加速图像处理的神器: Intel ISPC编译器ISPC简介
Posted 帅的发光发亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了加速图像处理的神器: Intel ISPC编译器ISPC简介相关的知识,希望对你有一定的参考价值。
Intel ISPC编译器ISPC简介
最近刷到这么一篇教程 使用SIMD利器ISPC加速游戏开发
简单的上手摸了一下,发现这是个神器,可以帮助我把自己写的单线程的基于C/C++的图像算法编译成SIMD的版本,这样就省得自己手工写SIMD汇编了;同时编译器级的自动优化效率也非常的高,比自己绞尽脑汁的手工调整代码顺序的优化要方便多了 😃 这里强烈的安利一下 😃
ISPC相对其他编译器的优势
这里用一段简单的代码对比一下ISPC和MSVC的效率.
1、先看MSVC
首先上一段C代码:

代码逻辑就是简单的从vin buffer里依次读count个浮点数,然后算这个浮点数的平方,再写出到vout buffer里
我们可以在https://godbolt.org/ 转换代码对应的MSVC x64编译输出的汇编代码。
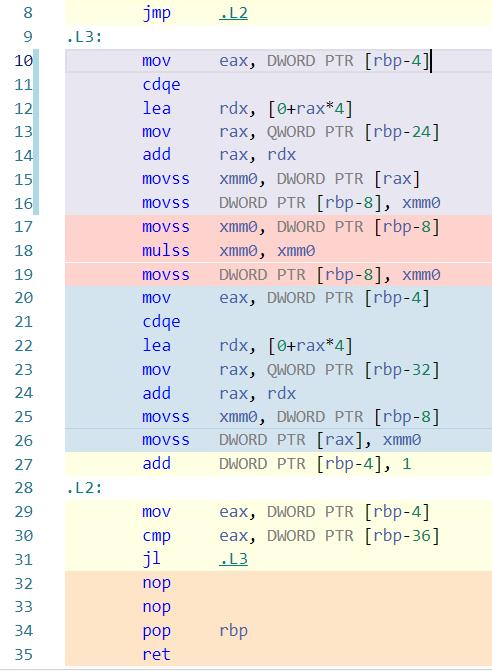
MSVC,GCC之类的编译器使用的是自动并行化编译的技术,就是由编译器来判断哪些数据可以用SIMD来做并行化处理。用MSVC生成的这段代码可以一眼看到2个问题
- 编译器默认是用的SSE指令,SSE寄存器是128bit长,所以一次只能并发4个float乘法。因为代码只会生成一次,所以即使在现在的支持AVX/AVX2的CPU上也只能用到SSE指令,因此不能充分利用一些先进的指令集来提高运算效率。
- 只有3句C代码的主循环,对应的汇编代码是从line 14到line 33, 单次循环用了太多指令,造成运行效率的低下。
2、再看ISPC
先把上面的C代码稍微修改一下,以便用 ISPC的语法,
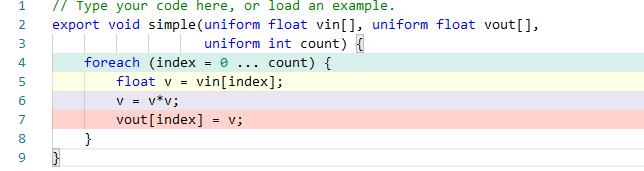
- 这个修改工作是非常简单的,ISPC语法里增加了3个keyword来显式的告诉编译器哪里是可以做数据并行化处理的。
- foreach来代替for,告诉编译器这部分循环里的数据是可以并行化处理的变量声明时用uniform标识这个变量不需要做并行化处理,这部分变量默认用EAX,RAX之类的寄存器来存放;用varying来标识此变量是需要并行化处理的(变量声明时默认就是varying),编译器会自动把这个变量用SIMD寄存器来存放。
接下来把这段代码放到https://ispc.godbolt.org/看一下ISPC生成的代码
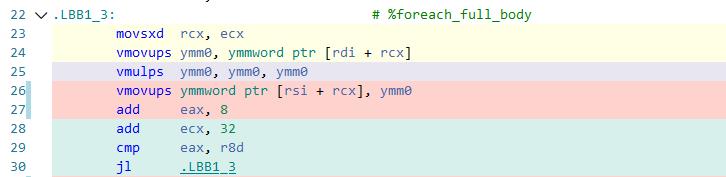
- 因为我的电脑支持AVX2,所以这里生成了AVX指令,一次计算可以做8个浮点乘法。根据ISPC的文档,在编译的时候可以指定生成的指令集类型,也就是说可以同时生成SSE,AVX,AVX2, AVX512等多个指令集的代码,在运行的时候自动根据硬件的类型来调用最符合当前硬件的代码,以此来提高计算效率。最爽的是还能生成ARM NEON版和Intel GPU的代码,让代码跑在ARM上或者GPU上,简直爽赞!!!
- 单次循环只用了8条指令,效率比MSVC的单次循环18条指令要高多了 (即使在MSVC编译参数里指定/ARCH:AVX2, 生成的AVX指令数也要多于ISPC, ISPC是基于LLVM的,看来LLVM的编译理念确实领先VC一些)
ISPC的使用方法
接下来看看怎么用这个编译器.
1、下载安装
编译器的下载非常简单,从官方https://github.com/ispc/ispc/releases 下载最新的发行包,支持windows, linux和macOS。 我用的windows版解压缩以后就3个部分。
- 根目录下的ispc.html和perfguide.html是ISPC的使用手册。
- bin目录下的ispc.exe就是编译器,不需要安装,也没有依赖库,绿色软件直接使用 (最好把这个bin目录加到系统路径里)。
- examples目录下面是自带的例子,开源软件通常文档有时候比较难理解,所以读文档的时候需要搭配example例子来阅读理解。
2、编译ISPC代码
编译就非常简单了,把需要编译的ISPC的代码放到一个文件里,直接在命令行下运行。(注意修改为自己的文件路径)
C:\\work\\ispc-v1.14.0-windows\\bin\\ispc.exe C:/work/ispc_test/simple.ispc --target=sse2-i32x4,sse4-i32x8,avx1-i32x8,avx2-i32x8,avx512knl-i32x16,avx512skx-i32x16 --arch=x86-64 -h C:/work/ispc_test/simple_ispc.h -o C:/work/ispc_test/simple_ispc.obj
默认就是带优化参数,所以只需要指定编译需要生成哪些硬件平台就可以, 我这里指定生成sse2/sse4/avx/avx2/avx512的代码。
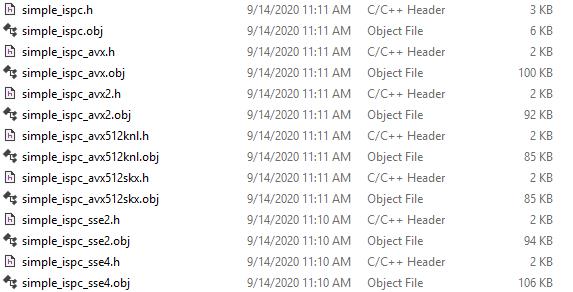
运行后可以看到在C:/work/ispc_test/目录下生成了一些h和obj文件
3、和现有项目的整合
使用时只需要在现有的项目代码里include生成的simple_ispc.h头文件,把simple()当成一个external的函数来调用;同时在link的时候把ISPC生成的所有obj链接到最终的可执行文件里就可以用了
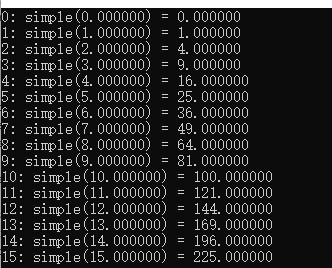
运行结果, 正确 😃。
小结
我个人的兴趣就是让代码充分的挖掘出硬件的潜力,SIMD也好,多核也好,尽量的用最便宜最低功耗的硬件方案来达到项目的需求。具体到最近几年玩的推理来说,MKLDNN, OpenVINO可以在推理的时候来发挥硬件的算力。但是就整个推理流程来说,还包括图像的预处理,推理数据的后处理和GUI显示部分,这部分不在OpenVINO的范畴,OpenCV的算法效率也不是那么高,这时候可以利用ISPC来好好搞点事情。在接下来的文章里,我会结合几个实际的图像预处理的代码来看看ISPC给性能带来的变化
以上是关于加速图像处理的神器: Intel ISPC编译器ISPC简介的主要内容,如果未能解决你的问题,请参考以下文章