Intel Hyperscan简介
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Intel Hyperscan简介相关的知识,希望对你有一定的参考价值。
https://software.intel.com/content/www/us/en/develop/articles/introduction-to-hyperscan.html
目录
Hyperscan是 Intel 的高性能正则表达式匹配库,可在 x86 平台上运行,并支持 Perl 兼容正则表达式 (PCRE) 语法、正则表达式组的同时匹配和流操作。它是在 BSD 许可下作为开源软件发布的。Hyperscan 提供了灵活的 C API 和多种不同的操作模式,以确保其在实际网络场景中的适用性。此外,专注于高效算法和英特尔® Streaming SIMD Extensions(英特尔® SSE)的使用使 Hyperscan 能够实现高匹配性能。适用于深度包检测(DPI)、入侵检测系统(IDS)、入侵防御系统(IPS)、防火墙等使用场景,已在全球网络安全解决方案中部署。Hyperscan 还被集成到广泛使用的开源 IDS 和 IPS 产品中,如Snort * 和Suricata *。
引擎盖下
Hyperscan 的工作流可以分为两部分:编译时和运行时。
编译时间
Hyperscan 带有一个用 C++ 编写的正则表达式编译器。如图 1 所示,它以正则表达式作为输入。根据可用的英特尔® 架构平台特性、用户定义的模式和模式特性,Hyperscan 通过复杂的图形分析和优化过程生成相应的模式数据库。生成的数据库也可以序列化并存储在内存中供运行时以后使用。
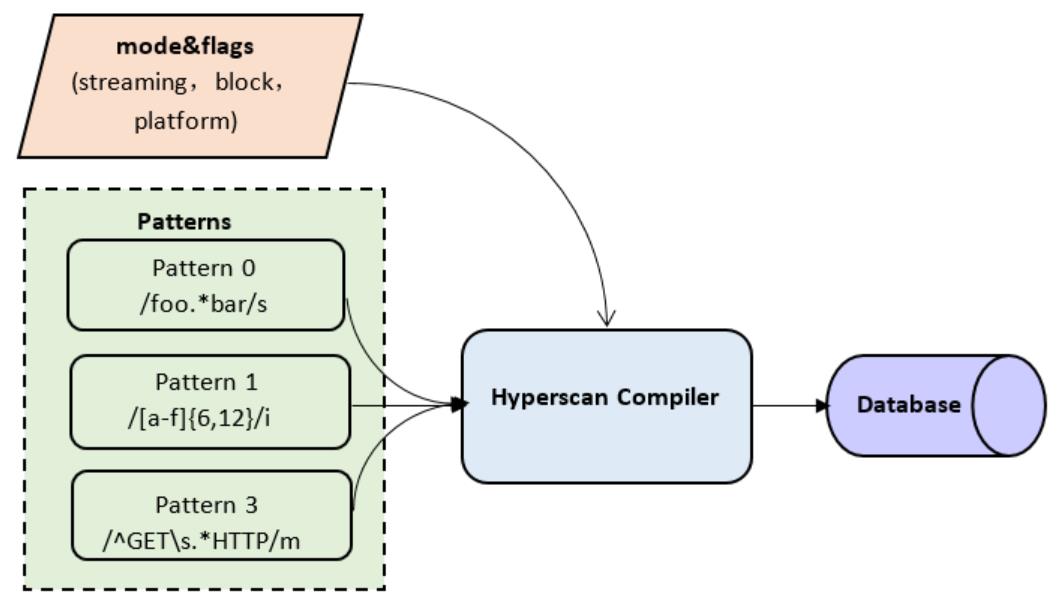
运行
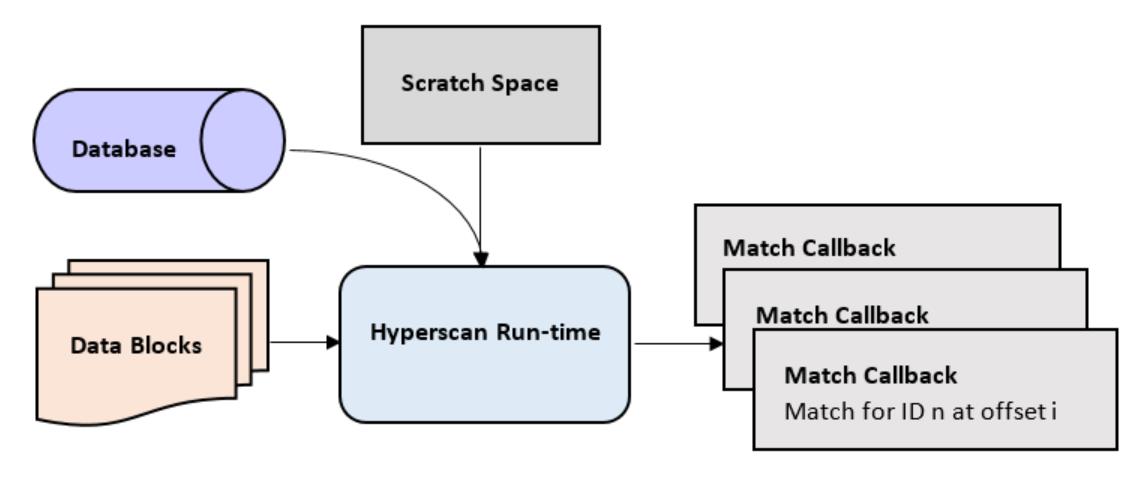
Hyperscan 运行时是用 C 语言开发的。图 2 显示了运行时主要组件的高级框图。您需要为扫描时使用的临时信息预先分配一个scratch空间,然后使用编译好的数据库调用Hyperscan的扫描API来触发内部匹配引擎(非确定性有限自动机(NFA)、确定性有限自动机(DFA)等) ) 来匹配语料库。Hyperscan 借助英特尔处理器提供的单指令、多数据 (SIMD) 指令加速这些引擎,并将匹配项通过用户提供的回调函数传递给用户应用程序进行处理。由于 Hyperscan 模式数据库是只读的,用户可以在多个 CPU 内核或多个线程之间共享数据库,以增强匹配的可扩展性。
特征
多功能功能
Hyperscan 支持对多个 Intel 处理器进行交叉编译,并针对不同的指令集进行特定优化。它没有操作系统限制,同时支持虚拟机和容器场景,涵盖大部分 PCRE 语法,并支持包含“.*”和“[^>] *”等语法的复杂表达式。提供不同的操作模式(流、块和向量),以满足不同场景的需求。如果通过使用每个模式标志请求,Hyperscan 可以在输入流中找到匹配数据的开始和结束位置。有关详细信息,请参阅Hyperscan 开发人员参考指南的当前版本 。
大规模匹配
根据复杂性,Hyperscan 可以支持匹配大量规则。与大多数常规匹配引擎不同,Hyperscan 支持多模式匹配。为每条规则指定唯一的 ID 后,Hyperscan 可以将规则编译到数据库中,并在匹配过程中输出所有当前匹配的规则 ID。
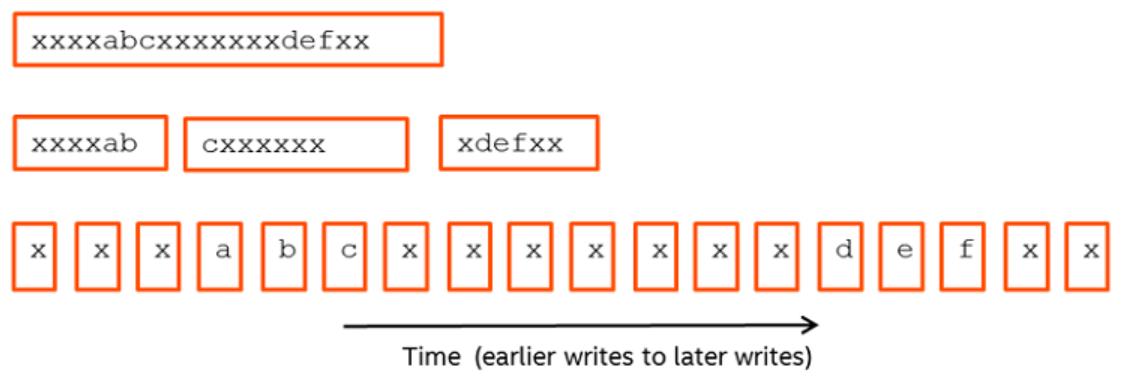
流媒体模式
Hyperscan 支持三种操作模式:块模式、流模式和向量模式。块模式是最直接的,其中扫描单个连续的数据块,找到匹配项时将匹配项返回给调用者。Streaming 模式是为在需要扫描的数据被分成多个数据包的组网场景中进行跨数据包匹配而设计的。在流模式下,Hyperscan 可以保存当前数据块的匹配状态,并在新数据块到达时将其用作初始匹配状态。如图 3 所示,无论“xxxxabcxxxxxxxdefx”数据如何随时间拆分为数据包,流模式都能保证最终匹配的一致性。此外,Hyperscan 可以压缩保存的匹配状态以减少应用程序的内存占用。流模式操作提供了一种简单的方法来扫描一段时间内到达的数据,而无需缓冲和重新扫描数据包或将扫描限制在历史数据的固定窗口。最后,还有向量模式,它提供按顺序扫描一组在内存中不连续的数据块。
高性能和可扩展性
Hyperscan 至少需要英特尔® Streaming SIMD Extensions 3 指令集,并利用 SIMD 指令来加速匹配性能。下面,我们提供了一个公开可用的性能演示的简要总结,Hyperscan 的性能分析与 hsbench。
我们使用三种不同的模式集进行此分析。
- Snort 文字是从 Snort* 3 网络入侵检测系统随附的示例规则集中提取的一组 3,316 个文字模式。
- Snort PCREs是一组 847 个正则表达式,它也是从包含 Snort 3 的示例规则集中提取的,取自针对 HTTP 流量的规则。
- Teakettle 2500是一组 2,500 个合成模式,由一个脚本生成,该脚本生成复杂度有限的正则表达式。我们在 alexa200.db 上测试了这些模式集,这是一个大型流量样本,由一个自动 Web 浏览器的 PCAP 捕获构建而成,该浏览器浏览了 Alexa* 上列出的顶级网站的一个子集。
这些模式集和语料库可从https://01.org/blogs/jpviiret/2017/performance-analysis-hyperscan-hsbench 获得。
图 4 显示了英特尔® 至强® 处理器 E5-2699 v4 @ 2.20 GHz 在块模式下 Hyperscan 的匹配性能 (Gbps)。
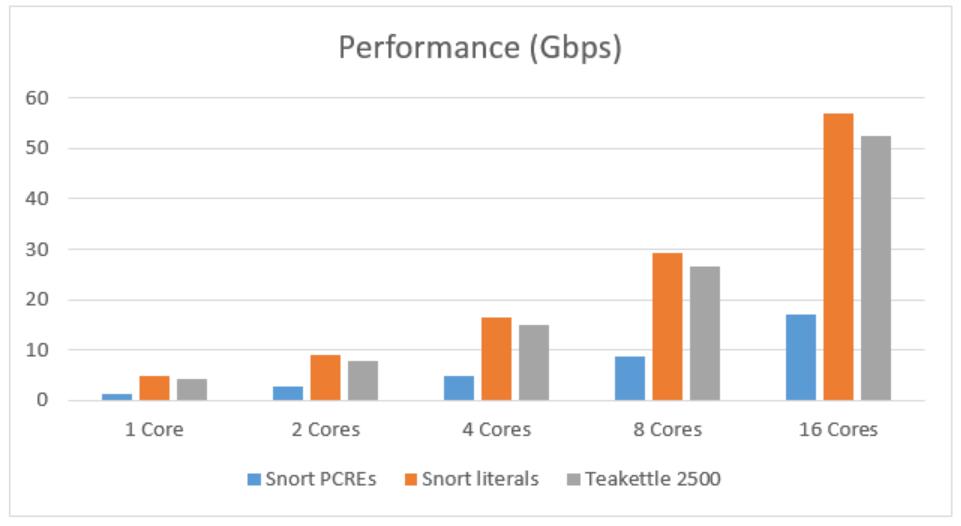
图 4 显示 Hyperscan 可以使用不同的规则集实现良好的单核性能。此外,它具有很高的可扩展性,其匹配性能随着使用的内核数量的增加几乎呈线性增长。
Hyperscan 和 DPDK 的集成
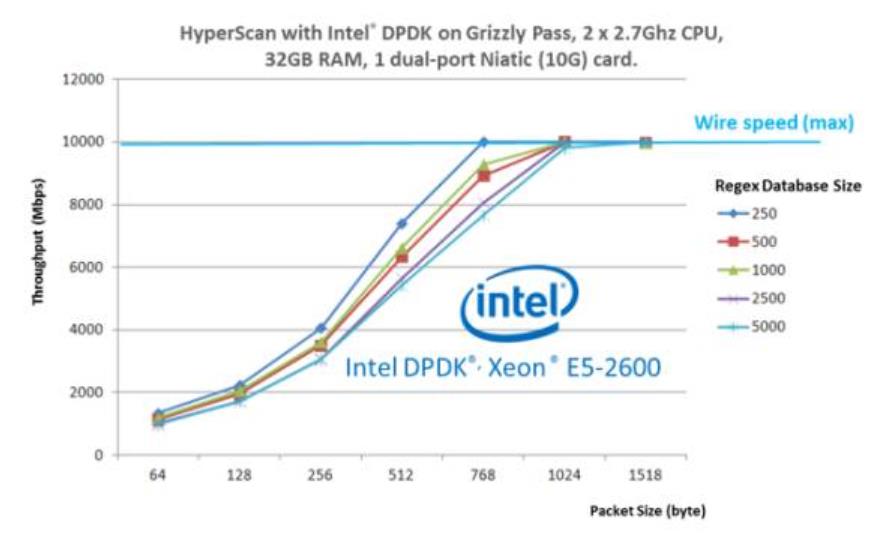
在数据平面开发工具包(DPDK)可实现高速网络分组处理和转发,并在工业中广泛应用。Hyperscan 和 DPDK 可以集成到高性能 DPI 解决方案中。图 5 显示了集成解决方案的性能数据。在测试中,我们使用真实模式和 HTTP 流量作为输入。Hyperscan 和 DPDK 的集成提供了高性能,并且在此测试中,在更大的数据包大小下,性能可以达到线速。
概括
Hyperscan 提供了一个灵活、易于使用的库,使您能够以高性能和良好的可扩展性同时匹配大量模式,并为网络数据包处理提供独特的功能。Hyperscan与DPDK的集成也为DPI、IDS、IPS等相关产品提供了成熟高效的解决方案。
关于作者
王翔是英特尔的 Hyperscan 软件工程师。他的主要关注领域包括自动机理论和正则表达式匹配。他致力于通过英特尔架构优化的模式匹配引擎,该引擎是网络安全领域中 DPI、IDS、IPS 和防火墙的核心。
产品和性能信息
性能因使用、配置和其他因素而异。如需了解更多信息,请访问 www.Intel.com/PerformanceIndex。
以上是关于Intel Hyperscan简介的主要内容,如果未能解决你的问题,请参考以下文章
加速图像处理的神器: Intel ISPC编译器ISPC简介