《我要进大厂系列 九》-谈谈Spring循环依赖
Posted 熊猫IT学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《我要进大厂系列 九》-谈谈Spring循环依赖相关的知识,希望对你有一定的参考价值。
文章目录
1.前言
想彻底弄清楚spring的循环依赖问题,首先得弄清楚
- 循环依赖是如何发生的,spring又是如何检测循环依赖的发生的。
- 其次再探究spring如何解决循环依赖的问题
2.什么是循环依赖?
循环依赖就是循环引用,指两个或多个bean互相持有对方,比如说TestA引用TestB、TestB引用TestA,最终形成一个闭环。
注意:循环依赖不是指循环调用。
循环调用:指方法之间的环调用,循环调用是无解的,除非有终结条件,否则就是死循环,最终会导致内存溢出异常。
3.两种Spring容器循环依赖
- 构造器循环依赖
- setter方法循环依赖
就是A类里面有B类的引用b,B类里面有C类的引用c,C类里面有A类的引用a,如下图所示
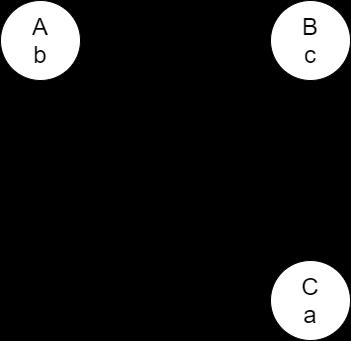
3.1.构造器循环依赖(无法解决)
A类
package com.bruce.spring2021;
public class A {
private B b;
public A (B b){
this.b = b;
}
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
}
B类
package com.bruce.spring2021;
public class B {
private C c;
public B (C c){
this.c = c;
}
public C getC() {
return c;
}
public void setC(C c) {
this.c = c;
}
}
C类
package com.bruce.spring2021;
public class C {
private A a;
public C (A a){
this.a = a;
}
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
}
applicationContext.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="A" class="com.bruce.spring2021.A" >
<constructor-arg name="b" ref="B"/>
</bean>
<bean id="B" class="com.bruce.spring2021.B" >
<constructor-arg name="c" ref="C"/>
</bean>
<bean id="C" class="com.bruce.spring2021.C" >
<constructor-arg name="a" ref="A"/>
</bean>
</beans>
主函数入口
package com.bruce.spring2021;
import org.junit.Test;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestSpring {
@Test
public void test1(){
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
}
}
运行main函数,报错截图
3.2.setter循环依赖(可以解决)
A类
public class A {
public A() {
}
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
}
}
B类
public class B {
public B() {
}
private C c;
public C getC() {
return c;
}
public void setC(C c) {
this.c = c;
}
}
C类
public class C {
public C() {
}
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
}
}
applicationContext.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="A" class="com.bruce.spring2021.A" >
<property name="b" ref="B"/>
</bean>
<bean id="B" class="com.bruce.spring2021.B" >
<property name="c" ref="C"/>
</bean>
<bean id="C" class="com.bruce.spring2021.C" >
<property name="a" ref="A"/>
</bean>
</beans>
最后输出
package com.bruce.spring2021;
import org.junit.Test;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestSpring {
@Test
public void test2(){
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext1.xml");
A a = ctx.getBean("A", A.class);
//System.out.println(a);
//System.out.println(a.getB());
//System.out.println(a.getB().getC());
//System.out.println(a.getB().getC().getA());
}
}
3.3.小结
通常来说,如果问Spring内部如何解决循环依赖,一定是单默认的单例Bean中,属性互相引用的场景。比如几个Bean之间的互相引用:
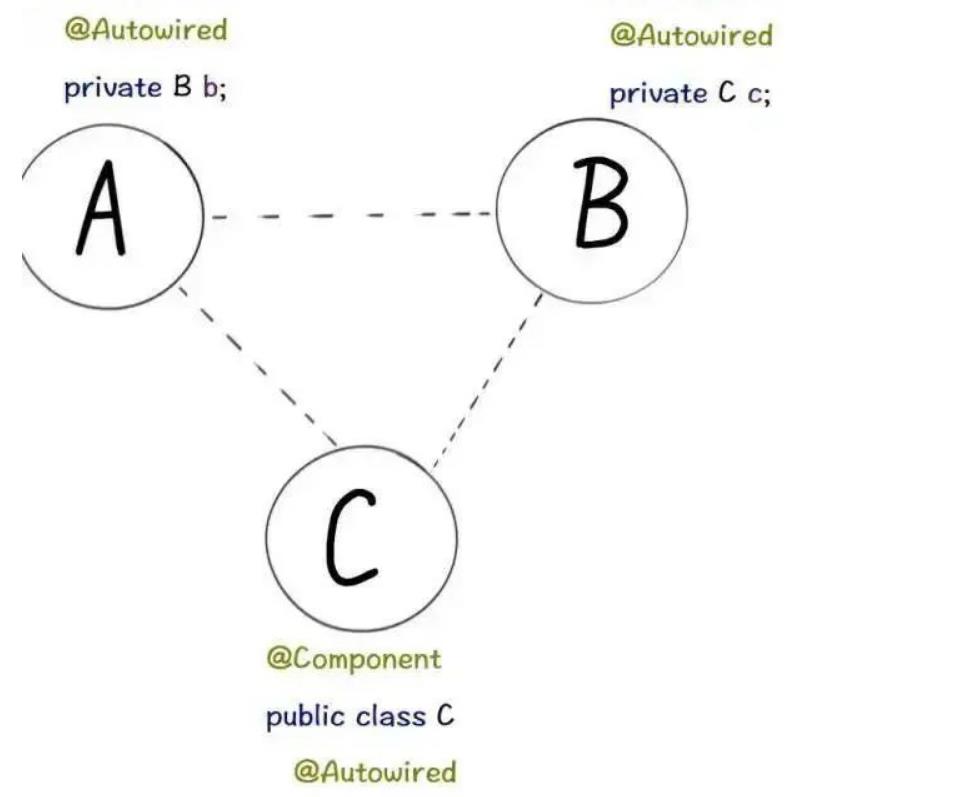
甚至自己“循环”依赖自己:
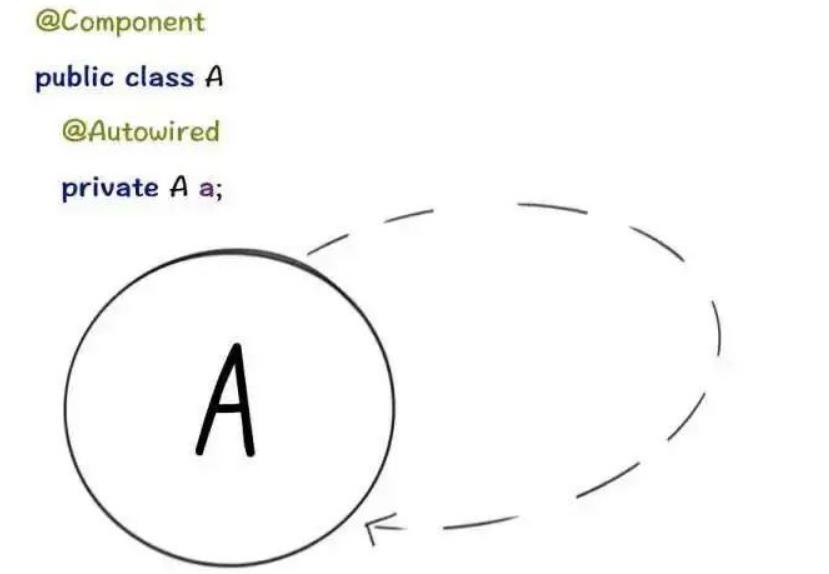
先说明前提:原型(Prototype)的场景是不支持循环依赖的,通常会走到AbstractBeanFactory类中下面的判断,抛出异常
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
原因很好理解,创建新的A时,发现要注入原型字段B,又创建新的B发现要注入原型字段A…
这就套娃了, 你猜是先StackOverflow还是OutOfMemory?
Spring怕你不好猜,就先抛出了BeanCurrentlyInCreationException
基于构造器的循环依赖,就更不用说了,官方文档都摊牌了,你想让构造器注入支持循环依赖,是不存在的,不如把代码改了。
那么默认单例的属性注入场景,Spring是如何支持循环依赖的?
4.循环依赖检查
<bean id="a" class="A">
<property name="b" ref="b">
<bean/>
<bean id="b" class="B">
<property name="a" ref="a">
<bean/>
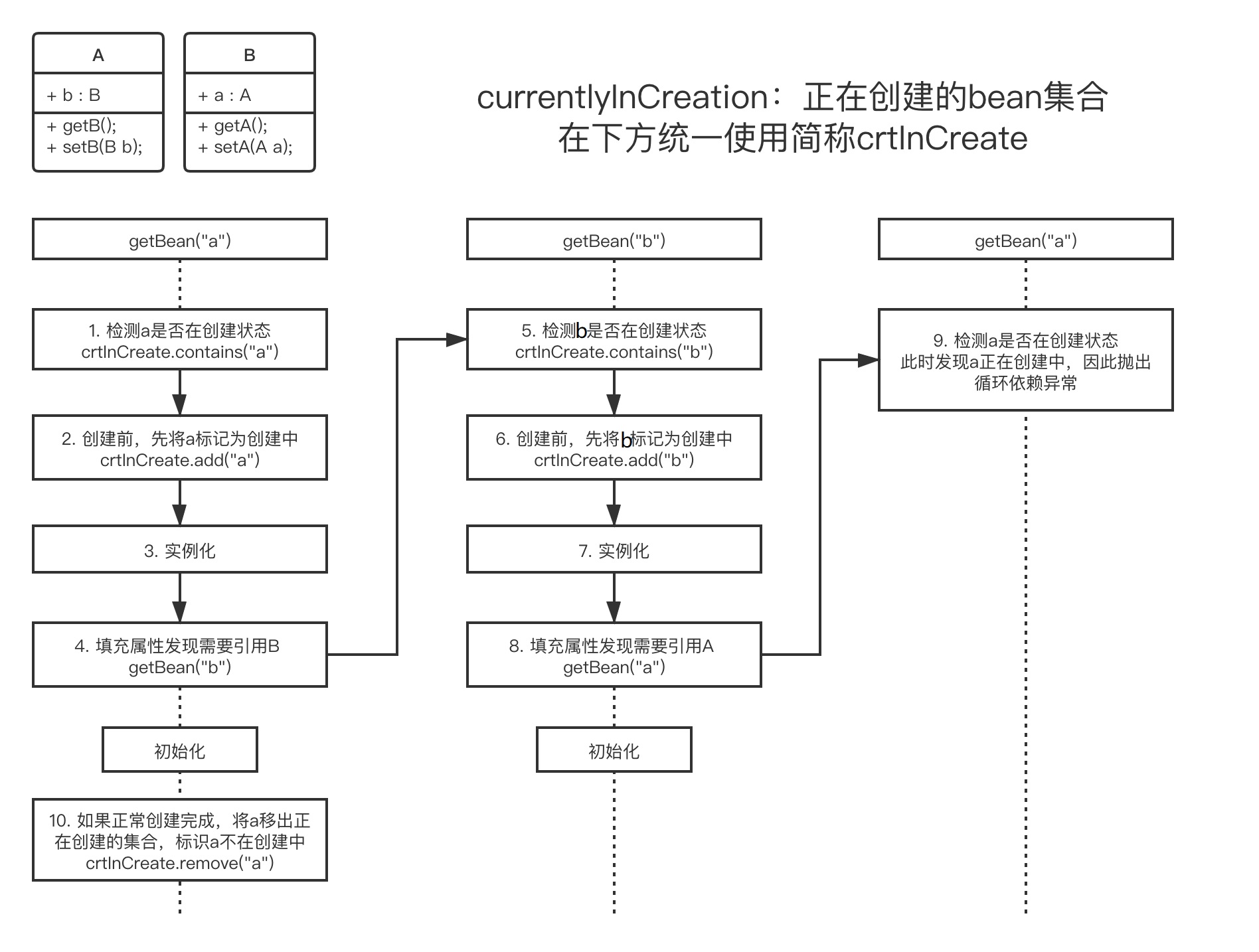
无论单例还是原型模式(下文①代表图中步骤1),spring都有对应的集合(singletonsCurrentlyInCreation)保存当前正在创建的beanName,标识该beanName正在被创建。
在bean创建前,
①检测当前bean是否在创建中,如果不在创建中则
②将beanName加入集合,往下创建bean。在bean创建前,检测到当前的bean正在创建,则说明发生循环依赖,抛出异常。最后记得当bean创建完时将beanName移出集合。
5.循环依赖的处理
5.1.单例setter循环依赖
spring注入属性的方式有多种,但是只有一种循环依赖能被解决:setter依赖注入。
spring解决循环依赖的做法是未等bean创建完就先将实例曝光出去,方便其他bean的引用。同时还提到了三级缓存,最先曝光到第三级缓存singletonFactories中。简单的说,就是spring先将创建好的实例放到缓存中,让其他bean可以提前引用到该对象。
示例
// 第一种 注解方式
public class A {
@Autowired
private B b;
}
public class B {
@Autowired
private A a;
}
// ===========================
// 第二种 xml配置方式
public class A {
private B b;
// getter setter
}
public class B {
private A a;
// getter setter
}
<bean id="a" class="A">
<property name="b" ref="b">
<bean/>
<bean id="b" class="B">
<property name="a" ref="a">
<bean/>
分析
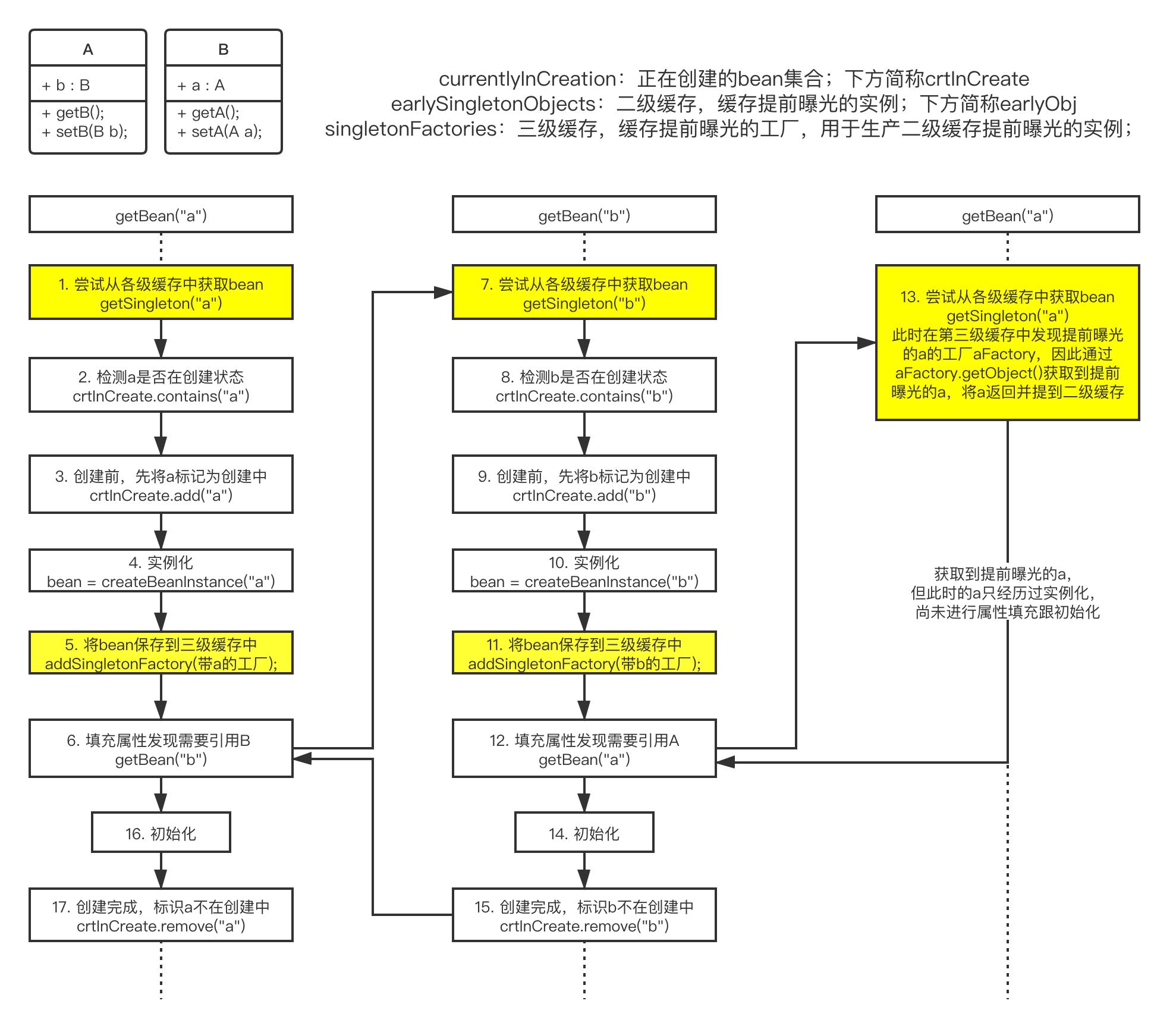
其中跟循环依赖检测对比,新添加的几个关键节点已经用黄色标识出来,这里有几个重点给大家画一下。
-
提前曝光,如果用c语言的说法就是将指针曝光出去,用java就是将引用对象曝光出去。也就是说即便a对象还未创建完成,但是在④实例化过程中new A()动作已经开辟了一块内存空间,只需要将该地址抛出去b就可以引用的到,而不管a后期还会进行初始化等其他操作
-
已经了解了提前曝光的作用,而相比而言⑤曝光的时机也非常的重要,该时机发生在④实例化之后,⑥填充与⑯ 初始化之前。spring循环依赖之所以不能解决实例化注入的原因正式因为注入时机在曝光之前所导致
5.2.Spring解决循环依赖
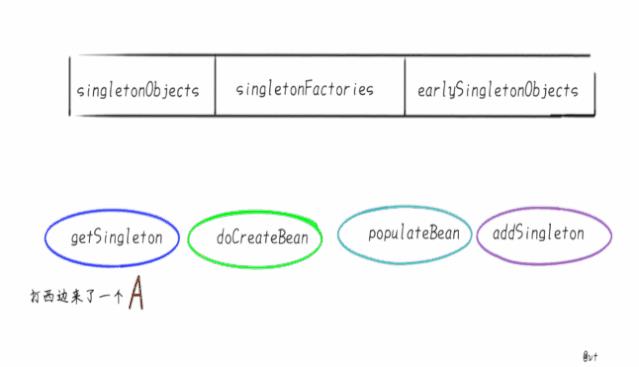
首先,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
在Spring的DefaultSingletonBeanRegistry类中,你会赫然发现类上方挂着这三个Map:
singletonObjects它是我们最熟悉的朋友,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。singletonFactories映射创建Bean的原始工厂earlySingletonObjects映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance.
后两个Map其实是“垫脚石”级别的,只是创建Bean的时候,用来借助了一下,创建完成就清掉了。
为什么成为后两个Map为垫脚石,假设最终放在singletonObjects的Bean是你想要的一杯“凉白开”。
那么Spring准备了两个杯子,即singletonFactories和earlySingletonObjects来回“倒腾”几番,把热水晾成“凉白开”放到singletonObjects中。
闲话不说,都浓缩在图里。
5.3. 循环依赖的本质
上文了解完Spring如何处理循环依赖之后,让我们跳出“阅读源码”的思维,假设让你实现一个有以下特点的功能,你会怎么做?
- 将指定的一些类实例为单例
- 类中的字段也都实例为单例
- 支持循环依赖
举个例子,假设有类A:
public class A {
private B b;
}
// 类B:
public class B {
private A a;
}
说白了让你模仿Spring:假装A和B是被@Component修饰, 并且类中的字段假装是@Autowired修饰的,处理完放到Map中。其实非常简单,笔者写了一份粗糙的代码,可供参考:
/**
* 放置创建好的bean Map
*/
private static Map<String, Object> cacheMap = new HashMap<>(2);
public static void main(String[] args) {
// 假装扫描出来的对象
Class[] classes = {A.class, B.class};
// 假装项目初始化实例化所有bean
for (Class aClass : classes) {
getBean(aClass);
}
// check
System.out.println(getBean(B.class).getA() == getBean(A.class));
System.out.println(getBean(A.class).getB() == getBean(B.class));
}
@SneakyThrows
private static <T> T getBean(Class<T> beanClass) {
// 本文用类名小写 简单代替bean的命名规则
String beanName = beanClass.getSimpleName().toLowerCase();
// 如果已经是一个bean,则直接返回
if (cacheMap.containsKey(beanName)) {
return (T) cacheMap.get(beanName);
}
// 将对象本身实例化
Object object = beanClass.getDeclaredConstructor().newInstance();
// 放入缓存
cacheMap.put(beanName, object);
// 把所有字段当成需要注入的bean,创建并注入到当前bean中
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// 获取需要注入字段的class
Class<?> fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// 如果需要注入的bean,已经在缓存Map中,那么把缓存Map中的值注入到该field即可
// 如果缓存没有 继续创建
field.set(object, cacheMap.containsKey(fieldBeanName)
? cacheMap.get(fieldBeanName) : getBean(fieldClass));
}
// 属性填充完成,返回
return (T) object;
}
这段代码的效果,其实就是处理了循环依赖,并且处理完成后,cacheMap中放的就是完整的“Bean”了
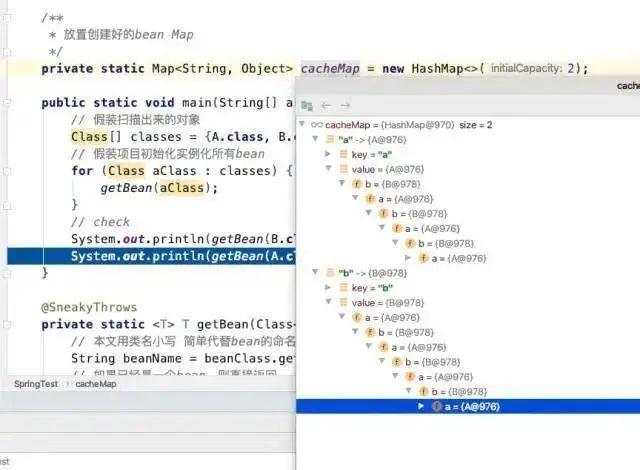
这就是“循环依赖”的本质,而不是“Spring如何解决循环依赖”。
5.4.what?问题的本质居然是two sum!
看完笔者刚才的代码有没有似曾相识?没错,和two sum的解题是类似的。不知道two sum是什么梗的,笔者和你介绍一下:two sum是刷题网站leetcode序号为1的题,也就是大多人的算法入门的第一题。常常被人调侃,有算法面的公司,被面试官钦定了,合的来。那就来一道two sum走走过场。
问题内容是:给定一个数组,给定一个数字。返回数组中可以相加得到指定数字的两个索引。比如:给定nums = [2, 7, 11, 15], target = 9 那么要返回 [0, 1],因为2 + 7 = 9这道题的优解是,一次遍历+HashMap:
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
}
先去Map中找需要的数字,没有就将当前的数字保存在Map中,如果找到需要的数字,则一起返回。
和笔者上面的代码是不是一样?
先去缓存里找Bean,没有则实例化当前的Bean放到Map,如果有需要依赖当前Bean的,就能从Map取到。
5.5.单例构造器注入循环依赖
上面已经剧透了这个方式是不得行的,原因是依赖注入的时间点不对,他的依赖注入发生在构造器阶段,这个时候连实例都没有,内存都还没开辟完,当然也还没有进行提前曝光,因此不得行
示例
public class A {
private B b;
@Autowired
public A(B b) {
this.b = b;
}
}
public class B {
private A a;
@Autowired
public B(A a) {
this.a = a
}
}
分析
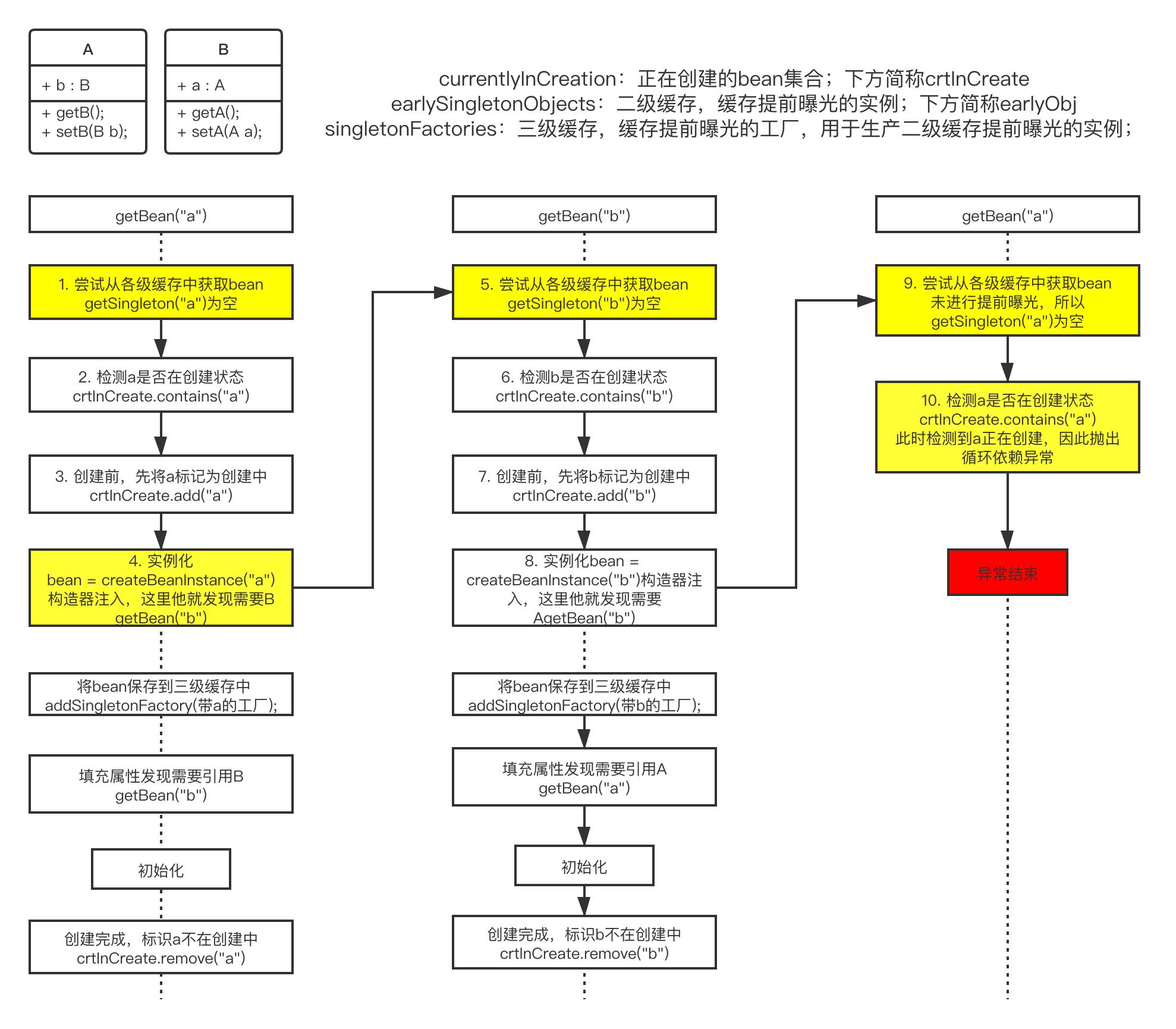
图上重点地方也用黄色标出了,问题的原因处在④实例化,实例化的过程是调用new A(B b);的过程,这时的A还未创建出来,根本是不可能提前曝光的,正是这个原因导致⑨无法获取到三级缓存,进而导致⑩异常的抛出
5.6.原型模式循环依赖
这此没有图了,因为原型模式每次都是重新生成一个全新的bean,根本没有缓存一说。这将导致实例化A完,填充发现需要B,实例化B完又发现需要A,而每次的A又都要不一样,所以死循环的依赖下去。唯一的做法就是利用循环依赖检测,发现原型模式下存在循环依赖并抛出异常.
6.总结
6.1.循环依赖的原因
beanA依赖beanB,beanB依赖beanA,导致两者都不能被创建,发生在填充属性的环节
6.2.循环依赖的解决方案
提前曝光机制+三级缓存
- 提前曝光
正常来说bean的创建过程有三步:实例化->填充属性->初始化,提前曝光就是实例化后填充属性前将bean放入缓存
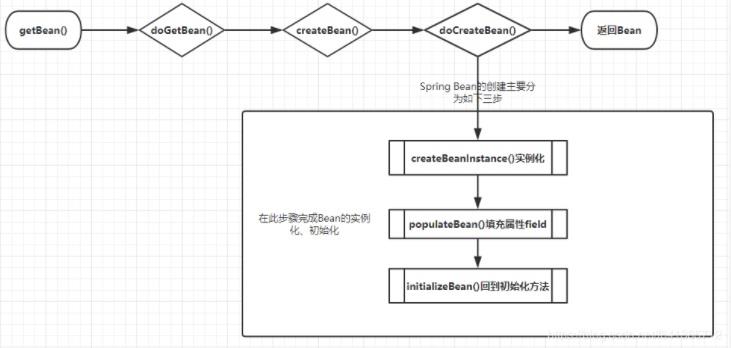
总结一下循环依赖,spring只能解决setter注入单例模式下的循环依赖问题。要想解决循环依赖必须要满足2个条件:
- 需要用于
提前曝光的缓存 - 属性的
注入时机必须发生在提前曝光动作之后,不管是填充还是初始化都行,总之不能在实例化,因为提前曝光动作在实例化之后
理解了这2点就可以轻松驾驭循环依赖了。比如构造器注入是不满足第二个条件,曝光时间不对。而原型模式则是缺少了第一个条件,没有提前曝光的缓存供使用。
- 三级缓存
singletonObjects:一级缓存,用于存放完全初始化好的bean,从改缓存中取出的bean可以直接使用
earlySingletonObjects:二级缓存,用于存放提前曝光的单例对象的cache,存放原始的bean对象(尚未填充属性)
singletoneFactories:三级以上是关于《我要进大厂系列 九》-谈谈Spring循环依赖的主要内容,如果未能解决你的问题,请参考以下文章