【面试专题】Android屏幕刷新机制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了【面试专题】Android屏幕刷新机制相关的知识,希望对你有一定的参考价值。
参考技术A这个问题在其他人整理的面试宝典中也有提及,一般来说都是问View的刷新,基本上从ViewRootImpl的scheduleTraversals()方法开始讲就可以了。之前看别人面试斗鱼的面经,被问到了android屏幕刷新机制、双缓冲、三缓冲、黄油计划,然后我面网易云的时候也确实被问到了这个题目。
屏幕刷新这一整套,你把我这篇文章里的内容讲清楚了,肯定ok了。网易云还附加问了我CPU和GPU怎么交换绘制数据的,这个我个人认为完全是加分题了,我答不出来,感兴趣的小伙伴可以去看一看,你要是能说清楚,肯定能让面试官眼前一亮。
在讲双缓冲这个概念之前,先来了解一些基础知识。
在一个典型的显示系统中,一般包括CPU、GPU、Display三个部分, CPU负责计算帧数据,把计算好的数据交给GPU, GPU会对图形数据进行渲染,渲染好后放到buffer(图像缓冲区)里存起来,然后Display(屏幕或显示器)负责把buffer里的数 据呈现到屏幕上。
屏幕刷新频是固定的,比如每16.6ms从buffer取数据显示完一帧,理想情况下帧率和刷新频率保持一致,即每绘制完成一 帧,显示器显示一帧。但是CPU/GPU写数据是不可控的,所以会出现buffer里有些数据根本没显示出来就被重写了,即 buffer里的数据可能是来自不同的帧的。当屏幕刷新时,此时它并不知道buffer的状态,因此从buffer抓取的帧并不是完整的一帧画面,即出现画面撕裂。
简单说就是Display在显示的过程中,buffer内数据被CPU/GPU修改,导致画面撕裂。
那咋解决画面撕裂呢? 答案是使用双缓冲。
由于图像绘制和屏幕读取 使用的是同个buffer,所以屏幕刷新时可能读取到的是不完整的一帧画面。
双缓冲,让绘制和显示器拥有各自的buffer:GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Frame Buffer,当屏幕刷新时,Frame Buffer 并不会发生变化,当Back buffer准备就绪后,它们才进行交换。
什么时候进行两个buffer的交换呢?
假如是 Back buffer准备完成一帧数据以后就进行,那么如果此时屏幕还没有完整显示上一帧内容的话,肯定是会出问题的。 看来只能是等到屏幕处理完一帧数据后,才可以执行这一操作了。
当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时有一段时间空隙,称为VerticalBlanking Interval(VBI)。这个时间点就是我们进行缓冲区交换的最佳时间。因为此时屏幕没有在刷新,也就避免了交换过程中出现画面撕裂的状况。
VSync(垂直同步)是VerticalSynchronization的简写,它利用VBI时期出现的vertical sync pulse(垂直同步脉冲)来保证双缓冲在最佳时间点才进行交换。另外,交换是指各自的内存地址,可以认为该操作是瞬间完成。
所以说VSync这个概念并不是Google首创的,它在早年的PC机领域就已经出现了。
先总体概括一下,Android屏幕刷新使用的是“双缓存+VSync机制”,单纯的双缓冲模式容易造成jank(丢帧)现象,为了解决这个问题,Google在 Android4.1 提出了Project Butter(⻩油工程),引入了 drawing with VSync 的概念。
以时间的顺序来看下将会发生的过程:
所以总的来说,就是屏幕平白无故地多显示了一次第1帧。 原因是第2帧的CPU/GPU计算 没能在VSync信号到来前完成。
这里注意一下一个细节, jank(丢帧、掉帧) ,不是说这一帧丢弃了不显示,而是这一帧延迟显示了,因为缓存交换的时机只能等下一个VSync了。
为了优化显示性能,Google在Android 4.1系统中对Android Display系统进行了重构,实现了Project Butter(⻩油工程): 系统在收到VSync pulse后,将⻢上开始下一帧的渲染。即一旦收到VSync通知(16ms触发一次),CPU和GPU 才立刻开 始计算然后把数据写入buffer。如下图:
CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。 一句话总结,VSync同步使得CPU/GPU充分利用了16.6ms时间,减少jank。
问题又来了,如果界面比较复杂,CPU/GPU的处理时间较⻓, 超过了16.6ms 呢?如下图:
为什么 CPU 不能在第二个 16ms 处理绘制工作呢? 因为只有两个 buffer,Back buffer正在被GPU用来处理B帧的数据, Frame buffer的内容用于Display的显示,这样两个 buffer都被占用,CPU 则无法准备下一帧的数据。 那么,如果再提供一个buffer,CPU、GPU 和显示设备都能使用各自的 buffer工作,互不影响。这就是三缓冲的来源了。
三缓存就是在双缓冲机制基础上增加了一个 Graphic Buffer 缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的一个 Graphic Buffer 所占用的内存。
三缓冲有效利用了等待VSync的时间,减少了jank,但是带来了延迟。是不是 Buffer 越多越好呢?这个是否定的, Buffer 正常还是两个,当出现 Jank 后三个足以。
上边讲的都是基础的刷新知识,那么在 Android 系统中,真正来实现绘制的类叫 Choreographer 。
Choreographer 负责对CPU/GPU绘制的指导 —— 收到VSync信号才开始绘制,保证绘制拥有完整 16.6ms,避免绘制的随机性。
通常 应用层不会直接使用Choreographer,而是使用更高级的API,例如动画和View绘制相关的 ValueAnimator.start()、View.invalidate()等。
(这边补充说一个面试题,属性动画更新时会回调onDraw吗?不会,因为它内部是通过AnimationHandler中的Choreographer机制来实现的更新,具体的逻辑,如果以后有时间的话可以写篇文章来说一说。)
业界一般通过Choreographer来监控应用的帧率。
(这个东西也是个面试题,会问你如何检测应用的帧率?你可以提一下Choreographer里面的FrameCallback,然后结合一些第三方库的实现具体说一下。)
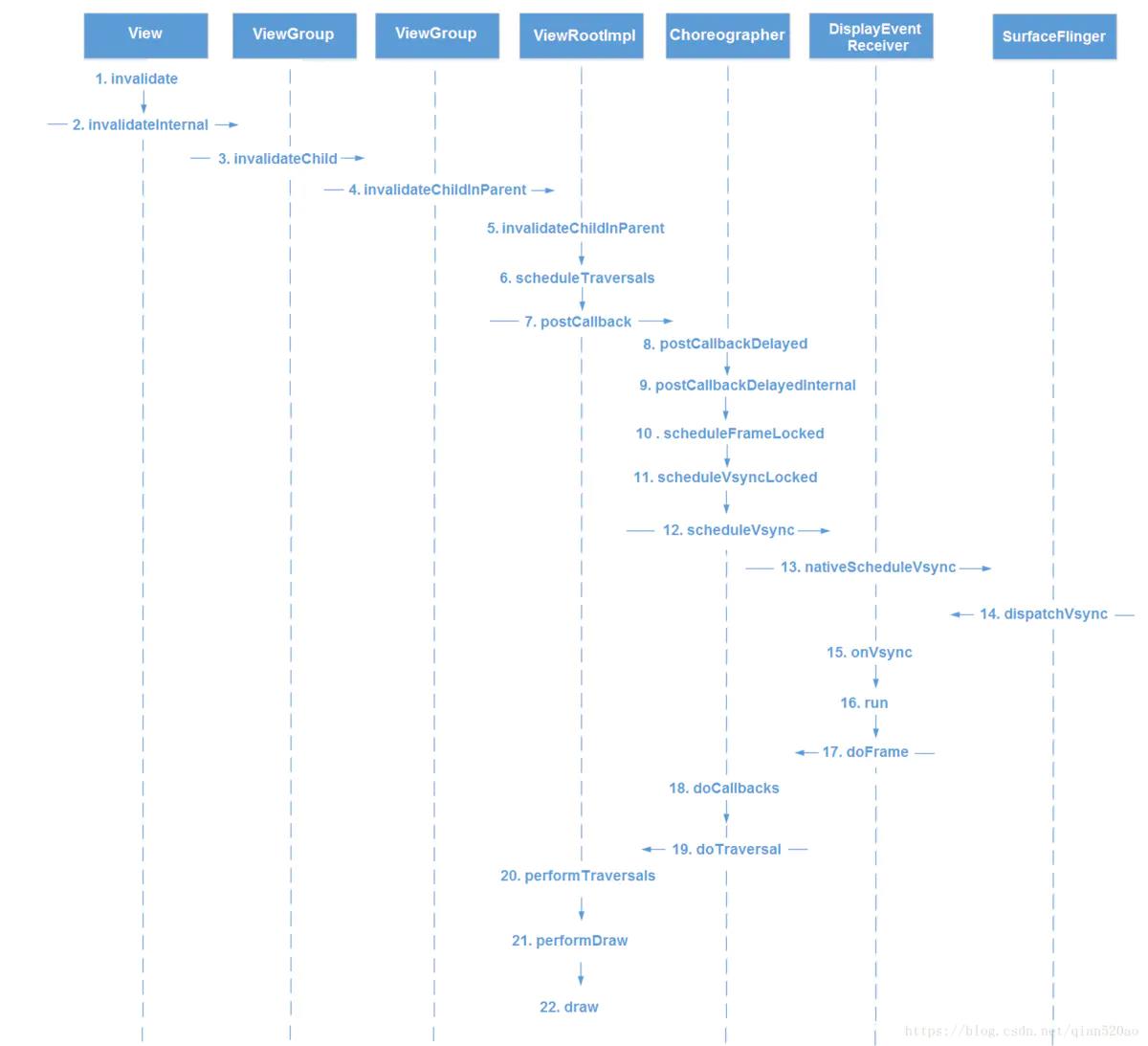
Activity启动,走完onResume方法后,会进行window的添加。window添加过程会调用ViewRootImpl的setView()方法, setView()方法会调用requestLayout()方法来请求绘制布局,requestLayout()方法内部又会走到scheduleTraversals()方法。最后会走到performTraversals()方法,接着到了我们熟知的测量、布局、绘制三大流程了。
当我们使用 ValueAnimator.start()、View.invalidate()时,最后也是走到ViewRootImpl的 scheduleTraversals()方法。(View.invalidate()内部会循环获取ViewParent直到ViewRootImpl的invalidateChildInParent()方法,然后走到scheduleTraversals(),可自行查看源码)
即所有UI的变化都是走到ViewRootImpl的scheduleTraversals()方法。
这里注意一个点:scheduleTraversals()之后不是立即就执行performTraversals()的,它们中间隔了一个Choreographer机制。简单来说就是scheduleTraversals()中,Choreographer会去请求native的VSync信号,VSync信号来了之后才会去调用performTraversals()方法进行View绘制的三大流程。
mChoreographer,是在ViewRootImpl的构造方法内使用 Choreographer.getInstance()创建。
Choreographer和Looper一样是线程单例的,通过ThreadLocal机制来保证唯一性。因为Choreographer内部通过FrameHandler来发送消息,所以初始化的时候会先判断当前线程有无Looper,没有的话直接抛异常。
mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null)方法,第一个参数是CALLBACK_TRAVERSAL,表示回调任务的类型,共有以下5种类型:
五种类型任务对应存入对应的CallbackQueue中,每当收到 VSYNC 信号时,Choreographer 将首先处理 INPUT 类型的任 务,然后是 ANIMATION 类型,最后才是 TRAVERSAL 类型。
postCallback()内部调用postCallbackDelayed(),接着又调用postCallbackDelayedInternal(),正常消息执行scheduleFrameLocked,延迟运行的消息会发送一个MSG_DO_SCHEDULE_CALLBACK类型的meessage:
FrameHandler 这个类是内部专门用来处理消息的,可以看到延迟的MSG_DO_SCHEDULE_CALLBACK类型消息最终也是走到scheduleFrameLocked:
scheduleFrameLocked() 方法里面就会去真正的申请 VSync 信号了。
VSync信号的注册和监听是通过mDisplayEventReceiver实现的。mDisplayEventReceiver是在Choreographer的构造方法中创建的,是FrameDisplayEventReceiver的实例。 FrameDisplayEventReceiver是 DisplayEventReceiver 的子类,
native的VSync信号到来时,会走到 onVsync() 回调:
(这里补充一个面试题:页面UI没有刷新的时候onVsync()回调也会执行吗?不会,因为VSync是UI需要刷新的时候主动去申请的,而不是native层不停地往上面去推这个回调的,这边要注意。)
doFrame() 方法中会通过doCallbacks()方法去执行各种callbacks,主要内容就是取对应任务类型的队列,遍历队列执行所有任务,其中就包括了 ViewRootImpl 发起的绘制任务mTraversalRunnable了。mTraversalRunnable执行doTraversal()方法,移除同步屏障,调用performTraversals()开始三大绘制流程。
到这里整个流程就闭环了。
Android Framework 学习:屏幕刷新机制
一、什么是屏幕刷新机制
屏幕的刷新包括三个步骤:
- CPU 计算屏幕数据
- GPU 进一步处理和缓存
- Display 将缓存中(buffer)的屏幕数据显示出来。
-
View 发起刷新的操作时,最终是走到了 ViewRootImpl 的 scheduleTraversals() 里去,然后这个方法会将遍历绘制 View 树的操作 performTraversals() 封装到 Runnable 里,传给 Choreographer,以当前的时间戳放进一个 mCallbackQueue 队列里,然后调用了 native 层的方法向底层注册监听下一个屏幕刷新信号事件。
-
当下一个屏幕刷新信号发出的时候,如果对这个事件进行监听,那么底层会回调 onVsync() 方法来通知。当 onVsync() 被回调时,会发一个 Message 到主线程,将后续的工作切到主线程来执行。切到主线程的工作就是去 mCallbackQueue 队列里根据时间戳将之前放进去的 Runnable 取出来执行,而这些 Runnable 就是遍历绘制 View 树的操作 performTraversals()。遍历操作完成后,就会去绘制那些需要刷新的 View。
-
当我们调用了 invalidate(),requestLayout(),等之类刷新界面的操作时,并不是马上就会执行这些刷新的操作,而是通过 ViewRootImpl 的 scheduleTraversals() 先向底层注册监听下一个屏幕刷新信号事件,然后等下一个屏幕刷新信号来的时候,才会去通过 performTraversals() 遍历绘制 View 树来执行这些刷新操作。
-
导致界面刷新丢帧的原因有两类:一是遍历绘制 View 树计算屏幕数据的时间超过了 16.6ms;二是,主线程一直在处理其他耗时的消息,导致遍历绘制 View 树的工作迟迟不能开始,从而超过了 16.6 ms 底层切换下一帧画面的时机。第一个原因是因为我们写的布局有问题,需要进行优化了。而第二个原因则是我们常说的避免在主线程中做耗时的任务。针对第二个原因,系统已经引入了同步屏障消息的机制,尽可能的保证遍历绘制 View 树的工作能够及时进行,但仍没办法完全避免,所以我们还是得尽可能避免主线程耗时工作。
二、Choreographer机制
Choreographer机制,用于同Vsync机制配合,统一动画、输入和绘制的时机。
本节讲解Choreographer机制主要是从绘制方面做阐述,界面的绘制要从ViewRootImpl的requestLayout开始说起,其源码如下:
@Override public void requestLayout() { if (!mHandlingLayoutInLayoutRequest) { checkThread(); // 检查是否在UI线程 mLayoutRequested = true; // 是否进行measure和layout布局 scheduleTraversals(); } } void scheduleTraversals() { if (!mTraversalScheduled) { mTraversalScheduled = true; // 拦截同步消息 mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier(); // 执行绘制操作 mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); if (!mUnbufferedInputDispatch) { scheduleConsumeBatchedInput(); } notifyRendererOfFramePending(); pokeDrawLockIfNeeded(); } }
这里需要注意的地方有两点:
- postSyncBarrier()方法:Handler 的同步屏障,作用是可以拦截 Looper 对同步消息的获取和分发,加入同步屏障之后Looper 只会获取和处理异步消息,如果没有异步消息那么就会进入阻塞状态。通过同步屏障,就为UI绘制渲染处理操作的优先处理提供了基础。
- Choreographer:编舞者,统一动画、输入和绘制时机。
1. Choreographer 启动逻辑
Choreographer的创建是在ViewRootImpl的构造函数中。
public ViewRootImpl(Context context, Display display) { mContext = context; mWindowSession = WindowManagerGlobal.getWindowSession(); ... mChoreographer = Choreographer.getInstance(); ... }
下面是Choreographer的getInstance执行的代码:
/** * Gets the choreographer for the calling thread. Must be called from * a thread that already has a {@link android.os.Looper} associated with it. * * @return The choreographer for this thread. * @throws IllegalStateException if the thread does not have a looper. */ public static Choreographer getInstance() { return sThreadInstance.get(); } // Thread local storage for the choreographer. private static final ThreadLocal<Choreographer> sThreadInstance = new ThreadLocal<Choreographer>() { @Override protected Choreographer initialValue() { Looper looper = Looper.myLooper(); if (looper == null) { throw new IllegalStateException("The current thread must have a looper!"); } Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP); if (looper == Looper.getMainLooper()) { mMainInstance = choreographer; } return choreographer; } }; private static volatile Choreographer mMainInstance;
可以看到每一个Looper线程都有自己的Choreographer,其他线程发送的回调只能运行在对应Choreographer所属的Looper线程上。
这里我们再看一下Choreographer的构造函数:
private Choreographer(Looper looper, int vsyncSource) { mLooper = looper; mHandler = new FrameHandler(looper); mDisplayEventReceiver = USE_VSYNC ? new FrameDisplayEventReceiver(looper, vsyncSource) : null; mLastFrameTimeNanos = Long.MIN_VALUE; mFrameIntervalNanos = (long)(1000000000 / getRefreshRate()); mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1]; for (int i = 0; i <= CALLBACK_LAST; i++) { mCallbackQueues[i] = new CallbackQueue(); } // b/68769804: For low FPS experiments. setFPSDivisor(SystemProperties.getInt(ThreadedRenderer.DEBUG_FPS_DIVISOR, 1)); }
Choreographer类中有一个Looper和一个FrameHandler变量。变量USE_VSYNC用于表示系统是否是用了Vsync同步机制,该值是通过读取系统属性debug.choreographer.vsync来获取的。如果系统使用了Vsync同步机制,则创建一个FrameDisplayEventReceiver对象用于请求并接收Vsync事件,最后Choreographer创建了一个大小为3的CallbackQueue队列数组,用于保存不同类型的Callback。
不同类型的Callback包括如下4种:
CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_TRAVERSAL、CALLBACK_COMMIT。
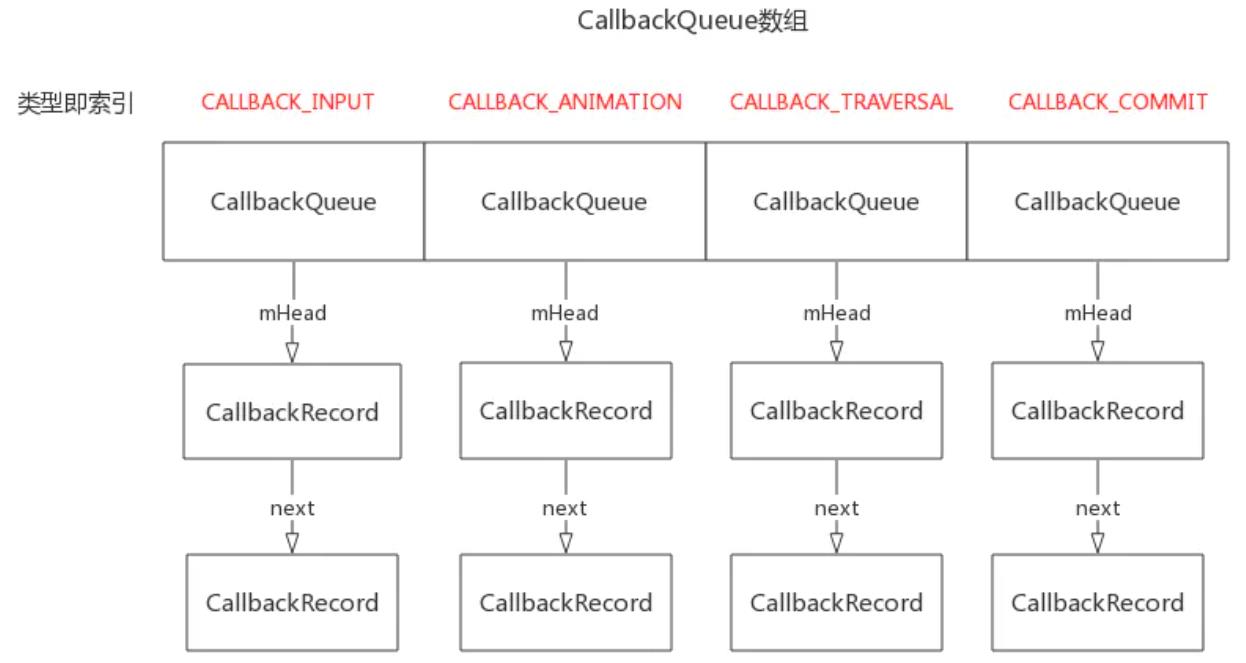
CallbackQueue是一个容量为4的数组,每一个元素作为头指针,引出对应类型的链表,4种事件就是通过这4个链表来维护的。而FrameHandler中主要处理三类消息:
private final class FrameHandler extends Handler { public FrameHandler(Looper looper) { super(looper); } @Override public void handleMessage(Message msg) { switch (msg.what) { case MSG_DO_FRAME: doFrame(System.nanoTime(), 0); break; case MSG_DO_SCHEDULE_VSYNC: doScheduleVsync(); // 请求VSYNC信号 break; case MSG_DO_SCHEDULE_CALLBACK: doScheduleCallback(msg.arg1); break; } } }
2. Choreographer执行流程
执行流程就要需要从下面的代码开始说起:
// 执行绘制操作 mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
最终会调到 postCallbackDelayedInternal 方法:
private void postCallbackDelayedInternal(int callbackType, Object action, Object token, long delayMillis) { synchronized (mLock) { // 当前时间 final long now = SystemClock.uptimeMillis(); // 回调执行时间,为当前时间加上延迟的时间 final long dueTime = now + delayMillis; // obtainCallbackLocked会将传入的3个参数转换为CallbackRecord,然后CallbackQueue根据回调类型将CallbackRecord添加到链表上。 mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token); if (dueTime >= now) { // 如果delayMillis=0的话,dueTime=now,则会马上执行 scheduleFrameLocked(now); } else { // 如果dueTime > now,则发送一个what为MSG_DO_SCHEDULE_CALLBACK类型的定时消息,等时间到了再处理,其最终处理也是执行scheduleFrameLocked(long now)方法 Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action); msg.arg1 = callbackType; msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, dueTime); } } }
mCallbackQueues先把对应的callback添加到链表上来,然后判断是否有延迟,如果没有则会马上执行scheduleFrameLocked,如果有,则发送一个what为MSG_DO_SCHEDULE_CALLBACK类型的定时消息,等时间到了再处理,其最终处理也是执行scheduleFrameLocked(long now)方法。
private void scheduleFrameLocked(long now) { if (!mFrameScheduled) { mFrameScheduled = true; if (USE_VSYNC) { // 如果使用了VSYNC,由系统值确定 if (DEBUG_FRAMES) { Log.d(TAG, "Scheduling next frame on vsync."); } if (isRunningOnLooperThreadLocked()) { // 请求VSYNC信号,最终会调到Native层,Native处理完成后触发FrameDisplayEventReceiver的onVsync回调,回调中最后也会调用doFrame(long frameTimeNanos, int frame)方法 scheduleVsyncLocked(); } else { // 在UI线程上直接发送一个what=MSG_DO_SCHEDULE_VSYNC的消息,最终也会调到scheduleVsyncLocked()去请求VSYNC信号 Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC); msg.setAsynchronous(true); mHandler.sendMessageAtFrontOfQueue(msg); } } else { // 没有使用VSYNC final long nextFrameTime = Math.max( mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now); if (DEBUG_FRAMES) { Log.d(TAG, "Scheduling next frame in " + (nextFrameTime - now) + " ms."); } // 直接发送一个what=MSG_DO_FRAME的消息,消息处理时调用doFrame(long frameTimeNanos, int frame)方法 Message msg = mHandler.obtainMessage(MSG_DO_FRAME); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, nextFrameTime); } } }
判断USE_VSYNC,如果使用了VSYNC,走scheduleVsyncLocked,即请求VSYNC信号,最终调用doFrame;如果没使用VSYNC,则通过异步Message执行doFrame。
下面我们看一下doFrame的代码:
void doFrame(long frameTimeNanos, int frame) { final long startNanos; synchronized (mLock) { if (!mFrameScheduled) { return; // mFrameScheduled=false,则直接返回。 } long intendedFrameTimeNanos = frameTimeNanos; //原本计划的绘帧时间点 startNanos = System.nanoTime();//保存起始时间 //由于Vsync事件处理采用的是异步方式,因此这里计算消息发送与函数调用开始之间所花费的时间 final long jitterNanos = startNanos - frameTimeNanos; //如果线程处理该消息的时间超过了屏幕刷新周期 if (jitterNanos >= mFrameIntervalNanos) { //计算函数调用期间所错过的帧数 final long skippedFrames = jitterNanos / mFrameIntervalNanos; //当掉帧个数超过30,则输出相应log if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) { Log.i(TAG, "Skipped " + skippedFrames + " frames! " + "The application may be doing too much work on its main thread."); } final long lastFrameOffset = jitterNanos % mFrameIntervalNanos; frameTimeNanos = startNanos - lastFrameOffset; //对齐帧的时间间隔 } //如果frameTimeNanos小于一个屏幕刷新周期,则重新请求VSync信号 if (frameTimeNanos < mLastFrameTimeNanos) { scheduleVsyncLocked(); return; } mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos); mFrameScheduled = false; mLastFrameTimeNanos = frameTimeNanos; } try { Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame"); //分别回调CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_TRAVERSAL事件 mFrameInfo.markInputHandlingStart(); doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos); mFrameInfo.markAnimationsStart(); doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos); mFrameInfo.markPerformTraversalsStart(); doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos); } finally { Trace.traceEnd(Trace.TRACE_TAG_VIEW); } }
doCallBacks里的run方法执行了,也就是真正执行了View的绘制流程了。
3.Choreographer总结
1). Choreographer支持4种类型事件:输入、绘制、动画、提交,并通过postCallback在对应需要同步vsync进行刷新处进行注册,等待回调。
2). Choreographer监听底层Vsync信号,一旦接收到回调信号,则通过doFrame统一对java层4种类型事件进行回调。
三、屏幕绘制过程的流程图
参考资料:
以上是关于【面试专题】Android屏幕刷新机制的主要内容,如果未能解决你的问题,请参考以下文章