去pdd面试,redis把我面哭了附面试答案
Posted springmeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去pdd面试,redis把我面哭了附面试答案相关的知识,希望对你有一定的参考价值。
https://www.toutiao.com/i6768458827856609804/
俗话说,面试造航母,工作拧螺丝。
但是想进大厂,就得经过很复杂的面试,才有资格去大厂扭螺丝。今天看下某网友去pdd面试,都问了哪些技术。面试都附了答案,如果不会的,我们可以继续充电哦。
祝你早日挺近大厂,奥利给……下面看面试情况
1、简单做一下自我介绍吧,为什么这么快就想换工作。简单说下你简历中的项目。
2、看你在项目中用了redis,我们先聊聊redis吧,常用的数据结构有哪几种,在你的项目中用过哪几种,以及在业务中使用的场景,redis的hash怎么实现的,rehash过程讲一下和JavaHashMap的rehash有什么区别?
redis cluster有没有了解过,怎么做到高可用的?
3redis集群和哨兵机制有什么区别?redis的持久化机制了解吗?你们在项目中是怎么做持久化的?遇到过redis的hotkey吗?怎么处理的?
4redis是单线程的吗?单线程为什么还这么快?讲一讲redis的内存模型?
5.我看你还用了RabbitMQ,简单说一下RabbitMQ的工作原理?如何保证消息的顺序执行?Kafka了解吗?和RabbitMQ有什么区别?你为啥不用kafka来做,当时怎么考虑的?
6、我看你简历里说熟悉计算机网络,来聊一聊计算机网络吧。了不了解tcp/udp,简单说下两者的区别?tcp为什么要三次握手和四次挥手?两次握手可以不?会有什么问题?
tcp怎么保证有序传输的,讲下tcp的快速重传和拥塞机制,知不知道time_wait状态,这个状态出现在什么地方,有什么用?
7、http与https有啥区别?https是怎么做到安全的?
8、有没有了解过协程?说下协程和线程的区别?用过哪些linux命令?如查看内存使用、网络情况?
9、你了解哪些设计模式啊。挑一个熟悉的讲讲?(除了单例模式)在项目中有用过设计模式吗?讲讲你怎么用的?简单说一下适配器模式和装饰器模式?
10、你们数据库有没有用到分库分表,怎么做的?分库分表以后全局id怎么生成的?
11、索引的常见实现方式有哪些,有哪些区别?mysql的存储引擎有哪些,有哪些区别?InnoDB使用的是什么方式实现索引,怎么实现的?说下聚簇索引和非聚簇索引的区别?
12、看你简历提到了raft算法,讲下raft算法的基本流程?raft算法里面如果出现脑裂怎么处理?有没有了解过paxos和zookeeper的zab算法,他们之前有啥区别?
13、聊聊java基础吧,如果我是想一个人的姓名一样就认为他们equal,能现场写下我们怎么重写equals吗?如果两个对象,一个是cat,一个是dog,我们认为他们的name属性一样就一样,怎么重写equals
14,还有点时间,写个题吧
leetcode406. 根据身高重建队列
假设有打乱顺序的一群人站成一个队列。每个人由一个整数对(h, k)表示,其中h是这个人的身高,k是排在这个人前面且身高大于或等于h的人数。编写一个算法来重建这个队列。
注意:
总人数少于1100人。
示例
输入:
[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]
输出:
[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]
一:看你在项目中用了redis,我们先聊聊redis吧,常用的数据结构有哪几种,在你的项目中用过哪几种,以及在业务中使用的场景,redis的hash怎么实现的,rehash过程讲一下和JavaHashMap的rehash有什么区别?redis cluster有没有了解过,怎么做到高可用的?
(1)常用的数据结构:
字符串(String),散列/哈希(hash),列表(list),无序集合类型(set),有序集合类型(sorted set)
(2)Redis的hash 实现:
Redis散列/哈希是键值对的集合。Redis散列/哈希是字符串字段和字符串值之间的映射,但字段值只能是字符串,不支持其他类型。因此,他们用于表示对象。应用场景:存储用户的基本信息,等等、
(3)redis cluster:
redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出来哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以在3.x提出cluster集群模式。
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
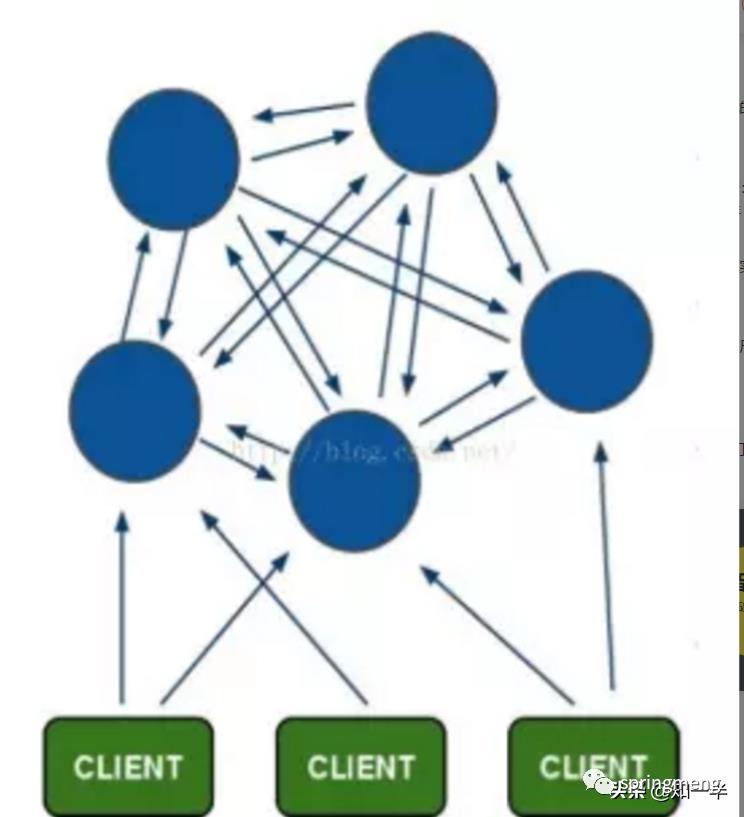
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
二.redis集群和哨兵机制有什么区别?redis的持久化机制了解吗?你们在项目中是怎么做持久化的?遇到过redis的hotkey吗?怎么处理的?
(1)redis集群和哨兵机制有什么区别?
谈到Redis服务器的高可用,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制。
哨兵(Sentinel):可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转移的功能。
复制(Replication):则是负责让一个Redis服务器可以配备多个备份的服务器。
Redis正是利用这两个功能来保证Redis的高可用。
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题。
Redis哨兵主要功能
(1)集群监控:负责监控Redis master和slave进程是否正常工作
(2)消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移:如果master node挂掉了,会自动转移到slave node上
Redis哨兵的高可用
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
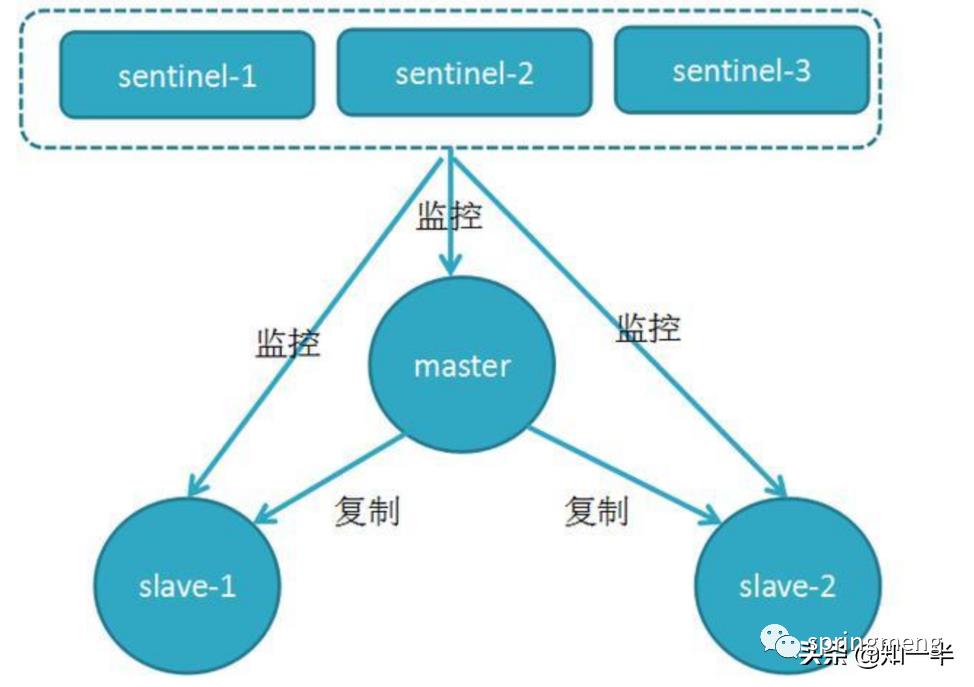
1.哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
2.同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
3.每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
这个就是哨兵用来判断节点是否正常的重要依据,涉及两个新的概念:主观下线和客观下线。
1. 主观下线:一个哨兵节点判定主节点down掉是主观下线。
2.客观下线:只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
原理:基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
Redis 复制
Redis为了解决单点数据库问题,会把数据复制多个副本部署到其他节点上,通过复制,实现Redis的高可用性,实现对数据的冗余备份,保证数据和服务的高度可靠性。
1.数据复制原理(执行步骤)
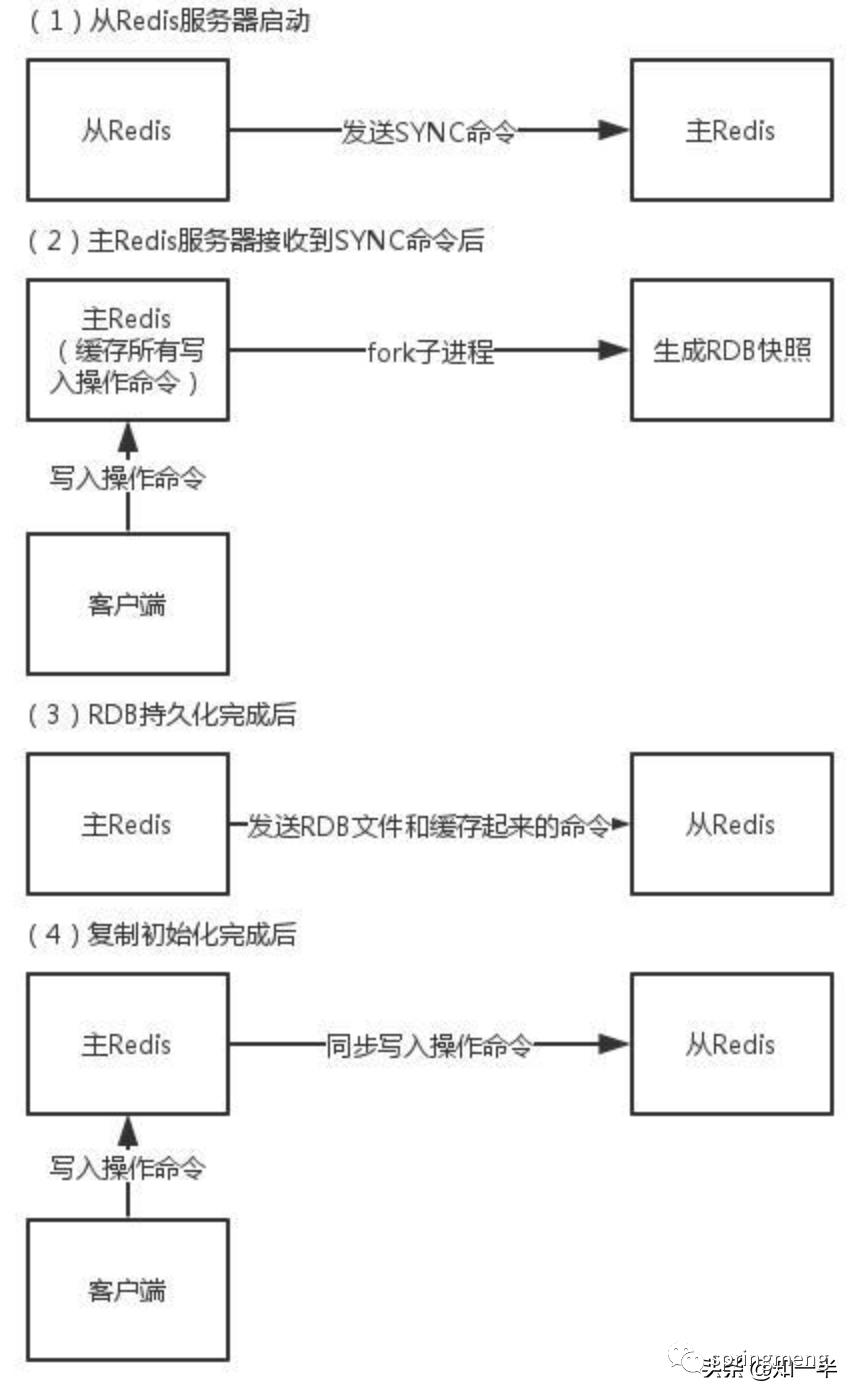
①从数据库向主数据库发送sync(数据同步)命令。
②主数据库接收同步命令后,会保存快照,创建一个RDB文件。
③当主数据库执行完保持快照后,会向从数据库发送RDB文件,而从数据库会接收并载入该文件。
④主数据库将缓冲区的所有写命令发给从服务器执行。
⑤以上处理完之后,之后主数据库每执行一个写命令,都会将被执行的写命令发送给从数据库。
注意:在Redis2.8之后,主从断开重连后会根据断开之前最新的命令偏移量进行增量复制
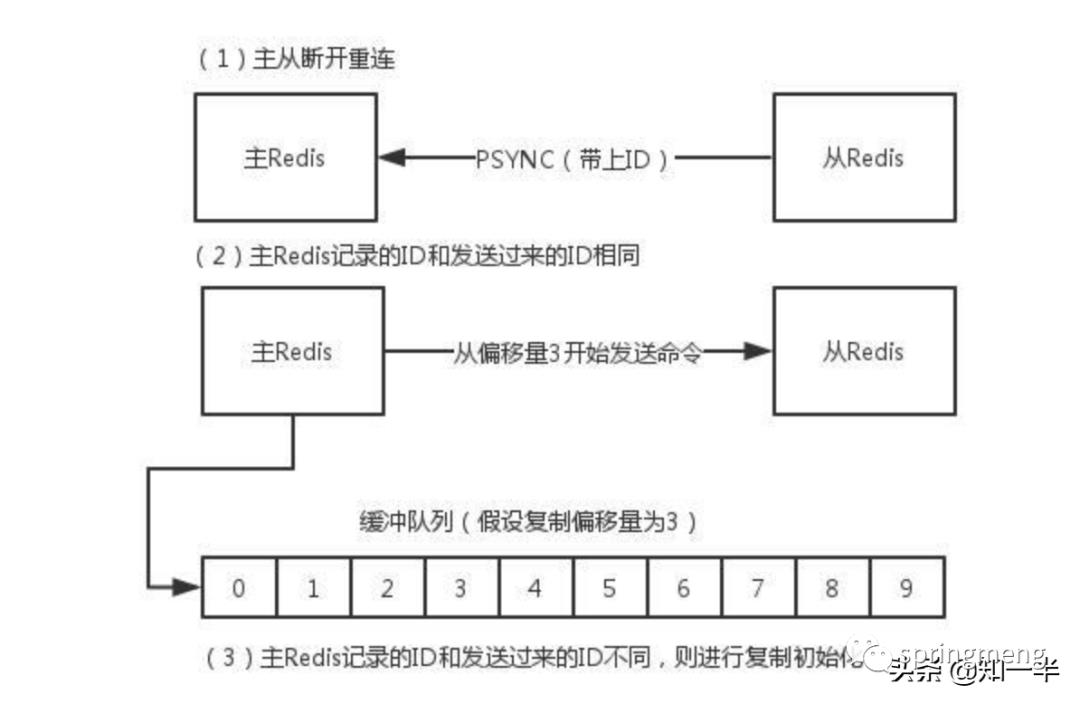
Redis 主从复制、哨兵和集群这三个有什么区别
主从复制是为了数据备份,哨兵是为了高可用,Redis主服务器挂了哨兵可以切换,集群则是因为单实例能力有限,搞多个分散压力,简短总结如下:
主从模式:备份数据、负载均衡,一个Master可以有多个Slaves。
sentinel发现master挂了后,就会从slave中重新选举一个master。
cluster是为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器。
sentinel着眼于高可用,Cluster提高并发量。
1.主从模式:读写分离,备份,一个Master可以有多个Slaves。
2.哨兵sentinel:监控,自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器。
3.集群:为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
4:redis是单线程的吗?单线程为什么还这么快?讲一讲redis的内存模型?
Redis内存划分:
Redis作为内存数据库,在内存中存储的内容主要是数据(键值对);通过前面的叙述可以知道,除了数据以外,Redis的其他部分也会占用内存。
Redis的内存占用主要可以划分为以下几个部分:
1、数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
Redis使用键值对存储数据,其中的值(对象)包括5种类型,即字符串、哈希、列表、集合、有序集合。这5种类型是Redis对外提供的,实际上,在Redis内部,每种类型可能有2种或更多的内部编码实现;此外,Redis在存储对象时,并不是直接将数据扔进内存,而是会对对象进行各种包装:如redisObject、SDS等;这篇文章后面将重点介绍Redis中数据存储的细节。
2、进程本身运行需要的内存
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
补充说明:除了主进程外,Redis创建的子进程运行也会占用内存,如Redis执行AOF、RDB重写时创建的子进程。当然,这部分内存不属于Redis进程,也不会统计在used_memory和used_memory_rss中。
3、缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;其中,客户端缓冲存储客户端连接的输入输出缓冲;复制积压缓冲用于部分复制功能;AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
4、内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
内存碎片的产生与对数据进行的操作、数据的特点等都有关;此外,与使用的内存分配器也有关系:如果内存分配器设计合理,可以尽可能的减少内存碎片的产生。后面将要说到的jemalloc便在控制内存碎片方面做的很好。
如果Redis服务器中的内存碎片已经很大,可以通过安全重启的方式减小内存碎片:因为重启之后,Redis重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选择合适的内存单元,减小内存碎片。
5. 我看你还用了RabbitMQ,简单说一下RabbitMQ的工作原理?如何保证消息的顺序执行?Kafka了解吗?和RabbitMQ有什么区别?你为啥不用kafka来做,当时怎么考虑的?
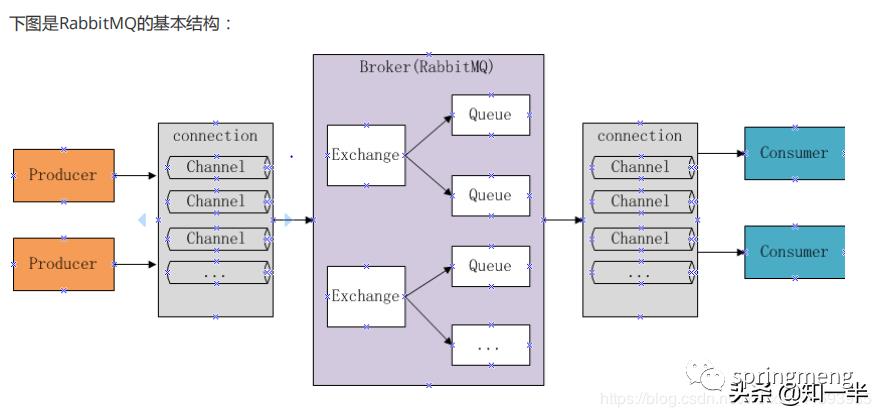
组成部分说明如下:
Broker:消息队列服务进程,此进程包括两个部分:Exchange和Queue。
Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的消费方。
Producer:消息生产者,即生产方客户端,生产方客户端将消息发送到MQ。
Consumer:消息消费者,即消费方客户端,接收MQ转发的消息。
消息发布接收流程:
-----发送消息-----
1、生产者和Broker建立TCP连接。
2、生产者和Broker建立通道。
3、生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
4、Exchange将消息转发到指定的Queue(队列)
----接收消息-----
1、消费者和Broker建立TCP连接
2、消费者和Broker建立通道
3、消费者监听指定的Queue(队列)
4、当有消息到达Queue时Broker默认将消息推送给消费者。
5、消费者接收到消息。
6、我看你简历里说熟悉计算机网络,来聊一聊计算机网络吧。了不了解tcp/udp,简单说下两者的区别?tcp为什么要三次握手和四次挥手?两次握手可以不?会有什么问题?tcp怎么保证有序传输的,讲下tcp的快速重传和拥塞机制,知不知道time_wait状态,这个状态出现在什么地方,有什么用?
(1)区别:
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
两次握手为什么不可以?
采用三次握手是为了防止失效的连接请求报文段突然又传送到主机B,因而产生错误。失效的连接请求报文段是指:主机A发出的连接请求没有收到主机B的确认,于是经过一段时间后,主机A又重新向主机B发送连接请求,且建立成功,顺序完成数据传输。考虑这样一种特殊情况,主机A第一次发送的连接请求并没有丢失,而是因为网络节点导致延迟达到主机B,主机B以为是主机A又发起的新连接,于是主机B同意连接,并向主机A发回确认,但是此时主机A根本不会理会,主机B就一直在等待主机A发送数据,导致主机B的资源浪费。
为什么要四次挥手?
TCP关闭链接四次握手原因在于tpc链接是全双工通道,需要双向关闭。client向server发送关闭请求,表示client不再发送数据,server响应。此时server端仍然可以向client发送数据,待server端发送数据结束后,就向client发送关闭请求,然后client确认。
tcp怎么保证有序传输的:
1)应用数据被分割成TCP认为最适合发送的数据块。
2)超时重传:当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
3)TCP给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
4)校验和:TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。
5)TCP的接收端会丢弃重复的数据。
6)流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的我数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。
7)拥塞控制:当网络拥塞时,减少数据的发送。
time_wait状态,这个状态出现在什么地方,有什么用?
1.为实现TCP全双工连接的可靠释放
当服务器先关闭连接,如果不在一定时间内维护一个这样的TIME_WAIT状态,那么当被动关闭的一方的FIN到达时,服务器的TCP传输层会用RST包响应对方,这样被对方认为是有错误发生,事实上这只是正常的关闭连接工程,并没有异常
2.为使过期的数据包在网络因过期而消失
在这条连接上,客户端发送了数据给服务器,但是在服务器没有收到数据的时候服务器就断开了连接
现在数据到了,服务器无法识别这是新连接还是上一条连接要传输的数据,一个处理不当就会导致诡异的情况发生
下面讲讲大量的TIME_WAIT产生需要的条件:
1.高并发
2.服务器主动关闭连接
如果服务器不主动关闭连接,那么TIME_WAIT就是客户端的事情了
7、http与https有啥区别?https是怎么做到安全的?
https安全的原因:
https把http消息进行加密之后再传送,这样就算坏人拦截到了,得到消息之后也看不懂,这样就做到了安全,具体来说,https是通过对称加密和非对称加密和hash算法共同作用,来在性能和安全性上达到一个平衡,加密是会影响性能的,尤其是非对称加密,因为它的算法比较复杂,那么加密了就安全了吗?不是的,https除了对消息进行了加密以外还会对通信的对象进行身份验证。
https并不是一种新的协议,而是使用了一种叫做TLS(Transport layer secure)的安全层,这个安全层提供了数据加密的支持,让http消息运行在这个安全层上,就达到了安全,而运行在这个安全层上的http就叫做https(http secure)
8,还有点时间,写个题吧
leetcode406. 根据身高重建队列
假设有打乱顺序的一群人站成一个队列。每个人由一个整数对(h, k)表示,其中h是这个人的身高,k是排在这个人前面且身高大于或等于h的人数。编写一个算法来重建这个队列。
注意:
总人数少于1100人。
示例
输入:
[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]
输出:
[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]
思路:
第一步排序:
people:
[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]
排序后:
[[7,0], [7,1], [6,1], [5,0], [5,2], [4,4]]
然后从数组people第一个元素开始,放入到数组result中,放入的位置就是离result开始位置偏移了元素第二个数字后的位置。如下:
1. people: [7,0]
插入到离开始位置偏移了0个距离的位置。
result: [[7,0]]
2. people: [7,1]
插入到离开始位置偏移了1个距离的位置,即插入到[7,0]的后面。
result: [[7,0], [7,1]]
3. people: [6,1]
插入到离开始位置偏移了1个距离的位置,即插入到[7,0]的后面。
result: [[7,0], [6,1], [7,1]]
4. people: [5,0]
插入到离开始位置偏移了0个距离的位置,即插入到[7,0]的前面。
result: [[5,0], [7,0], [6,1], [7,1]]
5. people: [5,2]
插入到离开始位置偏移了2个距离的位置,即插入到[7,0]的后面。
result: [[5,0], [7,0], [5,2], [6,1], [7,1]]
6. people: [4,4]
插入到离开始位置偏移了4个距离的位置,即插入到[6,1]的后面。
result: [[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]
这种算法体现了元素第二个数字与其插入位置的关系,所以通过简单的一个for循环就可以搞定。
代码
最后pdd成功把我面哭了,你看了面试题,感觉怎么样呢?
最后,孟哥整理了进大厂的必看面试题,免费领取,后台回复:面试文档
以上是关于去pdd面试,redis把我面哭了附面试答案的主要内容,如果未能解决你的问题,请参考以下文章
学会这些微服务+Tomcat+NGINX+MySQL+Redis,再去面试阿里P7岗吧