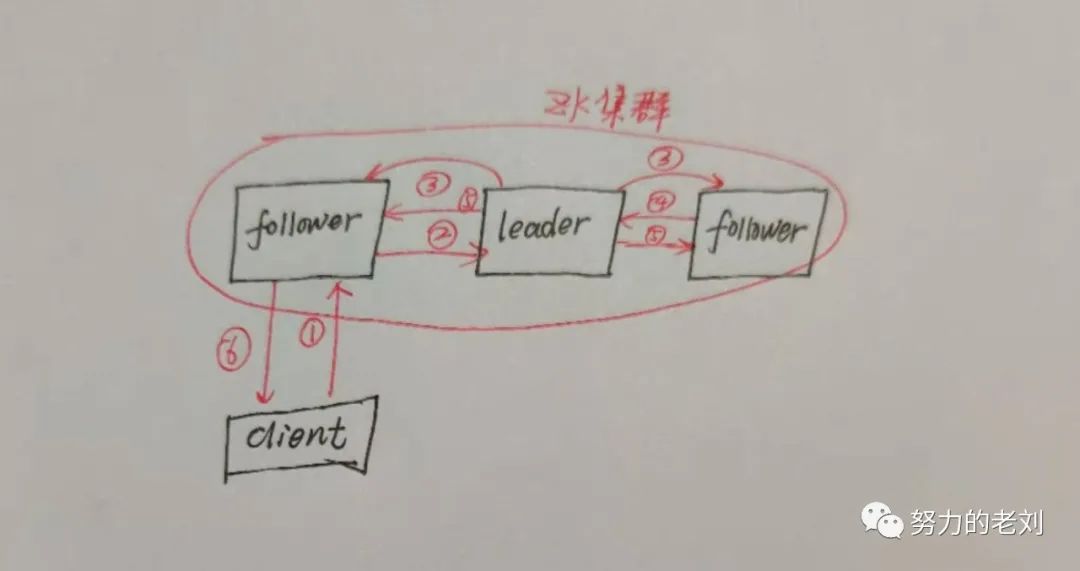
① 客户端向ZK集群写入数据,例如create /test;与集群中的最左边的follower建立session会话。
② follower就会将写请求转发给leader。
③ leader收到消息后,就会发出proposal提案创建/test,然后通知每个follower先记下要创建/test。
④ 现在就开始进行投票,是否允许创建/test这个写操作。如果在这个集群中,有个超过半数(quorum)的人同意,也同意的人包括leader自己,这个部分会在后面详细介绍,那么leader就会commit提案,leader就会在本地创建ZNode节点/test。
⑤ 之后leader就会通知所有follower,也commit提案,在各自的本地创建ZNode节点/test。
⑥ 结束上述所有操作后,最左边的follower就会响应客户端。
怎么样,怎么样,是不是和举的例子非常相似,哈哈哈!
第11点:ZK集群中leader选举
leader选举分为两种选举,一种是全新选举,另一种是非全新选举。这里老刘就仔细讲讲全新选举,非全新选举和全新选举大致相同,大家可以去自行搜索。
在leader选举中,有个非常重要的原则,就是超过半数(quorum)Server启动后,才能选举leader。这个半数如何计算呢?举个例子,在3台机器组成的ZK集群中,半数等于3/2+1=2,就是集群服务器的个数除以2,再加上1。
在选举过程中,每个服务器都会投票,投票信息是这种结构(sid, zxid),在全新leader选举中,每个服务器的初始投票信息为server1-(1, 0),server2-(2, 0),server3-(3, 0)。
那究竟如何判断选举得到leader呢?就是server1投票(sid1, zxid1),server2投票(sid2, zxid2),就会进行比较,先比较zxid,谁大谁是leader;如果zxid相等,就会比较sid,sid谁大谁是leader。
上述基本讲完了leader选举中的知识点,接下里就让老刘详细说一遍leader选举步骤,还是在3台机器组成的ZK集群中讲这个选举。
2、再启动ZK2;ZK1和ZK2票投给自己及其他服务器;ZK1的投票为(1, 0),ZK2的投票为(2, 0)。
3、现在集群个数达到2,就可以进行选举了,先开始处理投票。ZK1会把投给自己的票(1,0)与ZK2传过来的票(2,0)比较;利用leader选举公式,因为zxid都为0,相等;所以判断sid最大值;2>1;所以ZK1更新自己的投票为(2, 0)。同样的道理,ZK2也进行同样的逻辑,ZK2更新自己的投票为(2,0)。
4、处理完投票后,再次发起投票选举。现在ZK1、ZK2上的投票都是(2,0),那么ZK2就会被选为leader,接着就会更改服务器状态,更改ZK2为Leader;更改ZK1状态为Follower。
5、最后当K3启动时,它发现集群中已经有了Leader,就不会进行选举,直接变为follower。
第12点:仲裁qurorum知识点总结
就是不需要所有的服务器都响应,proposal就能生效,提高了集群的响应速度,也比较合理。
quorum数如何选择?
在3台机器组成的ZK集群中,半数等于3/2+1=2,就是集群服务器的个数除以2,再加上1。
第13点:ZooKeeper工作原理
读写操作已经在第10点讲述,现在开始讲讲ZooKeeper状态同步。在完成leader选举之后,ZK就会进入ZooKeeper之间的状态同步。
那究竟是如何进行状态同步的呢?让老刘先把脑子里记得的东西写出来,不急!
1、leader会构建一个NEWLEADER封包,在这个NEWLEADER封包中包含着这个leader的最大zxid,然后广播给其他follower。
2、follower接收到后,就会用自己的最大的zxid进行比较,如果自己的最大zxid小于leader的,那就说明自己的数据不是最新的,需要和leader状态进行同步;否则不需要。
3、如果需要同步,那leader就会给需要同步的每个follower创建LearnerHandler线程,这个线程就会负责数据同步的请求。
4、leader主线程就会等待LearnHandler线程处理完结果。只有大多数follower完成同步时,leader才开始对外响应写的请求。
5、上述是大致的状态同步过程,但是在第4步仅仅简单描述了一下LearnerHandler线程,接下里就详细说一下在LearnerHandler线程的流程:
① 首先会接收follower的封包FOLLOWERINFO,包含这个follower的最大zxid。
② follower的最大zxid与leader最大zxid比较,若相等,说明当前follower是最新的;
③ 在判断期间,还要判断有没有新提交的proposal。如果有,就会发送DIFF封包将有差异的数据同步过去。同时将follower中没有的数据逐个发送COMMIT封包给follower保存下来;如果没有,但follower数据id更大,那么会发送TRUNC封包告知截除多余数据;如果follower的最大zxid比leader最大zxid小,就会直接发送SNAP封包将快照同步发送给follower。
④ 以上消息完毕之后,就会发送UPTODATE封包告知follower当前数据就是最新的了,就差不多了。
第14点:ZooKeeper实例之HDFS HA
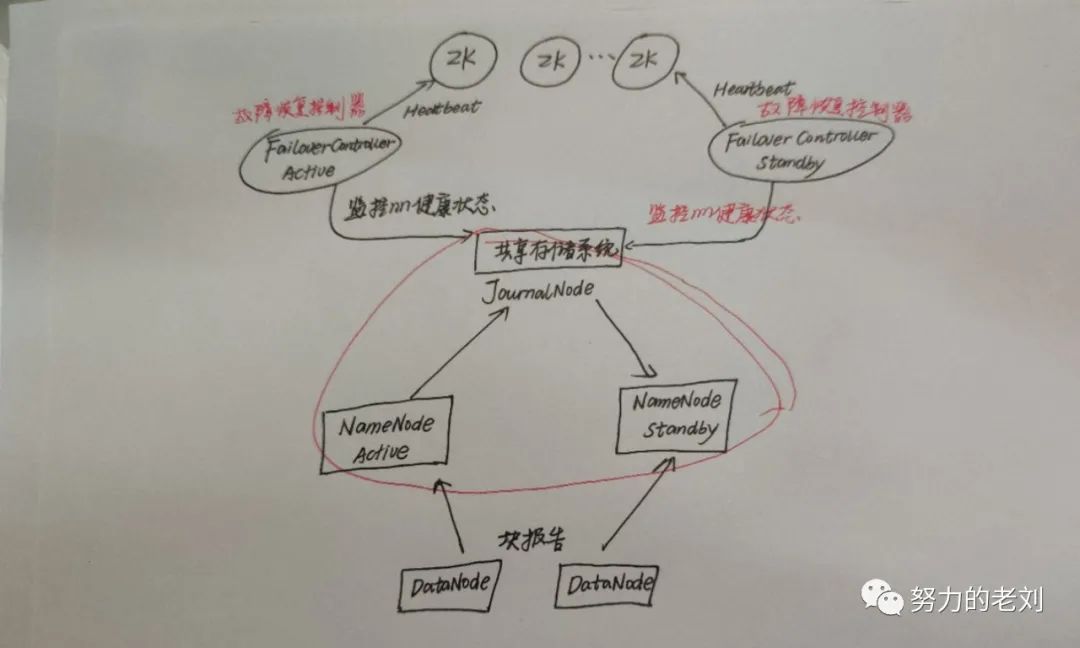
讲了那么多ZooKeeper的原理,现在开始讲讲ZooKeeper的实例,免得面试官问ZooKeeper相关的实例,自己没有准备。这次主要讲讲HDFS HA,HDFS HA实现高可用主要就是依赖于ZooKeeper,它主要包括两部分:一个是元数据同步,一个是主备切换。
先讲讲元数据同步,主要是下图中的画红圈部分。
现在就到了主备切换,好好讲讲!先画出流程图:
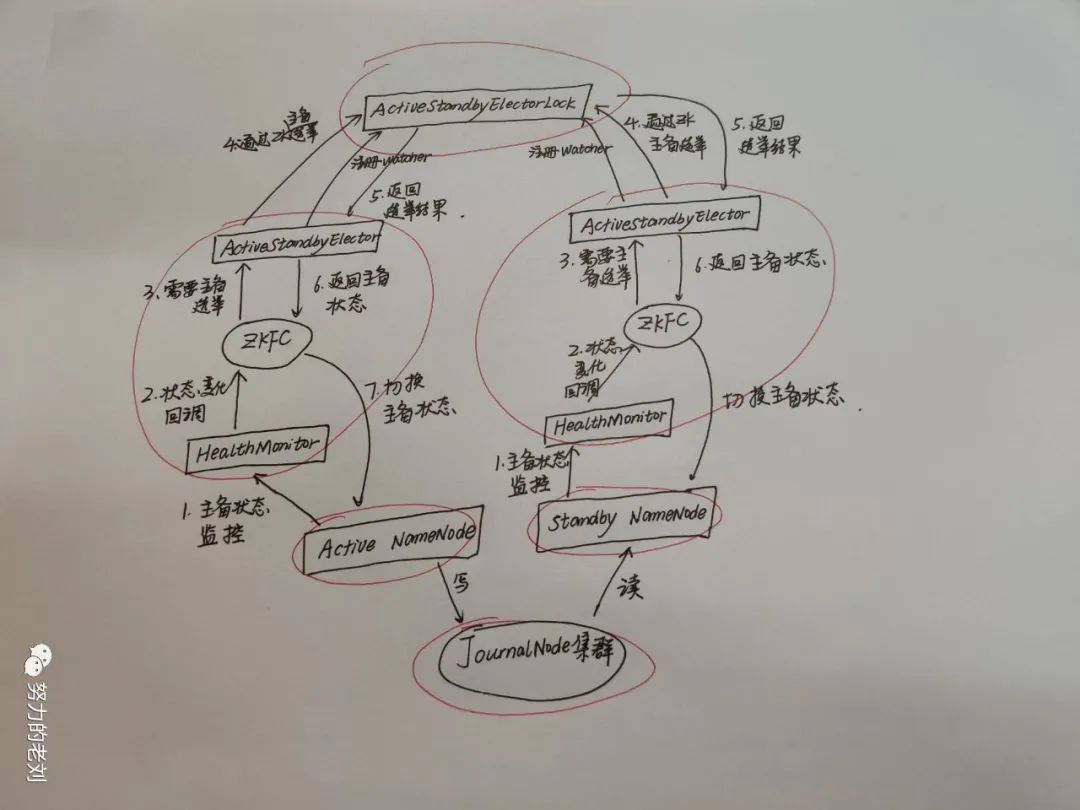
1、每个NameNode节点上都会有一个ZKFC进程,ZKFC进程它负责控制NameNode的主备切换。
什么是脑裂?
在分布式系统中出现两个leader的现象,就是脑裂。产生的原因有很多,例如网络有延迟之类的,这种情况的出现是非常可怕的,必须通过自带的隔离(Fencing)机制来避免这种现象。
那隔离到底是怎么做到隔离的呢?
2、当Active NameNode在正常的状态下断开Session,会同时删除临时节点ActiveStandbyElectorLock、持久节点ActiveBreadCrumb。
3、但是如果ActiveStandbyElector在异常的状态下关闭Session,那么持久节点ActiveBreadCrumb会保留下来。
03
最后,有事,就联系老刘,没事就和老刘一起加油,进大厂,
以上是关于我要进大厂之大数据ZooKeeper知识点的主要内容,如果未能解决你的问题,请参考以下文章